基于云计算的海量数据处理平台设计与实现✴
2012-07-01宋均祝林
宋均,祝林
(1.中国西南电子技术研究所,成都610036;2.四川职业技术学院,四川遂宁629000)
基于云计算的海量数据处理平台设计与实现✴
宋均1,祝林2
(1.中国西南电子技术研究所,成都610036;2.四川职业技术学院,四川遂宁629000)
针对传统并行处理技术在海量数据处理中存在的实际应用问题,利用云计算技术强大的计算能力、高效的海量数据处理方式,结合关系数据库实时访问的优点,在Hadoop分布式计算框架基础上,采用Map-Reduce架构,设计并实现了基于云计算的海量数据处理平台。实践证明,该系统在计算能力、稳定性、可扩展性等方面都优于传统并行处理的技术,能有效解决海量数据大并发访问。
云计算;海量数据;Hadoop分布式计算;并行处理技术
1 引言
在许多行业和机构中,大中型数据库和数据仓库的大批量数据集快速批量处理有广泛的应用需求。如何实现海量数据快速交互的批量处理是管理信息系统所面临日益突出的问题,也是数据集中工程中急需解决的关键问题[1]。传统的基于并行处理的数据平台已不能满足海量数据处理的实际要求,海量信息技术架构迫切需要具有动态的、可伸缩的存储计算模式,才能实现快速响应的机制[2-3]。
大型数据库大规模数据查询、分析、提取、更新等批量处理过程正面临着严峻的实际问题[4]:一是传统的数据库复杂,查询耗时过长,当面临大数据量查询任务时甚至无法完成;二是系统面临大并发的数据任务时,系统性能将急剧降低;三是传统的数据库可扩展性差,额外增加的可扩展硬件根本无法有效提高系统处理性能;四是海量数据的存取与处理成本高、维护费用大,等。研究海量数据及时高效的处理技术将有效地提高计算机系统的应用性能,从而更好地提供社会基础服务,带动经济效益的增长。
作为一种新型的基于互联网的商业计算模型,云计算提供了灵活的计算能力和高效的海量数据分析处理方法。本文将云计算应用于关系数据库的海量数据处理当中,设计并搭建了基于云计算的海量数据处理平台,为解决关系数据库的海量数据处理问题提供了新方法。
2 云计算技术
2.1 云计算的定义
云计算(Cloud Computing)是在信息技术进步和应用需求拉动两方面成熟的条件下逐渐演化而来的,于2007年被提出。到目前为止,云计算还没有统一、公认的定义,维基百科中对云计算的定义为:云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需提供给计算机和其他设备。提供资源的网络被称为“云”。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。
2.2 云计算的技术支撑
云计算是网格计算、分布式计算、并行计算、效用计算、网络存储、虚拟化、负载均衡等传统计算机技术和网络技术发展融合的产物,它旨在通过网络把多个成本相对较低的计算实体整合成一个具有强大计算能力的完美系统,并借助SaaS、PaaS、IaaS、MSP等先进的商业模式把这强大的计算能力分布到终端用户手中[5-6]。云计算的一个核心理念就是通过不断提高“云”的处理能力,进而减少用户终端的处理负担,最终使用户终端简化成一个单纯的输入输出设备,并能按需享受“云”的强大计算处理能力。
3 系统设计
3.1 系统需求背景
本文以某药品经营管理信息系统为例来设计和实现基于云计算的海量数据处理平台。药品经营管理具有药品种类繁多、统计数量大、药品的批次号和有效期管理要求高、销售门店多等特点,因此该系统具有数据量大、并发用户多、查询复杂等特点。
3.2 系统设计要求与原则
传统的基于并行处理的海量数据技术存在系统硬件要求高、成本大、并行程序编写困难等缺点,海量数据的处理要求系统不仅要具有良好的稳定性、超强的计算能力,能够进行快速、并行的数据处理,还要求在面对数据库的复杂查询问题时,系统具有一定的并发能力,能够面对一定程度海量数据的大并发访问[7]。此外,还应要求系统核心架构具有可扩展性,当节点增加时,核心架构可实现线性扩展功能[4]。
本系统设计遵循的几点原则:
(1)经济性原则,充分利用现有的资源构建系统基础设施,采用Hadoop做为底层集群部署,对系统硬件要求不高;
(2)高效性原则,以云计算为基础,充分利用云计算的优点和现有资源,采用合理的结构体系,实现对海量数据的高效处理;
(3)通用性,注重采用目前成熟的软、硬件技术,在兼顾个体用户需求的同时,突出广大客户对系统共性的需求,尽可能地满足不同类用户的需求;
(4)易操作性,贯彻落实面向最终用户的原则,建立友好界面,使用户操作简单直观,易于学习和掌握。
3.3 系统总体架构
传统的数据仓库是集中在一台大型服务器上的,本系统将数据分割到相互联系的一个集群上。每个服务器上有一小部分数据,整个集群的数据组合成一个完整的数据集。当系统并行运算时,整个系统的I/O、CPU、内存都远远高于单服务器的架构,从而为数据处理速度带来巨大的提升。与云计算的map/reduce/merge架构相对应,可以将数据分割理解为map,将每台服务器单独处理的模块理解为re
duce,在汇总节点进行再处理可理解为Merge。系统总体构架如图1所示。

图1 系统总体构架Fig.1 System architecture
3.4 并行数据分割技术
在并行计算系统中,如何分割数据是整个并行计算的核心问题之一[7-8]。简单按字段做Hash分割,可以快速分割数据,但是对系统带宽有很高的要求,而且对系统的并发和可扩展性都有很大限制;按业务规则进行复杂的数据分割可以极大地减少节点间数据的交换,降低并行计算系统对带宽的要求,但同时又会导致巨大的分割运算量(例如,当对一个1.3亿条的数据按业务规则进行分割时,单服务器进行的分割时间需要20 h以上)。
为了有效解决这个两难问题,我们开发了并行数据分割系统,在多机并行的模式下,按业务规则对数据进行有效分割(例如,若对1.3亿条数据用9台机器进行分割,可在24min内完成)。并行分割流程框图如图2所示。
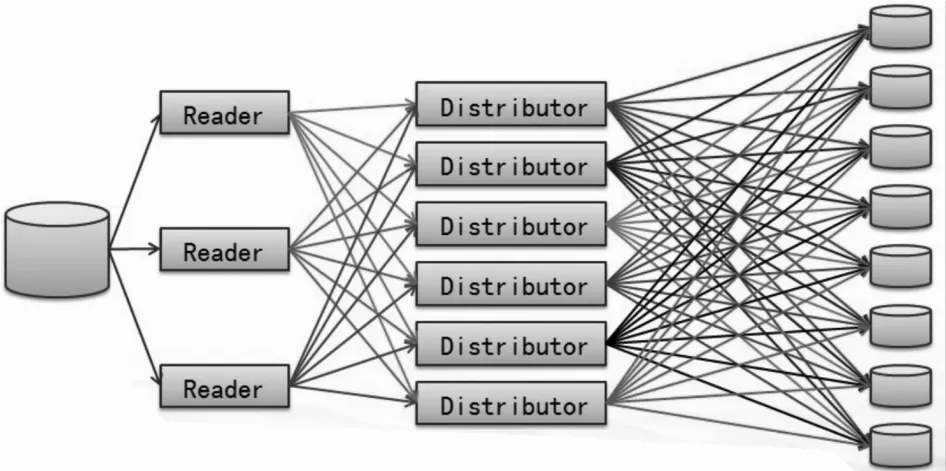
图2 并行数据分割流程框图Fig.2 Diagram of partitioning data parellet
3.5 智能节点替换技术
对于云计算系统来说,容错技术是保证系统稳定的基础[9]。系统采用多重备份模式,实现一份数据,多机存储。如图3所示,当某个节点出现故障时,系统的节点替换模块会自动更新节点信息,用备份节点替换掉故障节点。用户在前台操作时,丝毫感觉不到系统后台的操作。
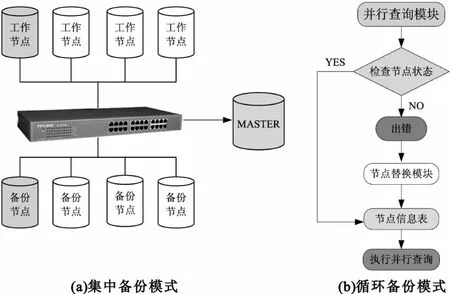
图3 系统备份模式流程图Fig.3 Backupmodes of system
3.6 内容负载均衡技术
按内容条件进行负载均衡技术查询流程如图4所示,查询往往包含很多过滤条件,如果能有效地利用这些过滤条件,锁定它们所在的节点,则可以有效减少对所有节点的扫描,降低运算所带来的时间浪费[10]。通过指定过滤条件和数据内容索引间的关联,查出查询所需要访问的节点,再针对性地向对应节点发出请求,大大减少了对系统资源的使用,同时也为海量数据的大并发查询提供了更多的可用计算资源。

图4 内容负载均衡技术查询框图Fig.4 Content load balancing lnquiry
3.7 任务负载均衡技术
如何应对海量数据的大并发访问是云计算技术面临的技术挑战,在并行计算时,所有子节点的运算结果需要由某个汇总节点进行集中再处理。在大并发的条件下,如果这个汇总节点是固定的,那么它的任务负荷一定会非常重,可能会造成整个系统的崩溃[11-12]。我们采用Master节点按任务进行负载均衡的技术,可以让任意节点担任Master的工作,从而极大地提高了并行计算系统应对大并发的能力。
如图5所示:实线任务和虚线任务两个任务同时并发,实线任务的汇总任务由1号节点完成,虚线任务的汇总任务则是由5号节点完成。
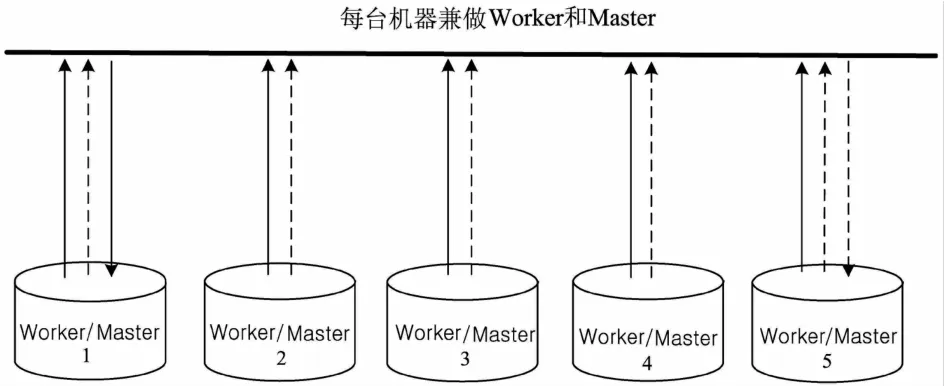
图5 负载均衡处理框图Fig.5 Load balancing processing
4 系统模块组成及其实现
整个系统包括六大功能模块,下面以系统在某医疗单位运行数据情况为例,分别进行介绍。
(1)数据分割模块
该模块包括中数据精确分割模块和大数据并行分割模块。
(3)并行查询模块
该模块包括并行查询设计模块、并行查询解析模块、并行查询控制模块,其中并行查询控制模块又包括并行调度模块、节点替换模块和负载均衡模块。
(3)安全管理模块
该模块包括用户管理、Portal内容权限管理及数据内容权限管理。
(4)Portal模块
该模块包括报表管理模块和缩略图模块。
(5)数据建模模块
该模块主要有元数据导入和业务视图模块。
(6)前台展现模块
该模块包括用户交互模块、表格模块及图表模块。
5 基于云计算海量数据处理系统的特点
系统在试用期间,通过对广大使用客户的调研,发现该系统具有以下几个特点。
(1)计算快速性
云计算的核心在于数据的分布式存储与大规模并行计算,google、yahoo、百度、facebook等互联网巨头正是利用这一技术来处理它们后台的海量数据,我们将这一技术与传统的关系数据库技术相结合,设计了基于云计算技术的海量数据处理系统,为解决关系数据库的海量数据快速处理提供了新方法。
(2)稳定可靠性
引进智能节点替换技术,在节点坏掉的时候,系统可以自动用备份节点替换掉故障节点,保证系统的稳定性。该系统采用和hadoop类似的多重备份模式,一份数据,多重备份。当有节点宕机后,系统自动用备份节点替换掉故障节点,保证系统稳定运行。
(3)可有效解决并发能力
采用多项负载均衡技术,通过dispather指定任意节点承担Master任务,有效消除并行计算中Master节点工作负荷太重的问题;通过内容索引、二次查询等技术,有效减少按条件查询时对所有节点进行的扫描数量,避免系统资源浪费等问题。
(4)可扩展性
由于系统完全是基于并行模式设计的,所以当节点增加时,整个系统的I/O、CPU、内存等核心架构可线性扩展,以此提高系统计算性能。
(5)零客户端
系统的设计按照云计算的架构,从系统管理[15]报表到查询的开发,用户使用完全基于Web完成。所有操作界面都通过浏览器完成,用户可以使用私有云在企业内部部署,也可以使用公有云的模式,将数据上传到云中心,然后通过云的方式使用,分析数据。
6 结束语
随着信息化进程的不断深入,人们对信息的需求也将不断增加,海量数据快速处理的技术需求与目前技术现状的滞后之间的矛盾将日趋激烈,已成为全球广为关注的热点议题。本文在对广大客户需求分析的基础上,针对传统并行数据库对大数据量处理不足等现状,利用云计算灵活的计算能力和高效的海量数据分析处理技术,设计并搭建了基于云计算的海量数据实现平台,最后对系统运行情况进行了简要展示。系统在投试期间,通过对使用客户的广泛调研,发现本系统在计算能力、稳定性、可扩展性等方面都优于传统并行处理的技术方法,能有效解决系统大并发问题。该系统是云计算技术面向海量数据处理的一个实际应用,是解决海量数据处理问题的一种成功范例,可为面向海量数据处理的系统开发提供参考和借鉴。
[1]2010 Digital Universe Study[EB/OL].[2010-7-27]. http://gigaom.files.wordpress.com/2010/05/2010-digital -universe-iview-5-4-10.pdf
[2]陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009,20(5):1337-1348. CHEN Kang,ZHENGWei-min.Cloud Computing:System Instances and Current Research[J].Journal of Software,2009,20(5):1337-1348.(in Chinese)
[3]黄华峰,曹王王木.云计算:中国未来的IT战略[M].北京:人民邮电出版社,2010. HUANG Hua-feng,CAOQin.Cloud Computing:China Future IT Tactic[M].Beijing:People′s Post and Telecomm Press,2010.(in Chinese)
[4]Armbrust M,Fox A,Grifth R,et al.Above the Clouds:A Berkeley View of Cloud Computing[R]//Technical Report No.UCB/EECS-2009-28.Berkeldy:Department of Electrical Engineering and Computer Sciences,University of California,2009.
[5]刘鹏.云计算[M].北京:电子工业出版社,2011. LIU Peng.Cloud Computing[M].Beijing:Publishing House of Electronic Industry,2011.(in Chinese)
[6]Fingar P.云计算:21世纪的商业平台[M].王灵俊,译.北京:电子工业出版社,2010. Fingar P.Cloud Computing:21st Century Business Platform Built[M].Translated by WANG Ling-jun.Beijing:Publishing House of Electronic Industry,2011.(in Chinese)
[7]Chaves SA,Westphall CB,Lamin FR.SLA Perspective in Security Management for Cloud Computing[C]//Proceedings of the 6th International Conference on Networking and Services.Cancun,Mexico:IEEE,2010:201-217.
[8]Cryans Jean-Daniel,April A,Abran A.Criteria to Compare Cloud Computingwith CurrentDatabase Technology[C]//Proceedings of the International Conferences on Software Process and ProductMeasurement.[S.l.]:IEEE,2008:114-126.
[9]Santos N,Gummadi K P,Rodrigues R.Towards trusted cloud computing[C]//Proceedings of HotCloud 2009.San Diego,CA,USA:[s.n.],2009.
[10]Li Wei,Chen C X.Efficient Data Modeling and Querying Systemfor Multi—dimensional Spatial Data[C]//Proceedings of ACM GIS.Irvine,CA,USA:ACM,2008.
[11]Porter G,UC San Diego,La Jolla.Decoupling Storage and Computation in Hadoop with SuperDataNodes[J].ACM SIGOPSOperating System Review,2010,44(2):41-46.
[12]Raj H,NathujiR,Singh A,etal.Resourcemanagement for isolation enhanced cloud services[C]//Proceedings of the 2009 ACM Workshop on Cloud Computing Security.New York:ACM,2009:77-84.
SONG Jun was born in Suining,Sichuan Province,in 1972.He received the M.S.degree in 2002.He is now a system analyst.
Email:songjun@china.com
祝林(1970—),男,四川射洪人,1994年获工学硕士学位,现为副教授。
ZHU Lin was born in Shehong,Sichuan Province,in 1970.He received the M.S.degree in 1994.He is now an associate professor.
M ass Data Processing Platform Design and Im plementation Based on Cloud Com puting
SONG Jun1,ZHU Lin2
(1.Southwest China Institute of Electronic Technology,Chengdu 610036,China;2.Sichuan Vovational and Technical College,Suining 629000,China)
According to the shortcomings of themassive data processingmethods based on traditional parallel processing techniques in practical applications,by using the powerful computing abilities and effcientways ofmass data processing of cloud computing,and taking the advantages of real-time access to relational databases,a cloud computing platform formass data processing based on the Hadoop distributed computing framework and Map-Reducemodel is developed.Practice shows that the system proposed is superior to the traditional parallel processing techniques in computing ability,stability,scalability,etc.,and what′smore,it can effectively solve the concurrent access tomass data simultaneously.
cloud computing;mass data;hadoop distributed computing;parallel processing technique
TP391
A
10.3969/j.issn.1001-893x.2012.04.029
宋均(1972—),男,四川遂宁人,2002年获工程硕士学位,现为系统分析师;
1001-893X(2012)04-0566-05
2011-11-11;
2012-03-26
