基于最短划分距离的网络流量决策树分类方法
2012-08-10杨哲李领治纪其进朱艳琴
杨哲,李领治,纪其进,朱艳琴
(1. 苏州大学 计算机科学与技术学院, 江苏 苏州 215006; 2. 江苏省计算机信息处理技术重点实验室, 江苏 苏州 215006)
1 引言
随着互联网的不断发展,出现了文件共享、VoIP和流媒体等各种不同类型的应用流量,它们对 QoS的要求各不相同。为了实施有效的 QoS保障,网络管理者需要了解网络中各种类型的流量状况,关注其流量特征,或者分析相应的用户行为和应用发展趋势,从而对网络进行扩容改造。这些都必须对各种应用流量进行准确的分类。此外,准确的流量分类在网络安全、流量计费等领域,也具有极其重要的意义,一直是网络测量领域的研究热点。
最初的流量分类是根据IANA端口映射表,将符合某个特定端口号的流量识别为相应的网络应用。其针对传统 Internet应用和早期采用固定端口传输的P2P应用,分类准确性较高。随着新型应用采用随机端口、端口跳变或端口伪装等技术,该方法的分类准确性已大大下降[1]。随后Moore[1]、Sen[2]和Karagiannis[3]等分别提出载荷分析法,通过检查数据分组的应用层载荷,进行应用协议的特征串匹配。这些特征串称为应用层签名(application signature)。该方法分类准确性最高,为当今大多数商用系统所采用。但是其必须针对每一种应用构建应用层签名,且需经常更新以适应应用的不断发展。虽然 Haffner[4]和 Ma[5]等提出了自动构建应用层签名的方法,但只能针对传统 Internet应用。随着应用载荷加密和混淆技术的不断发展,该方法的有效性正逐步下降。此外,也有研究者从其他的角度提出了不同的流量分类模型。Karagiannis等[6]提出基于传输层行为的盲分类器BLINC,通过主机在社会层、网络层和应用层3个层次的内在行为特性,先识别主机参与的应用,然后对其产生的流量进行分类。Xu等[7]也采用这种办法进行流量分类,但其使用信息论和数据挖掘工具。这些方法不依赖于分组载荷,扩展性好,但模型较为复杂。Dahmouni等[8]认为不同应用的 TCP控制分组也是统计可分的,并提出建立TCP标记序列的马尔可夫链作为分类器,该方法的有效性有待进一步验证。
为了克服上述方法的不足,研究者开始寻求新的方向。一般来说,不同应用产生的流量往往具有不同的统计特征,反映着各个应用的内在特性。例如,FTP流量的分组长度较大且分组间隔时间较小。但是,网络流量具有数据庞大、应用特性高度动态的特点。因此,利用机器学习方法,构造基于流统计特征的网络流量分类模型,是目前流量分类的研究热点。
2 基于流统计特征的网络流量分类
一般来说,流量分类的基本处理单元,通常是一组具有相同五元组<源IP、目的IP、源端口、目的端口、传输层协议>的分组序列,即网络流(flow)。在实际处理中,又进一步划分为单向流和双向流。单向流是指严格按照五元组规则划分的分组序列,双向流是指同一网络连接之内的双向分组序列,其包括正向流(client to server)和反向流(server to client)。通过提取单向流或双向流的特征集合,将流抽象为由一组特征属性构成的特征向量,实现从网络流量分类问题到机器学习问题的过渡。因此,利用机器学习方法处理流量分类问题,需要解决的关键问题,主要包括 3个方面:① 选择合适的特征属性构建特征向量;② 选择适当的机器学习算法构建分类模型;③ 利用真实流量数据,对分类模型进行评价。
目前,主要使用的特征属性分为以下3类。
1) 数量相关特征,例如双向分组/字节总数、正向分组/字节总数和反向分组/字节总数等。
2) 长度相关特征,例如正向(反向)分组的平均长度、方差和极值等。
3) 时间相关特征,例如流持续时间、正(反)向分组的平均到达间隔、方差和极值等。
不同网络应用在这些特征属性上,一般存在较大差异。如P2P是双向数据传输,而被动FTP是单向数据传输。因此利用正(反)向分组数量的差异,可以有效区分这两者[9]。选取最能够反应网络应用本质区别的特征属性,对于网络流量分类非常重要。但特征属性之间存在相关性和冗余性,不仅增加计算复杂度,并且会降低分类准确性。Moore等[10]提出的一个248项特征属性的集合,其中有100多项是通过傅里叶变换得来的。如果对每条网络流都进行傅里叶变换,则计算负担过于沉重。较少的特征属性可以有效降低分类模型的计算开销。Kim等[11]经过对几种常用的机器学习算法分析后认为,使用5~10个特征属性进行流量分类较为合适。有些特征属性值,必须等待流结束后才能获得,例如流持续时间、分组总数等。这一限制会影响分类模型的实时性。Nguyen等[12]提出的多子流模型,摆脱了这一限制。但子流持续时间相对较短,其特征属性容易受到网络运行状态的影响而发生变化。此外,Bernaille[13,14]、Li[15]、Huang[16]等都是根据流最初几个分组的大小和方向进行分类。这些方法具备了一定的实时检测能力,但其过分依赖于数据分组的到达顺序。在实际网络环境中由于非对称路由、网络拥塞等原因,分组通常无法保证顺序到达。因此,其稳定性得不到保证。
在获取合适的流特征属性集合之后,需要利用机器学习方法来构建流量分类模型,并以此模型对未知类型的网络流进行分类。
Roughan等[17]用k-NN和线性判别式分析方法来处理流量分类问题。Moore等[18]采用基于概率模型的朴素贝叶斯方法,虽然该方法的整体准确率只有 65%左右,但采用基于关联的快速过滤机制FCBF和核估计方法,对特征集进行筛选之后,能将准确率提高到90%以上。其他研究者还使用了贝叶斯人工神经网络[19]、支持向量机[20,21]、决策树[22,23]等有监督的机器学习方法,都取得了较好的分类准确率。Williams等[24]分析了包括朴素贝叶斯、决策树、贝叶斯网络和朴素贝叶斯树在内的几种有监督的机器学习方法后发现,它们分类的精度大致相当,但计算开销却差别很大。之后Kim等人[11]综合比较了7种常用的机器学习方法(朴素贝叶斯、带核估计的朴素贝叶斯、贝叶斯网络、C4.5决策树、k-NN、神经网络、支持向量机)后发现,它们都能取得80%以上的分类准确性。2009年,Li等人[39]分别用2003年、2004年和2006年的网络流量数据,对 C4.5决策树和带核估计的朴素贝叶斯的分类准确性进行了分析。结果表明,经 2003年的流量数据训练得到的分类模型,在对2004年和2006年的流量数据进行分类时,准确率会从96%下降至88%。这表明由机器学习得到的分类模型具有时效性。2010年,Callado等[40]进一步分析了载荷分析法和6种机器学习方法(NBTree、PART、J48、贝叶斯网络、带核估计的朴素贝叶斯和支持向量机),在校园网及商用网络中对流量分类的准确性。其结果表明在校园网环境的网络条件比较均衡,应用种类较少,机器学习算法能够取得95%的准确性。而在商用网络中,网络环境较为复杂,应用种类较多,且存在一定的未知应用,导致机器学习算法的分类准确性均低于77%,贝叶斯网络方法的准确性甚至只有10%左右。
但是,有监督的机器学习方法,都需要用预先分类好的样本集来训练分类器。如果分类样本较少,会出现过度拟合(overfitting),导致分类器的泛化能力弱。因此,有些研究者用无监督的机器学习方法进行流量分类。McGregor等[25]最早使用EM算法对网络流量进行聚类分析。Erman等[26,27]采用了K-Mean、DBSCAN和AutoClass算法来进行流量聚类,其精度明显优于朴素贝叶斯。Yuan等[28]分析了端口、IP地址、字节数等特征的熵,用聚类方法进行流量分类。之后Erman等[29]又提出了半监督的学习方法,有效减少了预处理时间,并且能够达到较高的分类精度。此类方法在聚类过程中无须使用训练样本的类型,因而能够识别部分类型尚未定义的新型网络流量。然而在聚类结束后必须进行手工标记以实现网络流量的分类,效率偏低。
从目前的研究成果来看,多数分类模型所采用的特征属性,必须等待流结束后才能获取。这大大影响了分类的实时性和实用性。虽然也有研究者仅仅根据流最初几个分组的大小和方向进行分类,使得对流量的分类有可能在流刚开始的一段时间内实现,但其过分依赖于数据分组的到达顺序,稳定性得不到保证。因此,本文对不同类别的应用数据流,根据其在最初若干分组中进行握手和参数协商的差异性,通过通信模式、载荷长度以及信息熵等特征,采用基于最短划分距离的方法构建决策树模型,对其进行流量分类。通过在4个不同类型的网络数据集上的离线分类实验,以及在校园网环境中在线流量分类实验,结果表明本方法对8种常见的网络应用,能够在分类准确性和系统开销上取得较好的综合效果。
3 双向流特征属性
本文进行分类处理的对象是双向流,因其不仅包含通信双方在2个方向上独立的网络流特征,还包含2个单向流之间的关联特征,具有更强的特征描述能力。由于 UDP协议是面向无连接的,与大多数分类模型一样,本文暂不考虑。对于TCP协议,由于双向TCP流是一个双向有序的分组序列,为统一对方向问题的讨论,本文以双向TCP流的SYN分组的方向为该流的正方向。在计算流特征属性时,忽略状态控制分组(如SYN、RST和FIN等)。因为这些分组的应用层载荷长度一般为零,对流量分类的作用不大。
在流量分类问题研究中,分类的类别可以有不同的定义。如将一组功能相似的应用定义为同一类,也可深入识别确切的应用甚至软件版本。本文将分类的类别定义为具体的应用协议,具体包括 HTTP、HTTPS、FTP、SMTP、POP3、IMAP、BitTorrent、eDonkey在内的 8个典型 Internet应用协议。
对于任何一种网络应用,通信双方会按协议状态机,在某个时刻i发出包含不同载荷数据的分组Xi。随着时间的推移,通信双方之间一次完整的流会话过程,可以视为一个离散平稳信源,用随机变量序列 X=X1X2X3X4…Xi…表示。待分类的网络流对象X可以由若干特征属性描述,设计通用的分类模型时应避免选择基于特定协议的特征。对于不同的应用,2个方向上的流特性迥异,还应考虑分别选取2个方向上的特征属性。出于实时性方面的考虑,所选取的特征属性,应该能通过流早期的若干分组计算得出。
一般来说,在消息序列X的前N个消息中,通信双方需要进行应用层握手,并协商各种参数。根据不同应用协议的约定,需要协商和传递的参数个数和类型不同,会导致其最初若干消息分组的方向、载荷长度以及载荷中每个字节取值的不确定性和差异性,其最能反映出应用协议的本质特征。因此本文使用以下特征,用于刻画前N个消息分组的这种差异性。
3.1 通信模式
通信模式(pattern),用于描述双向流中前 N个分组的方向,用形如b1b2b3…bN形式的二进制整数表示,其中,bi(i≤N)用于表示第i个分组的方向。本文规定如果第i个分组的方向与流量的正向同向,则bi取值为1,否则为0。例如N=4时,则Pattern的取值为0000~1111。
如图1所示的FTP应用,在TCP握手之后登录过程中,第1个分组方向是由服务器端发往客户端的“220”消息(b1=0),之后3个分组的方向交替出现。因此,FTP应用的通信模式一般为0101。而HTTP的第一个分组是由客户端发往服务器端的Get请求(b1=1),之后3个分组的方向受请求和响应报文的长度影响,没有固定的模式,因此HTTP的通信模式可能为1000~1111。
一般来说,不同应用协议的通信模式是统计可分的。本文对WIDE数据集(详见5.1节)中的FTP、HTTP、BitTorrent和eDonkey应用的通信模式进行统计,发现其通信模式有明显的差异,如表1所示(单位为%)。FTP和HTTP是典型的C/S应用,有92.84%的FTP流的通信模式为0101,有74.39%的HTTP流,其通信模式为 1000。而 BitTorrent和eDonkey这2种典型的P2P应用,其通信模式主要为1010和1001。
3.2 载荷长度
双向流消息序列中,任一时刻发出的消息Xi,其载荷长度(payload size)因协议和传输的参数而异。因此,本文用Si表示消息分组Xi的应用层载荷大小。与其他研究者使用分组大小[12,13,15~18,22]特征不同的是,本文使用的是以字节为单位的应用层载荷大小。因为分组中可能含有IP或TCP的可选数据,使用分组大小不能准确描述各种应用协议的应用层握手或信令长度的特征。
3.3 分组信息熵
对任一消息Xi,其载荷内容受协议和传输参数而异,其每个字节都取且可取遍字符集K={k, 0≤k≤255}。本文将分组Xi载荷数据中每个字节的取值当作一组随机事件,即Xi={xk, 0≤k≤255},用xk表示在分组Xi的载荷数据中,值为k的字节出现的次数,则Xi的信息熵为

其中,

对于一个完整的双向流消息序列X,其前N个分组的信息熵构成了一个熵序列H( X1),H( X2), …, H( XN),反映了每个分组Xi各自所含信息量的多少。但双向流是一个双向有序的分组序列,而由于H( Xi)的非负性(H( Xi)≥0),分组信息熵只能刻画信息量的多少,不能描述分组的方向。因此→本文定义分组Xi的有向熵(directed entropy)( Xi),用于增强对方向性的描述, ( Xi)可定义为

其中,sgn(x)为符号函数,bi为Pattern值,表示分组Xi的方向,其取值为1或0。若Xi与流的正向同向,则bi=1,sgn(bi-0.5)=1, ( Xi)=H( Xi)≥0,表示此时双向流按正向传递了大小为H( Xi)的信息。若→Xi与流的正向相反,则bi=0,sgn(bi-0.5)=-1,H( Xi)=-H( Xi)≤0,表示双向流按负向传递了大小为H( Xi)的信息。→此时,双向流前N个分组的有向熵构成的熵序列( X1), ( X2),…,( XN),从微观上能有效刻画双向流的信息传递大小和方向。此外,为了从整体上描述双向流的信→息流动情况,本文定义了双向流X的有向信息熵H( X):

3.4 双向流特征属性集
因此本文使用表2所示的特征属性作为双向流的分类依据。虽然端口号已经不能作为主要的分类特征,但它仍是一个重要特征,尤其是对一些传统的Internet应用进行分类时[2]。因此,本文仍使用端口号(port)作为描述双向流的特征之一。

表2 双向流的特征属性
4 基于最短划分距离的决策树
本文上述特征属性,采用决策树算法对真实网络流量进行分类。决策树是以实例为基础的归纳学习算法,能从一组无序的已知样本中,归纳出以倒挂的树状结构表示的分类知识。决策树的每个内部节点,代表对一个或多个特征属性的取值进行测试比较,并根据比较结果确定该节点的分枝,每个叶节点就代表一个类别。决策树算法应用简便,只要训练样本集能够用属性向量和类别表示,就能使用该算法。在使用决策树模型对类型未知的样本进行分类时,只需从根节点开始逐步对该样本的特征属性进行测试,并沿着相应的分支直到某个叶节点为止,此时叶节点所代表的类型即为该样本的类型。与其他机器学习算法相比,决策树算法相对简单,具有较高的数据处理效率,适合进行流量的实时分类[22,23]。
4.1 基于信息熵的决策树
在决策树创建过程中,如何确定内部节点的分枝是最为关键的问题。对当前节点进行分枝,对应着当前样本集的一个划分。采用不同的划分标准得到的决策树各不相同。在网络流量分类问题中,T为已知类别的流量样本数据集,包含m种类别{c1, c2,…,cm},每个流样本的特征属性集为A={a1,a2,…,ak}。根据样本类别可得T的一个理想划分T={t1, t2,…,tm},其中,样本子集ti中的样本都属于类别ci,则该理想划分的信息熵为

如果以选择特征属性ai(1≤i≤k)作为测试条件α,根据该属性的不同取值,可得T的另一个划分T′={t1′, t2′,…,tr′} ,则该划分的信息熵为

其中,
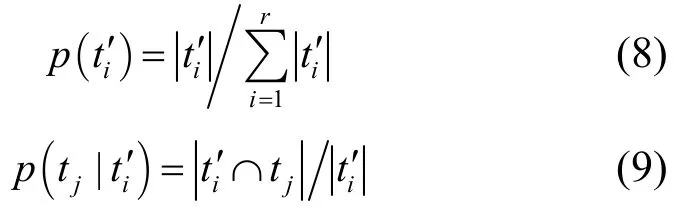
式(9)表示划分T′中属于子集t′i的样本,在理想划分中属于子集tj的概率。因此,选择ai对T进行划分所获得的信息熵增益为

ID3算法中[30],根据每个测试条件的信息熵增益,选择增益最大的测试来确定当前节点的分枝。对大多数应用,信息熵增益法都能取得较好的结果。但是其最大的缺陷是偏爱输出分枝较多的测试条件,导致决策树规模过大,泛化能力弱。随后在改进的C4.5算法中[31],引入测试条件α带来的分割信息熵。

用信息增益与分割信息熵的比值,即信息增益率作为选择测试条件的依据。

但是采用增益率标准,当划分产生的分割信息量很小时,增益率的值不稳定。一种情况是,如果划分后只有一个子集中有样本,会导致分母——分割信息熵为零。另一种情况是,对于某些划分,虽然产生的信息熵增益很小,但由于分割信息熵也很小,其信息增益率很大。
4.2 基于划分距离的决策树
为克服C4.5算法存在的上述2个缺点,本文用Mantaras范式距离来定义2个划分间的距离[32]。在各属性中选择与理想划分距离最近的属性作为当前节点的测试条件,用最短距离划分的办法来构建决策树。
根据样本集T的理想划分T={t1,t2,…,tm}和以属性ai作为测试条件α所得的划分T′={t1′, t2′,…,tr′ } ,则划分T′对于理想划分T的条件熵为

其中,

式(14)表示一个样本在划分T′中属于子集t′i,而在理想划分T中属于子集tj的概率。同理,理想划分T对于划分T′的条件熵为

划分T′与理想划分T的联合熵为

因此,划分T′与理想划分T的Mantaras范式距离为

按照最短距离标准,首先计算每个可能的特征属性所对应的划分与理想划分之间的距离,然后选择距离最小的划分所对应的属性作为当前节点的测试属性。最短距离法能有效克服信息增益率方法的缺陷,算法的稳定性好,其构建的决策树规模更小,分类速度更快。
4.3 属性离散化和剪枝
如表2所示,本文使用的流特征中,除端口和通信模式为离散属性外,其余均为连续属性。如果直接处理连续属性,一旦被选为决策树内部节点的测试条件,则会产生很多分枝,造成决策树结构庞大。因此,必须对连续属性进行离散化。本文采用划分距离评估连续区间的分割点,即选择划分后的2个样本子集间Mantaras距离最小的分割点作为最佳分割点[32],以最短描述长度准则(MDLP,minimum description length principle)作为离散化过程的结束条件。
在无冲突的情况下,算法生成的决策树将与训练集完全一致。但由于训练集里的实例可能包含了噪声点和孤立点,训练中生成的树会尝试拟合每一个异常的细节。这种过度拟合的结果,是对训练集分类的效果很好,但用它来对新的数据集进行分类时可能并不理想。因此有必要对生成的初始决策树进行剪枝,以得到更一般的分类规则。因此,本文使用PEP(pessimistic error pruning)算法[31]对生成的初始决策树进行剪枝,进而得到最终的决策树。由于PEP算法在剪枝过程中,对每棵子树最多只检查一次,且不需要额外的剪枝数据集,因此其速度较快,适用于样本数较多的数据集。
此外,在初始特征属性集中,属性之间存在的相关性和冗余性,不仅增加计算复杂度,并且很可能会降低分类的准确性。一般可以利用特征过滤算法,发现属性之间的关联性,从而滤除冗余属性。但是特征过滤算法可能会利用局部信息过滤特征属性,造成局部最优性问题。而且在决策树本身的构造中,实际上已经包含了属性选择过程,所以本文没有采用特征过滤算法。
5 实验与分析
5.1 实验环境
为了验证本文方法在分类准确性和实时性方面的性能,实现了一个原型系统,并部署在苏州大学计算机科学与技术学院局域网边缘的路由交换机上,其拓扑结构如图2所示。

图2 实验环境拓扑结构
该网络拥有约1 200台主机,其边缘为Cisco 4507路由交换机,通过吉比特每秒链路与苏州大学网络中心核心路由器相连。在该边缘路由交换机上通过端口镜像,将其出口的全部流量镜像到本文实验用的Dell PowerEdge 1950服务器上。服务器配置为1路4核至强CPU,8GB内存,146GB硬盘,运行Windows 7操作系统。该服务器主要用于:①用真实网络的离线流量数据,训练基于最短划分距离的决策树模型,并与其他分类算法的准确性进行对比;② 将经过训练得到的分类模型,用于在线流量分类,以验证其实时分类的能力。
5.2 网络流量数据与工具
本文首先使用4个真实网络流量数据,对决策树分类模型进行离线训练和验证。数据的采集点包括局域网和广域网,时间跨度从2003年到2011年,分别是 LBNL[33]、UNIBS[34]、WIDE[35]和 SUDA 数据集。
LBNL数据集来自劳伦斯伯克利国家实验室(lawrence Berkeley national laboratory)局域网出口的Trace数据集,本文选用2003年1月12日的数据。UNIBS数据集来自University of Brescia办公网,约有1 000个左右的用户,通过吉比特以太网链路接入Internet。采集时间为 2007年某一周的白天。WIDE数据集来自 WIDE互联网测量与分析项目采集的骨干网链路的 Trace数据。本文采用的是 F点获取的2009年10月1日20:00~21:00的数据。其中,LBNL和UNIBS原始Trace中包含全部分组载荷,WIDE原始Trace中,每个分组包含40byte的载荷内容,三者对涉及用户隐私的信息经过匿名处理。最后的SUDA数据集,采集自5.1节所述的苏州大学计算机科学与技术学院的局域网出口,采集时间为2011年4月13日至15日,数据集中每个分组包含40byte的载荷。
对上述4个离线数据集,首先使用Tcptrace软件[36]提取出双向均发送一个以上分组的双向 TCP流,并计算表2所述双向流的特征属性。本文分类的对象为HTTP、HTTPS、FTP、SMTP、POP3、IMAP、BitTorrent、eDonkey等 8种应用协议。首先使用Analyzer载荷分析软件[38],对离线数据集中这8种应用的双向TCP流,通过其应用层签名进行标记。经过流特征属性提取和标记后的数据集中,各种应用协议双向流的数量如表3所示。其中,LBNL数据集中没有BitTorrent和eDonkey的流量,UNIBS数据集中没有IMAP4的流量。

表3 数据集中各种协议的样本数
本文的决策树分类模型及其剪枝算法,是基于Weka平台[37]实现的。用于与本文方法进行对比的常用分类算法有k-NN(k-nearest neighbors)、SVM(support vector machines)、NBK(naïve bayes kernel estimation)和 C4.5决策树算法,这些算法也都基于Weka平台实现。
5.3 评价指标
本文采用如下准确性指标对分类模型的分类能力进行评估。在训练数据集中的流样本,分别属于m种类别。对类别i,令TPi表示其全部样本中被正确分类的样本数,FNi表示被误判为其他类别的样本数,FPi表示其他类别的样本中被误判为类别i的样本数,则定义如下分类准确性指标。
1) 类别i的召回率(recall)

2) 类别i的准确率(precision)

3) 类别i的F值(F-measure)

4) 整体准确率(overall accuracy)
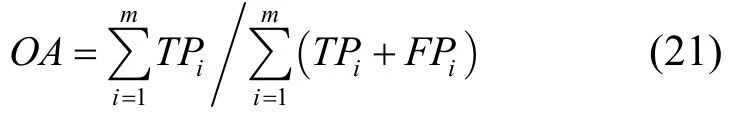
上述准确性指标中,单个类别的召回率和准确率能够反映分类模型针对某个类型的分类能力,而F值对模型分类能力的综合评价能力更好,因为F值是召回率和准确率的调和平均值。此外,分类模型的整体准确率,能从整体上反映正确分类的样本数占总样本数的比例。因此它和F值指标的应用最广,几乎为所有研究所采纳[2]。另外,本文还使用训练时间、分类时间、吞吐率等指标来评估分类模型的开销。
本文使用每个流的机器处理时间来评价分类模型的实时分类性能。流处理时间是指从每个流的第一个分组进入机器开始,然后计算流特征属性,最后由分类模型对流所属应用类型进行标记的全部时间,其包括3个部分。
1) 流缓存时间tcache。由于本文用表2所定义的流特征属性,需要处理每个TCP流中前N个载荷长度不为零的分组。因此tcache时间是指每个流的第一个分组进入机器开始,到前N个载荷长度不为零的分组全部到达的时间。
2) 属性计算时间tattributes,是指按表2的定义计算TCP流的特征属性的时间。
3) 分类时间 tclassification,是指分类模型依据每个流的特征属性,对流所属应用类型进行标记的时间。
这3部分机器处理时间,都与分类模型需要对每个流进行处理的分组个数N有关。N越大,则3部分时间都会延长,导致分类模型对流所属应用类型进行标记的时机越迟,其实时性变差;而N越小,虽然有利于提高分类实时性,但会导致分类的准确性降低。因此,本文用这3个指标来评价模型的实时分类能力,同时考虑准确性指标,以获得最佳的分类效果。
5.4 离线训练和验证
本文首先在4个离线数据集上,进行了3个实验,主要对本文提出的基于最短划分距离的决策树模型的分类准确性进行评价。其中,第1个实验用于确定本文模型中的待定参数 N,即每个流需要分析的分组数量。第2个实验在确定N取值的条件下,对比各种机器学习方法的分类整体准确性。第3个实验用于分析抽样率对单个类别分类准确性的影响。
实验1 确定待定参数N。
为了确定每个流需要分析的分组个数N,首先将4个离线数据集,用随机抽样的方法分别分成相同大小的A、B 2个子集,子集中每类应用协议的流样本的比例与原数据集保持一致,然后分别用不同的N取值,在子集A上进行训练以获得决策树分类模型,在子集B上对模型进行验证。重复实验10次,每次重新对离线数据集进行随机抽样,获得10组不同的A、B子集。综合考虑10次实验中分类模型的平均整体准确率和系统开销等指标后,确定最佳的N取值。

图3 不同N取值下的整体准确率
图3给出了不同N取值(N=2, 4, 6, 8, 10)条件下,分类模型在4个离线数据集上的整体准确率指标。可以看出,每个流如果只分析2个分组的信息,因为获取的信息不充分,导致整体准确率较低。分类模型的整体准确率随着N值的增加而提高。当N取6时,即每个流分析的分组数量为6个时,分类模型的整体准确率达到最大值,之后则略有下降。因为大多数协议的应用层握手过程,一般都在4~6个分组中完成,少数会持续6~8个分组,之后便开始传输数据。进行数据传输时,受数据内容和长度的影响,其分组的方向、长度和信息熵等特征不稳定,导致分类器的整体准确率有所下降。
表4给出了不同N取值条件下,分类模型在4个数据集上的训练和分类时间,以及吞吐率指标。决策树分类模型的建模过程相对复杂,因此导致其训练时间较长。但分类时只需根据流的特征属性在树状模型中,自上而下的进行简单比较,因此分类时间要明显少于训练时间,适合于实时的流量分类问题。但是随着N的增加,需要计算和进行测试的特征属性较多,训练和分类时间都大大增加,吞吐率也逐渐下降。
因此,从分类的整体准确率考虑,N=6是最佳的取值。此时在4个数据集上的分类准确性分别为94.0%(LBNL),96.7%(UNIBS),92.6%(WIDE)和95.8%(SUDA),平均吞吐率保持在5.1×104流/秒。
实验2 不同分类算法的准确性对比。
在第1个实验得到的10组A、B子集上,实验2分别用不同的机器学习算法,用本文使用的特征集进行训练和分类,以对比本文的基于最短划分距离的决策树(DBDT, distance based decision tree)算法和其他机器学习算法,在分类准确性和分类性能的差异。
图4给出了在4个离线数据集上,每种算法的分类整体准确率指标。可以看到,k-NN和NBK算法的准确率较低,本文的DBDT算法和SVM、C4.5算法的整体准确率大致相当,在样本数量较少的 UNIBS数据集上,略低于SVM算法。这是因为SVM算法是专门针对小样本情况下的机器学习算法,而决策树算法无论样本规模如何,都能取得较好的分类准确性。

图4 5种算法的分类整体准确率比较
表5给出了在N=6的条件下,5种分类算法在4个数据集上训练和分类时间以及吞吐率指标。

表4 不同N取值下的算法开销

表5 5种算法的性能对比
从训练时间来看,决策树算法(DBDT和C4.5)并不是最优的。但是在分类时间和吞吐率上,决策树算法仅需根据样本的特征属性,在决策树上自上而下的依次比较,处理相对简单,因此具有较高的数据处理效率。与 C4.5决策树算法相比,DBDT采用最短划分距离构建决策树,其克服了C4.5算法的缺陷,构建的决策树规模更小,因此其训练和分类速度更快。
实验3 抽样率对准确率的影响。
在第一个实验得到的10组A、B子集上,实验3主要分析不同抽样率对每个类别的分类准确率的影响。首先随机抽取A子集中每类应用协议10%的流样本,进行训练以获得分类模型,然后在子集B上对模型进行验证。随后抽样率按 10%递增直至100%,重复实验10次,以获得不同抽样率下单个类别的平均分类准确性指标。图5~图8分别给出了在LBNL、UNIBS、WIDE和SUDA数据集的A子集上,用不同抽样率进行训练后,用B子集进行验证得到F值的10次实验平均值。
如图5所示,在LBNL数据集上,每个类别的F值随着抽样率的递增而增加。但在原始数据集中,由于POP3和IMAP4协议样本数量较少,分别为1 172和7 677个流。在对A子集进行小样本抽样(10%~50%)后,样本数量严重不足,导致分类器训练不充分,对某些特殊样本过度训练。因此F值较低,且波动较大。而HTTP、SMTP和FTP的样本数量相对较多,虽然在小样本抽样条件下的F值较低,但仍高于POP3和IMAP4。

图5 LBNL数据集上的F值
如图6所示,在UNIBS数据集上,每个类别的F值随着抽样率变化的趋势与LBNL相似,即对eDonkey协议流的分类F值较低,HTTPS、SMTP和POP3的分类F值较高。

图6 UNIBS数据集上的F值
如图7所示,在WIDE数据集上,每个类别的F值的变化趋势与前两者相似,但整体的波动性要小。这是由于WIDE数据集中,每个类别的样本绝对数量要大于前两者,小样本抽样后得到的样本数量仍然较多。虽然对分类器的训练仍然不充分,导致F值较低,但在特殊样本上进行过度训练的概率较低,因此F值的波动比较平稳。

图7 WIDE数据集上的F值
如图8所示,在SUDA数据集上,除IMAP4和FTP外,其他类别的F值变化趋势与WIDE相似。这是由于SUDA数据集中,IMAP4和FTP类别的样本较少,而其他类别的样本较多。

图8 SUDA数据集上的F值
因此,针对单个类别的应用流量,为了取得较好的分类准确性,其用于训练的流样本的绝对数量必须保持一定的规模,才能避免分类模型对噪声点和孤立点的过度拟合,导致分类准确性的波动较大。
5.5 在线流量分类
除验证本文模型的准确性指标外,在5.1节所述的环境中,还进行了流量的在线分类实验,以验证其实时分类能力。首先在实验服务器上,用Tcptrace[36]捕获镜像流量中的TCP流,然后计算表2所定义的流特征属性。利用离线实验中,经由SUDA离线流量数据训练得到的分类模型进行流量的在线分类,用流处理时间指标来评价其实时分类的性能。同时在实验服务器上,还部署了Analyzer软件,用于事后检验分类的准确性。
考虑到内存开销和计算复杂度问题,实验中没有捕获每个流的所有分组。根据图3和表4所示的离线实验结果,从准确性角度考虑,N=6时是最佳结果。但是,在线流量分类对时间的要求更为关键。根据5.2节对机器处理时间与N取值的关系分析,在同时保持较高准确性和分类性能的前提下,N=4也是较好的结果。因此,在线分类实验一共持续 6天时间,从2011年4月17日到22日。其中前3天的实验,N的取值为6,即捕获了每个双向TCP流的前6个载荷不为零的分组;后3天的实验中,N取4,用于验证N取值与模型实时分类能力的影响。另外,考虑到实际网络中存在一定比例的短流(有效分组数少于N个)以及其他TCP错误,因此实验中对每个流的处理设置一个超时时间ttimeout=10s。如果在 ttimeout时间内,一个 TCP流的有效分组数量少于 N,则不进行处理,以节约内存的开销。
本文首先分析了不同的N取值,对在线分类的整体准确性的影响,如图9所示。实验每6个小时统计一次在线分类的整体准确率指标,在N分别取6和4的各自3天实验中,一共取得12组数据。通过对比可以看到 N=6的 3天实验中,分类的整体准确率平均为 93%。而 N=4时,分类的整体准确率会有所降低,但仍能取得平均90%的整体准确率。
然后本文分析了在不同N取值条件下,机器的处理时间和内存消耗的情况,如图10~图13所示。图10所示为在不同N取值条件下,流缓存时间tcache的累计分布情况。当N=6时,有52%的流缓存时间小于100ms,99%的流缓存时间小于1 000ms。而当N=4时,则74%的流缓存时间小于100ms,99%的流缓存时间小于500ms。这说明较小的N取值,可以大大减少流缓存的时间。

图9 不同N取值下的在线分类整体准确率

图10 不同N取值下的tcache累计分布
图11所示为在不同N取值条件下,属性计算时间tattributes的累计分布情况。当N=6时,有57%的流属性计算时间小于 100μs,99%的流属性计算时间小于700μs。而当N=4时,则83%的流属性计算时间小于100μs,99%的流属性计算时间小于300μs。较小的N取值也可以有效减少流缓存的时间。

图11 不同N取值下的tattributes累计分布
图12所示为在不同N取值条件下,流分类时间tclassification的累计分布情况。当N=6时,有83%的流分类时间小于 10μs,99%的流分类时间小于50μs。而当N=4时,则89%的流分类时间小于10μs,99%的流分类时间小于30μs。较小的N取值,虽然可以减少流分类时间,但程度不如对流缓存时间和属性计算时间提高的那样明显。

图12 不同N取值下的tclassification累计分布
图13所示为在不同N取值下,系统的内存开销情况。实验每6个小时统计一次内存的平均利用率指标,在N分别取6和4的3天实验中,一共取得12组数据。可以看到N=6的3天实验中,实验服务器的内存利用率平均为71%。而N=4时,内存利用率平均为32%。这主要是由于较小的N取值可以大大降低流缓存的时间,使得每个流得以尽快的处理,释放大量的内存空间。

图13 不同N取值下的内存开销
对流量进行在线分类时,实时性是最主要的要求。因此,综合考虑准确性、处理时间和内存开销等因素,N取4是比较理想的结果。此时本文提出的基于最短划分距离的决策树分类方法,可以取得90%的分类准确性,99%的流处理时间小于 500ms(流缓存时间)+300μs(属性计算时间)+30μs(分类时间),内存利用率平均为32%。
6 结束语
利用机器学习方法,构造基于流统计特征的网络流量分类模型,是流量分类问题的研究热点。目前大多数的分类模型必须等待流结束后,才能对其进行分类,实时性较差。一些模型从实时性的角度出发,仅仅根据流最初若干分组的方向和大小进行分类,导致其过度依赖分组的到达顺序,稳定性较差。本文除了考虑流最初几个分组的方向、载荷大小特征,主要根据分组的信息熵等特征,采用最短划分距离的方法构建决策树分类模型,对其进行分类。根据在真实网络 Trace数据集上,以及在线流量分类的实验结果表明,本文方法对8种常见的网络应用能够取得较好的分类准确性和综合分类性能。
[1] MOORE A W, PAPAGIANNAKI K. Toward the accurate identification of network applications[A]. Proc of PAM’05[C]. Boston, USA,2005.41-54.
[2] SEN S, SPATSCHECK O, WANG D. Accurate, scalable in-network identification of P2P traffic using application signatures[A]. Proc of WWW’04[C]. New York, USA, 2004.512-521.
[3] KARAGIANNIS T, BROIDO A, BROWNLEE N, et al. Is P2P dying or just hiding[A]. Proc. of GLOBECOM’04[C]. Dallas, USA, 2004.
[4] HAFFNER P, SEN S, SPATSCHECK O, et al. ACAS: automated construction of application signatures[A]. Proc of SIGCOMM Mine-Net’05[C]. New York, USA, 2005. 197-202.
[5] MA J, LEVCHENKO K, KREBICH C, et al. Unexpected means of protocol inference[A]. Proc of IMC’06[C]. Rio de Janeiro, Brazil,2006.313-326.
[6] KARAGIANNIS T, PAPAGIANNAKI K, FALOUTSOS M. BLINC:multilevel traffic classification in the dark[J]. SIGCOMM Computer Communication Review, 2005, 35(4): 229-240.
[7] XU K, ZHANG Z, BHATTACHARYYA S. Profiling Internet backbone traffic: behavior models and applications[A]. Proc of SIGCOMM’05[C]. Philadelphia, USA, 2005.
[8] DAHMOUNI H, VATON S, ROSSE D. A markovian signature-based approach to IP traffic classification[A]. Proc of SIGCOMM Mine-Net’07[C]. New York, USA, 2007.29-34.
[9] ERMAN J, ARLITT M, MAHANTI A. Traffic classification using clustering algorithms[A]. Proc of SIGCOMM MineNet’06[C]. New York, USA, 2006. 281-286.
[10] MOORE A W, ZUEV D, CROGAN M. Discriminators for use in flow-based classification[R]. RR-05-13, Queen Mary University of London, 2005.
[11] KIM H, CLAFFY K, FOMENKOV M, et al. Internet traffic classification demystified: myths, caveats, and the best practices[A]. Proc of ACM CoNEXT’08[C]. New York, USA, 2008.1-12.
[12] NGUYEN T, ARMITAGE G. Training on multiple sub-flows to optimize the use of Machine Learning classifiers in real-world IP networks[A]. Proc of IEEE LCN’06[C]. Tampa, 2006.
[13] BERNAILLE L, TEIXEIRA R., AKODKENOU I. Traffic classification on the fly[J]. ACM SIGCOMM Computer Communication Review, 2006, 36(2): 23-26.
[14] BERNAILLE L, TEIXEIRA R, SALAMATIAN K. Early application identification[A]. Proc of CoNEXT’06[C]. Lisboa, Portugal, 2006. 1-12.
[15] LI J, ZHANG S, LU Y, et al. Real-time P2P traffic identification[A].Proc of GLOBECOM’08[C]. Dallas, USA, 2008. 1-5.
[16] HUANG N, JAI G, CHAO H. Early identification traffic with application characteristics[A]. Proc of ICC’08[C]. Beijing, China, 2008.5788-5792.
[17] ROUGHAN M, SEN S, SPATSCHECK O, et al. Class-of-service mapping for QoS: a statistical signature-based approach to ip traffic classification[A]. Proc of IMC’04[C]. New York, USA, 2004. 135-148.
[18] MOORE A W, ZUEV D. Internet traffic classification using bayesian techniques[A]. Proc of SIGMETRICS’05[C]. Alberta, Canada, 2005.50-60.
[19] AULD T, MOORE A, GULL S F. Bayesian neural networks for Internet traffic classification[J]. IEEE Transactions on Neural Networks,2007, 18(1): 223-239.
[20] 徐鹏, 刘琼, 林森. 基于支持向量机的Internet流量分类研究[J]. 计算机研究与发展, 2009, 46(3): 407-414.XU P, LIU Q, LIN S. Internet traffic classification using support vector machine[J].Journal of Computer Research and Development, 2009,46(3): 407-414.
[21] WANG R, LIU Y, YANG Y. A new method for P2P traffic identification based on support vector machine[A]. Proc of AIML’06[C]. Sharm El Sheikh, Egypt, 2006. 967-974.
[22] 徐鹏, 林森. 基于C4.5决策树的流量分类方法[J]. 软件学报, 2009,20(10): 2692-2704.XU P, LIN S. Internet traffic classification using C4.5 decision tree[J].Journal of Software, 2009, 20(10): 2692-2704.
[23] 王宇, 余顺争. 网络流量的决策树分类[J]. 小型微型计算机系统,2009, 30(11): 2150-2156.WANG Y, YU S Z. Internet traffic classification based on decision tree[J]. Journal of Chinese Computer Systems, 2009, 30(11): 2150-2156.
[24] WILLIAMS N, ZANDER S, ARMITAGES G. A preliminary performance comparison of five machine learning algorithms for practical IP traffic flow classification[J]. SIGCOMM Computer Communication Review, 2006, 36(5): 5-16.
[25] MCGREGOR A, HALL M, LORIER P, et al. Flow clustering using machine learning techniques[A]. Proc of PAM’04[C]. Antibes Juanles- Pins, France, 2004. 205-214.
[26] ERMAN J, ARLITT M, MAHANTI A. Traffic classification using clustering algorithms[A]. Proc of SIGCOMM MineNet’06[C]. Pisa,Italy, 2006. 281-286.
[27] ERMAN J., ARLITT M., MAHANTI A. Internet traffic identification using machine learning[A]. Proc of GLOBECOM’06[C]. San Francisco, USA, 2006.
[28] YUAN J, LI Z, YUAN R. Information entropy based clustering method for unsupervised Internet traffic classification[A]. Proc of ICC’08[C]. Beijing, China, 2008. 1588-1592.
[29] ERMAN J, ARLITT M, MAHANTI A. Offline/real-time traffic classification using semi-supervised learning[J]. Performance Evaluation.2007, 64(9-12): 1194-1213.
[30] QUINLAN R. Discovering Rules from Large Collections of Examples:a Case Study[M]. Expert Edinburgh University Press, 1979.
[31] QUINLAN R. C4.5: Programs for Machine Learning[M]. San Francisco, USA. Morgan Kaufmann Publishers Inc, 1993.
[32] LOPEZ R, MANTARAS D. A Distance-based attribute selection measure for decision tree induction[J]. Machine Learning, 1991, 6(1):81-92.
[33] LBNL traces[EB/OL].http://ee.lbl.gov/anonymized-traces.html.
[34] CROTTI M, DUSI M, GRINGOLI F, et al. Traffic classification through simple statistical fingerprinting[J]. ACM SIGCOMM Computer Communication Review, 2007, 37(1):5-16.
[35] WIDE Project[EB/OL]. http://mawi.wide.ad.jp/mawi/.
[36] Tcptrace official homepage[EB/OL]. http://www.tcptrace.org.
[37] Weka 3: Data mining software in Java[EB/OL]. http://www.cs. waikato. ac.nz/ml/weak.
[38] Analyzer: a public domain protocol analyzer[EB/OL]. http://analyzer.polito.it/.
[39] LI W, CANINI M, MOORE A. Efficient application identification and the temporal and spatial stability of classification schema[J]. Computer Networks, 2009, 53(6): 790-809.
[40] CALLADO A, KELNER J, SADOK D, et al. Better network traffic identification through the independent combination of techniques[J].Journal of Network and Computer Applications, 2010, 33(10):433-446.
