基于2DPCA的手写数字识别
2012-09-26王军平赵振华
王军平,赵振华
(1.咸阳职业技术学院 电子信息系,陕西 咸阳 712000;2.兰州理工大学 电气工程与信息工程学院,甘肃 兰州 730050)
手写数字识别研究有着广泛的应用背景和重要的理论意义[1-3]。如今在邮政、财政、税务等工作中都需要进行手写数字的识别,识别结果的好坏直接影响到工作的效率。另外,由于数字识别的类别较小,有助于作深入分析及验证一些新的理论。例如支持向量机的提出,就是先在手写体数字识别领域里进行验证,然后推广到了其他的领域。
目前,对手写数字识别的研究依据特征的提取可分为两大类:基于字符统计规律和基于字符结构特征。基于统计规律的方法是利用字符样本库,找出0到9中每类字符空间分布的统计规律,构成分类器进行识别。基于字符结构特征的方法是分析字符笔画的构造如圈、端点、交叉点、轮廓等来构造分类器进行识别。两类方法各有优势,总体而言,统计方法能更好地描述一类模式的本质特征,对于与给定训练集差别不大的字符具有较高的识别率;基于字符结构特征的方法精确地描述了字符的细节特征,对书写结构较规范的字符有较高的识别率。
在字符的特征提取中,主元分析(PCA)是一种十分有效的方法。PCA的思想是将高维样本空间的样本投影到某个低维子空间,使得在该子空间中,投影样本的类间方差最大,类内方差最小。在字符识别中,PCA方法通常是将样本库中的每个字符图像矩阵转换为一维向量,然后求出样本总体的协方差矩阵,计算出该矩阵的特征值及特征向量,根据特征值及对应的特征向量确定子空间的基向量。子空间的这些基向量又称为字符图像的特征图,每个字符图像都可以由特征图的不同加权和重构出来,其与原图的均方误差是没有选取的那些特征值之和。由于选取的特征向量是对应于特征值较大的那些向量,一般远少于特征向量总数,这样就实现了对原始样本空间的降维。
虽然PCA能有效地降低样本空间的维数,但在实现过程中2D的图像矩阵必须首先转换为1D的图像向量,其所产生的图像向量空间的维数就很高,例如在MINIST字符库中,每个字符图像为28×28像素,转换为一维图像向量是1×784,这些图像向量所构成的空间的维数就为784。这样就很难精确计算相应的协方差矩阵。为了克服这一困难,就产生了二维主元分析(2DPCA)方法。相对于PCA,2DPCA是基于二维图像矩阵而非一维向量,即不需将图像转换成一维的向量,取代PCA中样本总体协方差矩阵的是图像协方差矩阵,它是直接从字符图像矩阵中构造出来的。这样得到的图像协方差矩阵较PCA要小很多。2DPCA有两个明显的优点:首先容易精确计算协方差矩阵,其次确定相应的特征向量所耗的时间要少的多。
文中首先介绍2DPCA的原理及其算法的描述,随后简要说明识别过程要用到的一些图像预处理,第3节讲述两种分类器的构造,第4节是实验及结果分析,最后做出总结。
1 二维主元分析
1.1 原理及算法
用X表示一个归一化的n维列向量,A为某个m×n的图像矩阵,通过下面的线性变换将A投影到X:

这样就得到了一个m维的向量Y,称之为图像A的投影特征向量。为了确定最佳的投影向量X,引入投影到X上的样本的整体散度来度量X的分辨能力。投影样本的总体散度可以用投影特征向量的协方差矩阵的迹来确定。由此得到下面的判据:

其中Sx表示训练样本的投影特征向量所构成的协方差矩阵,tr(Sx)表示的迹。通过对(2)式的最大化来找出X的某个投影方向,投影到该方向的样本总体散度最大。协方差矩阵Sx可表示为
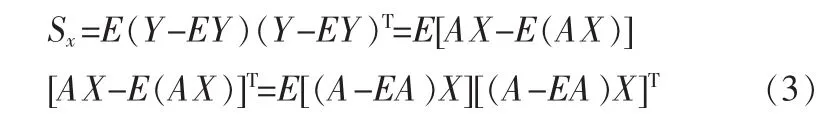
所以有
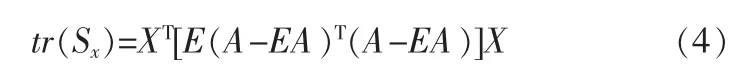
现在定义下面的矩阵
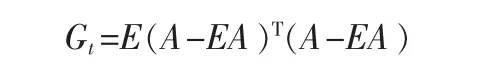
称矩阵Gt为图像协方差(散度)矩阵。容易验证Gt为n×n非负定矩阵。Gt可以利用训练图像样本直接计算出来。假定共有 M 个训练样本,Aj(j=1,2,…,M)表示第 j个训练图像,大小为m×n的矩阵,A表示所有训练图像的均值。则Gt为
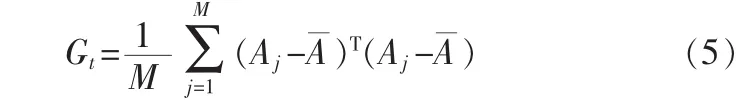
则判据(2)可表示为

其中X为归一化的列向量。使这个判据最大化的归一化向量X被称为最优投影轴。直观上讲,它意谓着在图像投影到X后,所得的投影样本的总体散度是最大的。
最优投影轴Xopt是最大化J(X)的归一化向量,即Gt的特征向量中对应于最大特征值的那个特征向量。通常需要选取一组正交的投影轴,X1,…,Xd,来最大化 J(X),即
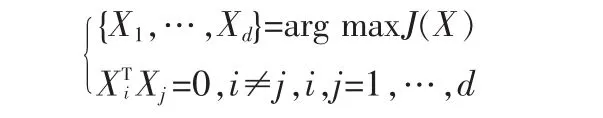
事实上,最优的投影轴,X1,…,Xd,是 Gt的前 d 个最大特征值所对应的正交特征向量。
1.2 特征提取
已经得到了2DPCA的最优投影向量X1,…,Xd,就可以用这些向量进行特征提取。对图像样本A,定义:
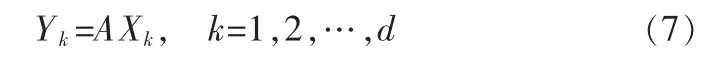
这样得到一组特征向量Y1,…,Yd,称之为样本图像A的主成分(向量)。注意2DPCA的每个主成分是向量,而PCA的主成分是标量。
用这些主成分向量构成一个m×d矩阵C=[Y1,…,Yd],称其为图像样本A的特征矩阵或特征图。
1.3 基于2DPCA的图像重构
在PCA方法中,重构图像是用主成分和特征向量(特征图)结合在一起完成的。2DPCA可以用下面类似的方法实现对图像的重构。
设图像的协方差矩阵为Gt,其前d个最大的特征值所对应的特征向量为X1,…,Xd,这些特征向量是正交的。将图像样本投影到这些向量轴上,生成主成分向量,Yk=AXk,(k=1,2,…,d)。 设
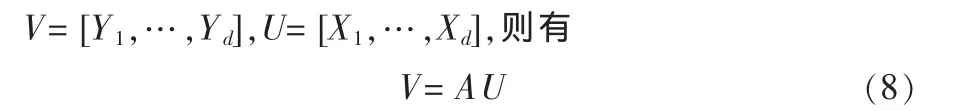
因为 X1,…,Xd是正交的,由(8)可以得到样本 A的重构图像:
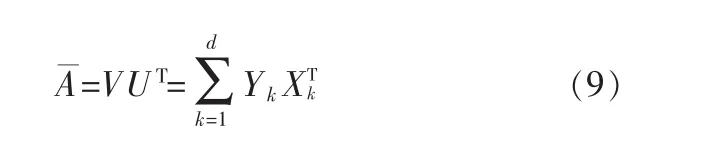
2 字符识别方法
用2DPCA方法对字符图像进行变换后,就可以利用图像的主成分向量来构造分类器进行字符的识别。作为研究,文中采用了两种识别方法。第一种是最邻近法,另一为重构误差法,下面分别介绍。
2.1 最邻近法
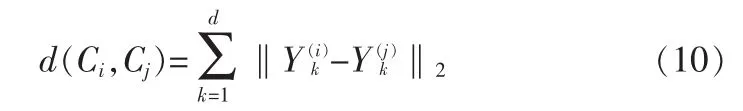
其中‖Y(i)k-Y(j)k‖2表示两个主成分向量Y(i)k和Y(j)k之间的欧氏距离。
现在假定训练样本为C1,C2,…,CN(N为训练样本的总数),并且每个样本都指定了类别γk,对某个测试样本C,若d(C,Cl)=mind(C,Cj),且 Cl∈γk,则有 C∈γk。
2.2 重构i误差法
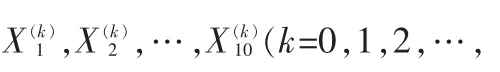
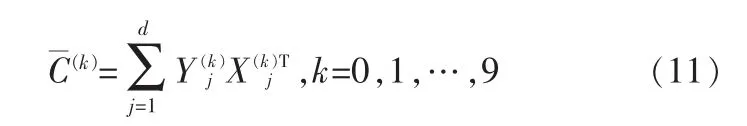
随后分别计算出测试样本与每类近似图像的误差,
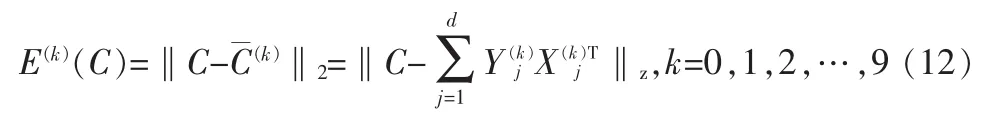
则C应属于误差最小的那类字符,即
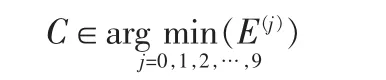
3 图像预处理
为了提高字符的识别率,有必要对字符图像进行一些预处理。预处理的目的是将字符的灰度图像二值化,并将笔画粗细统一规范为2个像素。
文中采用Otsu方法对字符图像进行二值化。Otsu又称最大类间方差法,是在最小二乘法原理的基础上推导得出的。它通过利用直方图零阶、一阶累积矩来最大化判别函数,选择最佳阈值。
字符灰度图像转化为二值图像后,利用数学形态学方法进行笔画粗细的规范处理。下面简单介绍一下本文所用到的一些数学形态法的原理。
数学形态学(Mathematical Morphology)是分析几何形状与结构的数学方法,目前它已成为分析图像几何特征的重要工具。它是由一组形态学的代数运算子组成,其中最基本的是腐蚀算子和膨胀算子,运用这些算子及其组合可以对图像结构和形状进行分析与处理。
对于一个给定的目标图像X和一个结构元素S,如果S[x]∩X≠Φ,即S[x]与X的交集不为空集,表明它们部分相关,则称这个点集为结构元素S对X的膨胀,记为X⊕S,用集合表示为X⊕S={x|S[x]∩X≠Φ},膨胀运算可以看作是将图像X中的每一个点x扩大为S[x];与此相反,腐蚀是将X中的每一个与结构元素S全等的子集S[x]收缩为x所构成的集合,记为XΘS,用集合表示为
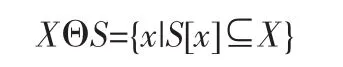
一个字符的“骨架”是描述其几何及拓扑性质的重要特征。本文通过对经过二值化的字符进行细化,提取其骨架特征,然后用包括原点的2×2结构元素对骨架图像进行一次膨胀。包括原点的2×2结构元素对图像的膨胀,相当于沿着字符骨架在骨架像素的3邻域分别“加粗”了一个像素,这就严格保证了字符所有笔画均为2个像素宽度。
图1是MINIST数据库中部分样本的处理结果。图中第1行是原始样本的灰度图,第2行是二值化图,第3行是骨骼化图,第4行是笔画规范图。从图中可以看出,通过上述预处理过程,使所有字符笔画粗细取得一致,并且通过数学形态预处理,使图像中字符的部分细节得到改善,从而使同类字符整体形态的一致性得到改善。

图1 字符图像预处理Fig.1 Image preprocession of digits
4 实验及结果分析
本实验采用的数据库是MNIST数据库[4],此数据库中含有60 000个训练样本和10 000个测试样本,每个样本都是28×28个像素的图像加上一个样本标示组成。
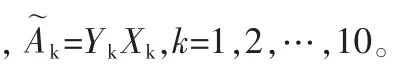

图2 部分子图Fig.2 Some reconstructed subimages
从图2可以看到,第一个子图包含了原始图像的大部分信息,随着k的增加,子图 A˜k的信息量逐渐减少,图3所示的特征值也逐渐收敛到0,这是因为每个子图对应着某个特征值,而特征值的大小反映了该子图对重构原图的贡献。所以,可以认为原始图像的大部分信息都集中在前几个比较大的特征值所对应的子图中,在识别过程中用这些主成分向量来表示原始图像是合理的。
现在将这些子图相加,就可以得到样本的重构(近似图,图4给出了数字3的5个重构图,它们是将前d(d=2,4,6,8,10)个子图相加得到的。 随着子图数量的增加,近似图越来越清晰。作为比较,同时也给出了用PCA的特征图进行重构的近似图,可以看到,2DPCA的效果要好于PCA。
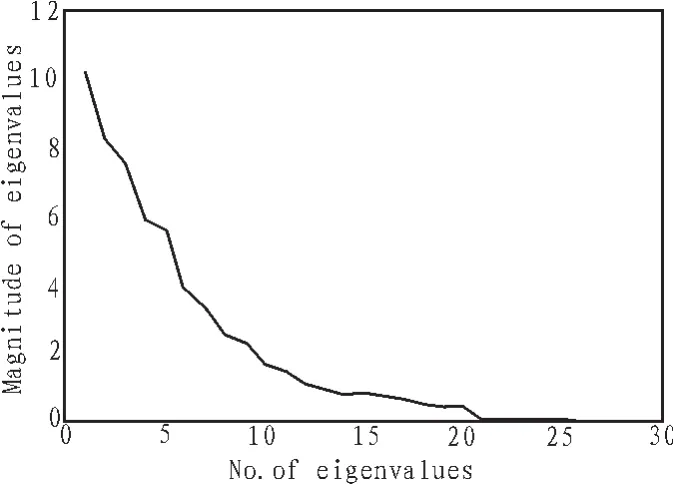
图3 降序排列的特征值幅度图Fig.3 Plot of the magnitude of the eigenvalues in decreasing order

图4 部分基于2DPCA(第一行)和PCA(第二行)重构图Fig.4 Some reconstructed images based on 2DPCA (upper)and PCA (lower)
完成了字符的特征提取,接下来对测试样本进行识别实验。实验中分类器分别采用最近邻法 (Nearest Neighbour Method)和重构误差法(RMEM),识别结果如表1所示。作为比较,表1除了PCA外,还给出了其他常用的分类器的识别结果及计算耗时。
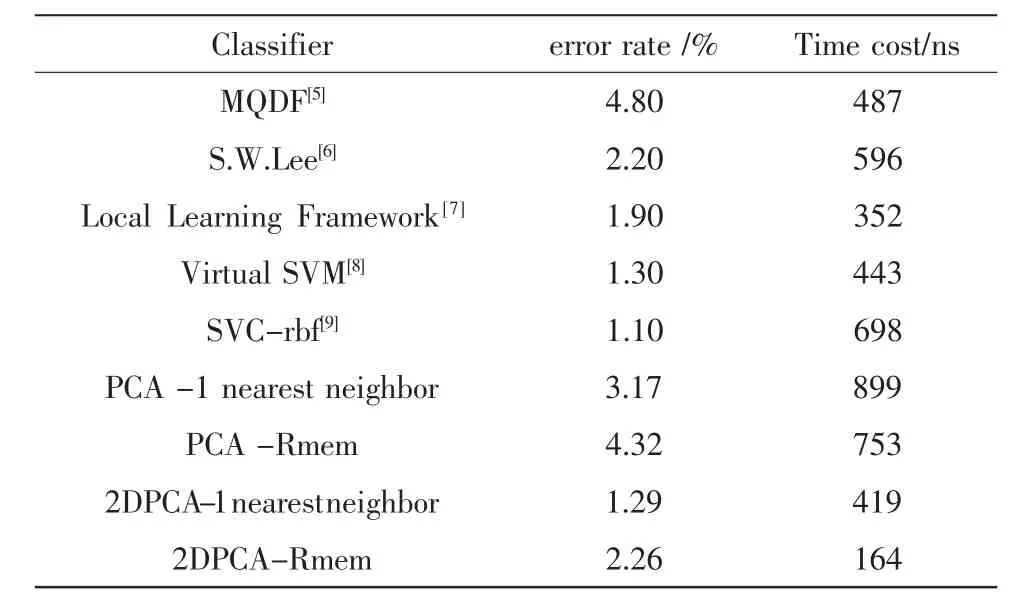
表1 常用方法相比较Tab.1 Contrast with traditional methods
从实验结果可以看出,无论是PCA还是2DPCA,采用最近邻法 (1-nearest neighbor)识别效果要优于重构误差法(Rmem),但重构误差法的计算时间要明显少于最近邻法,而且2DPCA-Rmem耗时是所有分类器中最少的。
2DPCA优于PCA的原因,主要有两条:1)2DPCA的图像协方差矩阵比较小,所以计算精度要高于PCA;2)重构原始样本时所用的参数比PCA要少很多。
在和未作“骨架提取”与“膨胀”预处理的字符识别的对比实验中发现,通过图像预处理对字符笔画粗细进行规范后,对各字符的识别率平均提高了大约2个百分点。
总体而言,在表1所示的识别方法中,2DPCA的识别率并不是最高的,这是因为2DPCA是基于统计规律,采用的是单一分类器,要想进一步提高识别精度,就必须利用字符的结构特征来构造分类器,并将两类分类器结合起来进行识别。不过就计算速度而言,2DPCA具有明显的优势,比较适用于某些实时性要求较高的场合。
5 结 论
文中提出了一种基于2DPCA的手写字符识别方法:针对手写字符书写随意,字符笔画形态结构不稳定的特点,提出首先采用数学形态学方法对字符笔画的粗细特征进行规范,保证了字符笔画粗细的一致性,同时也使字符部分细节的一致性得到改善;在通过图像预处理得到相对稳定的模式后,利用2DPCA抽取字符特征,在相应基向量张成的特征空间里对字符的重建模型进行估计,并利用重建误差及最近邻法对字符进行识别。从实验结果看,该方法在准确率和计算耗时方面有明显的提高。从理论上讲,训练集的规模越大越好,但从实验中发现训练集规模达到一定程度时,本算法的识别率已很高且稳定,初步观察发现它所要求的训练集规模比其他方法相对要小,这样就会节省不少训练时间。在进一步的研究中将考虑结合其它字符形态矫正预处理方法,使字符模式更加稳定,以进一步提高字符识别率。
[1]YousefAO,CherietM.Databasesforrecognitionof handwritten arabic cheques[J].Pattern Recognition,2003(36):111-121.
[2]Juan A,Vidal E.On the use of Bernoulli mixture models for text classification[J].Pattern Recognition,2002,35 (12):2705-2710.
[3]Hu J,Yan H.Structural primitive extraction and coding for handwritten numeralrecognition[J].Pattern Recognition,1998,31(5):493-509.
[4]Hsu Chih-wei,Chang Chih-chung.A practicalguide to support vector classification [EB/OL](2010-04-15).http://www.csie.ntu.edu.tw/~cjlin/.
[5]LeCun Y,Jackel L.Learning algorithms for handwritten digitalrecognition [J].Int’L Conf1 ArtificialNeural Networks1 Paris.AI Computer Press,1995(1):53-60.
[6]Seong-Whan L.Multilayer cluster neural network for totally unconstrained handwritten numeral recognition[J].Neural Networks,1995,8(5):783-792.
[7]DONG Jian-xiong,Krzy’zakb A,Suen C Y.Local learning framework for handwritten character recognition [J].Engineering Applications of Artificial Intelligence,2002,15(2):151-159.
[8]ZHANG Bai-ling,FU Min-yue,YAN Hong.Handwritten digit recognition by adaptive-subspace self-organizing map[J].IEEE Trans Neural Network,1999,10(4):589-603.
[9]Teow L N,Loe K F.Robustvision-basedfeatures and classificationschemes for off-linehandwritten digit recognition[J].Electronic Design Engineering,2002,35(11):2355-2364.
