面向Weblog的模糊协同聚类算法
2012-09-19陈恩红刘仁金
宗 瑜 金 萍 陈恩红 李 红 刘仁金
①(中国科学技术大学计算机科学与技术学院 合肥 230036)
②(皖西学院信息工程学院 六安 237012)
1 引言
近年来,Web技术的迅猛发展使互联网成为信息发布与共享的重要平台[1]。由Web应用产生的海量数据使得用户使用信息的效率下降的现象被称为信息超载。推荐引擎是解决信息超载的有效方法,包含基于决策规则的过滤、内容过滤、协同过滤及Weblog挖掘4种类型。Web聚类是Web信息挖掘的重要内容,通过对Web数据重组使有意义的数据聚集成簇,从而达到信息检索和信息表示等目的[2-5]。在Weblog挖掘中,Web聚类可以分为Weblog用户聚类和Weblog页面聚类。Weblog用户聚类旨在从用户的访问行为中发现用户行为模式、分析用户之间的关联关系。每个用户的访问会话是由(页面,权重)对组成的,而该对信息反映了用户对不同页面的兴趣程度,因此对用户会话执行聚类将会发现能反映用户行为模式的会话簇。文献[6]调用传统的K-means算法对用户会话进行聚类发现具有相似行为的用户会话,以实现个性化推荐。Xu等人[7]首先利用概率语义分析模型对Weblog数据进行语义分析,产生语义空间S';然后将Weblog数据映射到S'中,最后调用K-means算法在S'中对Weblog数据进行聚类,产生用户访问模式。Weblog页面聚类从Web页面的侧面考虑Weblog信息挖掘,旨在发现具有相似功能或语义的页面簇。文献[8]详细地阐述了基于Snippet的页面聚类算法实现。文献[4]对单一文本执行层次聚类,以实现搜索结果的汇总。不论是Weblog用户聚类,还是Weblog页面聚类,都仅反映了Weblog数据某个侧面的信息。在某些应用中,Weblog的聚类结果往往是由协同出现的用户和页面组成,即同簇中的用户仅对某些页面子集感兴趣,而且同簇中的页面仅被某些用户关注。因此,同时发现用户簇及与之对应的页面簇,对实现Weblog行为模式和更新页面设计具有重要的意义[7,8]。Xu等人[9]2010年给出了一种针对Weblog的协同谱聚类算法SCC(Spectral Co-Clustering),该算法首先将“会话-页面”之间的关系用二分图表示;然后调用协同谱聚类算法发现其中的聚类结果C={CSk,CPk},k=1,…,K,其中CSk为会话或用户聚类结果,而CPk则是与之相对应的页面聚类结果。为了降低Weblog数据稀疏性对算法的影响,Zong等人[10]给出了基于语义分析的协同聚类算法COCS(Co-Clustering in Semantic space)。COCS算法框架首先利用概率隐形语义分析(PLSA)模型学习Weblog的语义空间;然后再将Weblog数据映射到该语义空间;最后执行谱协同聚类算法发现与之对应的聚类结果。
现有的面向Weblog的协同聚类算法大多采用硬划分方法,以发现具有共现特征的聚类结果,即用户和页面要么属于某个聚类结果,要么不属于任何聚类结果。硬划分方法虽然可以发现数据中隐含的聚类结果,但是不能很好地处理聚类边界的问题。由于SCC[9]和COCS[10]聚类算法在不同的属性空间中,采用硬划分方法对用户和页面进行聚类,因此,这两种算法的聚类质量都会受到聚类边界的影响。因此,本文给出了一种模糊协同聚类FCOW(Fuzzy CO-clustering for Weblog)算法。该方法首先利用Hadamard积来发现Weblog数据中不同的用户模式PA={pa1,…,paK};然后依据独立模式包含的页面子集,将剩余用户分配给不同的用户模式,组成协同聚类结果C={CSk,CPk},k=1,…,K;最后计算协同聚类结果中模式与页面之间的模糊关联关系,产生关联关系矩阵。在3个实际数据的实验结果显示,FCOW算法的精度和覆盖率均优于其他比较算法。
2 符号约定及背景知识
本节我们首先给出了相关的符号约定。
给定n个页面P={p1,…,pn}和m个用户会话S={s1,…,sm}。由于用户兴趣可以用不同权重的页面描述,因此,每个用户会话si∈S被定义为si={ai1,…,ain},m个用户会话向量构成了“会话-页面”矩阵SP={aij},其中aij,j=1,…,n表示页面pj在si中的权重。表1给出了SP矩阵的例子。
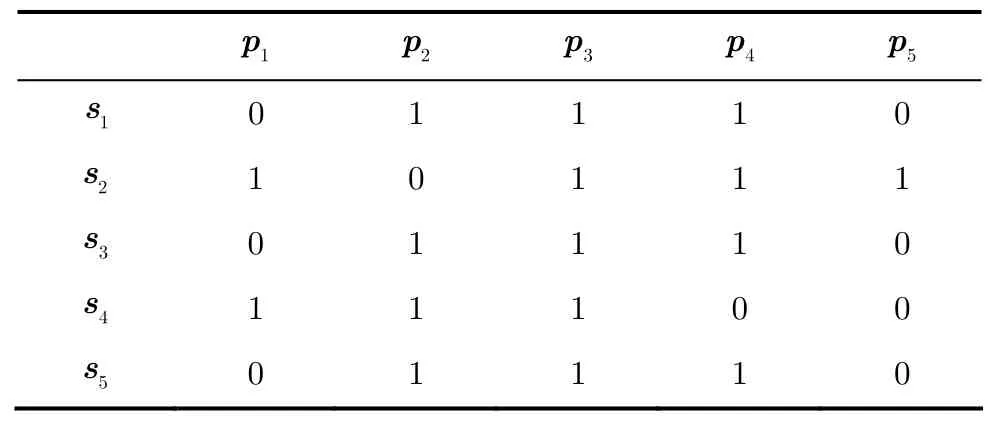
表1 会话-页面矩阵例子
本文的目的是从SP矩阵中发现其中具有共现特征的聚类结果,即C={CSk,CPk},k=1,…,K,其中CSk的会话记录仅在CPk子集上相似。例如,表1所示的用户访问记录中包含的协同聚类结果如表2所示。

表2 表1中包含的协同聚类结果
本文涉及的相关符号及其意义如表3所示。

表3 符号约定
3 模糊协同聚类算法FCOW
模糊协同聚类算法主要由模式提取、页面分配及隶属度值计算等步骤组成。本小节将对这些部分进行详细的阐述。
3.1 模式抽取与隶属度定义
本文考察的“会话-页面”矩阵中元素aij∈{0,1},表示用户i是否对页面j进行访问操作,若访问,则aij=1,否则aij=0。为了抽取SP矩阵中抽取出不同的模式,本文采用矩阵Hadamard积来完成。矩阵Hadamard积如定义1所示。
定义1(Hadamard积)给定两个矩阵Am×n和Bm×n,它们的Hadamard积就是分素乘积(entrywise product),定义为?(A°B)ij=(A)ij⋅(B)ij,i=1,…,n;j=1,…,m。
SP矩阵中每一行都代表一个用户会话si={ai1,…,ain},而用户访问页面的兴趣隐含在这些会话中,因此,本文采用行与行的Hadamard积来捕获用户的访问兴趣。我们通过计算每个会话si与其他m-1个会话的Hadamard积的方法来完成这个目标,但是m个会话的Hadamard积计算十分耗时,且需要大量的存储空间。为了降低时间和空间消耗,本文采用贪心方法来实现该目标:首先,从m个会话中选择非零分量最多的会话si;然后,计算该会话与其他m-1个会话之间的Hadamard积,产生SP的Hadamard积矩阵H;最后利用独立模式(如定义2)捕获用户的访问兴趣。
定义 2(独立模式)给定生SP的 Hadamard积矩阵H,SP的独立模式PA={pa1,…,paK},其中pak,k=1,…,K定义为:pak={pj|ifH(i,j)==1,i=1,…,m;j=1,…,p},其中H(i,j)为H的第i行第j列元素。
表1所示的SP矩阵中隐含的独立模式如表4所示。
从表4中可以看出每个模式的页面子集与表2所示的相关协同聚类结果中的页面子集相同,而且用户聚类个数与模式个数相同。这个现象说明,Hadamard积发现的独立模式与聚类结果之间存在着比较直观的联系。因此,本文以每个模式所对应的页面子集为基准,按照定义3来发现与之对应的用户聚类。
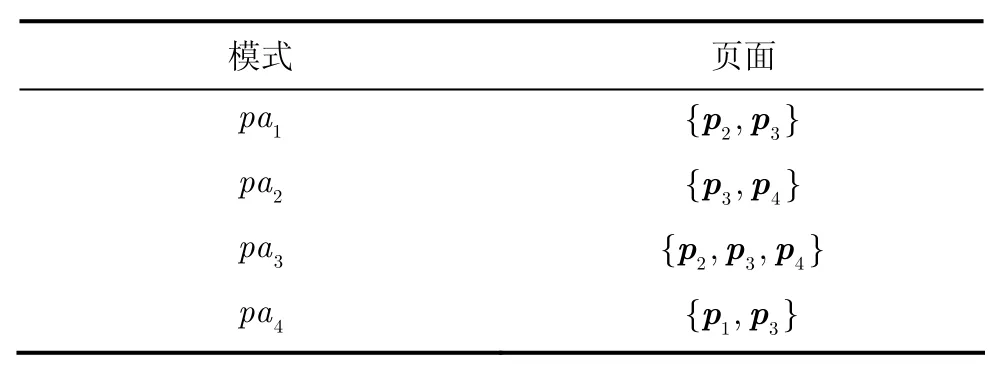
图4 Hadamard积方法产生的独立模式
定义 3(聚类定义)给定模式pak∈PA,k=1,…,K,本文定义pak包含的页面为第k个页面聚类CPk,那么与之相对应的用户聚类CSk定义为
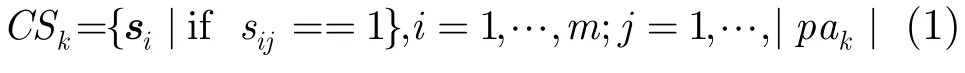
其中|pak|表示第k个页面子集包含的页面数。
本文通过计算每个会话和页面与协同聚类结果C={CSk,CPk},k=1,…,K之间的隶属度来刻画它们之间的关联程度,实现软聚类的目的。
定义 4(用户隶属度)给定协同聚类结果C={CSk,CPk},k=1,…,K,m个用户与CSk会话聚类之间的隶属度由如下公式定义:
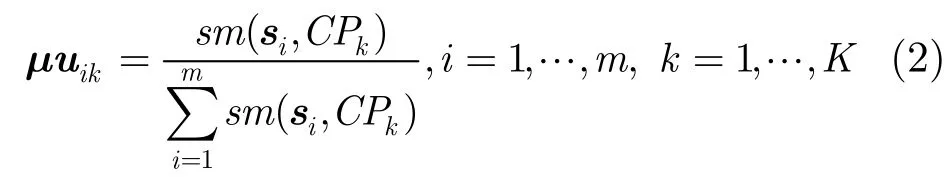
其中si∈SP是SP中第i个会话,sm(si,CPk)是会话si与页面聚类CPk的相似度,通常用向量的余弦相似度来计算[6]。
定义 5(页面隶属度)给定协同聚类结果C={CSk,CPk},k=1,…,K,n个页面与CSk会话聚类之间的隶属度定义为

其中pj∈SP是其中第j列向量,即页面j。
3.2 模糊协同聚类算法框架
模糊协同聚类算法 FCOW(Fuzzy CO-clustering for Weblog)由3部分组成:(1)利用贪心方法计算SP的Hadamard积矩阵,并由定义2发现其中隐含的独立模式;(2)在独立模式的基础上,发现会话聚类和页面聚类结果;(3)利用迭代更新方法计算每个会话与会话聚类之间的隶属度和每个页面与会话聚类之间的隶属度。具体流程如表5所示。

表5 模糊协同聚类算法流程
步骤(1)首先计算SP的Hadamard积矩阵H,确定其中的独立模式PA及其对应的页面子集;步骤(2)依据定义3,确定与页面子集相关的会话聚类,从而形成了协同聚类结果C={CSk,CPk},k=1,…,K;步骤(3)则是页面隶属度矩阵的初始值设定;步骤(4)-步骤(6)迭代地执行页面隶属度矩阵的更新操作,直到最近两次更新值的差小于给定阈值ε,其中m'为模糊因子,通常情况下m'=2。参数minp为与独立模式相关的最小页面数。本文首先统计SP矩阵中每个会话中权重为1的页面数,然后取m个会话的平均页面数为minp的值设定。
3.3 时间复杂度分析
算法FCOW的步骤(1)需要考虑m对会话之间的Hadamard积,而每对会话的Hadamard积需要n次乘法运算,因此步骤(1)共需消耗O(m⋅n)时间。步骤(2)依据产生的独立模式,进行会话分配,产生会话聚类结果。每个会话都需要与K个页面子集进行比较分配,其总的时间消耗为O(m⋅K)。步骤(3)为每个页面分配初始隶属度,其最多时间消耗为O(n)。步骤(4),步骤(5)共同完成会话隶属度计算功能:首先,计算n个会话与K个会话聚类之间的相似度,需要耗时O(n⋅K),然后根据定义(3)计算会话相似度需要O(m⋅K)时间。步骤(6)更新n个页面与会话聚类之间的隶属度消耗O(n)时间。假设步骤(4)-步骤(6)共迭代允许了λ次,那么FCOW算法的总的时间消耗为O(m⋅n)+O(m⋅K)+O(n)+λ⋅(O(m+n)⋅K+O(n))。
4 实验及分析
本节在3组实际数据集上对比了算法FCOW,SCC[9],COCS[10],CCMD(Co-Clustering using Matrix Decomposition)[11],RB (Robust Biclustering)[12]及模糊聚类算法FWLC (Fuzzy Web Log Clustering)[13]的算法性能。FCOW及5种对比算法均由Matlab 7.0编程语言实现,并在Intel 2.0/ 4 GM/250 G兼容机、windows XP环境下执行。
4.1 评价标准及参数设置
由于我们需要利用协同聚类结果进行推荐,因此本文采用信息检索领域的传统评价标准精度和覆盖率作为对比算法的评价标准。本文的推荐过程描述如下:对t时间窗口内的用户si,首先,发现与新用户si具有最大相似度的用户sj;然后,从用户隶属度矩阵μu中推荐p≤K个相似聚类CS1,…,CSp;再根据页面隶属度矩阵μp所描述的页面与聚类结果之间的关联关系,为每个聚类CSk,k=1,…,p推荐pr个页面,从而形成推荐集合R。本文通过实验方法设置p=K/2,pr=10。
定义6给定t时间窗口内用户si的访问记录集合T,及由聚类结果产生的推荐集合R,精度定义为:
定义7给定t时间窗口内用户si的访问记录集合T,及由聚类结果产生的推荐集合R,那么覆盖率定义为:
由定义6,定义7可以看出,精度标准度量了推荐子集R的推荐精度,而覆盖率则衡量了推荐结果被用户使用的频度,因此,精度和覆盖率的值越高,说明由本文提出的聚类算法的质量就越高,对个性化推荐的支撑作用越好。
4.2 实验数据集
本文在5个实际数据集上对比6种比较算法。CTI.STD数据集是从Depaul CTI Web Sever (http://www.cs.depaul.edu)网站收集的2002年4月份前2个星期访问该站点的所有用户访问记录集合。经过处理,CTI.STD数据集包含了13,745个用户向量,每个用户向量由683个属性描述。其中一个用户可以拥有多个会话,而每个属性表示一个页面。用户向量中包含了非零和零两类数值(零表示用户没有访问该页面,而非零则反映了用户访问该页面的次数,本文把所有的非零数值用1代替)。CSD数据集是2003年10月到2004年3月期间访问AUTH大学信息学院网站(http://www.csd.auth.gr)的weblog数据。经过预处理后,CSD包含了373个用户,而每个用户由255个页面描述。MUMA数据集则是访问Hyperreal音乐网站(http://hyperreal.org/)的Music Machines(http://machines.hyperreal.org/)的用户访问数据。经过预处理之后,MUMA数据集共包含265个用户,每个用户则有127个页面属性描述。Amazon2011数据集是由UCI于2011年9月份发布的Amazon网站的访问记录。由于本文在用户-页面矩阵中研究模糊协同聚类,以发现其中隐含的兴趣模式,因此,我们对该数据集进行预处理,最终保留15,596个用户,每个用户由729个页面描述。而TechCmantiX数据集则是2010年7月到12月期间访问www.techcmantix.com的用户数据,经过预处理后,本文保留了12,599个用户,每个用户由698个页面描述。
4.3 实验结果及其分析
图1给出了6种对比算法在5个不同实际数据集上的精度值对比。精度反映了个性化推荐的准确程度,其值越高,说明由算法给出的推荐越好。从图1的6条变化曲线中,我们可以发现,算法FCOW的精度值变化曲线始终处在最高处。这个现象说明以FCOW算法结果为基础的个性化推荐精度是6种对比算法中最好的,即使在包含了大规模高维数据集(15,596×729)Amazon2011上,其精度值也在0.8以上。这个现象说明,采用模糊策略的FCOW算法的聚类结果有效地解决了边界问题,克服了SCC,COCS,CCMD和RB算法存在的固有缺陷。FWLC算法采用模糊概念解决硬划分聚类算法无法处理边界问题,但是由于该算法直接采用了经典模糊聚类算法FCM作为子方法,无法实现高维Weblog数据的协同聚类目的。因此,从图1中可以看出,该算法的精度值曲线在5个数据集中始终处于最下面。同时,从图1中还可以看出,算法FCOW在5个数据集上的精度值曲线基本保持不变。该现象说明,采用Hadamard积运算可以准确地发现数据集中隐含的独立模式及其对应的页面子集,而其他对比算法都不具备这样的能力。
图2是6种对比算法在5个实际数据集上的覆盖率值对比。从定义7可以看出,覆盖率体现了以聚类结果为基础的个性化推荐被用户使用的比例,其值越高,说明推荐结果被用户接受的程度就越高。从图中可以看出,6种算法在Amazon2011数据集上的覆盖率值都小于在其他4个数据集上的覆盖率值。造成这个现象的原因是由于描述该数据集的属性个数比较多(729个页面),矩阵十分稀疏,从而影响了算法的性能。但是算法FCOW在该数据集上的覆盖率值接近 0.91,远远高于其他对比算法在该数据集上的覆盖率值。同时,从图中还可以发现,FCOW算法在其他4个数据集上的覆盖率值也远远高于对比算法的覆盖率值。图2的实验结果再次表明,以FCOW聚类结果为基础的个性化推荐结果的用户接受程度好于其他5种算法。

图1 6种算法在5个实际数据集上的精度值对比
图3给出了6种对比算法在5个实际数据集上的运行时间对比情况。从图中可以看出SCC,COCS,CCMD,RB及FWLC算法的时间消耗明显高于FCOW算法的时间消耗,这是因为,SCC,COCS,CCMD和RB中算法都是以图运算为基础的算法,其时间复杂度为O(m2)。而FWLC算法是以FCM聚类算法为子方法,因此该算法的时间消耗也是O(m2)。由于在FCOW算法中,本文采用贪心方法计算Hadamard积,从而达到了降低算法运行时间的目的,同时,用户隶属度与页面隶属度的计算时间仅仅与m和n成线性关系,因此,算法FCOW的时间消耗远远低于其他5种对比算法。
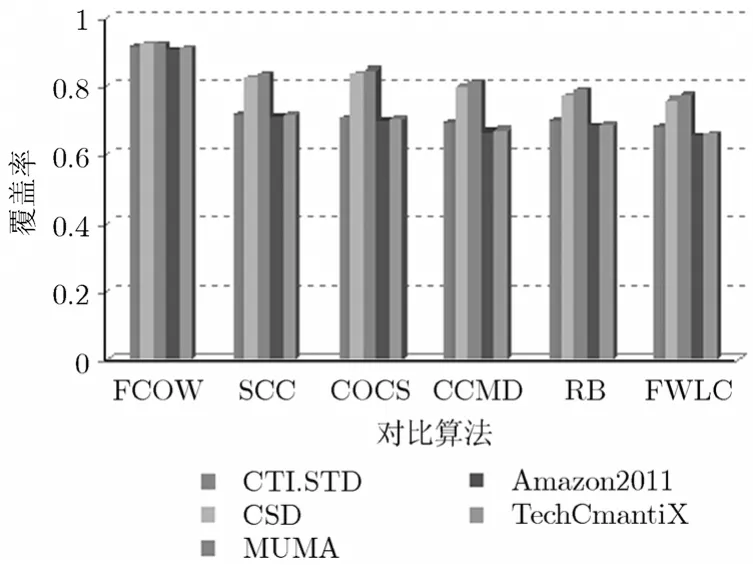
图2 6种算法在5个实际数据集上的覆盖率值对比
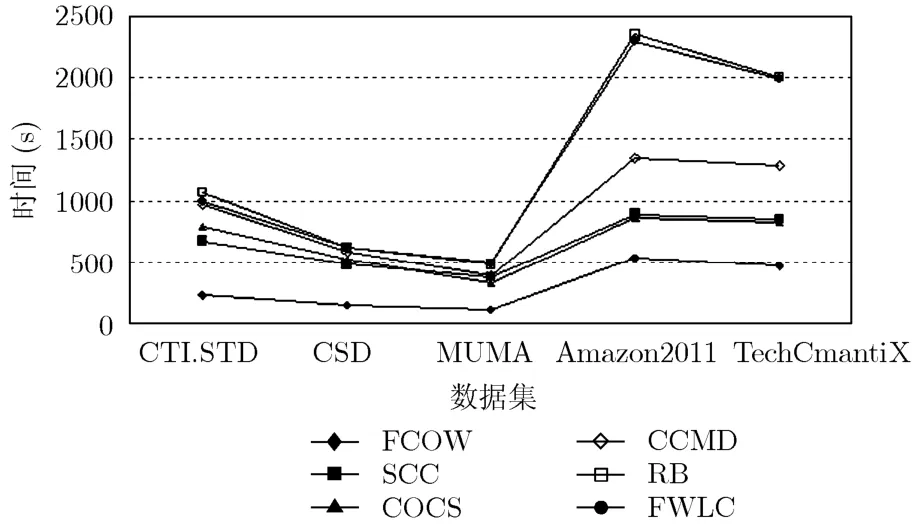
图3 6种算法在5个实际数据集上的时间消耗对比
5 结论
近年来,Weblog协同聚类成为Weblog信息挖掘的重要研究内容。现有的 Weblog聚类算法大多采用硬划分方法将用户和页面唯一地分配给协同聚类结果。硬划分方法的刚性要求使得聚类算法无法处理聚类结果边界问题,从而影响了聚类质量。本文给出了一种面向 Weblog的模糊协同聚类算法,该方法首先用Hadamard积识别Weblog中独立模式及其对应属性子集;然后以属性子集为基础,分配用户到对应的模式中,产生协同聚类结果;最后通过迭代计算用户与页面之间的模糊隶属度来产生模糊关联关系,并以此来做推荐。实验结果表明,本文提出的方法具有获得高质量协同聚类结果的能力。
[1]Zhang Y C,Yu J X,and Hou J.Web Communities:Analysis and Construction[M].Berlin Heidelberg,Springer,2006:1-45.
[2]Xu G D,Zhang Y C,and Li L.Web Mining and Social Networking:Techniques and Applications[M].Berlin Heidelberg,Springer,2010:127-156.
[3]Wang X and Zhai C.Learn from web search logs to organize search results[C].Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,New York,NY,USA,ACM,2007:87-94.
[4]Kummamuru K,Lotlikar R,Roy S,et al..A hierarchical monothetic document clustering algorithm for summarization and browsing search results[C].Proceedings of the 13th International Conference on World Wide Web,New York,NY,USA,ACM,2004:658-665.
[5]Flesca S,Greco S,Tagarelli A,et al..Mining user preferences,page content and usage to personalize website navigation[J].World Wide Web Journal,2005,8(3):317-345.
[6]Mobasher B,Dai H,Nakagawa M,et al..Discovery and evaluation of aggregate usage profiles for web personalization[J].Data Mining and Knowledge Discovery,2002,6(1):61-82.
[7]Xu G D,Zhang,Y C,and Zhou X.A web recommendation technique based on probabilistic latent semantic analysis[C].Proceeding of 6th International Conference of Web Information System Engineering,New York City,USA,2005,LNCS 3806:15-28.
[8]Ferragina P and Gulli A.A personalized search engine based on web-snippet hierarchical clustering[C].Special Interest Tracks and Posters of the 14th International Conference on World Wide Web,New York,NY,USA,ACM,2005:801-810.
[9]Xu G D,Zong Y,Dolog P,et al..Co-clustering analysis of weblogs using bipartite spectral projection approach[C].In Proceeding of the 14th International Conference on Knowledge-based and Intelligent Information and Engineering Systems (KES2010),Part III,Cardiff,Wales,UK,2010:398-407.
[10]Zong Y,Xu G D,Dolog P,et al..Co-clustering for Weblogs in semantic space[C].Proceeding of the 11th Conference on Web Information Systems Engineering (WISE’2010),Hong Kong,2010:120-127.
[11]Ling Y,Ye C Y,and Wei G Y.Fast Co-clustering on large datasets using matrix decomposition[J].International Journal of Intelligent Information Technology Application,2010,3(2):85-91.
[12]Inbarani H and Thangavel K.A Robust Biclustering Approach for Effective Web Personalization.Visual analytics and Interactive Technologies:Data,Text and Web Mining Applications[M].2011:186-201.
[13]Sudhamathy G and Venkateswaran C.Web log clustering approaches-a survey[J].International Journal on Computer Science and Engineering,2011,3(7):2896-2902.
