电子商务中的WEB挖掘技术应用研究
2012-08-20汪华茂
汪华茂
(湖北经济学院 网络与教育技术中心,湖北 武汉430205)
1.引言
电子商务作为一种新兴的事物,随着Internet的迅速发展和应用的深入,电子商务的应用也相应的迅速崛起起来,这使得商家对基于Internet的Web数据检索、挖掘等的需求不断提高。
传统的Web站点,通常由HTML页面组成,使得这种Web文档的结构性有限,要想利用分析工具准确、高效地进行数据挖掘和分析还比较困难。XML的出现,则对Web数据挖掘带来了新的挈机。利用XML作为元标记语言的特性,用户只要在XML的文档类型定义中定义一系列有意义的标记,就可实现对Web上大部分非结构化文档的内容进行有效的总结、分类、组织,从而实现与关系型数据库中的属性建立对应关系,Web上的数据挖掘也就变得可行了。
2.基于XML的Web数据挖掘技术
2.1 Web数据挖掘技术概述
Web数据挖掘就是从Internet上庞大、复杂、异构的数据中发现隐含的规律性的东西或者是特定的精确的数据。Web挖掘则可以对大量的文档、数据重新进行整理、分析和组织,可以按照用户特定的要求给出结果,比单纯的信息检索更进一步,是未来技术发展的趋势。
WEB挖掘按照处理对象的不同可分为:内容挖掘、结构挖掘和使用记录挖掘。内容挖掘是从Web文档的内容中抽取信息特征,这些文档包括文本、HTML、图象、音频、视频等形式;结构挖掘是从Web文档的组织结构和链接关系中推导知识,这些结构不仅仅局限于文档之间的超连接,还包括文档内部的结构、文档URL中的目录路径结构等;使用记录挖掘则是从Web的访问记录中抽取感兴趣的模式。
2.2 XML优势
XML出色之处在于它不再是一个单纯的标记语言,而是一个定义语言。XML突破了HTML固定标记集合的约束,可以定义无穷无尽的标记来描述Web中的任何数据元素及其结构,从而组成一个完整的信息体系,使文件的内容更丰富更复杂更结构化。而且,在兼容性方面,HTML规范的文件可以转换成XML格式文件,普通的SGML文件也可以转换成XML文件。由于XML能针对特定的应用定义自己的标记语言,这使得XML可以在电子商务、政府政务、企业及中介组织的信息交换中得到广泛的应用。
2.3 基于XML的WEB挖掘过程
在目前多数的Web站点仍由静态的或动态的HTML页面组成的情况下,虽然每个站点的开发自行其是,而且数据本身还存在着自我描述性和动态可变性,但由于XML作为可以定义语言的语言,能够把不同来源的数据结合在一起,从而使得Web上大量非结构化的数据变成了进行挖掘的宝藏。
Web挖掘的过程由以下三步组成:
(1)Web信息数据的获取。进行数据源搜索,获取必要的信息。
(2)Web信息的转换。对HTML文档进行抽取,转换为结构化的XML文档,生成相应的DTD文档或者XML Schema,并进行分类,选择合适的数据库进行存储组织。
(3)Web信息的挖掘。将大量结构化处理的信息文档进行有效的组织与管理,根据用户的特定需求进行挖掘。
如果HTML文档比较规范,所有元素的首位标记都配对,所有元素的嵌套层次结构都正确,所有的属性值都以“”的形式出现,所有的自说明的元素以 “/>”结束,那么通过对HTML文档的处理,可以从页面中抽取出所需要的属性,从而进一步转换为XML文档;但一些页面很少遵循连续的格式,在抽取属性时则比较困难。在转换过程中,主要解决HTML文档及其集合的表达模式信息(WEB-SCHEMA)的抽取,即可以通过程序自动完成,也可由系统人员手工的对HTML文本作进一步的分析,将遗漏的模式信息补充进来,确定对象的属性名和对象之间的语义关系,形成完整的数据模式。
HTML的模式信息抽取出来后,为了有效地将其用XML文档表示出来,必须定义XML的合适的文档类型定义(DTD)。由于XML允许用户定义自己的标记,可能会出现混乱,影响信息的共享,因此,Dubilin Core workshop提出了一套描述符用以描述文档的内容、表现形式和相关属性,目前由15个组成,即 TITILE、CREATOR、SUBJECT、DESCRIPTION、PUTLISHER、CONTRIBUTION、DATE、TYPE、FORMAT、IDENTIFIER、SOURCE、LANGUAGE、RELATION、COVERAGE、RIGHTS 等,通过这些描述符,就比较容易地将HTML文档统一为XML文档。
3.应用研究
以一个网络产品信息服务公司为例进行web数据挖掘应用研究。该公司主要业务是通过Web提供各类网络设备的代购。目前,该公司的信息渠道来源是从Web上搜索到的有关的设备信息。但目前的搜索引擎搜索到的只是包含少量或部分有用信息的Web文档,无法自动的将设备的型号、设备的规格、设备的生产厂商、设备的生产日期、设备的价格、设备的数量、设备的简介等信息分捡出来,对其进行编号、分类,因此如何从Web上精确地获得所需要的信息,并将结果按设备或者是按提供商进行分类,再通过Web发布出去,也就成了公司急需解决的问题。
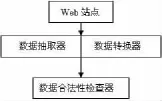
在本实例中采用了数据服务的形式,实际上包括抽取、数据转换和数据合法性检查等三个部分,如下图所示。其中抽取器包含一系列的抽取规则,主要负责从非结构化的数据中抽取设备的型号、规格、生产厂商、生产日期、价格、数量、简介等属性,用XML表示并存储起来;数据转换器将来自不同站点或数据源的数据转换为一种公共的表示方式;而数据合法性检查器则对一些条件进行监视,强制在不同级别(行、列、标)进行约束,它和数据转换器共同保证数据的完整性。
4.结语
Web数据挖掘是一个较新的研究领域。XML更是给Web挖掘带来了新的契机,随着XML技术的更加成熟,面向Web的挖掘必然会变得更轻松,在电子商务上的应用也会更加深入。
[1]Simon St.Laurent.XML基础教程[M].康晓林、伊希荣,等译.电子工业出版社.
[2]胡彦.XML技术与B2B电子商务发展[J].电脑开发与应用,13(9).
[3]李寅,林宣雄.基于WEB的XML数据交换技术[J].计算机系统应用,2000,(11).
[4]徐振航,刘莉芹.基于XML的数据挖掘技术[J].计算机系统应用,2001,(1).
