变异特征加权的异常语音说话人识别算法*
2012-07-31何俊李艳雄贺前华李威
何俊 李艳雄 贺前华 李威
(华南理工大学电子与信息学院,广东广州510640)
说话人识别(SR)是以语音为依据对说话人进行别识,从而达到身份鉴别和认证的技术,已广泛应用于国防、公安的身份鉴定系统、电话银行及电子商务的身份确认系统及各类门禁系统[1-2].目前各类说话人识别和认证系统在实际应用时受环境噪声和异常语音的影响,识别率急剧下降;同时,现实生活中引起说话人语音变异的因素较多,如感冒、咽喉炎、淋巴炎、反胃酸、情绪波动等.如何解决目前声纹身份认证系统的普适性低、鲁棒性差问题及异常语音问题,受到了广泛的关注[3-5].
目前,用于提高语音识别系统鲁棒性的经典方法可分为3类[6]:(1)基于特征的方法,直接去掉说话人特征信息中的噪声,如倒谱均值归一化(CMN)、RASTA滤波处理、嵌入方法(WM)和健壮参数;(2)基于打分的方法,如模型打分和特征帧层打分;(3)基于模型的方法,试图把失真特征合并到说话人本身的模型中,以取得系统的鲁棒性,如并行模型组合(PMC).
基于特征的方法主要集中于稳健特征的提取和加权处理.特征加权就是通过抑制由噪声引起的特征变化对识别模型分数的影响,提高纯净语音特征对识别模型分数的权重,从而达到抑制噪声语音对说话人识别结果的影响.然而,在实际应用环境中获得纯净语音是比较困难的.文献[7]中使用CMN算法对加性噪声的语音进行识别,相对不进行CMN处理的识别率提高了2.6%.文献[8]中根据心理听觉声学原理对Mel倒谱特征进行加权,用安静语音进行说话人识别,结果表明通过加权能使识别率提高1.3%.文献[9]用统计各阶MFCC特征对说话人识别的贡献,根据贡献大小进行特征加权,用TIMIT语音数据库进行说话人识别,识别率比不加权时提高了0.6%.
对于安静和正常语音,文献[8-9]中算法的性能稍有提高.但在实际应用中,说话人总是身处复杂的声学环境中,同时说话人自身的生理因素也是复杂多变的.实际应用的身份认证和说话人识别系统的性能不仅要面临复杂的环境噪声干扰,而且还要面临因说话人的发音器官病变引起语音异常的影响.根据心理听觉声学原理对Mel倒谱进行加权处理,面对复杂背景噪声环境和病变异常语音等情况,该算法表现出较严重的局限性.根据各阶特征对说话人识别的贡献进行加权,对于因说话人发音器官病变而引起的变异语音,不仅难以统计各阶特征对说话人识别的贡献,而且可能出现贡献大的特征变异严重.如何对它进行有效加权还有待研究.
CMN算法对加性噪声污染语音的识别效果比较明显,但对病变异常语音的识别效果较差,因为病变异常语音主要是由于说话人的发音器官的功能性失调(表现为发浊音时声带振动不到位或声带打开不全及关闭不严密等),使得语音谱高频部分出现噪声.这种噪声不同于环境噪声(如加性噪声),它表现出不连续性、隐蔽性强,其变化具有非平稳性,发音器官的不同病变对各音素的影响不一样.
当说话人识别认证系统面临说话人异常语音时,常用的特征加权算法难以统计异常语音各阶特征对说话人识别的贡献并对变异特征进行加权,导致识别认证系统的性能大幅下降.为此,文中以正常说话人发音器官病变引起的异常语音为研究对象,提出了一种变异特征加权的异常语音说话人识别算法.首先通过提取大量不同说话人的不同文本内容的正常语音MFCC特征,建立正常语音模板,旨在描述正常语音说话人的各阶特征概率分布;然后分别用K-L距离(Kullback-Leibler Divergence)[10]和欧式距离度量变异语音特征与正常语音特征模板之间的差异(变异程度),根据变异语音各阶特征的变异程度对变异语音特征进行加权,并将加权后的MFCC特征送进高斯混合模型(GMM)进行说话人识别;最后通过实验验证算法的有效性.
1 正常语音特征模板与变异分析
1.1 正常语音特征模板
MFCC是语音信号处理中常用的特征,也是说话人识别中区分性最好的一个特征.为了刻画正常语音MFCC特征的概率分布,便于度量异常语音MFCC特征的变异程度,文中首先建立一个正常语音特征模板(NSFT).
设si表示第i段语音,si的n阶MFCC特征可以表示为为第i段语音的第k阶MFCC特征表示第i段语音中第r帧的第k阶分量.
设FNSFT为m段正常语音的特征模板,则FNSFT的各阶MFCC特征可以表示如下:

1.2 变异分析
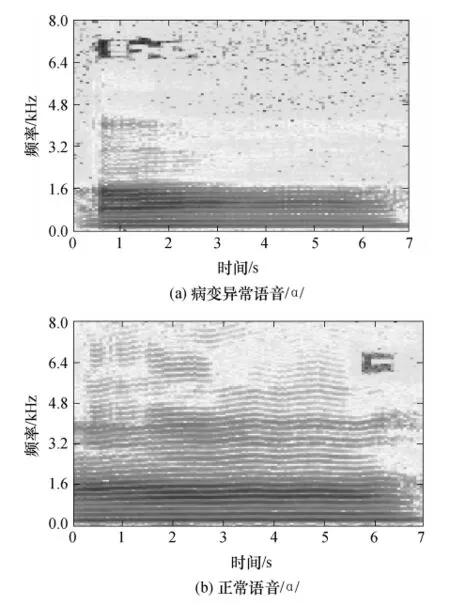
图1 病变异常语音/ɑ/和正常语音/ɑ/的语谱图Fig.1 Spectra of abnormal speech/ɑ /and normal speech/ɑ /
文中讨论的病变异常语音主要是由于说话人发音器官的功能性失调而引起,表现为发浊音时声带振动不到位或声带打开不完全及关闭不严密等,而使说话人语音发声变异,即轻微的嘶哑声.从频谱图看,变异语音的高频部分出现噪声现象.图1给出了病变异常语音/ɑ/和正常语音/ɑ/的频谱图.从图1(a)可知,频率大于4.8 kHz的病变异常语音出现能量较大的噪声成分,频率大于6.0 kHz时,语音信息非常小.在1.6~4.8kHz区间能量带间距变大,在0~1.6kHz内异常语音的能量带间距缩小,整体下移,能量带分布较密.这说明异常语音对高频部分的影响较大,中频部分整体下移,对低频部分的影响较小.从图1(b)可知,在6.0~8.0 kHz内正常语音存在表征说话人特征的语音信号,在1.6~4.8 kHz内正常语音的能量带分布明显比异常语音密,在0~1.6kHz内能量带分布比异常语音稀疏,纹理浓.这说明正常语音的低频部分分布稀疏,中频部分有较多的说话人信息能量带分布,高频部分还有说话人信息.图1表明,正常语音和异常语音在频谱图上表现出较明显的差异.
为了寻求异常语音在特征层的差异,文中以MFCC特征为语音特征来分析其特征层的变化,以12阶MFCC特征为参考进行实验研究.用3600条时长为3~5s的正常语音建立正常语音特征模板,其各阶MFCC特征的概率分布如图2(a)所示.

图2 正常语音和单条病变语音的12阶MFCC特征概率分布Fig.2 12-order MFCC feature probability distribution of normal speech and one abnormal speech
为了分析发音器官病变对语音特征层的影响,分别使用1条时长约为17 s的单个病变语音和826条时长为15~20s的异常语音来分析各阶特征相对于正常语音特征模板中各阶特征的个体差异性和统计差异性,单条病变语音的各阶MFCC特征的概率分布如图2(b)所示.
K-L距离[10]常用来量化两个概率分布或密度间的差异,是一种非对称性差异的度量方法,并不是严格上的距离公式.K-L距离广泛应用于语音处理中[11-12].文中用 K-L 距离来度量单条异常语音特征和正常语音特征模板的个体差异性、826条异常语音特征和正常语音特征模板的统计差异性,各阶MFCC特征的K-L距离如表1所示.从表1可知:语音变异对其各阶特征的影响及影响幅度是不相同的,这是因为产生语音变异的因素很多,有咽喉炎、声带发炎、口腔溃疡或鼻腔炎症等;病变语音中第6、9、10、11和12阶特征受语音病变的影响较大,而第5、7和8阶特征受到的影响相对较小.

表1 单条异常语音、826条异常语音与NSFT的K-L距离Table 1 K-L distances from one abnormal speech and 826 abnormal speeches to NSFT
2 加权算法
2.1 K-L 加权因子
设两个连续的概率分布为p(x)和q(x),则它们的K-L距离定义为

如果p(x)、q(x)为离散的概率分布,则式(2)可以改为

设Fk为FNSFT中第k阶MFCC特征分量,pk为Fk的概率密度分布函数.给定测试语音sc,提取其MFCC特征并获得第k阶特征的概率密度分布函数qk,则测试语音的第k阶MFCC特征与FNSFT中第k阶特征之间的距离为

式中,N为概率分布中离散点的个数.测试语音各阶特征与FNSFT中相应特征之间的K-L距离可以表示为
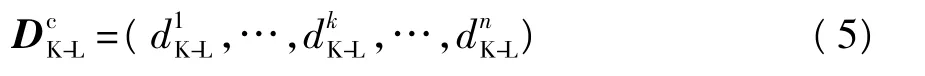
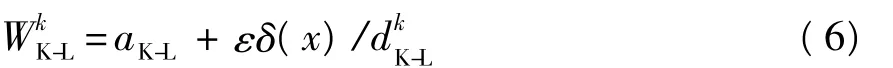
式中:δ(x)为符号函数,
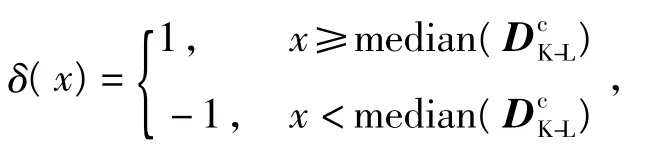
获得测试语音的加权因子后按式(7)进行加权:

式中,FNk为加权后测试语音的第k阶MFCC特征,FOk为加权前测试语音的第k阶特征.
2.2 欧氏加权因子
欧氏距离是一种常用的真实距离.m'维空间中两个点之间的欧氏距离可定义为

式中,M为空间中点的个数.文中使用欧氏距离来度量测试语音的观测向量和模板的距离,然后根据这种距离计算加权因子.
设测试语音sc的MFCC特征为Fc,Fc的第i阶特征向量为Ai,FNSFT的第i阶特征向量为 Bi,Ai中第j点到Bi的距离dj(Ai(j),Bi)可表示为
式中,M'为向量Bi的元素个数.则两个不等维向量空间的欧氏距离可计算为

式中,N'为向量Ai的元素个数.测试语音各阶特征与FNSFT中相应特征之间的欧氏距离表示为

式中,aE为欧氏加权常数因子.然后利用式(12)中取代式(7)中的进行测试语音特征的欧氏加权.
3 实验数据
在病变异常连续语音研究方面,国内外学术界没有统一可用的数据库,本课题组参考国家“863”计划项目录制的语音库和MEEI数据录制标准,经过长期的取样录音,建立了一个病变异常语音数据库(PANSD).PANSD的语料设计主要包括:
(1)27个汉语拼音的声韵母;
(2)0~9的10个单数字和10个长度为10的数字字符串(随机产生,每个数字分布均匀);
(3)选自“863”连续语音库的20句音素和韵律分布均匀的句子(每句含8~16个汉字);
(4)语素和音节分布均匀的3篇短文,其中2篇选自中国普通话水平测试的短文(分别含1 362和1317个汉字),1篇摘自北京师范大学于丹教授《婚姻爱情观》的网络片段(含1253个汉字).
PANSD从2010年3月到2011年8月已采集到17名病变(感冒)异常语音(从人耳听觉上能感觉到明显的差异)及其对应的正常语音,其中男生9名,女生8名,年龄分布在20~35岁,大专以上学历,分别来自湖南、湖北、河北、广东、广西、江西等地.每位受录者以普通话方式提供语音并进行录制.语音的采集环境分别为实验室、寝室、教室、办公室等.信噪比(SNR)分布在37~55 dB.分别用三星yep120录音笔和Toplux TVP208录音笔录音,采样频率为22.05kHZ,16位量化.语音采集时的语速每秒基本上保持在3~5个汉字,录音笔到受采集者的距离为5~20cm,一个受采集者的整个语音需要20~25min.PANSD目前已录制700min左右的语音.经统计,本语音库的字频和《现代汉语频率词典》提供的汉字字频基本一致.PANSD不仅包含了汉语中的400个不同音节(参考国家普通话水平测试要求),而且包含汉语中所有的60个音素.
4 实验及结果分析
从PANSD中选取9个说话人的3600条正常语音,每条语音在去静音后时长为3~4 s,作为训练共用特征模板数据;选取7个说话人的557条正常语音和826条病变异常语音(每条语音在去静音后时长为15~20s)作为测试数据,同时取每个说话人时长为1~2min的正常语音用于训练GMM说话人模型.所有的数据都是单声道的 WAV格式,用Cooledit Pro 2.0将采样频率调整为16 kHz,量化精度为16位,帧长为32 ms,帧移为16 ms,提取24阶MFCC特征(后12阶为差分特征).
826条病变异常语音包括:(1)轻微异常语音394条,受录者感冒而咽喉不适应,录音时不见明显的咳嗽,但偶尔咳嗽一下,同时有流鼻涕症状,语音没听出明显的变化;(2)稍重异常语音154条,受录者因感冒而咽喉不适应,录音时有明显的咳嗽,一般2~3 min就需要喝水,语音能听出变化但不明显;(3)较重异常语音278条,受录者因感冒而咽喉不适应,录音时咳嗽不断,鼻塞严重,语音能听出明显的变化.
选取12阶MFCC特征训练正常语音特征模板.整个算法的基本流程如图3所示.
图3 文中算法流程图Fig.3 Flowchart of the proposed algorithm
采用穷尽搜索算法获得使异常语音说话人识别率最高的加权常数因子和加权系数.不同的加权常数因子和加权系数对异常语音说话人识别率的影响见图4.从图4可知,当加权常数因子为1.8、加权系数ε=0.5时,文中算法的异常语音说话人识别率最高.
图4 加权参数对异常语音说话人识别率的影响Fig.4 Influence of weighting parameter on speaker recognition rate for abnormal speech
把基于K-L加权和欧式加权的算法分别简称为K-L-W和E-W 算法.首先用测试语音中异常语音进行K-L-W、E-W和不加权的GMM说话人识别,几种算法的识别率比较如表2所示.
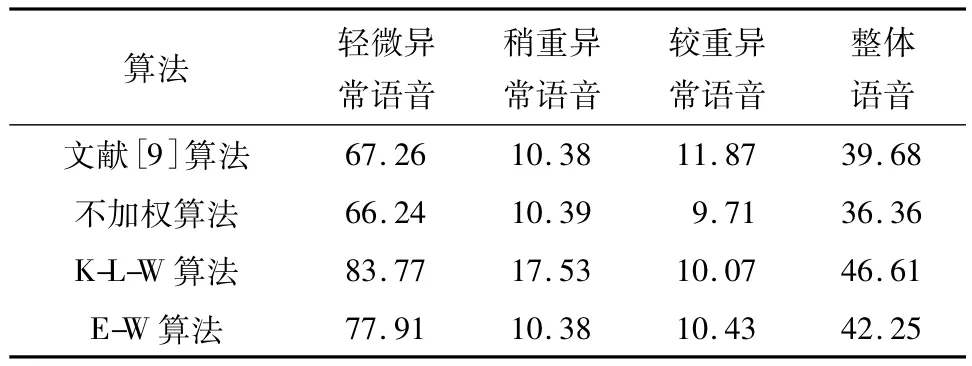
表2 几种算法的异常语音说话人识别率比较Table 2 Comparison of speaker recognition rates for abnormal speech %
从表2可知,对于轻微异常和稍重异常的语音,K-L-W算法的说话人识别率高于 E-W 算法、文献[9]算法和不加权算法.主要原因有:(1)K-L距离用于度量具有统计意义的两个概率分布间的差异,能较好地描述异常语音相对正常语音的变异情况;(2)欧氏距离是客观描述两向量间的距离,不具有统计意义;(3)文献[9]算法通过大量数据统计出各阶特征对说话人识别的贡献,再根据贡献大小进行加权,当语音异常时,没有考虑各阶特征的异常程度,也没有根据异常程度进行加权.对于较重异常语音,4种算法的说话人识别率均很低,K-L-W算法和E-W算法的说话人识别率相对于不加权算法的说话人识别率没有明显的提高,文献[9]算法表现最好.这因为文献[9]算法是通过大量数据统计出各阶特征对说话人识别的贡献,并根据经验进行加权,在语音异常较严重时表现相对好些.K-L-W算法对异常语音的整体识别率为46.61%,相对于不加权算法对异常语音的整体识别率提高了10.25%,E-W算法和文献[9]算法对异常语音的整体识别率分别提高了4.36%和6.93%.
为验证K-L-W和E-W算法对正常语音说话人识别的影响,使用测试语音中的正常语音进行实验.E-W算法的识别率为98.56%,优于文献[9]算法的98.54%、不加权算法的 98.38% 和 K-L 算法的98.02%.上述研究表明,K-L-W 和 E-W 算法对异常语音和正常语音的说话人识别都是有效可行的.
5 结语
文中提出了一种变异特征加权的异常语音说话人识别算法.首先建立正常语音特征模板,根据测试语音相对正常语音特征模板的距离来分析异常语音的变异程度,然后使用变异程度加权因子对测试语音进行特征加权,并将经过加权后的特征送进GMM模型进行说话人识别.实验结果表明,文中提出的K-L加权和欧氏加权的异常语音说话人识别算法的整体识别率分别为46.61%和42.25%,而基于各阶特征对说话人识别贡献的加权算法和不加权算法的整体识别率分别为39.68%和36.36%.
[1] Rashid R A,Mahalin N H,Sarijari M A,et al.Security system using biometric technology design and implementation of voice recognition system[C]∥Proceedings of International Conference on Computer and Communication Engineering.Kuala Lumpur:IEEE,2008:898-902.
[2] 杨继臣,贺前华,潘伟锵.一种改进的BIC说话人改变检测算法[J].华南理工大学学报:自然科学版,2009,37(9):47-51.Yang Ji-cheng,He Qian-hua,Pan Wei-qiang.Modified BIC algorithm of speaker change detection[J].Journal of South China University of Technology:Natural Science Edition,2009,37(9):47-51.
[3] 张磊,韩纪庆,王承发.变异语音处理的研究进展[J].电子学报,2003,31(3):411-418.Zhang Lei,Han Ji-qing,Wang Cheng-fa.Research progress of stress speech processing[J].Acta Electronic Sinica,2003,31(3):411-418.
[4] Alpan A,Maryn Y,Kacha A,et al.Multi-band dysperiodicity analyses of disordered connected speech[J].Speech Communication,2011,53(1):131-141.
[5] Maciel C D,Pereira J C,Stewart D.Identifying healthy
and pathologically affected voice signals[J].IEEE Signal Processing Magazine,2010,27(1):120-123.
[6] Togneri R,Pullella D.An overview of speaker identification:accuracy and robustness issues[J].Circuits and Systems Magazine,2011,11(2):23-61.
[7] Garner Philip N.Cepstral normalisation and the signal to noise ratio spectrum in automatic speech recognition[J].Speech Communication,2011,53(8):991-1001.
[8] Yang Hong-wu,Liu Ya-li,Huang De-zhi.Speaker recognition based on beighted Mel-cepstrum [C]∥Proceedings of the Fourth International Conference on Computer Sciences and Convergence Information Technology.Seoul:IEEE,2009:200-203.
[9] Weng Zufeng,Li Lin,Guo Donghui.Speaker recognition using weighted dynamic MFCC based on GMM [C]∥Proceedings of International Conference on Anti-Counterfeiting Security and Identification in Communication.Chendu:IEEE,2010:285-288.
[10] Kullback S,Leibler R.On information and sufficiency[J].Annals of Mathematical Statistics,1951,30(3):79-86.
[11] You Chang Huai,Lee Kong Aik,Li Haizhou.GMM-SVM kernel with a bhattacharyya-based distance for speaker recognition [J].IEEE Transactions on Audio,Speech,and Language Processing,2010,18(6):1300-1312.
[12] Ferrante A,Ramponi F,Ticozzi F.On the convergence of an efficient algorithm for kullback-leibler approximation of spectral densities [J].IEEE Transactions on Automatic Control,2011,56(3):506-515.
