面向辅助驾驶的夜间行人检测方法*
2012-06-25庄家俊刘琼
庄家俊 刘琼
(华南理工大学软件学院∥计算机科学与工程学院,广东广州510006)
基于视频的行人检测是计算机视觉领域中的一个研究热点,是车辆辅助驾驶系统中保障行人与驾驶员安全的重要功能模块,具有重要的应用价值.驾驶员在夜间行车时的视觉范围受到较大限制,相对于白天,在夜晚与行人发生交通事故的概率更高[1-2],因此探索夜间行人检测方法的需求和意义更大.当前,多数夜间行人检测系统以红外摄像头为基础.Viola等[3-4]提出了基于Haar-like特征和AdaBoost算法的瀑布型级联分类器,该方法具备一定的实时性,但与人脸相比,行人模式具有更大的外观差异,直接应用于行人检测的效果并不理想;O’Malley等[5]利用方向梯度直方图(HOG)特征对远红外行人进行描述,结合支持向量机(SVM)实现行人检测,该方法检测效果较好,但计算开销稍大,在Matlab平台下检测速度为1~2帧/s;利用Haar-like特征计算速度快、HOG特征描述能力强的特点,Ge等[6]提出一种基于Haar-like和HOG特征及Gentle-AdaBoost算法的两级树型结构的近红外行人检测器,在保证检测性能的同时于一定程度上降低了运算复杂度;梁英宏[7]利用远红外图像中人体比背景亮的特点,通过检测图像中的高亮区域,利用其灰度-投影直方图进行行人检测,该方法复杂度小,容易实现,但其仅在简单场景下可行,且虚警较多;Bertozzi等[8]根据行人的步态模式建立4个人体概率模板,再通过模板计算各像素的联合概率判断输入图像是否包含人体,计算开销较低,但这种模板建立模式比较适合站立且腿部可见的行人;Sun等[9]提出一种描述性能较强的多级二元模式(PBP)特征,在多级网格划分密度下利用每个网格中纹理信息的空间布局来描述红外行人的对称性特点,并采用SVM实现行人检测,检测性能优于文献[5]采用的HOG描述子,但PBP特征计算开销较高,在Visual C++环境中也仅有平均10帧/s的处理速度.
面向辅助驾驶的行人检测方法受其应用条件和需求限制,必须具备良好的实时性和较高的准确度[10].上述多数基于机器学习的检测方法虽具备较高的准确度,但其高计算复杂度的不足制约了算法的实时性.文中在前人研究成果的基础上,采用单目远红外摄像头,提出一种基于概率模板匹配的夜间行人检测方法,并将该方法分为3个阶段来介绍:(1)利用局部水平邻域像素的灰度统计特性,获得局部分割阈值,实现输入图像的二值化,并对分割结果进行形态学处理,通过8连通标记提取出感兴趣区域(ROIs);(2)采用人工分割获得的训练样本建立多尺度行人概率模板,对ROIs进行匹配判别;(3)结合目标跟踪和概率模板匹配,进行多帧处理结果的综合判断.
1 ROIs的提取
ROIs提取是为了提取红外图像中可能存在行人的区域,以降低计算开销,便于后续目标检测,包括图像分割、形态学处理和ROIs选取.
1.1 图像分割
远红外图像是热图像,一般情况下,人体散发的热量高于周围环境散发的热量,对应到图像中则表现为行人区域比周围背景亮[6],如图1所示.从每一条水平线方向看,行人区域的像素比两边的背景亮,且在边缘位置有一个突变,因此可利用局部水平邻域像素的灰度统计特性实现图像的二值化.文中采用一种局部阈值分割算法,按式(1)和(2)分别计算图像中每个像素的两个阈值,即低阈值TL和高阈值TH:

式中,(i,j)为当前水平邻域中心像素点的坐标,I(z,j)是局部水平邻域中像素(z,j)的灰度值,ω为水平邻域的半宽度,σ为该邻域像素灰度值标准差的平方根为控制参数,用于调节TH的取值.输入图像中坐标为(i,j)的像素点的二值化结果I'(i,j)由式(3)确定:

图1 行人区域灰度分布拓扑图Fig.1 Topographic surface of intensity in a pedestrian area

由上述分析可以得出,半宽度ω较大时,局部水平邻域将同时包含目标及其两边背景区域的像素,获取的高低阈值较为合理,更能凸显目标区域并抑制两边背景,故分割后人体的完整性较好,但计算开销也较大;半宽度ω较小时,局部水平邻域像素可能全部落入目标内部,这时局部邻域灰度同质性较高,导致得到较大的TL,容易降低分割后目标的完整度.另一方面,控制参数较大时,得到的TH较大,也可能降低分割后目标的完整度;控制参数较小时,容易导致分割结果中包含较多的噪声.采用通过大量实验确定参数的方式,文中发现当ω和分别为12和2时,分割算法对输入图像具有较好的二值化效果,如图2所示.

图2 图像的二值化效果及候选区域选取Fig.2 Binary segmentation result of an input image and corresponding candidates selection
1.2 形态学处理
为了消除二值图像中的噪声和填补弱连接区域,先后采用形态学腐蚀与膨胀操作来改善图像中的连通区域.由于二值化阶段采用了水平邻域像素的灰度统计特性计算分割阈值,当连续多个水平邻域中的绝大部分像素位于人体内部时,获得的阈值TH和TL可能偏高,容易造成二值图像中行人区域上下部位的弱连接甚至“断裂”现象.为缓解该问题,文中采用1×3的结构元素进行腐蚀操作以滤除噪声,继而采用3×3的结构元素进行膨胀运算以填补弱连接区域.图2(a)为实拍的红外图像,对其处理后的二值化效果见图2(b),图中所有区域均采用8连通标记获得.
1.3 ROIs选取
图2(b)表明,二值图像中连通区域数量较多,且大部分属于非行人区域.如果对所有区域进行后续检测,不仅计算开销较大,而且容易出现虚警.因此,可利用一些先验知识对这些区域进行过滤.根据行人区域最小外接矩形宽高比的统计分布(见图3)以及行人在图像中可能出现的位置信息(即行人位于路面上的物理约束),过滤了绝大多数明显的非行人区域,有效地提升了系统的执行效率,最终获取的ROIs如图2(a)所示.

图3 行人区域宽高比分布Fig.3 Distribution of aspect ratio of pedestrian regions
2 基于概率模板的行人检测
行人检测是车辆辅助驾驶系统的核心组成部分,与ROIs提取阶段不同,其必须具备出色的分类性能.基于知识的检测方法通过人为归纳出描述行人的某些特征或规律来判别行人模式,普遍具有计算复杂度低的优点.
考虑到行人是非刚体,姿态多样化容易造成行人类内方差较大,所需建立的形状/轮廓模板的数量将非常庞大(如文献[11]中构造了近1000个行人轮廓模板),在真实硬件平台(如DSP)上实现时需要较大的存储和匹配计算开销.行人概率模板是对行人外观模式的一种归纳,模板数量容易控制,在检测阶段可方便地通过模板与输入图像的相似性匹配程度来确认行人.
2.1 训练样本及其预处理
与基于机器学习的检测方法类似,文中也需要利用行人样本来构建概率模板.运动方向的不同是造成行人外观模式多样性的主要原因之一,如图4所示.不同于文献[8]的方法,为降低行人类内方差,提高每一个概率模板对相应姿态下行人外观模式的归纳准确度,根据不同的运动方向,文中将样本集划分为沿着摄像头运动(包括踩单车、跑步和行走等运动方式)、横跨摄像头由右向左运动和横跨摄像头由左向右运动3个子类,每个子类中各包含80个样本.这种划分方式使得在检测阶段不仅能判断ROIs是否包含行人,而且即使在不加入目标跟踪与行为分析模块时也能对行人的运动方向进行估计.

图4 部分训练样本Fig.4 Some examples of training dataset images
接下来,对所有样本进行预处理,包括尺度调整和0-1二值化.首先将所有样本通过插值调整至96像素×40像素.其次,在观察了大量样本的灰度分布情况后,发现每个样本中属于人体的像素高于周围背景的像素灰度值,且多数情况下高于该局部区域的平均灰度值,为此,选取每个样本的灰度均值作为对该样本进行0-1二值化时的动态阈值,以凸显行人的高亮像素区域.
2.2 概率模板的构建
根据样本集的划分方式,分别对应建立3个运动方向的行人概率模板,如图5所示.每个模板中相应的像素取值代表该像素在该类样本中高于样本灰度均值的频率,即该像素隶属于人体区域的概率.
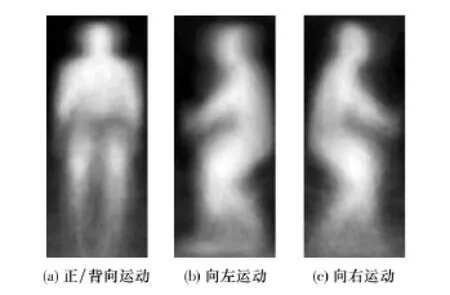
图5 行人概率模板Fig.5 Pedestrian probabilistic templates
由于摄像头安装在运动平台上,因此图像中行人的成像尺寸是不断变化的,而且受特定应用背景的限制,即使及时检测到车辆前方近距离处的行人,也难以保证驾驶员拥有足够的反应时间来采取紧急应对措施,因此检测位于中远距离(15m之外)处的目标显得更有意义.文中采用的远红外摄像头的空间分辨率(352×288)较低,位于中远距离外的行人成像尺寸较小,而且这类目标通常数量较多,若将每一个ROI调整至与模板同等大小的尺寸,所需的插值运算开销较大,会影响系统的实时性.因此,文中将上述大尺度行人概率模板通过降采样的方式重新建立3个尺度(分别是96像素×40像素、64像素×24像素和24像素×10像素)下的概率模板,分别对应位于近(15 m之内)、中(15~45 m之间)、远(约45m之外)距离下的目标匹配运算.
2.3 行人检测
受人体手臂摆动幅度的影响,ROIs的宽度变化较大,不适合估计当前目标的距离.文中根据视频中所有行人样本高度的统计分布规律,利用高度估计当前ROIs与摄像头之间的距离.将高度多于64像素的ROIs视为近距离目标,高度在24~64像素之间的视为中距离目标,其余的视为远距离目标.进而对ROIs进行尺度调整,使其与相应距离下模板的尺度相同,并对其进行0-1二值化处理(与训练样本的处理过程相同).进一步根据式(4)与相应尺度下的3个模板进行匹配运算:

式中,C为匹配值,R为进行预处理后的ROI,P为概率模板,n为R和P的像素数.
式(4)表明,当概率模板P中某个像素取值大于0.5且感兴趣区域R中相应像素取值也大于0.5时,即P中该像素隶属于人体而R中该像素也隶属于人体时,该像素将对最终的匹配值C赋予正贡献;同理,当P和R中某个像素取值同时小于0.5时,该像素也对C赋予正贡献;反之,则对C赋予负贡献.故式(4)表征了ROI各像素对匹配值C的联合贡献和.其中分母的作用在于将匹配值C规范化到[-0.5,0.5]之间,C 值越大表明匹配程度越高.
3 多帧校验/目标跟踪
由于动态场景的复杂多变和不稳定分割,难以保证目标在每一帧中都能被准确分割,容易造成目标的漏检,若能利用前一帧的检测结果估计目标在后一帧中的位置与尺寸,将估计结果与后一帧的分割结果一起作为ROIs,通过模板匹配进行判别,可提高对单个目标的检测率;若能准确分割出后一帧中的目标,那么前一帧的估计结果将与后一帧的分割结果相互重叠,此时则采用极大化抑制的方法进行区域合并,形成一个完整的ROI.虽然部分干扰源(如树干、灯柱、邮筒等)的外形轮廓与行人相似度较大,在匹配阶段容易产生虚警,但一般来说,行人可在连续多帧中被持续检测到,而干扰源仅在个别帧中被误检,因此通过多帧的检测结果进行综合判断有利于抑制虚警.
行人与背景相对于摄像头的运动主要是由车辆的运动引起的,故相邻两帧中同一目标的位置与尺寸变化较小,可近似将该目标在视频中的运动视为匀加速运动,其运动状态可表示为 S={x,dx,y,dy,w,dw,h,dh}.其中,x与 y分别为目标在图像中水平与垂直方向的起始位置坐标,dx与dy为位置的变化量,w与h分别为目标的宽度与高度,dw与dh分别为w与h的变化量.
目标检测系统中常用的跟踪算法有Kalman滤波[6,12]和粒子滤波算法[13-14]等,其中粒子滤波算法计算量大,与实际应用存在距离.鉴于Kalman滤波算法具备较强的实时性,而本系统中目标的运动近似为匀加速运动,因此可利用Kalman滤波算法来估计目标在视频中的线性运动状态.以x方向为例,即对状态 Sx={x,dx,w,dw},其 Kalman 滤波的状态方程和观测方程可表示为

4 方法的实现与结果分析
4.1 概率模板性能的比较
文中从实拍视频中分别提取1200个行人样本和1000个与行人外形相似的干扰样本,以测试概率模板对目标匹配的性能,并与文献[8]中的方法进行比较,匹配结果使用接受者操作特性曲线(ROC)进行评估,如图6所示.
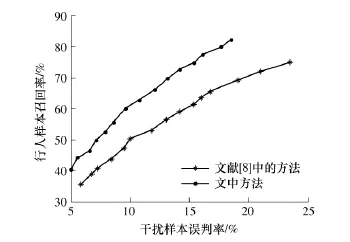
图6 不同概率模板匹配性能的比较Fig.6 Comparison of matching performance of different probabilistic templates
图6表明,在目标匹配阶段,文中的模板建立方式优于文献[8]中的方法.原因在于文献[8]是通过行人样本的步态模式建立相应的概率模板,使得运动方向不同但腿部模式一致的样本被归纳到同一个概率模板中,这有悖于本研究基于运动方向划分多个子类样本以降低行人样本类内方差的做法,因此影响了每一个概率模板对相应姿态下行人外观模式的归纳准确度.
匹配阶段的时间复杂度由式(4)决定.在模板建立之后,式中的分母项可以事先获得,故实际计算时间开销取决于ROI的像素数n.因此每个ROI与模板之间相似度匹配过程的时间复杂度为O(n),是一个线性时间复杂度,表明该方法具备较高的执行效率.值得指出的是,通过设置合适的阈值(匹配值),概率模板匹配法亦可在级联检测框架中作为前端分类器.
4.2 行人检测实验与结果分析
为了验证文中方法的实际性能,从拍摄总长约为80min的视频中抽取4个片段,对应郊区(广州大学城)和市区(广州大道南)两种场景的视频各占2个片段,每段视频长度均为30s(即每段包含750帧图像),并人工标注了视频中的所有行人目标,作为方法验证的客观标准.文中将检测率定义为正确检测到行人的帧数与含有行人的总帧数的比值,虚警率定义为出现误检测的帧数与总帧数的比值.
测试实验运行在Intel Dual-Core E5800 3.2GHz的PC平台上,用Matlab实现,图7为部分检测结果.图中实线矩形为正确检测到的行人区域,点线矩形为漏检的行人(图中在漏检位置用“miss”标识),虚线矩形为虚警(图中在虚警位置用“FA”标识).实线矩形下方的数字为对被检测到的行人运动方向的判断情况,根据模板构建阶段对样本集的划分,数字“1”表示目标沿着摄像头运动,“2”表示横跨公路由右向左运动,“3”表示横跨公路由左向右运动.

图7 部分实测结果Fig.7 Some detection results
方法的统计性能见表1,除了系统级的检测率与虚警率,表中也给出了两种场景中出现的行人总数、实际被检出的个数和虚警数(一帧可能存在多个虚警),便于从分类器级的角度考察文中方法对行人目标的检测性能.

表1 文中方法的性能统计Table 1 Statistical performance of the proposed method
表1表明,文中方法在郊区路段的检测效果较好,因场景相对简单,漏检数较少,虚警率也较低,获得了不低于90%的检测率和不高于10%的虚警率.但在市区路段,场景复杂度的提高导致行人与背景的对比度下降,甚至与背景融为一体,在ROIs提取阶段难以连续、准确地选取目标,造成后续检测与跟踪环节较难填补该漏检目标,使得总体检测率有一定幅度的降低,检测率约为75%;同时,场景中干扰热源的显著增多导致较多的虚警产生,虚警率约为22%.Matlab平台下,文中方法在行人检测阶段的处理速率为4~8帧/s(取决于ROIs的数量),若改为VC或专用图像处理平台,实时性将得到进一步的提高.
5 结语
文中提出一种面向车辆辅助驾驶的夜间行人检测方法,从局部双阈值分割算法获得的二值图像中提取潜在的行人区域,并与离线构造的多尺度概率模板通过相似度匹配进行行人检测,最后对被检目标通过多帧校验的方式进行鲁棒的综合判断.相对于基于机器学习的检测方法,该方法所需训练样本数量较少,且无需收集大量的“困难”负样本以应对分类器推广性能的问题.实验结果表明文中方法检测效果较好,实时性可得到保障,具有一定的应用前景,但在市区场景中虚警率偏高.下一步将考虑结合运动方向和更多的人体形态特征,进一步提高概率模板归纳行人外观模式的准确度,并抑制系统的虚警率.
[1]Soga M,Hiratsuka S,Fukamachi H,et al.Pedestrian detection for a near infrared imaging system[C]∥Proceedings of IEEE Conference on Intelligent Transportation Systems.Beijing:IEEE,2008:1167-1172.
[2]Gerónimo D,López A M,Sappa A D,et al.Survey of pedestrian detection for advanced driver assistance systems[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(7):1239-1258.
[3]Viola P,Jones M.Rapid object detection using a boosted cascade of simple features[C]∥Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Kauai:IEEE,2001:511-518.
[4]Viola P,Jones M,Snow D.Detecting pedestrians using patterns of motion and appearance[C]∥Proceedings of IEEE International Conference on Computer Vision.Nice:IEEE,2003:734-741.
[5]O’Malley R,Jones E,Glavin M.Detection of pedestrians in far-infrared automotive night vision using region-growing and clothing distortion compensation[J].Infrared Physics & Technology,2010,53(6):439-449.
[6]Ge J F,Luo Y P,Tei G.Real-time pedestrian detection and tracking at nighttime for driver-assistance systems[J].IEEE Transactions on Intelligent Transportation Systems,2009,10(2):283-298.
[7]梁英宏.红外视频图像中的人体目标检测方法[J].红外与激光工程,2009,38(5):931-935.Liang Ying-hong.Human detection method in infrared video images[J].Infrared and Laser Engineering,2009,38(5):931-935.
[8]Bertozzi M,Broggi A,Gomez C H,et al.Pedestrian detection in far infrared images based on the use of probabilistic templates[C]∥Proceedings of IEEE Intelligent Vehicles Symposium.Istanbul:IEEE,2007:327-332.
[9]Sun H,Wang C,Wang B L,et al.Pyramid binary pattern features for real-time pedestrian detection from infrared videos[J].Neurocomputing,2011,74(5):797-804.
[10]郭烈,高龙,赵宗艳.基于车载视觉的行人检测与跟踪方法[J].西南交通大学学报,2012,47(1):19-25.Guo Lie,Gao Long,Zhao Zong-yan.Pedestrian detection and tracking based on automotive vision [J].Journal of Southwest Jiaotong University,2012,47(1):19-25.
[11]Gavrila D M.A bayesian,exemplar-based approach to hierarchical shape matching [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(8):1408-1421.
[12]Gavrila D M,Munder S.Multi-cue pedestrian detection and tracking from a moving vehicle[J].International Journal of Computer Vision,2007,73(1):41-59.
[13]Giebel J,Gavrila D M,Schnörr C.A Bayesian framework for multi-cue 3D object tracking[C]∥Proceedings of EuropeanConferenceonComputerVision.Prague:Springer-Verlag,2004:241-252.
[14]赵运基,裴海龙.基于增量学习的关节式目标跟踪算法[J].华南理工大学学报:自然科学版,2012,40(3):88-93.Zhao Yun-ji,Pei Hai-long.Articulated object tracking algorithm based on incremental learning[J].Journal of South China University of Technology:Natural Science Edition,2012,40(3):88-93.
