基于模糊聚类的云任务调度算法
2012-08-10李文娟张启飞平玲娣潘雪增
李文娟,张启飞,平玲娣,潘雪增
(1. 浙江大学 计算机学院,浙江 杭州 310018;2. 杭州师范大学 钱江学院,浙江 杭州 310012)
1 引言
云计算(cloud computing)是在网格计算、并行计算、P2P和虚拟化等技术基础上发展起来的一种新型的共享信息基础设施的模式,也是未来提供网络服务的重要形式[1~3]。云计算的宗旨是为企业和其他终端用户提供廉价按需服务,因而特别强调QoS。而任务调度模型的优劣直接影响云服务质量,毋庸置疑是云计算研究的重要组成部分[4~6]。云计算研究目前仍处于初级阶段,有关云调度的算法还非常稀少,但传统的其他并行分布式系统中的调度模型[7,8]有很多。其中以最小化作业完成时间为目标的元任务调度算法有OLB、贪心(greedy)算法、最大最小(max-min)、最小最小(min-Min)、Sufferage算法[9~12]等以及基于人工智能的调度算法(遗传算法、蚁群算法)[13,14]等。上述算法将任务与资源绑定时,更多的是考虑如何缩短任务执行时间,但云计算的目标是提供按需服务,这样无法反映用户真实的QoS要求。另外,传统的任务调度算法在选择资源时,其针对的对象是全体服务资源,未考虑资源本身的特性和用户或任务的偏好,导致资源选择的开销大且存在盲目性。因此找到一种合适的方法对资源进行一定程度的划分能够缩小资源选择范围,从而降低任务调度开销。聚类方法是对目标进行分类的有效手段。聚类的主要方法有:谱系聚类法、基于等价关系的聚类方法、图论聚类法和基于目标函数的聚类方法等[15~17]。资源模糊聚类[18~20]的研究集中于最近几年,比如杜晓丽等人提出的网格DAG任务图调度算法[18]、陈志刚等提出的网格服务资源多维性能聚类任务调度[19]等,为资源聚类和任务调度提供了有益的参考。但之前的聚类调度算法大多只考虑计算任务,并且仅对资源进行综合性能优劣的划分,主要目标是减少总执行时间,没有考虑资源的其他属性也没有考虑任务的期望。
为更好地体现云计算“廉价按需”服务的宗旨,反映资源公平公正分配的原则,在对云提供商的资源按性能进行模糊聚类的基础上,采用两级调度模式,按照任务的期望进行按需公平调度,本文提出了一种云环境下基于模糊聚类的两级任务调度(FCTLBS, fuzzy clustering and two level based task scheduling)算法。理论与实验分析表明,该算法在提高云系统整体效率和实现调度公平上具备一定的优越性。
本文的创新之处在于:1) 用模糊聚类方法对云资源进行划分,在实际分配时减少了资源搜索的空间,降低了算法复杂度,同时更能充分有效发挥对应资源的优势;2) 提出任务偏好的计算方法,能够更好分析任务的实际需求;3) 提出一种模糊聚类基础上的两级任务调度算法,依据资源聚类结果及任务偏好,最大限度体现调度公平性。同时对用户实施整体调度,对任务实施微观调度,有助于减小问题规模,并为未来在调度中加入安全及其他机制奠定基础。
2 调度模型
2.1 用户模型
用户是指请求云服务、提交云任务的实体。使用U={u0,u1,u2,…,uk-1}表示用户集合,k=|U|代表用户数。其中第i个用户ui(i∈[0,k-1])又可以进一步表示为ui={uID,uName,uUAid,uTaskSet},各属性的含义如下。
1) uID表示用户编号,用户编号在云系统中是唯一的。
2) uName表示用户名称。
3) uUAid表示用户代理的编号。
4) uTaskSet表示用户提交的任务集。
2.2 任务模型
云计算植根于并行系统之上,云任务可以由有向无环图(DAG):G=(T,E)来表示。其中,T={t0,t1,t2,…,tn-1}表示任务集,n=|T|代表任务数;E表示任务间执行先序关系的边集。第i个任务ti(i∈[0,n-1])又可以进一步刻画为ti={tID, tLength, tStatus,tRRes, tORSet, tDeadLine, tData},各属性的含义如下。
1) tID表示任务编号,任务编号对于同一用户的任务而言是唯一的。
2) tLength表示任务的长度,用于判断任务的计算量。
3) tStatus表示任务状态,任务可能的状态包括创建(CREATED)、就绪(READY)、执行(INEXEC)、完成(FINISH)、等待(WAITING)、撤销(CANCELED)、挂起(PAUSED)、唤醒(RESUMED)和失败(FALSE)。任务刚创建时被赋予 CREATED状态;当执行条件满足时转为READY状态;获得处理机执行时进入INEXEC状态;因等待资源或其他协作任务完成转为WAITING状态;若从内存中调出的任务为PAUSED状态,相应地调入内存状态为RESUMED;任务执行完毕转为FINISH状态;若任务请求的资源在本系统中无法达成或缺乏执行可能则成为FALSE状态。
4) tRRes表示任务的资源需求。资源需求tRRes又可以进一步刻画为tRRes={tComp,tBW,tStor},其中tComp、tBW、tStor分别表示任务对资源计算能力、通信能力和存储能力的需求。
5) tORSet表示任务已分配的资源集合。
6) tDeadLine表示任务的最晚完成时间,用于辅助评判调度策略的成功与否。
7) tData表示处理任务所需要的相关数据,包括tInputData和 tOutputData。
2.3 资源模型
R={r0,r1,r2,…,rm-1}表示云系统中的资源集合。m=|R|代表资源数。其中,第 j个资源 rj(j∈[0,m-1])又可以进一步刻画为rj={rID, rUser, rCap},各属性的含义如下。
1) rID表示资源编号。
2) rUser表示资源隶属的云提供商。
3) rCap表示资源的性能。本文使用3维向量来刻画资源的性能,包括计算能力、网络传输能力、存储能力。
因此,资源性能rCap又可以进一步刻画为rCap={rComp, rBW, rStor},rComp、rBW、rStor分别表示资源的计算能力、通信能力和存储能力。
定义1 资源综合性能rGP:由资源的各项性能需求综合计算得出,计算公式如下:

其中,参数α、β、δ分别表示计算、带宽和存储能力的经验系数。
定义2 资源相似度ijPDTr :表示资源i与资源j综合性能的相似度,由资源之间综合性能的距离计算得出,公式如下:

定义 3 聚类资源综合性能 crGP:某一类型资源聚类的综合性能均值,公式如下:

其中,参数n表示类内资源数。
2.4 资源模糊聚类
模糊C均值聚类方法(FCM)是Bezdek 提出用来对数据进行模糊聚类的方法[21]。给定数据集X={x1,x2,…,xn},FCM 算法的目标是找到该数据集的一个模糊划分聚类Uc×n,即划分原数据为c个模糊组,并使得每组样本与其组聚类中心的非相似性指标达到最小。聚类目标函数的一般定义如下:

其中,uij表示数据j隶属于模糊组i的隶属度,其值介于 0,1之间;而ci是模糊组 i的聚类中心,dij=||ci-xj||为第i个聚类中心与第j个数据点间的欧氏距离;m∈[1,∞)是一个加权指数。
本文使用 FCM 方式将资源按照性能模糊划分为3个类别。聚类的主要步骤如下。
1) 以系统中资源性能向量 rCap建立初始化样本矩阵。
2) 对原始数据进行标准化处理,将数据压缩到[0,1]之间。
3) 将资源随机分为4个类别,初始化模糊划分矩阵U。
4) 计算聚类中心 ci,i∈{1,2,3}。
5) 计算类内各节点与聚类中心的目标函数值。若小于某个确定的阈值,或它相对上次目标函数值的改变量小于某个阈值,则算法停止。
6) 计算新的划分矩阵U。返回步骤4)。
以包含8个资源节点的云系统为例,假定初始状态下资源的各种性能指标如表1所示。

表1 资源性能参数
原始数据及经标准化处理后的资源性能数据如图1所示。

图1 资源性能数据
经过设定阈值和若干次迭代运算,最终将8个资源划分为3个聚类,分别为Cluster0= {r1,r4,r8},Cluster1={r3,r6},Cluster2={r2,r5,r7}。其中Cluster0标识为计算型资源集,Cluster1标识为带宽型资源集,而Cluster2标识为存储型资源集。
2.5 任务偏好系数
定义4 任务综合资源期望tGR:由任务对资源的各项性能需求综合计算得出,公式如下:

其中,参数a、b、c分别表示计算、带宽和存储能力的经验系数。
定义5 任务偏好系数tRC:经过量化的任务对资源性能的敏感度。对应于资源的3种类别,本文中将任务区分为计算敏感型、带宽敏感型和存储敏感型。
任务偏好系数的计算:任务综合资源期望 tGR与各种类型的资源之间综合性能的最短距离。

其中,cGPjr表示第j类资源聚类的综合性能。
3 FCTLBS调度算法
在资源按性能模糊聚类的基础上,设计了基于两级调度模型的调度算法。算法将云调度分为两级:用户调度和任务调度。用户调度是指以云用户为单位的调度。用户调度模块根据用户的整体需求和当前云市场中各提供商的情况,实现用户与若干提供商及资源集的绑定。任务调度实现同一用户内部任务与用户所获得的虚拟资源的绑定。用户调度的层面高于任务调度。
3.1 实施框图
新的调度模型在开放云系统中设立云信息服务中心(CISC, cloud information service center)以及云用户中心(CUC, cloud user center)。以各提供商的单云平台为依据划分服务域,域代理由提供商设立,域代理代表提供商实施域管理策略,包括资源模糊聚类算法的实施,资源任务的绑定等。用户首次登录时向 CUC注册,而后每次登录时,依据注册账号向 CUC提交本次登录的各项需求,包括服务类型、资源需求、时间期限和费用约束等。云提供商(通过域代理)向CISC注册。CISC与CUC可以交互。因而用户可以获取提供商列表,云提供商也可以向用户发布资源广告。
在模型实施过程中,首先实现以云用户为单位的整体调度,根据用户的整体需求为其选择云服务商或其组合。当用户与特定的几个提供商绑定之后,将获得提供商分配的若干虚拟资源以完成用户任务。在任务调度中,事先将云提供商的资源模糊划分为3个类别:计算型、带宽型和存储型。当任务提交时计算任务的偏好系数,根据任务偏好在合适的资源聚类中为其选择资源。模型的具体实施过程如图2所示。
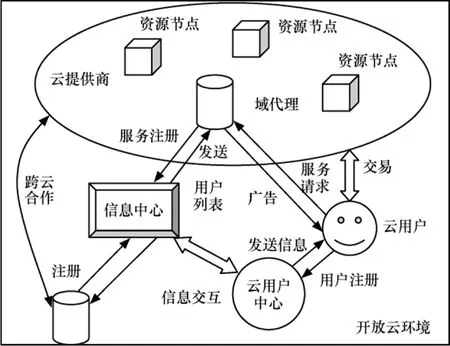
图2 FCTLBS算法实施
3.2 FCTLBS算法流程
以各云提供商的单云平台为域进行资源模糊聚类。云资源模糊聚类的算法如下。
RCluster(resourceList rlist){
设定停止阈值ε和最大迭代次数MaxTimes;迭代次数i=0;
根据输入的资源列表中资源性能为原始数据初始化并进行数据标准化处理
将资源随机分入3个类别,生成初始化划分矩阵U0;
计算初始聚类中心;
计算Jvalue0


更新聚类中心
计算新的目标函数值Jvalue;i

用户调度的算法如下。
CUserS(userList ulist, providerList plist){ //用户调度实现用户与提供商的绑定
While(ulist.iterator().hasNext()){ //需要分配资源的用户列表非空
CloudUser cuser = (CloudUser) iter.next(); //取出列表中的一个用户
//用户登录云系统时出示要求的服务类型和各项需求,据此计算用户的整体资源需求
requiredResource=cuser. computeRequireCapability ();
List<CloudProvider> chosenPList=new Array-List< CloudProvider >(); //创建选中的提供商列表
/* findProvider函数将根据该用户的服务类型、自身的等级、安全级别以及本次运行的资源需求,在现有的提供商列表中寻找最合适的提供商或组合来为该用户服务。*/
NodifyProvider(chosenPList,cuser); //通知云提供商需要服务的用户
NodifyUser(cuser,chosenPList); //通知云用户为其分配的提供商列表

在资源模糊聚类的基础上,任务调度算法如下。
FCTLBS(taskList tlist, resourceList rlist){ //任务调度实现任务与资源的绑定
RCluster(rlist); //实现某一云提供商资源的模糊聚类,生成计算型、带宽型和存储型资源聚类
Sort(comrlist); //对计算型资源聚类按照类内资源性能降序排列
Sort(bwrlist); //对带宽型资源聚类按照类内资源性能降序排列
Sort(storrlist); //对存储型资源聚类按照类内资源性能降序排列
crGP1=ComputClusterGP(comrlist); //按照式(3)计算计算型资源聚类的综合性能crGP1
crGP2=ComputClusterGP(bwrlist); //按照式(3)计算带宽型资源聚类的综合性能crGP2
crGP3=ComputClusterGP(storrlist); //按照式(3)计算存储型资源聚类的综合性能crGP3
While(tasklist.iterator().hasNext()){ //任务列表非空
CloudTask cloudt= (CloudTask)iter.next(); //取出任务集中的一个任务
/* ComputeTRC函数根据任务的各项资源需求按照式(5)计算任务综合资源期望 tGR,并根据式(6)确定任务的资源偏好*/

//根据任务类型从虚拟机列表中寻找合适的虚拟机

3.3 算法性能分析
在云系统中,某一云用户在一次登录时的完成时间取决于该用户所申请执行的云任务集的最终完成时间,即完成时间最迟的任务的完成时间。使用uCTi表示用户i的完成时间, tCTj表示任务j的完成时间,则 uCTi可以表示为

对于云任务而言,其预期完成时间取决于任务的执行时间、通信时间和存储时间。任务j的通信时间如下:
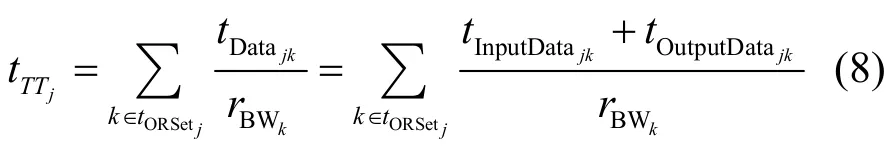
其中,tORSetj表示任务j已分配的资源集合,tDatajk表示任务j使用资源k传输的数据量,相应地,tInputDatajk和tOutputDatajk表示通过k输入及输出的数据量。rBWk表示资源k的网络传输能力。
任务j的处理时间为
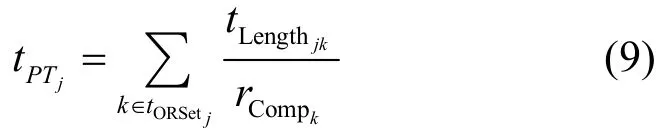
其中,tLengthjk表示任务j在资源k上的计算量,rCompk表示资源k的计算能力。

其中,tSDjk表示任务j在资源k上的存储量,rStork表示资源k的存储能力。因此任务的预期完成时间为

云系统的吞吐量取决于单位时间内系统服务的云用户总量,缩短各用户完成时间可以达到此目标。用户完成时间取决于该用户隶属的用户任务集的完成时间。缩短任务完成时间应从缩短任务的计算、传输和存储时间入手。本文将资源分为计算型、带宽型和存储型3类,同时将任务也按照其对资源需求的特点归为对应的计算偏好型、带宽偏好型和存储偏好型3个类别,从而使得对资源某种能力要求高、需求量大的任务获得在此能力上性能较好的资源,更好地体现了按需分配的原则,也从一般意义上缩短了任务的完成时间。
RCluster算法在最坏情况下的时间复杂度为o(m×MaxTimes),m表示某一云提供商拥有的资源数,MaxTimes为最大迭代次数。用户调度程序CUserS在最坏情况下的时间复杂度为o(n×k),其中n表示云用户数,k表示云提供商数。任务调度程序FCTLBS是在RCluster基础上对任务与资源进行绑定,因此其在最坏情况下的时间复杂度为o(x×m×MaxTimes),其中x表示任务数,m与MaxTimes的含义同前。
4 实验设计与分析
云系统中的任务调度算法目前还比较稀少,在已有的分布式元任务调度算法中,Min-Min是很多其他调度模型的基础,另外,考虑到本调度算法的目标之一是实现资源的按需分配,也可以说是实践资源分配的公平性原则,而赵春燕等人提出的基于伯格模型的云任务调度算法[22]其宗旨即分配公平,因此本文将FCTLBS与Min-Min及基于伯格模型的任务调度算法相比较,以获得相对客观的评价。
4.1 实验设计
实验模拟包含2个云提供商和若干云用户构成的云计算环境。以提供商的单云平台作为划分域的依据,由提供商设立域代理节点,域代理是代表提供商管理域资源和进行云交易的主体。仿真系统由任务生成器、资源发生器、云交互环境、用户调度器和任务调度器几部分构成。任务生成器按照输入的任务数、任务各项参数基值和对应的任务差异度随机生成任务,并部署任务参数。资源发生器则按照要求的资源数目、资源性能基数以及资源差异度随机产生资源节点,并部署资源性能。云交互环境主要实现仿真云环境中不同实体的交互和消息传递。交互系统中包含3.1节提到的云信息服务中心CISC和云用户中心CUC。提供商(通过域代理)向CISC注册、获取用户信息,用户向CUC注册并间接获取提供商的信息。用户调度器是实现用户与提供商绑定的程序,而任务调度器是实现用户任务集中的任务与用户已经获得的资源绑定的程序。仿真系统模拟50~1 500个任务在5~200个资源节点上的执行情况。通过任务生成器的控制,任务的长度控制在[tLength,Ldif×tLength]之间的值,任务的计算需求控制在[tComp,Cdif×tComp]之间,带宽需求量控制在[tBW, Tdif×tBW],存储需求控制在[tStor,Sdif×tStor]之间。同理,通过资源发生器的控制,将资源的计算能力控制在[rComp,Cdifr×rComp]之间,将资源的网络能力控制在[rBW,Tdifr×rBW]之间,将资源的计算能力控制在[rStor,Sdifr×rStor]之间。其中,tLength表示任务长度,Ldif表示任务长度差异度。tComp表示任务计算量,Cdif表示任务计算量差异度。tBW表示任务带宽需求,Tdif表示任务带宽需求差异度。tStor表示任务存储需求量,Sdif表示任务存储需求差异度。资源的各项指标类似。
4.2 评价指标
调度的目标是实现资源任务的合理匹配,从而一方面提高系统的整体工作效率,另一方面提高系统使用者的满意度。为了判断新的调度算法在实践调度目标上的性能,仿真实验主要设置了2个评价指标:一是任务集的最终完成时间,用来评价系统的吞吐量;二是用户满意度,用于评价资源分配和调度的合理性。本文中用户满意度是根据任务的实际占有资源水平与期望占有水平的相比较计算得出的。
单个任务的满意度 tJvaluei的计算方法如下所示:

其中,tORSet如前所述表示任务实际分配得到的资源集合,ρ、ω、τ分别表示计算、带宽和存储资源需求的经验系数。由式(12)可以很容易推导出任务集的整体满意度,即用户满意度 uJvalue的计算方法如下所示:
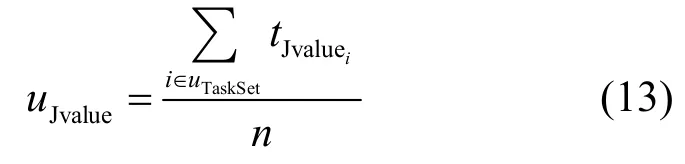
其中,uTaskSet表示归属于该用户的任务集,n表示任务的个数。
4.3 实验结果分析
由于基于伯格模型的任务调度算法开销很大,当任务数增加时,其执行时间呈急速上升趋势,因而对于任务完成时间的比较分两次进行。任务数较少时,比较3种调度算法的性能;任务数较多时,比较FCTLBS和Min-Min的性能。比较结果如图3和图4所示。

图3 任务数较少时,3种算法完成时间比较

图4 任务数较多时,2种算法完成时间比较
相应地,对用户满意度的比较也分成两次进行,比较结果如图5和图6所示。

图5 任务数较少时,3种算法满意度比较

图6 任务数较多时,2种算法满意度比较
从仿真实验结果可以看出,当问题规模较小(本文中0~120个任务)时,FCTLBS与Min-Min调度模型的时间效率相当,优于伯格模型,在用户满意度上 FCTLBS与伯格模型相当,优于Min-Min;当问题规模较大(本文中大于 150个任务)时,FCTLBS在完成时间和用户满意度上均较优。Min-Min调度算法的主要思想是不断寻找并优先调度任务集中在所有资源上拥有最小完成时间最小的任务,因而执行速度较快,但由于其总是优先调度短任务,无法保证整体用户满意度。伯格模型将欧氏距离最短的任务资源进行匹配,以期达到用户期待分配资源与实际分配资源的最大一致性,整体用户满意度较高,但无法保证系统吞吐量,且实现全体任务与全体资源的匹配计算开销大,在实际系统中实现困难。FCTLBS算法采取两级调度模式,以提供商的单云平台为单位实施资源聚类算法,降低了问题的规模。同时在资源综合性能聚类的基础上,按照任务的资源需求进行资源和任务的绑定,更好地体现了按需分配的原则,也从整体上缩短了任务集的完成时间。由此可见,FCTLBS算法具备更好的性能和可操作性。
5 结束语
本文提出了一种云计算环境中使用的任务调度算法。该算法将调度分为用户调度和任务调度两级。以用户为单位进行的整体调度,可以更好地发挥用户的自主资源选择权,反映不同用户的需求,也有利于后续安全措施的引入。任务调度中,采用模糊聚类的方法对不同提供商的资源按照其综合性能进行聚类,并计算任务资源偏好,以任务的偏好为依据在对应资源聚类中进行选择。聚类任务调度算法降低了资源选择的空间,也保证了分配的公平合理性。最后,通过实验与分析可知,新的调度算法在确保系统整体吞吐量的同时保证了较高的用户满意度。
[1] 刘鹏. 云计算[M]. 北京:电子工业出版社, 2010.LIU P. Cloud Computing[M]. Beijing: Electronic Industry Press, 2010.
[2] FOSTER I, KESSELMAN C. The Grid: Blueprint for a New Computing Infrastructure[M]. Morgan Kaufmann, San Francisco,1999.
[3] FOSTER I, ZHAO Y, IOAN R, et al. Cloud computing and grid computing 360-degree compared[A]. Grid Computing Environments Workshop, 2008. GCE '08 (2008)[C]. 2008.1-10.
[4] 王鹏. 云计算的关键技术与应用实例[M]. 北京:人民邮电出版社,2010.WANG P. The Key Technologies of Cloud Computing and Its Application [M]. Beijing: Posts & Telecom Press, 2010.
[5] 中国云计算论坛[EB/OL]. http://bbs.chinacloud.cn.Chinese cloud forum[EB/OL]. http://bbs.chinacloud.cn.
[6] MLADEN A, VOU K. Cloud computing-issues research and implementations[A]. Proceedings of the ITI 2008, 30th Int Conf on Information Technology Interfaces[C].2008.31-40.
[7] 朱福喜,何炎祥. 并行分布式计算中的调度算法理论与设计[M].武汉:武汉大学出版社, 2003.ZHU F X, HE Y X. Parallel Scheduling Algorithm in Distributed Computing Theory and Design[M]. Wuhan: Wuhan University Press,2003.
[8] CRREA R C.Scheduling multiprocessor tasks with genetic algorithms[J]. IEEE Transactions on Parallel and Distributed Systems,1999,10(8):825-837.
[9] FREUND R, GHENITY M, AMBROSIUS S, et al.Scheduling resources in multi-user heterogeneous computing environments with SmartNet[A]. Proceedings of the 7th IEEE Heterogeneous Computing Workshop[C]. Orlando, Florida, USA,1998.184-199.
[10] HOU E S H, ANSARI N,REN H. A genetic algorithm for multiprocessor scheduling[J]. IEEE Trans on Parallel and Distributed Systems,1994,5(2):113-120.
[11] IBARRA O H, KIM C E. Heuristic algorithms for scheduling independent tasks on non identical processors[J].Journal of ACM,l997,24(2):280-289.
[12] TRACY D B, HOWARD J S, NOAH B. A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems[J]. Journal of Parallel and Distributed Computing,2001,61(6):810-837.
[13] HOLLAND J H. Adaptation in Natural and Artificial Systems[M].Michigan, USA: Ann Arbor University of Michigan Press,1975.228-234.
[14] GAMBARDELLA L M, DORIGO M. Solving symmetric and asymmetric TSPs by ant colonies[A]. Proceedings of the IEEE Conference on Evolutionary Computation[C]. 1996.622-627.
[15] 曲绍云.分布式异构系统中任务调度问题的研究[D]. 青岛:青岛大学, 2005.QU S Y. Research on Task Scheduling Problems in Distributed and Heterogeneous Systems[D]. Qindao: Qindao University, 2005.
[16] 高新波.模糊聚类分析及其应用[M]. 西安: 西安电子科技大学出版社, 2004.GAO X B. Fuzzy Clustering Analysis and Applications[M]. Xi’an:Xi’an Electronic and Technology University Press,2004.
[17] 严骏,姚敏.模糊聚类算法应用研究[D].杭州:浙江大学,2006.YAN J, YAO M. Research on the Applications of Fuzzy Clustering Algorithms[D]. Hangzhou: Zhejiang University, 2006.
[18] 杜晓丽, 蒋昌俊, 徐国荣等. 一种基于模糊聚类的网格 DAG 任务图调度算法[J].软件学报,2006, 17(11): 2277-2288.DU X L, JIANG C J, XU G R, et al. A grid DAG scheduling algorithm based on fuzzy clustering[J]. Journal of Software, 2006, 17(11): 2277-2288.
[19] 陈志刚,杨博.网格服务资源多维性能聚类任务调度[J]. 软件学报,2009,20(10):2766-2774.CHEN Z G, YANG B. Task scheduling based on multidimensional performance clustering of grid service resources[J]. Journal of Software, 2009,20(10):2766-2774.
[20] 任大娟,张忠平.基于模糊聚类的网格资源发现方法研究[D]. 秦皇岛:燕山大学,2009.REN D J, ZHANG Z P. Research on Grid Resource Discovery Based on Fuzzy Clustering[D]. Qinhuangdao: Yanshan University,2009.
[21] BEZDEK J C. Pattern Recognition with Fuzzy Objective Function Algorithms[M]. New York: Plenum Press, 1981.10-18.
[22] 赵春燕. 云环境下作业调度算法研究与实现[D]. 北京:北京交通大学, 2009.ZHAO C Y. Research and Realization of Job Scheduling Algorithm in Cloud Environment[D]. Beijing: Beijing Jiaotong University, 2009.
