用于关系数据库关键词查询的基于划分的候选网络生成算法
2012-06-28金远平
周 翔 金远平
(东南大学计算机科学与工程学院,南京211189)
随着越来越多的文本数据存储到关系数据库中,关系数据库关键词查询逐渐成为新的研究热点.一个关键词的查询分为相关元组获取、候选网络(candidate network,CN)[1]生成和候选网络执行3个阶段.由于候选网络执行阶段是整个系统的性能瓶颈,所以一直是重点关注的对象[1-6],而对前2个阶段算法的改进很少.文献[7-8]最先提出通过广度优先查询方法生成所有组合关键词的候选网络.但是组合关键词的候选网络数量会随着网络大小成指数增长,执行时间急剧上升[1,9].Markowetz等[10]提出了减少中间结果和避免同构检查的算法.文献[11]利用半连接和连接操作减少候选网络连接计算,但是实验表明候选网络的数量依然很庞大,消耗了大量的查询结果生成时间[2].文献[1]在文献[7]的基础上,对候选网络生成算法进行了改进,使之生成完备的基于查询的候选网络.之后查询结果的生成效果和效率受到广泛研究,而对候选网络生成算法的改进越来越少,多数都采用文献[1,7,10]的算法.
然而对候选网络生成阶段算法的改进同样也可以很大程度地提高关键词查询系统的性能.因此,本文通过对候选网络生成过程[1]的分析,提出了基于划分的候选网络生成策略,并设计了高效的候选网络生成算法.同时通过改写图的同构方法生成无冗余的候选网络集合.最后,在DBLP[12]数据集上进行了大量的算法对比实验,结果表明,本文提出的高效候选网络生成算法的性能较基于广度优先扩展算法有大幅度的提升.
1 候选网络生成算法[1]
1.1 基于广度优先扩展的候选网络生成算法
文献[1]提出的基于查询的候选网络数比文献[7,10]基于关键词的少得多,因此本文将文献[1]中的算法作为对比算法.将数据库模式(database schema)、最大候选网络尺寸M和非自由元组集集合(the set of non-free tuple set,STS)作为输入,输出候选网络集合(candidate network set,SCN).算法首先由数据库模式图GS和非自由元组集集合STS构造元组集无向图GTS,非自由元组集RQ和自由元组集Rφ构成点的集合,即元组集所属关系间的主外键联系构成边的集合,即Ri和 Rj存在主外键联系}.根据 DBLP[11]数据集构造的数据库模式图如图1所示.图中,表Person存储编辑和作者信息;表Publication存储出版物信息;表Publisher存储出版社信息;表Series存储出版物的类别;表Article存储文章信息;表Cite存储文章之间引用的信息;表Write存储文章和作者之间关系;表Edit存储出版物和编辑之间关系.假设STS由非自由元组集PersonQ和ArticleQ构成,则对应的元组集无向图GTS如图2所示.

图1 DBLP数据库模式图
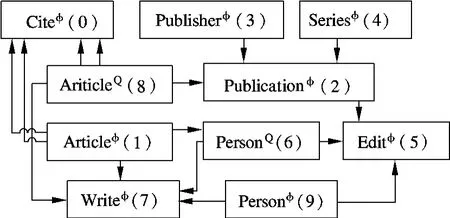
图2 元组集无向图GTS
构造好GTS之后,首先选取非自由元组集(尺寸为1的连接元组集图)作为算法的起始节点集,然后利用图的广度优先遍历思想不断地扩展已生成的连接元组集图,最后返回符合候选网络条件的连接元组集图[1].为了叙述方便,称连接元组集图中度(出、入度之和)为1的元组集为叶子节点.候选网络的生成过程见表1.

表1 候选网络生成过程
由于表1中“/”后的编号相同的连接元组集图是重复的,因此,该算法会产生大量、重复的候选网络.
1.2 基于划分策略的候选网络生成算法
分析基于广度优先扩展的候选网络生成算法,可以发现,中间结果中同一个连接元组集图可能会被生成多次.例如图2中,由2个元组集构成(尺寸为2)的ArticleQ←PublicationQ就可分别由尺寸为1的ArticleQ和PublicationQ扩展生成.这样SCN中就包含2个ArticleQ←PublicationQ,形成了冗余.当元组集图的尺寸增大时,SCN将出现很大的冗余,不仅消耗了大量内存资源,也严重降低了算法的效率.可见,在候选网络生成算法中消除候选网络冗余具有重要意义.
正因为尺寸为i-1的、不同的连接元组集图可以产生相同的尺寸为i的连接元组集图,才导致冗余的出现,所以若能够使尺寸为i的连接元组集图只被生成一次,冗余就得到了解决.本文通过特定的划分策略,将生成尺寸为i的连接元组集图的职责指定给某个i-1的连接元组集图.这样就从源头上解决了冗余的产生.
首先给元组集无向图GTS中每一个元组集指定一个唯一的数值编号0,1,2,….非自由元组集最后编号.图2括号中的值为元组集的编号.然后将尺寸为i的连接元组集图的生成职责指定为删除了最小编号的叶子节点所剩下的尺寸为i-1的连接元组集图.按照以上策略,生成的候选网络能够保证其完备性.
定理1基于划分策略的候选网络生成算法可以保证生成候选网络的完备性.
证明 ① 算法覆盖了所有非自由元组集,所以,可以生成所有尺寸为1的连接元组集图.② 设算法可以生成所有尺寸为i-1(i>1)的连接元组集图.因为尺寸i的连接元组集图必定是由其去除一个叶子节点后所剩的尺寸为i-1的连接元组集图扩展生成.而基于划分策略的算法保证尺寸i的连接元组集图是由尺寸为i-1的连接元组集图扩展最小编号的叶子节点构成的,从而保证了尺寸i的连接元组集图可由算法生成.证毕.
算法1基于划分策略的候选网络生成算法


算法1首先以非自由元组集开始扩展,即扩展前的连接元组集图集合为{8,9}.扩展后的连接元组集图集合为{8→0,8←2,8→7,9→5,9→7}.按照划分策略,刚添加的叶子节点的编号应该最小,如:2←8→0是由8→0扩展的,但是刚添加的编号为2的叶子节点不是最小的叶编号(存在编号为0的叶子节点),所以不满足基于划分策略的扩展过程,可以删除.表1中带有“×”标记的连接元组集图为算法执行中的删除结果.
连接元组集图中编号并不唯一,会出现多个最小的叶子节点,所以算法1并不能完全消除冗余.尽管如此,定理1的证明表明,含j(1<j<i)个叶子的连接元组集图存在j种由尺寸i-1生成尺寸i的方案,因而至少产生j-1倍冗余.所以可以说明基于划分的候选网络生成算法较文献[1]算法有较大改进.实验结果表明,算法1可以很大程度地减少了冗余,避免了指数量级的中间结果的检查和扩展.
1.3 冗余候选网络的消除
由于算法1生成的候选网络集合存在冗余,而候选网络执行阶段需要无冗余的候选网络集合,所以需要消除冗余.本节的冗余候选网络消除算法是在文献[13]中图同构算法的基础上,利用候选网络的同一性消除重复的网络.因为候选网络的生成采用广度优先方式,且元组集的编号是允许重复的,所以2个候选网络的同一性判断需要在图同构的判别过程中检测元组集编号是否相同.
定义1(候选网络的同一性)对于尺寸相同的候选网络,如果CN1中每个节点都可以找到元组集编号相同的CN2中的唯一对应节点,且所有对应节点间的连接关系完全一致,就称CN1和CN2是相同的候选网络.
算法2给出了冗余候选网络消除算法.算法以尺寸相同的一组候选网络作为输入.两两比较,删除重复的候选网络.考虑2个尺寸为s的候选网络CN1和 CN2,算法首先构造检测矩阵 Ms×s=(mi,j)s×s,其中

然后,对CN1中的节点按照其度数降序排列,并利用矩阵Ms×s依次检查其与CN2中节点是否存在一一对应关系,若所有节点都一一对应,则2个候选网络是相同的,删除其中任意一个即可.
算法2冗余候选网络消除算法

定理2已知CN1中的节点i与CN2中的节点j对应,则CN1中节点p与CN2中节点k对应的必要条件是:节点p和节点i间的关系与节点k与节点j间的关系一致,这里的关系包括边的存在和方向.
证明 若节点p,k和节点i,j是2个候选网络间的2对对应点,则根据相同候选网络的定义,显然有节点p和i间的关系与节点k与j间的关系一致的结论.所以必要性成立.
但是,节点p和i间的关系与节点k和j间的关系一致却不能推导出节点p和k是对应点.因为候选网络中会存在元组集编号相同的节点,只有CN1中所有点都找到一一对应的点之后才能确定对应关系.所以充分性不成立.证毕.
定理2的非对应点的判定条件为:在确定CN1中节点i的对应点是CN2中节点j的情况下,若节点p和i间的关系与节点k和j间的关系不一致,则节点p和k必定不是对应点.
2 实验
本实验从DBLP[12]数据集中抽取数据,构造了如图1的数据库模式图.其中5个含文本属性的关系分别为:Person,Publisher,Series,Publication 和Article.实验假设这5个关系的非自由元组集都非空,从而可以广泛地测试候选网络生成算法的性能.算法使用 C#语言,在.NET 4.0平台上实现,采用Windows XP操作系统,Intel Pentium双核,主频1.6 GHz,1G内存.本实验分别固定候选网络最大尺寸和关键词个数,对候选网络生成算法[1](简称GCN)、算法1和算法2的性能进行了测试.表2分别展示了关键词个数为3和4时,GCN和算法1随着最大候选网络尺寸M的变化而生成的候选网络数量,以及算法2所计算的无冗余的候选网络数.表3为固定候选网络最大尺寸为7时,各个算法生成的候选网络数量.
此外,实验还对比了候选网络生成阶段执行时间.图3和图4分别为关键词个数为4和最大候选网络尺寸为7时,候选网络生成阶段执行时间与参数的关系.其中执行时间为候选网络生成时间与冗余候选网络消除时间之和.
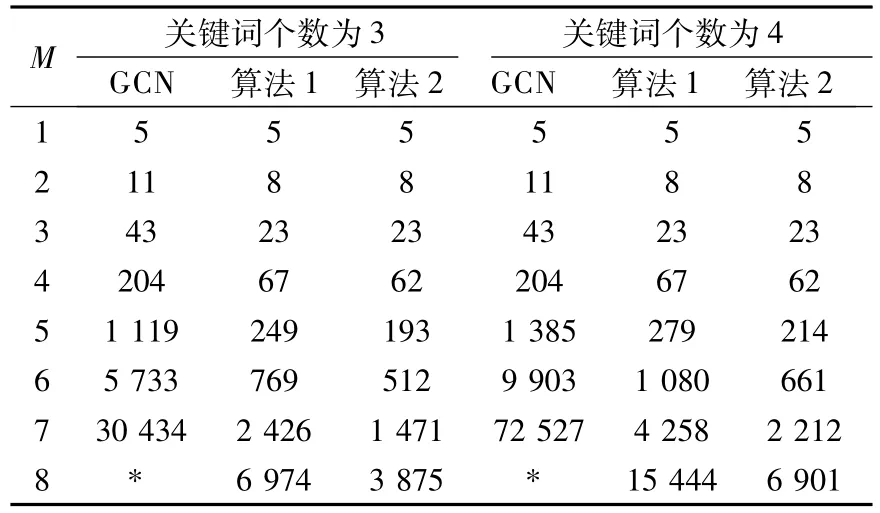
表2 不同关键词个数生成的候选网络的数目

表3 CN尺寸为7时生成的候选网络数

图3 关键词个数为4时的执行时间

图4 最大候选网络尺寸为7时的执行时间
由表2、表3和图3、图4可以清晰看出,当关键词个数与最大候选网络尺寸较小时,连接元组集图可扩展的选择较少,2种算法所生成的候选网络数量相差不大,执行时间相近.随着关键词个数与最大候选网络尺寸的不断增大,GCN算法生成庞大的冗余候选网络,消耗了大量的空间和时间;而算法1生成的候选网络的冗余较小,执行时间增长缓慢.可见,在数据量很大的情况下,算法1有着非常明显的优势.据保守估算,当最大候选网络平均尺寸为7,查询关键词平均个数为4时,采用算法1至少可以减少10倍的冗余.
3 结语
本文在对候选网络的生成过程进行观察的基础上,提出了一种基于划分策略的候选网络生成算法.实验结果表明,基于划分策略的候选网络生成算法较盲目的广度优先扩展的生成算法能够减少大幅度冗余,有效地提升了整个候选网络生成阶段的性能.
目前,本文基于划分策略的候选网络生成算法还不能完全消除冗余候选网络的产生,需要借助候选网络消除算法做进一步的过滤,因此,一个能够完全消除冗余候选网络产生的高效算法是需要进一步研究的方向.
References)
[1]Hristidis V,Gravano L,Papakonstantinou Y.Efficient IR-style keyword search over relational databases[C]//Proceedings of the 29th VLDB Conference.Berlin,Germany,2003:850-861.
[2]Qin Lu,Yu J X,Chang Liujun.Ten thousand SQLs:parallel keyword queries computing[C]//Proceedings of the VLDB Endowment.Singapore,2010:58-69.
[3]Luo Yi,Lin Xuemin,Wang Wei,et al.SPARK:top-k keyword query in relational databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data.Beijing,China,2007:115-126.
[4]Liu Fang,Yu C,Meng Weiyi,et al.Effective keyword search in relational databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data.Chicago,USA,2006:563-574.
[5]Qin Lu,Yu J X,Chang Liujun.Keyword search in databases:the power of rdbms[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data.Rhode Island,USA,2009:681-694.
[6]Ding B,Yu J X,Wang S,et al.Finding top-k mincost connected trees in databases[C]//Proceedings of the 23rd International Conference on Data Engineering.Istanbul,Turkey,2007:836-845.
[7]Hristidis V,Papakonstantinou Y.DISCOVER:keyword search in relational databases[C]//Proceedings of the 28th VLDB Conference.Hong Kong,China,2002:670-681.
[8]Agrawal S,Chaudhuri S,Das G.DBXplorer:a system for keyword-based search overrelationaldatabases[C]//Proceedings of the 18th International Conference on Data Engineering.California,USA,2002:5-16.
[9]Yu J X,Qin Lu,Chang Liujun.Keyword search in databases[M].Washington,USA:Morgan and Claypool Publishers,2010:12-21.
[10]Markowetz A,YangYin,Papadias D.Keyword search on relational data streams[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data.Beijing,China,2007:605-616.
[11]Qin Lu,Yu J X,Chang Liujun,et al.Scalable keyword search on large data streams[C]//Proceedings of the 25th International Conference on Data Engineering.Shanghai,China,2009:1199-1202.
[12]Ley M,Herbstritt M,Hoffmann O,et al.The DBLP Computer Science Bibliography[EB/OL].(2011-05-01)[2011-05-20].http://www.informatik.uni-trier.de/~ ley/db/.
[13]Ullman J R.An algorithm for subgraph isomorphism[J].Journal of the Association for Computing Machinary,1976,23(1):31-42.
