可加模型的序列相关性检验
2012-09-18乔静然
刘 锋,李 飞,乔静然
(重庆理工大学数学与统计学院,重庆 400054)
可加模型是Ezekiel首先提出来的一种重要的非参数模型。Breiman和 Friedman、Bujia、Hastie和 Tibshiran、Ansley和 Kohn以及 Opsomer和 Ruppert等[1-8]诸多学者研究了向后拟合算法的收敛速度。Stone[9]估计了可加模型的最优收敛速度。Wand[10]证明了局部多项式向后拟合算法估计量的中心极限定理。近几年来,也有许多学者致力于可加模型的研究,比如Jiang和Li给出了可加模型非参数部分的2阶段局部M-估计。综上所述,目前对于可加模型的研究都集中在模型的估计和收敛速度方面。在对模型进行估计之前,对模型进行序列相关性检验是十分必要的[11]。
对于一个拟合得好的模型,一般要求模型的残差项是一列独立同分布的白噪声,只有满足此假定,方可对模型进行估计。本文正是基于这方面的考虑,引入了VT,P方法对可加模型中的序列相关问题进行检验,得到了零假设下VT,P检验统计量的渐近分布,并用数值模拟验证了检验的功效。
1 方法与主要结果
考虑如下的部分线性单指标模型:
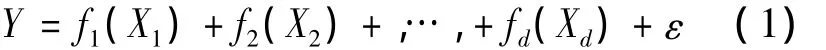
其中(X,Y)是独立同分布的随机变量。Xj(j=1,…,d)是X的第j个分量。X∈Rd,fj是未知函数。为了满足模型的可识别要求,令E(fj(Xj))=0,容易看出当fj(Xj)=βjXj时,式(1)其实就是多元线性回归模型。
本文用VT,P检验方法对模型(1)的序列相关性进行检验。首先构造VT,P检验统计量,令
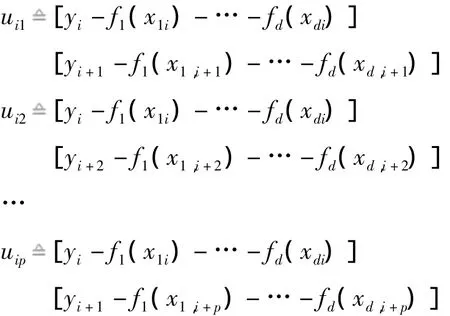
记T=n-p,根据Hu的研究得到了如下的VT,P检验统计量。但该式中含有未知函数fj(·),因而不能直接用于统计推断。这时,在零假设下分别用它们的估计(·)来代替。令
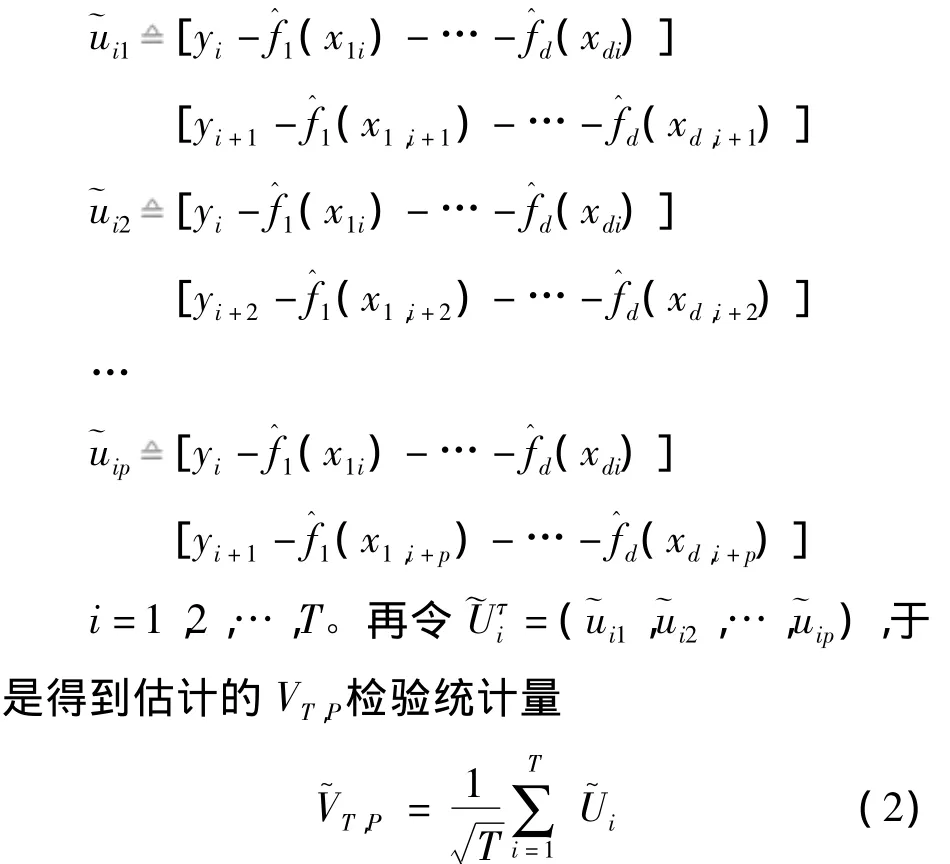
对于未知函数fj(·)的估计,采用局部多项式向后拟合算法来计算,其正规方程为
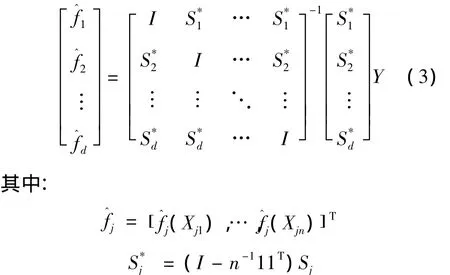
Sj是依赖于Xj1,…,Xjn的n阶局部多项式平滑器矩阵。当式(3)中的逆矩阵的维数比较大时,直接利用正规方程在普通的计算机上难以执行,于是本文采用局部多项式向后拟合算法来实现,步骤如下:
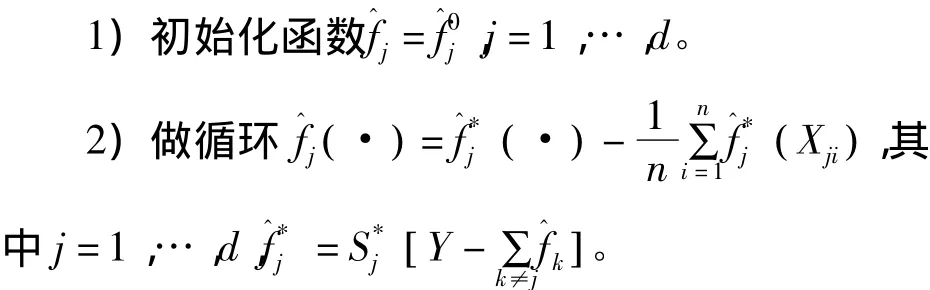
3)重复步骤2),直到收敛为止。
本研究为了得到主要结果,需要如下条件:
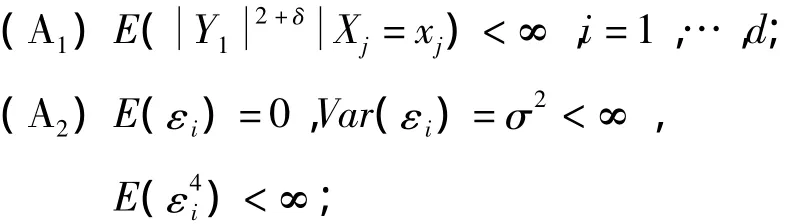
(A3)fj,i=1,…,d 是 p+1 阶连续可导的;
(A4)概率密度函数 fX1,X2,…,Xd和 fX1,fX2,…,fXd都是有界连续的,有紧支撑,并且
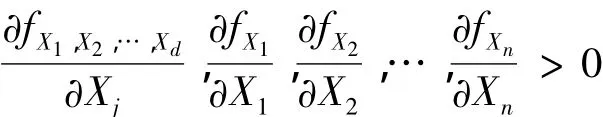
(A5)核函数K在它的支撑上是有界连续的,并且一阶偏导数大于0;
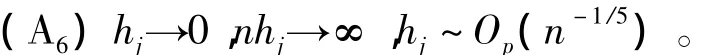
在上述条件下,有如下定理:
定理1 在条件A1~A6及零假设下,当T→∞时,有(0,σ2Ip),其中Ip是 p×p的单位矩阵,σ2=
2 数值模拟
通过一些数值模拟来考虑VT,P检验的有限样本性质。为了简单起见,考虑下面的模型:
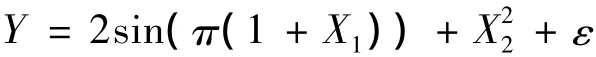
其中:ε与 X1、X2相互独立;Z1和 Z2服从U(-1,1);X1=Z1+Z2,X2=Z1- βZ2;β 为 Z1和Z2的相关系数。
假定误差εi分别服从如下模型:
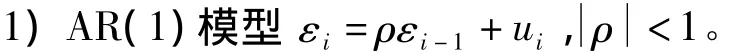

对于误差模型1和2,样本量分别选为50,100,200,显著性水平选为0.05;对于误差模型3和4,样本量分别选为100,200,400,显著性水平选为0.05,均做1000次模拟。模拟结果在表1~4中给出。

表1 检验size和功效,误差服从AR(1)模型

表2 检验size和功效,误差服从MA(1)模型

表3 检验size和功效,误差服从AR(2)模型

表4 检验size和功效,误差服从MA(2)模型
从表1~4中可以看出:当样本量小时,检验的size有偏大的现象,但是随着样本量的增加,检验的size迅速收敛到给定显著性水平;而在备择假设下,检验的功效都很好。同时也可以看出,在样本容量n相同的情况下,随着模型误差相依程度的不断加大,这2种检验方法的功效也随之提高,在各种情况下,都有好的检验功效。
3 定理1的证明
3.1 引理
在证明过程中,由于T=n-p,因此本文不区别Op(n)和Op(T)等。假定C为绝对常数,在不同的地方取值不同。为了证明定理1,先给出几个引理。
引理1 在条件A1~A6和零假设下,有
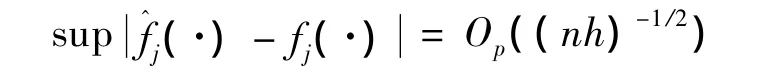
证明见文献[10]。
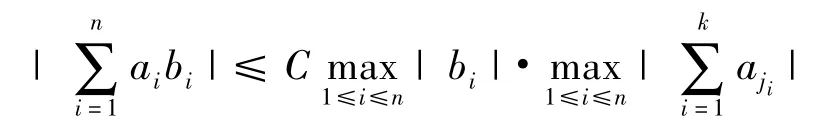
其中(j1,j2,…,jn)是(1,2,…,n)的任意排列。
引理3 设 εi,i=1,2,…,n 是独立随机变量序列,满足 Eεi=0<∞,则有
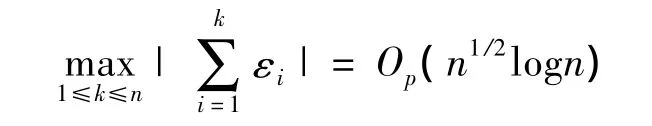
且对于(1,2,…,n)的任何一个置换(j1,j2,…,jn),有
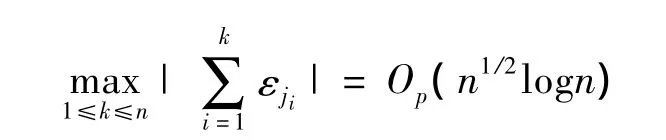
证明见文献[5]。
3.2 定理1的证明
因为
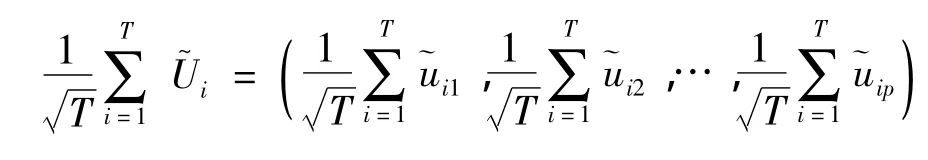
故对任意的整数k(1≤k≤p),有:
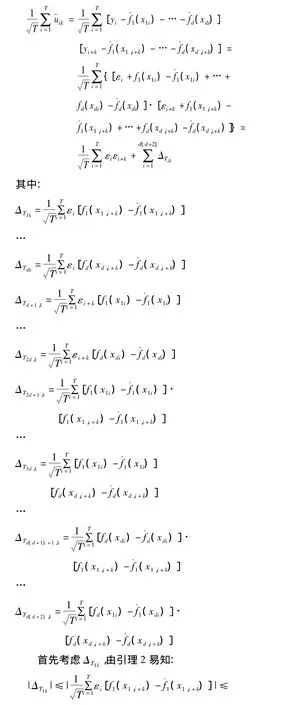

由Gramer-Wold方法,根据m步相依随机变量中心极限定理可得
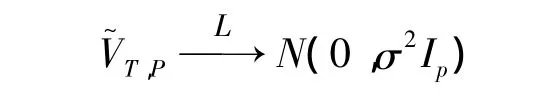
定理1得证。
[1]Ansley C F,Kohn R.Convergence of the backfitting algorithm for additive models[J].Journal of the Australian Mathematical Society,Series A,1994,57:316-329.
[2]Buja A,Hastie T J,Tibshirani R.Linear smoothers and additive models[J].The Annals of Statistics,1989,17:453-510.
[3]Ezekiel A.A method of handling curvilinear correlation for any number of variables[J].Journal of American Statistical Association,1924,19:431-453.
[4]Fan J,Hardle W,Manmen E.Direct estimation of low-dimensional conponents in additive models[J].The Annals of Statistics,1998,26:943-971.
[5]Gao J T.Asymptotic theory for partly linear models[J].Communications in Statistic-Theory and Methods,1995,24:1985-2010.
[6]Hu X M,Liu F,Wang Z Z.Testing serial correlation in semiparametric varying coefficient partial linear errors-invariables models[J].Jrl Syst Sci Complexity,2006,22:483-494.
[7]Jiang J,Li J.Two-stage local M-estimation of additive models[J].Science in China,Series A:Mathematics,2008,51:1315-1338.
[8]Opsomer J D,Ruppert D.Fitting a bivariate additive model by local polynomialregression[J].The Annals of Statistics,1997,25:186-211.
[9]Stone C J.Additive regression and other nonparametric models[J].The Annals of Statistics,1985,13,689-705.
[10]Wand M P.A central limit theorem for local polynomial backfitting estimators[J].Journal of Multivariate Analysis,2000,70:57-65.
[11]刘锋,陈敏,邹捷中.部分线性模型序列相关的经验似然比检验[J].应用数学学报,2006,29:577-586.
