基于支持向量机的高新技术企业与传统企业的类型辨识模型研究
2012-09-29潘建欣张瑞稳
郑 佳,潘建欣,张瑞稳
(1.中国科学技术大学管理学院,安徽 合肥 230026;2.清华大学核能与新能源技术研究院,北京 100084)
基于支持向量机的高新技术企业与传统企业的类型辨识模型研究
郑 佳1,潘建欣2,张瑞稳1
(1.中国科学技术大学管理学院,安徽 合肥 230026;2.清华大学核能与新能源技术研究院,北京 100084)
基于支持向量机神经网络理论,首创性地建立了一个由业绩产出财务指标辨识高新技术企业与传统企业类型的支持向量机模型。模型以企业的业绩产出财务指标数据为基础,以径向基函数作为核函数,使用网格寻优方法调节模型参数,得到优化后的模回去型,并使用测试集数据验证了模型。对结果进行二元分类决策分析,结果表明:该模型的准确率和决策率等主要评价指标都达到了85%以上,具有较高的辨识能力和可信度,为高新技术企业和传统企业的类型辨识提供了一种可靠的、简单方便的方法,可以直接量化地判别企业是否属于高新技术企业。
高新技术企业;类型辨识模型;支持向量机;神经网络
1 引言
高新技术企业在国家的经济增长中起着重要作用,但是由于高新技术是一个动态发展、不断演进的过程,这使得高新技术企业很难有能够被广泛接受的定义。在中国,高新技术企业主要是产品 (服务)属于国家重点支持的高新技术领域,且研发投入密集度、科研人员比例符合条件的企业,但这一定义并没有细化至每个企业的生产方式及产品 (服务)。现行的定义可能导致:处于传统领域的某些企业,仍然具有领先的工艺、卓越的创新能力,且创新性、成长性和盈利能力优于某些高新技术企业,但是因所处的行业不属于国家重点支持的高新技术领域,而无法认定为高新技术企业;或者,某些高新技术企业的业绩表现,并不具备高成长性和高盈利性。高新技术企业资质作为企业的无形资产,是企业科研实力的有力证明,可以获得税收政策、人才引进、投融资、土地和工商等各方面的优惠。据统计,2012年第一季度中,148家通过高新技术企业资格复审的创业板企业中,有27家没有达到高新技术企业的认定标准;对于上述不符合高新技术企业认定的公司,如果按利润总额乘以10%的企业所得税优惠粗略计算的话,仅2011年,这27家企业就至少享受了2.61亿元的企业所得税优惠。因此,对于管理者、投资者、战略政策的研究制定者,制定出更清晰成熟的高新技术企业评价标准就具有重要意义;也正因为如此,我们尝试从财务指标的角度,建立模型,希望能形成更公正客观的认证评价标准。
Oakey和Mukhar(1999)[1]主张绩效指标是高新技术企业与传统企业的重要区分指标。正是由于在资源投入上高新技术企业与传统企业之间存在显著差异,因此在业绩产出上,高新技术企业应当表现出与其高技术、高投入、高风险相对应的财务特征;但这并不能满足市场上信息需求者的要求。Nicholas和Martin(2008)[2]的研究指出现有的标准产业分类 (SIC)只能将企业进行模糊的分类,而不是建立在系统分类的基础上,并证实使用绩效指标途径来定义高新技术企业的可能。
Vapnik(1995)[3]基于统计学习理论提出了支持向量机 (support vector machine,SVM)神经网络,具有鲁棒性、计算简单以及理论上完善等优点,可用于模式分类和非线性回归的研究。已有文献报道了SVM用于商业银行构建企业破产预测机制[4]、上市公司经营决策失败预警[5]和粮食产量预测[6]等领域,但暂未有SVM用于高新技术企业与传统企业分类研究的文献报导。
2 类型辨识模型的建立
2.1 模型理论
SVM模型主要思想是建立一个超平面作为决策曲面,使得正例与反例之间的隔离边缘被最大化。对于考虑训练样本,其中x为第i个
i输入模式向量,di为对应的目标输出,用于分离的超平面形式的决策曲面方程则为:wTx+b=0,使得wTx+b>0时di=+1,否则为-1。其中在正反例附近用于确定最优决策超平面的向量称为支持向量,也是最难区分的数据点。理论研究表明模型的原问题即最优分离边缘为2/||w||,通过最小化权值向量w的欧几得里范数||w||,提供正反例之间的最大分离的可能。一般通过Lagrange乘子方法转化成其对偶问题,解决约束最优问题。建立的Lagrange函数为:

其中的α为辅助的Lagrange乘子,在N个向量中αi为非负值的向量即为支持向量。
在LIBSVM工具箱中,SVMtrain函数中预设的用于分类的C-SVM类型,其决策函数为:
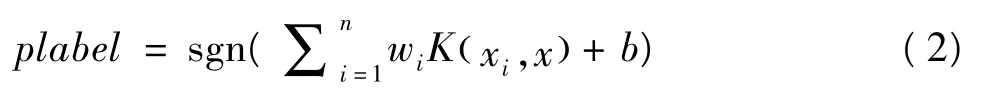
其中K为核函数,其主要类型有线性核函数、多项式核函数、径向基核函数和sigmoid核函数等。研究表明,在一般条件下径向基函数K(xi,x)=exp(-r|xi-x|2),表示以x为中心、xi到x的径向距离半径为r形成的构成的函数系,具有较好普适性。
2.2 建模过程
本文使用具有产出性质的10项绩效财务指标作为参数,直接量化地判别企业是否属于高新技术企业。区别于我国目前《高新技术企业认定管理办法》中,“企业产品 (服务)属于《国家重点支持的高新技术领域》”加“研发人员及R&D投入强度标准”的认定方法,避免了样本的投入性参数和依据此类参数所确定的高新企业之间存在的必然联系;总结已有的相关文献在指标设置上出现的频度,主要从企业的盈利能力、成长能力、营运能力上来选定财务指标,这十项绩效财务指标分别为:总资产净利率、成本费用利润率、销售毛利率、主营业务收入增长率、净利润增长率、净资产增长率、总资产增长率、存货周转率、固定资产周转率和总资产周转率。在选择样本企业时还考虑到:样本企业是否上市与该企业是否属于高新技术企业没有必然联系;本模型使用十项绩效财务指标对企业类别进行判断,将模型所得结果与该企业的真实分类进行比较,作为模型判断的准确率;为了保证样本数据的绝对真实可靠,防止原始数据的不准确引起的模型准确率下降,因此选用财务数据更可靠的上市公司作为样本企业。
根据2008年4月24日由财政部、科技部、国家税务总局联合发出的《高新技术企业认定管理办法》,以及《2010年国家高新技术企业名单》随机抽取102家高新技术上市公司,剔除数据不全的企业,得到98家样本企业,这98家样本企业中有创业板上市公司21家,非创业板上市公司77家;学者王今朝、王静 (2008)[7]认为,我国当前的传统产业主要属于第二产业中的原材料工业以及加工工业中的轻加工工业,主要包括纺织业、轻工、部分机械、化工和建材工业。并根据证监会2010年颁布的《上市公司行业分类指引》,从食品饮料(C0)、纺织业 (C11)、煤炭采选业 (B01)、建筑业 (E)的130家企业中剔除财务特征异常的ST板块和数据不全的企业,为了保证数据的一致性和可比性,再随机抽取与高新技术企业数相当的企业,得到99家传统企业样本;选取此197个样本企业2007—2010年的年报数据中盈利能力、成长能力、营运能力10个参数为输入值。
建立模型首先从原始数据中随机分离出训练集和测试集,训练集用于神经网络的学习,得到合适的模型;测试集用于测试网络的泛化能力,即检验模型的正确性。正态分布化、归一化和主成分分析降维等方法对数据进行预处理,得到有效不失真的处理后数据。使用训练集数据训练得到SVM模型,使用测试集数据对模型进行检验,并不断调节模型参数,得到最优模型。使用模型对未知数据的运算,判断企业是否为高新技术企业,达到预测的目的。
3 模型的Matlab实现
模型利用Matlab软件包编程,使用台湾大学林智仁教授等[8]开发的LIBSVM工具箱,部分函数参考了 Faruto等[9]基于 LIBSVM开发的加强工具箱。
3.1 原始数据处理
原始数据整体保存在corporation.mat文件中,记录了全部197个样本的10个参数值的197×10 double型的名为corp的矩阵,以及一个197×1的double型列向量corp_labels记录企业类型标签(T设置为传统企业,C为高新技术企业)。使用load命令载入数据,并使用figure命令查看数据。
3.2 原始数据的预处理
将corp的197×10矩阵按每一列 (即每个指标)进行正态化,得到正态化后的197×10矩阵corp_norm,目的是独立地将每一个特征成分正态化为特定区间范围。这样确保更大值的输入属性不会覆盖更小值的输入属性,有助于减少预测误差[10]。
使用ismember(corp_labels,H)命令,对企业标签corp_labels列向量元素进行逻辑判断,是“H”的元素为logic型的“1”,即为高新技术企业,不是“H”的元素为logic型的“0”,为传统企业。得到了一个名为groups的197×1的列向量。使用[train,test]=crossvalind('holdOut',groups,0.40)命令划分训练集和测试集。其中crossvalind是产生交差检验 (Cross-Validation)的函数,从groups集中以40%的概率随机选出近似比例的测试集。输出为一个含78(约197×40%)个logic“1”元素的197×1的test集,以及一个含119(=197-78) 个 logic“1”元素的 197×1的train集。利用train和test集,随机挑选得到了训练集和测试集的数据和标签,分别为train_corp,train_corp_labels,test_corp和test_corp_labels。
经验表明,对数据进行归一化处理,可以提高模型的准确率。对上一步得到的train_corp和test_corp采用 [0,1]归一化,得到了119×10的归一化后的训练集train_scale和78×10的归一化后的测试集test_scale。
变量个数太多就会增加课题的复杂性,使用主成分分析方法,从中可以取出较少的综合变量尽可能多地反映原来变量的信息。对train_scale和test_scale进行主成分分析,如图1所示,当10个参数降维成7个参数时,仍保留了95%的原始数据信息。得到了119×7的 PCA后的训练集train_pca和78×7的归一化后的测试集test_pca。代码如下:


图1 SVM模型数据的主成分分析图
3.3 建模
使用依次进行正态化,归一化和主成分分析后得到数据进行网络训练,得到SVM网络模型。代码如下:
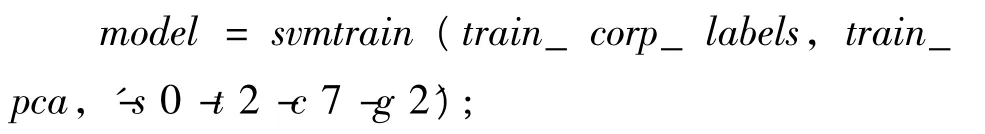
模型的输入值为测试集标签train_corp_labels和处理后的数据 train_pca,参数'-s 0 -t 2'表示使用了SVMtrain函数中预设的用于分类的C-SVM类型,其核函数类型径向基函数。'-c 7-g 2'中c和g是SVM神经网络的两个重要参数,分别对其赋值为7和2,具体选择和优化在3.5节讨论。命令输出得到了一个名为model的数据结构体,包含决策函数中的承装系数列向量w(model.sv_coef)和常数项系数的相反数-b(rho),以及得到了支持向量 (SVs)等参数。
3.4 模型预测
使用svmpredic命令,建模得到的model结构体,以及用于测试的标签和数据test_corp_labels和test_pca进行预测,Matlab命令如下:

命令输出78×1预测后的标签predict_label列向量和准确率Accuracy=85.8974%(67/78)。
3.5 c和g参数优化
核参数c和g是径向基函数RBF的SVM两个重要参数,对模型的性能起关键作用,不合适的c和g会导致网络欠学习或者过学习。最优SVM算法的核函数和参数选择,目前没有理论依据,只能是凭借经验、实验对比、大规模搜索以及使用交叉验证方法进行寻优。交叉验证方法可以在没有测试集表情的情况下,找到一定意义上的最佳参数c和g,即能使训练集在交叉验证下达到最高分类率,但并不能保证在测试集下也能达到最高分类准确率。
常用的经验方法有网格寻优、基于遗传算法寻优和基于粒子群算法寻优。本模型选用最简单的网格寻优,即建造二维的cg网格,在网格暴力寻找最大的准确率及其对应的c和g值。使用内置的SVMcgForClass函数寻优,在c和g都在 [2-10,210]广域区间内搜索,后缩小至c为 [2-3,24],g 为 [2-5,22]区间内以 20.2的步长,使用 5-folder交叉验证方法寻找最佳值,Matlab代码为:
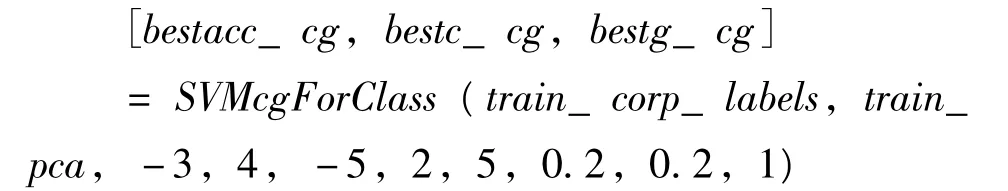
输出得到了最大的精度值和对应的最佳c值bestc_cg和g值bestg_cg。需要说明的是,只是对测试标签和数据进行运算,还需要在该计算值附近手动寻找最佳值,本例选取了c为7和g为2。
4 结果分析
4.1 模型结果分析
使用CR_train=ClassResult(train_corp_labels,train_pca,model,1)查看训练集结果。结果表明:支持向量数目为93,整体分类准确率为92.437%(110/119),其中高新技术企业分类准确率为89.8305%(53/59),传统企业分类准确率达到了95%(57/60),学习效果好。同样的,CR_test=ClassResult(test_corp_labels,test_pca,model,2)命令查看测试集结果,整体分类准确率达到了85.8974%(67/78),其中高新技术企业分类准确率为87.1795%(34/39)传统企业分类准确率达到了84.6154%。
对于二元分类决策分析,多使用Tp、Fp、Tn和Fn等参数来计算准确率、决策率、召回率、F参数、特异值和综合平衡参数等评价模型。其中,Tp表示模型辨识正确的正例数,Fp表示模型辨识错误的正例数,Tn表示模型辨识正确的反例数,以及Fn表示模型辨识错误的反例数。对于本模型而言,Tp、Fp、Tn和Fn的含义及对应数值如表1:

表1 验证集参数结果表
计算得到准确度:Accuracy=85.8974%,即高新技术企业和传统企业都被正确判别的数量占整个样本数的比重,反映了模型对整个样本的判断能力;决策率:Precision=85%,表示被模型判断为高新技术企业的40家企业中,34家真正的高新技术企业所占的比重,即模型做出企业为高新技术企业的判断,Precision表示这一判断的可信程度;召回率:Recall=87.1795%,表示在实际为高新技术企业的39家之中,被模型正确判定为高新技术企业的34家企业所占的百分比,即模型从样本企业中正确辨识出高新技术企业的能力,该参数也被称为灵敏度 (Sensitivity);特异性:Specificity=84.6154%,表示在实际真为传统企业的39家之中,被模型正确判定为传统企业33家所占的百分比。总体F评估指数:F-score=86.0759%,总体平衡精度:BAC=85.8975%,上述两项是综合评价指标,评价模型对两类指标的整体判别能力。本模型的主要评价参数指标大于85%,可知本模型在高新技术企业与传统企业的类型辨识上具有较高的辨识能力和可信度。
4.2 模型预测
构建的模型目的是用于对未知企业是否为高新技术企业进行辨识,只需要该企业 (或M个企业)的10个参数,构成M×10的数据矩阵Data,元素为随机生成0和1的M×1标签列向量Labels,表明在测试前随意的划归企业为传统的非高新的(T)或是高新的 (H),然后使用svmpredict函数,输出N×1的预测的标签Predict_label。
[Predict_label,Accuracy]=svmpredict(Labels,Data,model);
需要说明的是,由于Labels中的数据是随机的,企业是否为高新技术企业未知,只是程序计算时所需的初始赋值,而准确率Accuracy,仅表示初始的Labels和最终结果Predict_label相同的比率,在此处是没有意义的。查看Predict_label列向量的数据,当某行结果为1时表明对应的该企业是高新的,否则是传统的。对高新技术企业和传统企业,其预测结果的决策接受率,即 Precision和Recall,才是用于预测时的模型准确率,由测试集的结果来看,达到了85%和87.1795%,因此模型是可靠的。
5 结论
本文首次将支持向量机神经网络引入到高新技术企业与传统企业的类型辨识研究,建立了一个支持向量机神经网络的模型,使用企业的业绩产出财务数据直接辨识该企业是属于高新技术企业或者传统企业。模型的原始数据经过正态分布化、归一化和主成分分析降维等方法,以径向基函数为核函数,使用训练集数据训练得到了模型,利用网格寻优方法调节模型的c参数和g参数,并使用测试集数据验证了模型的准确性。使用优化后的模型的各项评价参数都达到了85%以上,结果表明模型具有优异的辨识能力和可信度,是可以用于高新技术企业与传统企业的类型辨识的。
使用SVM模型用于高新技术企业与传统企业的类型辨识的研究,与现有的评测标准相比,提供了一种全新的、可靠的但又操作简单的量化方法;十项参数指标是对企业业绩的计量和评价,对企业的管理者、投资者、战略政策的研究制定者来说,财务绩效指标更加直观、规范、容易获得;且相较于现行的高新技术企业认定指标,不存在计量上的争议和主观操作性,可以进行更客观的评判。该模型可以运用于高新技术企业对其业绩表现进行自我评价,也可作为各级高新技术企业的认定管理机构对申请企业认定审查的参考依据,还可作为高新技术企业的投资人对被投资企业综合业绩表现的评估工具。本论文使用SVM对高新技术企业与传统企业的类型辨识模型做了初步探索,在参数指标的选择、模型的优化等方面还可进一步研究。
[1]R.P.Oakey,S.M.Mukhar.United Kingdom high-technology small firms in theory and practice:a review of recent trends.International Small Business Journal.1999,(17):48 -64.
[2]Nicholas O’Regan,Martin A.Sims.Identifying high technology small firms,A sectoral analysis[J].Technovation,2008,(28):408-423.
[3]C.Cortes,V.Vapnik.Support-Vector Network[J].Machine Learning,1995,(20):273 -297.
[4]杨毓,蒙肖莲.用支持向量机(SVM)构建企业破产预测模型[J].金融研究.2006,(10):67-75.
[5]宋新平,丁永生.基于最优支持向量机模型的经营失败预警研究[J].管理科学.2008,(2):115-121.
[6]向昌盛,周子英.粮食产量预测的支持向量机模型研究[J].湖南农业大学学报.2010,(2):6-10.
[7]王今朝,王静.论高技术产业与传统产业的融合发展[J].商业时代.2008,(7):98-99.
[8]Chih-Chung Chang and Chih-Jen Lin,LIBSVM:a library for support vector machines[EB/OL].http://www.csie.ntu.edu.tw/~cjlin/libsvm,2010.
[9]Faruto and Liyang,LIBSVM-Faruto Ultimate Version.A toolbox with implements for support vector machines based on libsvm[EB/OL].http://www.matlabsky.com,2011.
[10]Hsu C-W.,Chang C C.,Lin C J.A Practical Guide to Support Vector Classification[R].Department of Computer Science and Information Engineering.Taiwan:National Taiwan University,2004.
(责任编辑 刘传忠)
Type Identification Model of High-tech Companies and Traditional Companies
Zheng Jia1,Pan Jianxin2,Zhang Ruiwen1
(1.School of Management,University of Science and Technology of China,Hefei 230026,China;2.Institute of Nuclear and New Energy Technology,Tsinghua University,Beijing 100084,China)
This paper presents a novel identification model for the identification of high technology companies and traditional ones from financial performance indexes for the first time,based on the support vector machine(SVM)neural network(NN).The model is on the basis of the data of companies’indexes,employs radial basis function(RFB)as the kernel function.The kernel parameters are selected and adjusted by grid search method.The optimized model is verified by the test data.The results are discussed by binary classification decision analysis.It indicates that the accuracy,precision,recall and other main evaluation indexes of the model are achieved 85%above,which means high reliability.The model provides a reliable,simple and convenient approach for the type identification of high technology companies quantitatively.
High technology companies;Type identification model;Support vector machine;Neural network
F270
A
2012-02-27
郑佳 (1987-),女,湖北宜昌人,管理学硕士;研究方向:高新技术企业的财务管理。
