一种基于异构系统的H.264/AVC运动估计算法
2012-06-23仰枫帆
章 剑,仰枫帆
(南京航空航天大学电子信息工程学院,江苏 南京 210016)
H.264/AVC[1]是目前新型视频编码标准,通过采用一些新的编码技术获得了更高的编码效率以及更好的图像质量。但是由于运算复杂度的增加,难以进行实时编码。而实际上这些新技术在提高编码效率的同时也带来了更高的计算消耗以及对系统内存带宽的需求。另一方面,近年来图形处理器(GPU)的处理速度正在以超过摩尔定律的速度发展,而且能够加速处理一些非图形领域的应用问题。目前人们已经在使用图形处理器强大的并行处理能力,研究如何对H.264/AVC视频编码标准中计算复杂度最大的运动估计模块进行优化,从而加快H.264/AVC视频编码速度。
目前已经有不少基于GPU的H.264运动估计算法被提出。文献[2]利用 CUDA[3]计算平台,实现了H.264/AVC中的运动估计与离散余弦变换(DCT)系数的计算,并且给出了线程块的划分方法,为读者使用GPU优化H.264/AVC编码一些启示。文献[4]提出了一种基于CUDA的块大小可变的运动估计算法,该算法使用块级并行,并取得了12倍的加速比。但该算法忽略了运动矢量(MV)预测,牺牲了视频质量。文献[5]也提出了一种基于CUDA的并行全搜索运动算法。该算法在处理不同大小宏块的运动估计时没有进行进一步优化,虽然视频质量没有损失,但是计算量依然很大。
文中在基于GPU的异构平台上提出了一种新的H.264/AVC运动估计算法。运动估计是H.264/AVC编码过程中最耗时的环节,其计算量占整个编码系统的80%以上[6]。在X264编码软件的基础上引进了针对GPU进行优化的运动估计算法,该算法充分利用了GPU的并行编程模型,大量线程的并行执行使得处理时间大幅减少。利用已得到的小宏块数据进行合成得到整个树形结构的运动补偿信息。最后在NVIDIA GTS450和Intel Core-i5 CPU组成的异构计算平台上试验获得了平均超过50倍的加速比。
1 CUDA硬件模型
近年来新的异构系统被引入到高性能计算中[7]。比如由CPU和GPU组合而成的系统就是一种异构计算系统。现在的GPU都是由上百个核心构成,因而能获得更佳的计算性能。然而GPU的编程方式与CPU有较大的差异,所以使用GPU编程并不是一件简单的任务。为简化GPU编程,NVIDIA公司推出了统一计算设备架构(CUDA)。它可以像使用 CPU一样对GPU进行编程。
与以往的GPU相比,支持CUDA的GPU在架构上了有了显著改进,这两项改进使CUDA架构更加适用于GPU通用计算。一是采用了统一处理架构,可以更加有效地利用过去分布在顶点渲染器和像素渲染器的计算资源;二是引入了片内共享存储器,支持随机写入和线程间通信以减小片外访存延迟[8]。其硬件模型如图1所示。
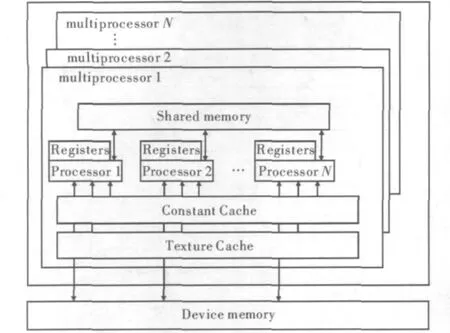
图1 CUDA硬件模型
CUDA源程序由运行于Host(CPU)上的控制程序和运行于Device(GPU)上的计算核(kernel)两部分组成。每个Kernel由一组相同大小的线程块(Thread Block)来并行执行,同一线程块内的线程通过共享存储空间来协作完成计算,线程块之间是相互独立的。运行时,每一个线程块会被分派到一个流多处理器(Stream Multiprocessor,SM)上运行。为管理运行种不同程序的数百个线程,SM利用一种称为SIMT(Single Instruction Multiple Thread)的新架构。SM将各线程映射到一个线程处理器(Thread Processor,TP)核心上,各TP使用自己的指令地址和寄存器状态独立执行。
SIMT单元以32个并行线程为一组来创建、管理、调度和执行线程,这样的线程组称为Warp块。构成SIMT Warp块的各个线程在同一个程序地址一起启动,也可随意分支、独立执行。为一个多处理器指定一个或多个要执行的线程块时,SIMT单元调度器会将其分成Warp块,并由SIMT单元进行调度。将块分割为Warp块的方法总是相同的,每个Warp块都包含连续的线程,递增线程ID。每发出一条指令时,SIMT单元都会选择一个已准备好执行的Warp块,并将指令发送到该Warp块的活动线程。
2 基于CPU-GPU异构系统运动估计算法
这里将介绍一种基于CPU-GPU异构系统的H.264整像素运动估计算法,而运动估计也是H.264编码器中耗时最长的环节。在帧间预测模式下,H.264标准对一个宏块划分模式共有7种:16×16,16×8,8×16,8×8,8 ×4,4 ×8,4 ×4。对于任意一种划分模式,都需要得到该宏块在其参考帧搜索窗口中的SAD值。为此,把运动估计分为3步:首先,计算各个4×4子块的SAD值;其次,根据第一步得到的各4×4子块SAD值,组合得到宏块在其他划分模式下的SAD值;最后,对各种模式下的SAD值进行比较,得到宏块的最小SAD值以及最佳运动向量。
针对CPU-GPU异构系统,将整个计算任务作如下划分。CPU负责将所需编码的视频文件读入计算机主存并拷贝到GPU的显存中,GPU负责核心的运动估计算法执行,并将计算结果传输回计算机主存由CPU进行后续处理。在进行运动估计之前,把在编码过程中不变的数据读入到GPU的常量存储器当中。这些数据信息包括帧的大小,搜索窗口大小,和搜索方式等等。另一方面,每帧的图像信息和参考帧信息需要传输到GPU的全局存储器中。当运动估计结束之后,得到的运动补偿信息将被传输回CPU的主存中。
2.1 4×4子块的SAD值计算
第一个Kernel的目的是为了获得4×4子块的SAD值。首先,为使提出的运动估计算法获得更好的性能,需要对H.264/AVC的搜索方式做一些改变。图1(a)表示了H.264编码器的运动搜索方式。这种搜索区域的分布呈螺旋状,第一个搜索点在整个区域的中心位置。连续的两个搜索点在存储器中的位置不相邻。由于每个像素点需要用来计算多个4×4子块的SAD值,所以需要多次访问每一个像素点。而按照这种方式,就无法对GPU纹理存储器Cache与共享存储器中的数据进行复用。所以这里定义了一种新的搜索方式。如图1(b)所示,搜索顺序从整个搜索区域的左上方开始,按照先行后列的顺序进行。
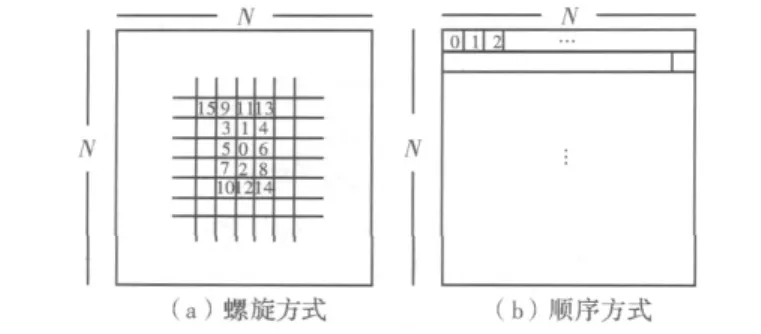
图2 搜索方式
将一个宏块划分成16个4×4的子块,假设搜索区域的大小为M×N,那么需要创建M×N个线程。每个线程计算一个宏块在搜索窗口中一个位置的16个4×4的子块SAD值。每个GPU的线程块有256个线程,所以每个线程块可以得到一个宏块在搜索窗口中256个相邻位置的4×4的子块SAD值。这些4×4的SAD值将用来组合得到其他划分模式下的SAD值。
由于使用新的搜索方式,可以充分利用GPU存储器中的数据复用。在每个线程块开始工作前,该线程块中的所有线程将共同把待预测宏块的数据与参考帧搜索窗口包含的所有数据读入共享存储器中。这种存储模型对全局存储器中的所有参考像素值只需访问一次,减少了对同一个搜索窗口中重复使用像素的多次片外读取,将对片外全局存储器的访问转化为对片内共享存储器的访问。这样可以减少数据的访问延时。
2.2 各种划分模式SAD值的合成
为得到更加精确的预测值,还需要计算宏块在其他划分模式下的SAD值。如果对每一种划分方式都进行全搜索,那么得到的各种划分方式对应的MV肯定是最佳的,但计算量也较大。文中利用已经计算得到的4×4子块的SAD值来合成其他划分模式下对应形状块的SAD值。虽然图像质量有一定损失,但显著减少了计算量。
因此,第二个Kernel主要是为了获得宏块在其他划分模式下的SAD值,同时也对不同划分模式下得到的SAD值进行第一次归约。该Kernel的输入为第一步中获得的128个位置处的4×4的SAD值。
图3中显示了如何使用4×4子块的SAD值合成其他划分模式下的运动信息。为得到8个8×4以及8个4×8子块的SAD值,仅需要相加两个4×4子块的SAD值。例如,将#0与#24×4子块的SAD值相加便可以得到#08×4子块的SAD值,将两个4×8子块的SAD值相加便可得到8×8子块的SAD值。其他形状的子块SAD值都可以根据这种方式计算得到。最后将所有划分模式下得到的SAD值全部存储在线程块的共享存储器当中。
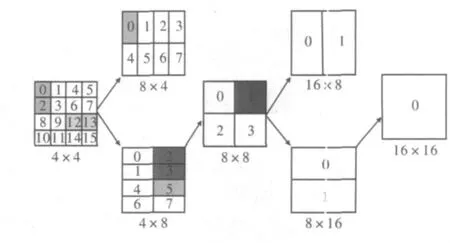
图3 合成其他形状子块
第二个Kernel的另一个任务是对存储在共享存储器中的SAD值进行第一次归约。对于每种宏块的划分模式,整个归约过程都是相同的。在这里以16×16宏块对应的SAD值归约为例说明归约过程。为完成归约过程,一共需要进行7次迭代。线程块刚开始时处理128个子块的SAD值,每进行一次迭代有效线程数目缩小1/2。在进行比较归约的过程中,如果选择相邻的线程进行比较,则会出现两个严重的问题:(1)共享存储器访问冲突;(2)Warp分支严重。为解决这两个问题,文中约定每一次比较过程中的有效线程始终为前N个线程。每个线程取与本线程ID号相差N的线程对应的两个SAD值进行比较,将较小的SAD值及其对应的MV存储到该线程对应的共享存储器中。整个比较归约的过程如图4所示。
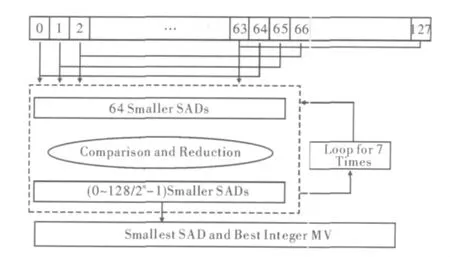
图4 SAD值比较归约
2.3 获取最佳匹配结果
第3个Kernel对第二个Kernel归约得到的数据继续进行归约。第2个Kernel的归约因子为128,所以每个宏块还有M×N/128个候选位置。该Kernel使用与第2个Kernel中相同的归约方法,最终得到每个宏块的最小SAD值以及最佳运动向量。
3 实验结果
为验证文中提出的运动估计算法性能,使用X264[9]开源软件作为试验基础。X264是一款免费的、开放源代码的H.264编码器,并且引入了MMX、SSE、SSE2等多媒体汇编指令来提高编码速度。实验环境配置如下:(1)Intel Core-i52.53 GHz CPU,4 GB内存,Microsoft Visual Studio 2010;(2)GeForce GTS450,1 GB显存,49152 kB Shared Memory,CUDA Toolkit 4.0。
通过选取几种不同分辨率的视频序列进行测试,试验结果如表1所示。
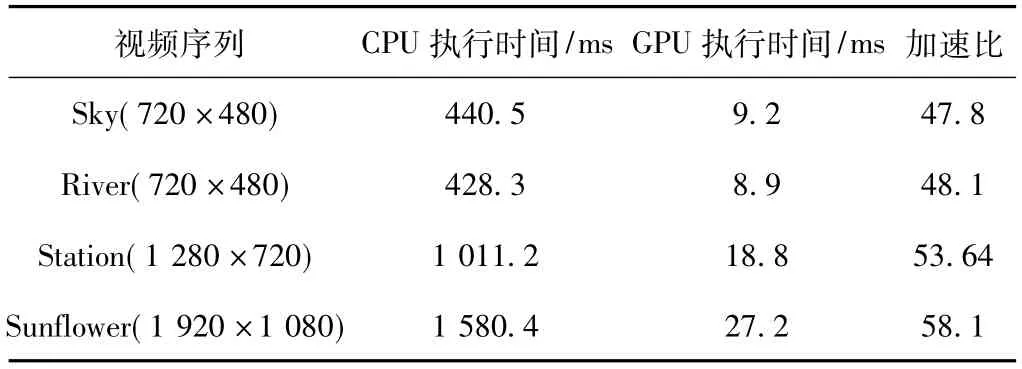
表1 CPU与GPU上运动估计实验结果比较
从实验结果可以看出,在GPU上执行的运动估计算法相比CPU有了较大的性能提升,并且在分辨率越大的视频序列获得的加速比也大。这是因为GPU特别适合计算密集型任务,所需处理的数据量越大,获得的性能提升效果也越明显。
4 结束语
阐述了一种基于CUDA的运动估计算法,并在X264开源编码软件上进行了测试。试验结果表明在不同的视频序列上获得了平均超过50倍的加速比。使用GPU完成视频编码器中计算密集且计算量最大的运动估计模块,获得了显著的性能提升。文中所提出的算法也可作为设计基于GPU的完整H.264/AVC视频编码器的基础,进一步研究编码器其他模块在GPU上的实现方法。
[1]毕厚杰.新一代视频压缩编码标准-H.264/AVC[M].北京:人民邮电出版社,2009.
[2]高智勇,万双,舒振宇,等.基于CUDA的H.264/AVC视频编码的设计与实现[J].中南民族大学学报,2009,28(3):67 -72.
[3]张舒,褚艳利,赵开勇,等.GPU高性能运算之 CUDA[M].北京:中国水利水电出版社,2009.
[4]CHEN Weinien,HANG Hsuehming.H.264/AVC motion estimation implmentation on compute unified device architecture(CUDA)[C].IEEE International Conference on Multimedia and Expo,2008:697 -700.
[5]甘新标,沈立,王志英.基于CUDA的并行全搜索运动估计算法[J].计算机辅助设计与图形学学报,2010,22(3):457-470.
[6]FENG W C,MANOCHA D.High -performance computing using accelerators[J].Parallel Computing,2007,33(10 -11):645-647.
[7]席迎来.H.264/AVC编码的关键算法与VLSI架构研究[D].西安:西北工业大学,2006.
[8]NVIDIA.CUDA programming guide 2.0[M].Santa Clara:NVIDIA Corportion,2008.
