基于多特征集成分类器的脱机满文识别方法
2012-05-04魏巍,郭晨
魏 巍,郭 晨
(1.大连民族学院 计算机科学与工程学院,辽宁 大连116600;2.大连海事大学 航海学院,辽宁 大连116026)
0 引 言
近年来国内外针对汉字印刷体和手写体的识别技术开展了很多研究,取得了一定的成果,但对我国少数民族文字的识别,特别是对满文识别的研究却相对较少。事实上,自清太祖努尔哈赤仿照蒙文字母创制满族文字以来,在近300余年的时间里,满文作为一种官方文字清晰的记录了大量的满清时期我国政治、军事、历史、气象等具有很高史料价值的资料,然而这些资料如今散落在各地的博物馆中,信息利用率较低[1]。运用现代化的识别技术,充分挖掘这些宝贵的档案资料,对于研究满清历史文化,保护和传承我国非物质文化遗产有着十分重要的意义。
1 满文识别系统的架构
满文属于阿尔泰语系满-通古斯语族语支,其书写形式通常带有圈点,故又称为 “圈点满文”。满文识别技术的研究对其它阿尔泰语系文字,特别是对锡伯文和蒙古文的扫描识别研究有重要的借鉴作用。由于大部分满文资料均为手书体,因此本文研究的目标是规范书写的圈点满文手写体。
满文存在字符变形的情况,为了更好的识别满文,针对满文字元开展识别研究。所谓满文字元是组成满文单词的基本单元,通过一系列处理操作获得。首先将扫描成图像的手写圈点满文数字化为二维像素点坐标序列,其次进行二值化、去噪、倾斜校正、行列划分等预处理操作,最后依据一定的算法切分出满文字元。针对字元提取其投影特征、链码特征以及端点和交叉点特征,并组合3组特征进行基于BP神经网络的集成分类识别,将识别得到的结果作为后处理部件的输入进行处理,采用隐马尔科夫模型(HMM)校正识别过程中出现的错判和拒判情况,进一步提高系统的识别率。脱机手写体满文文本识别系统的架构如图1所示。
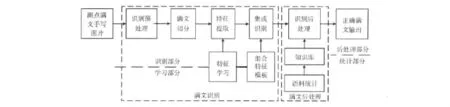
图1 脱机手写体满文文本识别系统架构
2 识别预处理
预处理是识别系统中重要的一个环节,通过二值化、去噪等操作来消除原始图像中一些与统计类别无关的因素,以此提高统计的精度。
2.1 二值化原始满文图像
由于满文文档存放年代久远,书写的纸张存在不同程度的腐蚀和老化,因此在原始满文图像中,背景色的对比度并不总是相同的。为此,设计了动态阈值识别算法来区别图像像素中文本信息和背景信息,并以此二值化图像。求取动态阈值算法如下:
(1)设置128作为图像二值化的初始阈值;
(2)高于128的像素点均作为背景色,低于128的作为前景色;
(3)求出(2)中背景色和前景色的均值,并将两者的平均作为新阈值;
(4)重复操作(2)~(4)直到新阈值与上次阈值变化在2%以内。
2.2 去 噪
手书的满文序列受书写快慢和笔画抖动等因素的影响,通常带有较大的噪声,这对识别将会产生一定的影响,这里采用高斯滤波算法[2],对满文图像进行滤波去噪处理,如下所示
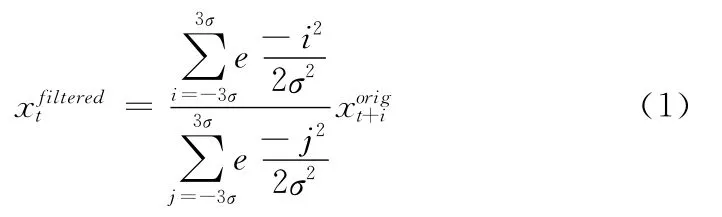
2.3 倾斜校正
满文的书写方式非常独特,与汉字和英文等文字有很大区别。满文书写一般按照从左至右,由上至下竖写完成,每个单词中所有的字符缀连在一个竖直的主干线上,然而由于书写风格不同,部分满文字体存在偏离主干线的情况,因此有必要对满文进行倾斜校正。本文采用Hough变换[3]获得实际满文的主干线,它与垂直线的夹角即为偏离正常主线的角度,将样本旋转相应的角度即可校正倾斜的样本,如图2所示。
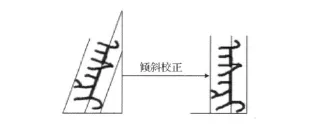
图2 满文 “阁”字的校正
2.4 满文的切分
满文字符拼写复杂,同一个字符根据所在单词位置的不同具有不同的显现形式,如满文元音字母a就有独立形、词首形、词中形和词尾形等不同的显示形式,这为正确识别满文带来很大的困难。为了更好的识别满文,在识别前需要对满文图像进行行列切分,以获取满文字元。如图3所示,左边为正常书写的满文单词,右边为切分得到的满文单词字元。
考虑到满文单词中存在圈点的形式,由于圈点并没有和文字主干相连,可以直接通过扫描法判断它们的存在并得到具体的位置所在,因此在以下切分和文字识别算法中没有考虑圈点的情况。对扫描的满文文本采用分层切分的方式,首先切分出图像中满文文本的列,再切分出每列中不同的单词,再对每个满文单词进行进一步的切分,得到识别用的字元[2,4]。具体切分算法如下:

图3 满文单词 “哲理”字元切分
(1)满文列切分:列切分就是将图像中的每一列满文提取出来。考虑到满文的书写特点,对满文图像进行垂直投影,由于两列满文之间存在一定的空隙,因此在投影图像中必然存在投影的空白区域,由左至右搜索投影图像中空白区域,将空白区域与投影区域的交界作为满文列切分的左右边界,从而切分出满文列;
(2)满文词切分:满文在行文中词与词之间存在一定的空隙,因此针对切分出的满文列在水平方向进行投影,由上至下搜索投影图像中空白区域,将空白区域与投影区域的交界作为单词之间的上下边界,进而切分出满文单词;
(3)满文字元切分:由满文的字形可知,单词中轴汇聚了最多的像素点,中轴的左侧和右侧为满文单词的分支笔画,统计大量的满文单词可知,中轴左右两侧的有效像素信息一般为中轴像素信息的3倍宽度,因此可采用以下算法切分满文字元:
1)对满文单词进行垂直投影,像素点最多的投影区域被确定为单词的中轴边界,计算出满文中轴边界长度,并以此为基准分别向左右扩展3倍中轴边界宽度,重点考察这一区域的满文像素分布情况;
2)对考察区域内的满文单词进行水平投影,分布在中轴左右两侧的笔画信息所投得影像将高于单纯的中轴水平投影,因此将高于中轴投影的像素累积与中轴投影的像素累积的交界点作为满文字元的切分点,依此算法共切分出36个满文字元;
3)通过仿射变换对切分出的满文字元归一化为100*100像素尺寸,同时使用形态学操作来平滑字符图像的边界。
3 特征提取
针对切分的满文字元,通过三类特征集合进行描述,分别是投影特征、边界链码特征和端点交叉点特征。阴影特征从归一化的字符图像中统计获得;边界链码特征通过对图像进行边界追踪从而获得边界点的链码信息;端点交叉点特征从细化为一个像素宽的满文字元骨架中获取。
3.1 投影特征
这里的投影特征是将满文字元向某一方向做垂直映射,所获得的映射阴影长度作为特征集合中的元素进行保存[5]。如图4所示,考察满文字符a的独立形,把封闭满文字元的矩形分为8个象限,将位于不同象限中的字元向垂直边界和对角线上分别做3个方向上的投影计算,以此获得24个投影特征。
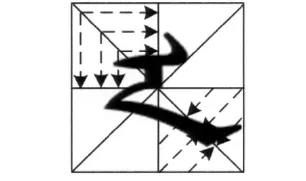
图4 满文字元投影特征的提取
3.2 边界链码特征
使用链码表示图像边界最早是由Freeman提出的。所谓链码可被看作由一系列具有固定方向和长度的小直线段组成。Freeman链码具有两种表现形式,8方向链码和4方向链码[6-7],如图5和图6所示。根据边界跟踪,每个边界像素点被分配不同的码值用来表示下一个边界像素的链码方向,边界跟踪可以按顺时针方向进行也可按逆时针方向。满文字元的字符边界判断方法如图7所示,考虑一个3*3的像素点阵,如果目标点P的4个邻接点中有1个是背景像素点,则称目标点P为边界点。将字元边界图像划分为5*5网格的形式,为了避免因起始点确定的不同而导致链码统计的多样性,这里约定以每个网格中的左下角为基准开始扫描,将遇到的第一个边界点作为本网格内边界像素链码统计的起始点,逆时针方向统计网格内边界像素的4方向和8方向链码值,分别累计获得100个和200个链码特征信息。
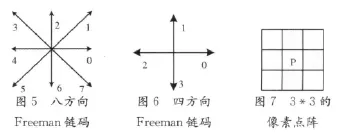
3.3 端点和交叉特征
为了提取满文字元的端点和交叉点特征,需要将满文字元细化为一像素宽度,重点考察满文字元的骨架信息,使用Hilditch算法将满文字元细化为一像素宽度。将细化的图像划分为4*4的网格形式,每一网格的像素尺寸为25*25。统计每个网格中存在的字元骨架的端点和交叉点的特征个数。实际上所谓的端点像素特征是在8方向邻接像素内仅有一个像素点与之相连[8],即(Effect({p})=1)∩(Effect({Next8(p)})=1)。其中p是当前像素点,函数Effect({p1,p2,…,pn})表示返回集合 {p1,p2,…,pn}中的有效像素点个数,Next8(p)表示像素点p的8邻域像素。
像素交叉点特征的确定算法是:设当前黑色像素点为参考点P,考察P点的8方向邻域,确定黑色像素点的个数记为C,从中任选两个不相邻的黑色像素点M和N,分别考察其4方向邻域,确定其与P点相邻的黑色像素点个数,记为C1和C2。若C-C1-C2≥3,则参考点P为像素交叉点。不难发现,若P为交叉点,则在其8方向邻域像素内至少存在3个像素点与之相连,即(Effect({p})=1)∩(Effect({Next8(p)})≥3)是当前像素P为交叉点的必要条件。
统计满文字元的端点和交叉点特征如图8所示,考虑到满文字符的整体结构集中在单词中轴附近,因此仅考察网格4-11,对于其它网格的舍弃,并不影响满文特征的识别效果。统计由端点和交叉点特征组成16个特征值,其中前8个特征为每个网格中的字元端点个数,后8个特征为网格中交叉点的个数,图8所示的端点和交叉点特征为01001110 01000100。
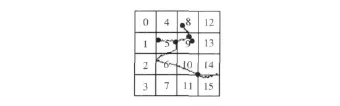
图8 满文字元骨架网格分布
4 分类器的设计
神经网络是对人脑或自然神经网络若干基本特性的抽象和模拟,是一种基于连接学说构造的智能仿生模型,是由大量神经元组成的非线性动力系统。将神经网络用于文字分类识别的出发点是因为神经网络的优点主要是抗干扰能力很强[9]。传统的神经网络模型有BP网络,Hopfield网络,Hamming网络等。本文使用BP网络对提取的满文字元不同特征进行识别分类。通过求得权值空间中下降梯度来使训练样本的方差和最小,以此对满文字元进行分类,其中激励函数采用S型函数,同时为了提高网络的运算效率避免求解限于局部最优,在修正权值ω(k)时,引入了动量项和变学习率的算法,因此权值修改公式如下

式中:η——动量项因子,取值在 [0,1)之间;D(k)、D(k-1)——k、k-1时刻的负梯度;α——学习率,取值在 [0,1]之间,α越大,对网络权值的修改越大,网络学习速度越快,权值在学习过程中易产生振荡,α过小,对权值修改难趋稳定,收敛过慢[10]。采用变学习率算法,在BP网络进化初期快速收敛,随着学习过程的进行,学习率不断减小,网络趋于稳定。变学习率计算公式如下
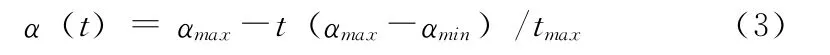
式中:αmax、αmin——最大、最小学习率,tmax——最大迭代次数,t——当前迭代次数。
针对上述提取的满文字元特征,设置BP网络输入层的神经元个数分别为24、100、200和16。通过实验效果的对比,投影、4方向链码、8方向链码以及端点和交叉点特征的隐含层神经元个数分别6、16、18、4时,单个特征识别效果最优。输出层为所分类的字元类别数目,这里为36个类别。BP网络采用简单最大响应策略对满文字元进行分类。
5 分类器的集成
多分类器的集成往往较单分类器的识别能获取更好的识别效果。一般来讲,物体的某一特征仅反映了其某一方面的特性,而从物体提取的多个特征向量,往往具有一定的互补性;另一方面,在当前维度中不好区分的特征,可能在另一种特征空间中很容易区分。因此,考虑采用多分类器的集成对物体的多个特征进行识别,进而达到提高识别率的目的。多分类器集成有3种基本的结构形式,串联型、并联型和混联型[11],分别如图9所示。
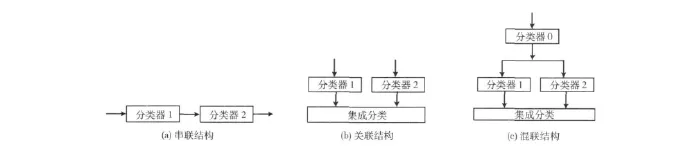
图9 多分类器集成结构
本文采用并联结构设计分类器集成,该集成分类器基于候选字加权多数表决原理对满文字元的3组特征识别结果进行集成判断。集成分类器由C1,C2,…Ck个子分类器组成,待识别满文字元M经过分类器Ck识别后产生n个候选输出ck1,ck2,…,ckn,每个候选输出对应的加权因子为pk1,pk2,…pkn,对应的相似度为sk1,sk2,…,skn。若分类器Ck决定将一个未知的满文字元分类到第i个类,1≤i≤n,n为分类的个数,则其置信度可表示为
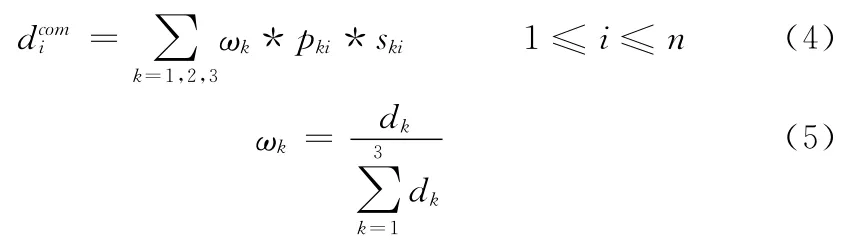
式中:ωk——分类器的加权因子,dk——单独采用一种特征进行分类识别时所获得的识别率。最终系统的集成判据根据置信度最大原则如下

6 识别效果
为了测试集成分类器的识别效果,本文构建了满文字体识别系统,对满文词典中的800个单词进行学习并构建满文的投影、链码以及端点和交叉点特征库,其中每个满文单词选取3种方式书写进行训练。测试样本从 《高宗实录第一卷》中随机抽取600字并分为3部分,每部分200个测试字。所有测试样本经过光学扫描、预处理、归一化等操作转换为标准的100*100二值化像素点阵图像。
实验首先分别单独测试采用投影、链码以及端点和交叉点作为特征的满文识别率。使用3倍交叉验证的方式,将第一和第二部分共400字作为特征训练样本对单系统开展训练,用第三部分的200字对系统进行阴影特征识别测试;将第一和第三部分作为特征训练样本,第二部分进行链码特征识别测试;将第一和第二部分作为特征训练样本,第三部分进行端点和交叉点特征识别测试。测试结果如表1所示。

表1 满文字元不同特征识别率
实验其次对两类单独的特征和三类特征进行集成识别,结果见表2。

表2 多分类器集成识别率
综合表1和表2的数据可知,8方向链码的特征组合识别率要高于4方向链码,集成分类器的识别率要高于单个特征的识别率,同时集成分类器中类别越多,识别效果越好。
7 识别后处理
满文识别后处理的过程就是利用单词识别已获得的满文识别信息,结合满文的构词规则及其统计特性来检测、纠正单词识别输出的拒识词和错识词,以此来提高系统的识别率[12-13]。隐马尔科夫模型(HMM)可以将自然语言和图像观测这两个随机过程有机结合起来,在完成对大量满文单词样本集的识别分析基础上,可以精确地统计出候选词的后验概率,进而提高系统的满文字符识别率。
一个典型的识别后处理架构如图10所示。识别后处理系统由两个部件组成,前端为单词识别器(SCR),后端为语言编码器[14-15]。设满文识别系统从前端部件输入的符号串为A(a1,a2,…ai),识别输出对应于每个ai的候选字集B(bi1,bi2,…bij),后端部件以待定字集B为输入,考虑可能对应的所有满文序列C(c1,c2,…ci),并对每一字串进行概率赋值,选择最优的结果。即设A(a1,a2…an)为待识别的有确定边界的满文序列,C为识别结果,现欲使得C获得最优结果,可表示为P(C|A)=max {P(B|A)}。根据Bayes公式可知max {P(B|A)}=max {P(B)P(A|B)/P(A)},其中P(A),P(A|B)为已知项,因此P(C|A)=max {P(B|A)}可转换为求得max {P(B)}。视满文输入为隐马尔科夫源,采用一阶隐马尔科夫模型,识别结果C可表示为bi-1),其中p(bi|bi-1)为状态转移概率,可通过大规模满文语料库的统计获得。为了避免状态转移概率中出现概率为0的情况而影响最终的分类效果,识别结果C可近似表示为经统计,使用隐马尔科夫模型对满文单词识别结果进行后处理,系统的识别率可提高3%。

图10 典型识别后处理
8 结束语
满文作为近代中国的主要文字之一,记录了大量宝贵的历史文化信息,具有很高的应用研究价值。研究满族文字的识别方法对保护我国少数民族非物质文化遗产,促进民族地区的科技发展有重要的意义。本文根据满族文字的特点,将模式识别和图像处理等技术结合在一起,提出了基于投影、链码以及端点和交叉点特征的多分类器集成识别方法,取得了比较满意的识别效果。采用隐马尔科夫模型对识别结果进行后处理,进一步提高了满文的识别率。由于满文手写字体的标准样库还没有建立,测试数据相对不足,需要在以后的工作中进一步完善。就目前的测试结果看,本文提出的基于多特征集成识别方法在满文的识别中是比较有效的,这对识别其它少数民族文字也有一定的借鉴意义。
[1]WEI Wei,GUO Chen,ZHAO Jing-ying.Implement of manchu script input method in mobile terminal [J].Journal of Dalian Maritime University,2011,37(1):113-117(in Chinese). [魏巍,郭晨,赵晶莹.移动终端满文输入的实现[J].大连海事大学学报,2011,37(1):113-117.]
[2]BAI Wen-rong.Research of the technology of online handwriting Mongolia words recognition [D].Hohhot:Inner Mongolia University,2007:27-28(in Chinese).[白文荣.联机手写蒙古文字识别技术的研究 [D].呼和浩特:内蒙古大学,2007:27-28.]
[3]WANG Hui,MU Hong-xin,WANG Jia-mei,et al.An approach to document skew detection and correction [J].Journal of Yunnan University of Nationalities(Natural Sciences Edition),2010,19(3):232-234(in Chinese). [王辉,牟宏鑫,王嘉梅,等.一种文本图像倾斜校正的方法 [J].云南民族大学学报(自然科学版),2010,19(3):232-234.]
[4]WEI Hong-xi,GAO Guang-lai.Feature selection of Mongolian characters in the recognition of printed mongolian characters[J].Journal of Inner Mongolia University(Acta Scientiarum Naturalium Universitatis NeiMongol),2006,37(6):694-697(in Chinese).[魏宏喜,高光来.印刷体蒙古文字识别中蒙古文字特征的选择 [J].内蒙古大学学报(自然科学版),2006,37(6):694-697.]
[5]Nibaran Das,Brindaban Das,Ram Sarkar,et al.Handwritten Bangla basic and compound character recognition Using MLP and SVM [J].Journal of Computing,2010,2(2):109-115.
[6]LIU Yongkui,WEI Wei,WANG Pengjie,et al.Compressed vertex chain codes [J].Pattern Recognition,2007,40(11):2908-2913.
[7]LIU Yong-kui,WEI Wei,GUO He.Research on compressed chain code [J].Chinese Journal of Computers,2007,30(2):281-287(in Chinese).[刘勇奎,魏巍,郭禾.压缩链码的研究 [J].计算机学报,2007,30(2):281-287.]
[8]ZHANG Guang-yuan,LI Jing-jiao,WANG Ai-xia.Separation and recognition method for off-line handwritten manchu character strokes [J].Computer Engineering,2007,33(22):200-202(in Chinese).[张广渊,李晶皎,王爱侠.脱机手写满文笔画基元的提取和识别 [J].计算机工程,2007,33(22):200-202.]
[9]ZHAO Dong-xiang.A recognition research of off-line handwritten WuMei Tibetan based on BP network [D].Xining:Qinghai Normal University,2009:17-22(in Chinese). [赵冬香.基于BP网络的脱机手写吾美藏文识别技术研究 [D].西宁:青海师范大学,2009:17-22.]
[10] WANG Geng.The research of off-line handwritten Chinese character recognition based on BP neutral network [D].Tianjin:Tianjin Normal University,2009:35-37(in Chinese).[王赓.基于BP神经网络的脱机手写汉字识别研究[D].天津:天津师范大学,2009:35-37.]
[11]ZHU Long-hua, WANG Jia-mei.Off-Line handwritten Yi character recognition based on the multi-classifier ensemble with combination features [J].Journal of Yunnan University of Nationalities(Natural Sciences Edition),2010,19(5):329-333(in Chinese). [朱龙华,王嘉梅.基于组合特征的多分类器集成的脱机手写体彝文字识别 [J].云南民族大学学报(自然科学版),2010,19(5):329-333.]
[12]ZHAO Ji,LI Jing-jiao,WANG Li-jun,et al.Research on the post-processing of Manchu character recognition based on hidden Markov model [J].Journal of Chinese Information Processing,2006,20(4):63-66(in Chinese). [赵骥,李晶皎,王丽君,等.基于HMM的满文文本识别后处理的研究 [J].中文信息学报,2006,20(4):63-66.]
[13]ZHAO Ji,LI Jing-jiao,ZHANG Guang-yuan,et al.Design and implement of off-line handwritten document recognition system of Manchu manuscript [J].Pattern Recognition and Artificial Intelligence,2006,19(6):801-805(in Chinese).[赵骥,李晶皎,张广渊,等.脱机手写体满文文本识别系统的设计与实现 [J].模式识别与人工智能,2006,19(6):801-805.]
[14]ZHANG Guang-yuan,LI Jing-jiao,WANG Ai-xia.Manchu Handwritten character recognition post-processing based on knowledge base [J].Computer Aided Engineering,2006,15(3):69-71(in Chinese). [张广渊,李晶皎,王爱侠.基于知识的满文识别后处理 [J].计算机辅助工程,2006,15(3):69-71.]
[15]BAI Wen-rong,SHOU Zhen-kun.Research of the technology of Mongolia feature information selection [J].Journal of Inner Mongolia Agricultural University,2010,31(1):241-244(in Chinese).[白文荣,寿震坤.蒙古文字特征信息选取技术的研究[J].内蒙古农业大学学报,2010,31(1):241-244.]
