基于R的过采样方法在非平衡数据中的应用
2012-09-19苏加强丁柳云
苏加强 丁柳云
(1.宁德职业技术学院计算机系,福建 宁德 355000;2.宁德职业技术学院教务处,福建 宁德 355000)
1 背景
R是一个有着统计分析功能及强大制图功能的软件系统,是由奥克兰大学统计学系的Ross Ihaka和Robert Gentleman共同创立的。该软件属于GNU系统的一个自由、免费、源代码开放的软件,用于统计计算和统计制图。R以包的形式内建多种统计学及数字分析功能,透过安装套件Packages增强。KDnuggets曾调查了实际项目使用了哪些数据挖掘软件,底层语言使用频率最高的依旧是 R语言、SQL、Java和Python。而从软件工具角度上看,R、Excel和RapidMiner则名列三甲。
传统的分类实验中,都假定学习的数据集为分布平衡的,即数据集中各类样本的数目大体一致。但是在现实情况中平衡数据集几乎是不存在的。在真实世界中,通常标号不同的类所含有的样本数目是不等的,甚至有着很大的差别,这样的数据集为不平衡数据集。
在不平衡数据集的分类学习过程中,少数类样本被误分的几率通常要高于多数类。现实应用中,少数类样本通常比多数类样本重要,故少数类被误分所带来的损失相对较大。因此,对不平衡数据分类的研究就致力于提高数据集中少数类的识别效率,以减少少数类被错分所带来的损失。
2 数据挖掘任务和所用数据
一些公司售货员要报告商品的交易情况,公司需检测售货员所提交的交易情况报表中的异常值,目的是检查售货员所提交的交易报表中的异常现象,给出一种异常概率排序,该排序可以让公司以优化的方法应用于检查工作。售货员出售公司产品,每月末,售货员需向公司提交交易情况。售货员可以根据营销策略和市场情况自由设定产品的交易价格。数据挖掘应用的目的是帮助公司根据过去的检测错误和异常交易报表的经验来核实报表的真实性,提供交易报表异常概率排序,此排序使公司将有限的检查资源用于系统给出的可疑报表。
如,以某公司售货员提交的交易报表为分析数据,数据总共401 146行,每行信息包括售货员ID(ID)、产品 ID(Prod)、产品数量(Quant)和总价(Val)。这些数据已经通过公司的一些分析,并把分析的结果显示在最后一列(Insp)。Insp可能有以下情况:ok,即交易被检查并认为有效;fraud,即交易被发现是异常的;unkn,即交易未检查。
R语言中提供一个包DMwR,里面有需要的数据。首先通过以下命令加载包和数据。
然后查看sales数据的前6行,如表1所示。
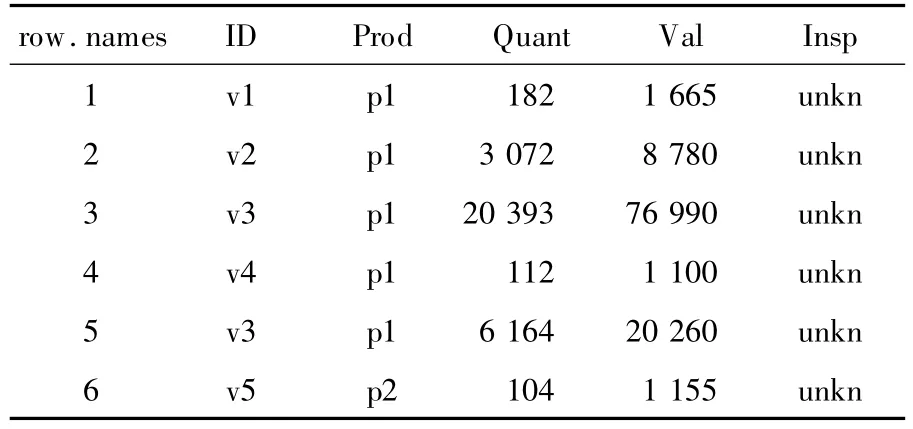
表1 实验所用数据结构
数据集报表中正常和异常的比例非常不平衡,异常报表为少数,只有8.1%。在获取预测模型的任务中,这种类型的问题可以导致各种困难。首先,它们需要恰当的评定指标,因为本领域中标准误差是明显不足的。实际上,应用可较易得到大约90%的精确度。类型不平衡的另一问题是对缺少统计的支持而趋向忽略少数类的学习算法的性能有强烈的影响。应用中,重点研究对象是不平衡数据集中的少数样本时,就特别成问题。
3 朴素贝叶斯和ORh方法
3.1 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是基于贝叶斯定理的概率分类器,其严格限定预测器之间的独立性。这些限定很少适用于真实世界的问题,所以命名为朴素。
贝叶斯定理:
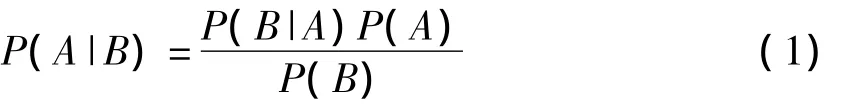
使用这一定理,朴素贝叶斯分类器用式(2)计算给定测试集用例每个类的概率:
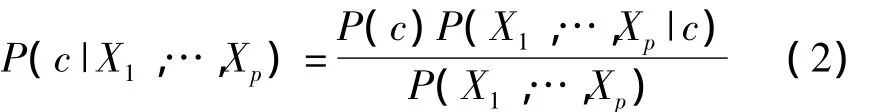
c为一个类;X1,…,Xp为给定测试用例预测器的观察值;P(c)的概率可以视为类c的先验期望;P(X1,…,Xp|c)是类c中给定测试用例的似然;分母是观察证据的概率。用式(2)计算所有可能的类的值来判定测试用例的最可能的类,这一判定取决于式(2)的分子,因为分母在所有的用例中是常量。利用条件概率和预测器间朴素的条件独立的统计定义,把分数的分子变为:
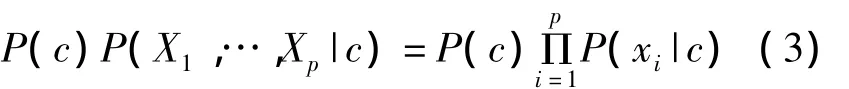
朴素贝叶斯使用相对频率评价训练样本的概率,使用这些评价,根据式(2)输出每个测试用例的类概率。
R有几种方法实现朴素贝叶斯方法,它们分别是:使用包e1071中的函数Naive Bayes();使用朴素贝叶斯来获得报表测试集的排序值;使用给定训练样本中检查过的报表来建立一个朴素贝叶斯模型。


从Hold-out程序中调用函数,获得朴素贝叶斯预测器的选择评价统计。

最后,调用holdOut()函数来执行此模型的实验。

3.2 ORh方法
基于聚类算法ORh方法,使用层次凝聚聚类算法来获得给定数据的系统树图,系统树图是聚类方法融合过程的可视化表现形式。不同高度等级的消减树产生数据的不同聚类,在最低等级有个解,给定的训练集数据中每个观察值都是一个组,这是这个模型迭代算法的初始解。算法的下一步是决定前面第一步中哪两组合并成一个简单聚类,这个融合过程被试图把彼此间有相似性放到一起的准则操纵,直到所有观察值的最后两组被合并成一个简单聚类迭代过程才停止,基本包stats中函数hclust()实现了这种类型的聚类方法。
朴素贝叶斯模型对10%检查结果如表2所示。
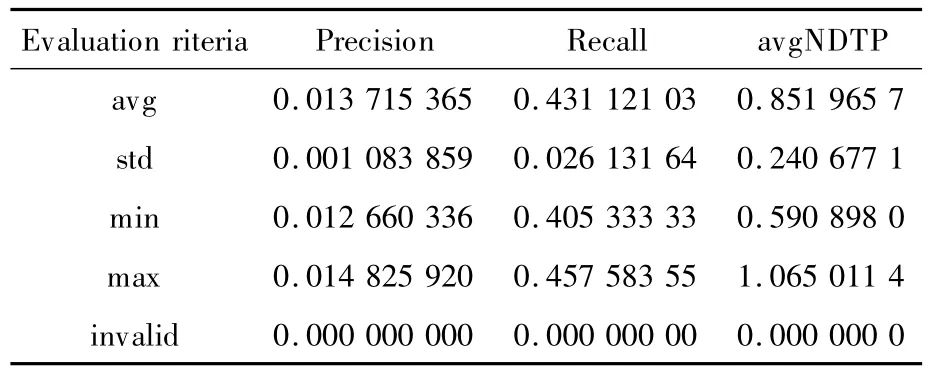
表2 朴素贝叶斯模型对10%检查结果
与未监督式ORh方法获取的最好的分数相比,就查准率和查全率而言结果不理想。图1清晰地显示,在本应用中,朴素贝叶斯方法劣于ORh方法。
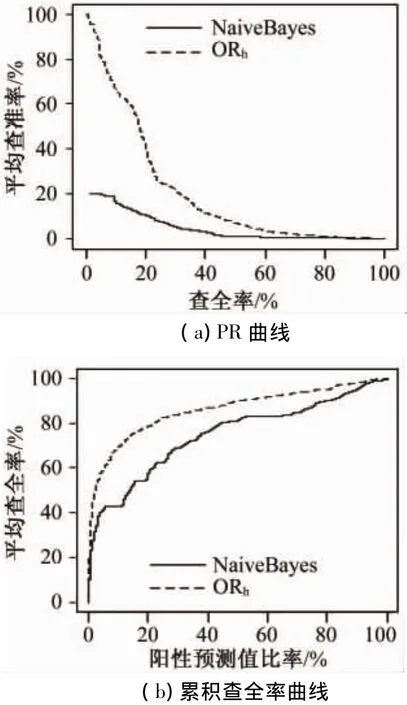
图1 朴素贝叶斯和ORh性能对比图
4SMOTE算法及应用
用于帮助学习算法克服类型不平衡问题的技术通常可归为两类:一类是倾向于用对少数类采样敏感的特别的评定指标评定学习过程;另一类是处理训练数据来改变类型分布的采样方法。在使用监督式分类方法的尝试中,使用第二类方法。
有多种采样方法可以改变一个数据集的类型不平衡。如,欠采样方法(Under-sampling methods),即选择多数类的一小部分,并添加到少数类用例中,因此建立一个平衡类分布的数据集;过采样(Over-sampling),即用一些方法来重复少数类采样。然而以上方法的许多变种已经存在。由Chawla等人提出的SMOTE(Synthetic Minority O-ver-sampling Technique)算法是一种成功的采样方法,该方法的主要思想是利用k近邻和线性插值,在相距较近的两少数类样本间按照一定的规则人为地插入新的样本,以达到使少数类样本数目增加,数据集趋于平衡的目的。基本思想是用样例的最近邻居人为地产生少数类的新样本,而且多数类样例也是欠采样的,产生一个平衡的数据集。
使用函数SMOTE()实现这种采样方法,给定一个不平衡的采样,此函数产生一个较平衡类分布的新的数据集。

用iris创建一个带有两个预测变量和一个未平衡类分布的目标变量的人工数据集。调用函数SMOTE()时,变量perc.over赋值为600,即在属于少数类的初始数据集的每个用例中创建6个采样。这些新的用例通过用例和其最近领域之间的随机插值创建。图2为原始数据信和使用SMOTE后的数据集。
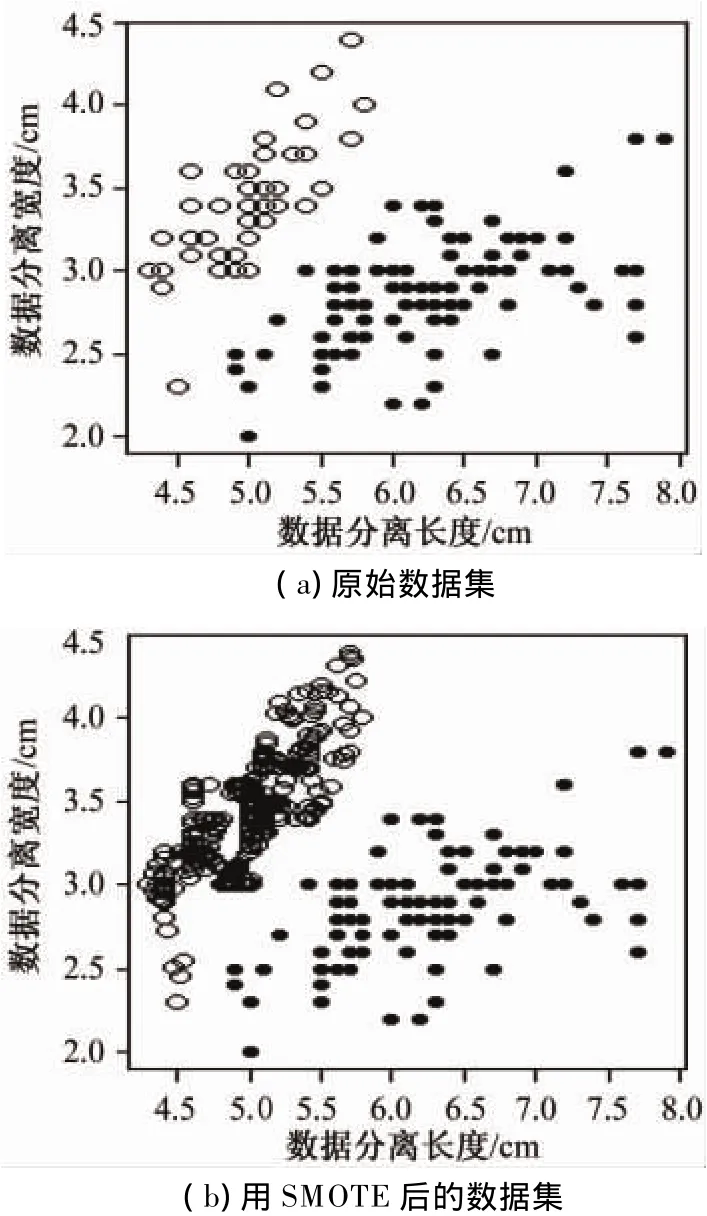
图2 原始数据集和使用SMOTE后的数据集图
在监督式分类算法中,使用此方法的变形。首先用SMOTE方法获取的训练集来应用朴素贝叶斯分类器,然后用修改后的训练集应用于navieBayes()函数来获得异常值排序。

下面的语句获得SMOTE版本的朴素贝叶斯Hold-out评价。

5 结果评价
此版本朴素贝叶斯模型对10%检查的结果如表3所示。
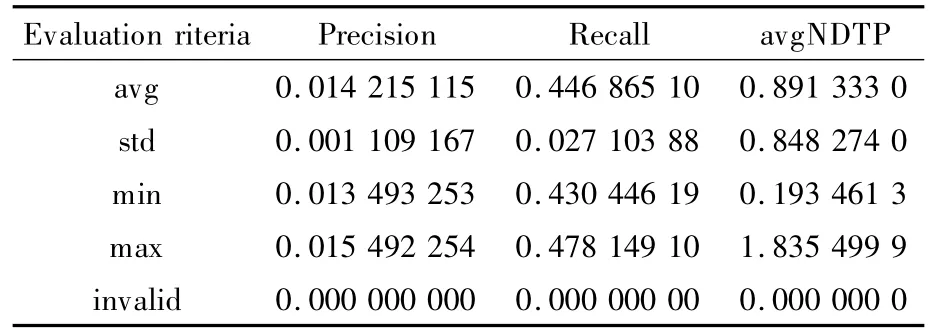
表3 SMOTE方法的朴素贝叶斯模型检查结果
此结果与正常朴素贝叶斯结果基本相同,结果稍好,但仍低于未监督式方法的最好结果。尽管SMOTE方法对少数类过采样,朴素贝叶斯依然不能正确地预测哪些是异常的报表。用图形方式以全局的视角来查看此变种方法的性能,如图3所示。
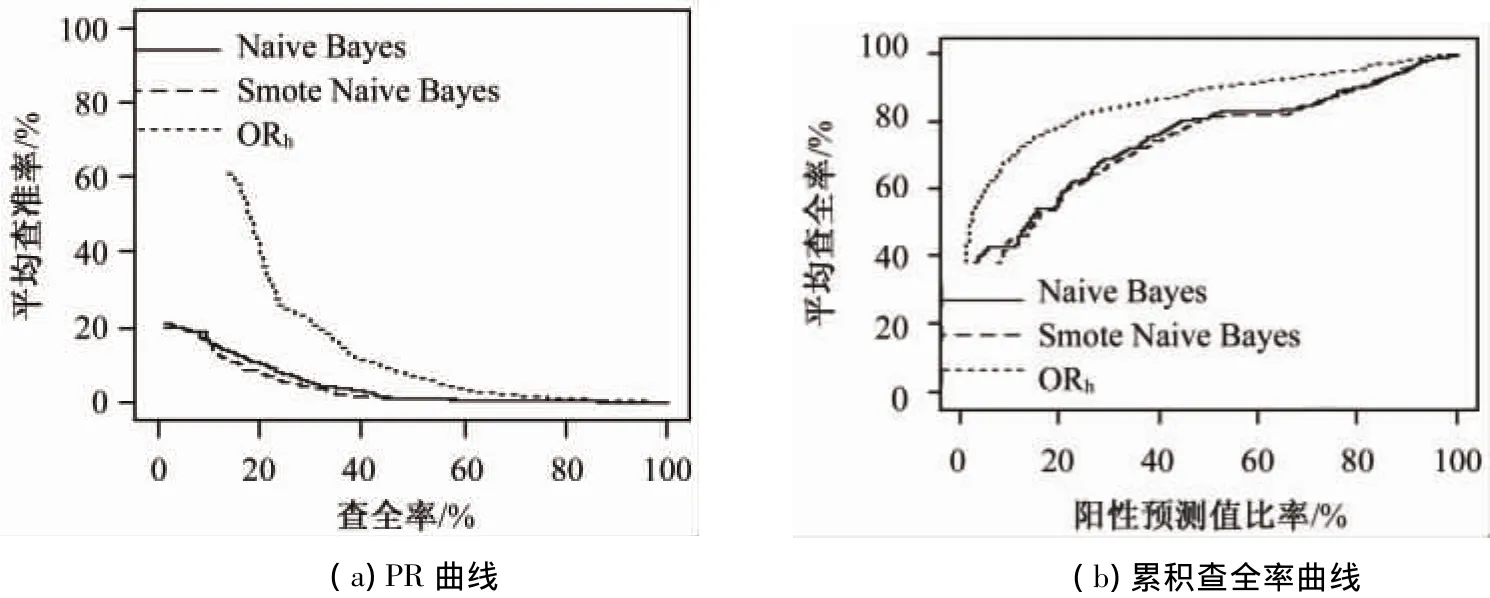
图3 性能对比图
SMOTE算法提出前,对非平衡数据的处理一般采用随机采样方法,SMOTE算法在相距较近的少数类之间人为地增加其虚拟样本,在某种程度上规避了过学习的问题,提高了数据集的分类性能。
[1]Chawla N.The Data Mining and Knowledge Discovery Handbook:Data Mining for Imbalanced Datasets[M].Heidelberg:Springer,2005:853 -867.
[2]Seeger M.Technicalreport:Learning With Labeled and Unlabeled Data:Institute for Adaptive and Neural Computation[J].U-niversity of Edinburgh,2002:5 -27.
[3]Sing T,Sander O,Beerenwinkel N.ROCR:Visualizing the Performance of Scoring Classiers.R Package Version 1.0 - 4[J].Heidelberg:Springer,2012:2 - 10.
[4]Breunig M,Kriegel H,NG R.Management of Data:LOF:Identifying Density-based Local Outliers[M].New York ACM,2000:93-104.
[5]Chambers J.Software for Data Analysis:Programming With R[M].Heidelberg:Springer,2008:166 -221.
