基于BP神经网络的文本验证码破解
2012-04-24高原
高 原
(江苏省邳州市机动车综合性能检测站,江苏邳州 221300)
基于BP神经网络技术识别验证码是破解验证码的关键步骤。BP神经网络是1986年由以Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络。近20年来,神经网络技术逐渐成熟,由于其具有强泛化能力和实用性能,故能有效地解决实际生活中各种分类、识别或与其相关的问题。
现在很多网站都使用验证码,用以阻止自动化程序的恶意注册、论坛灌水和刷票行为。例如,国外的Google,MSN等网站采用验证码来防止非法的邮箱注册等。国内的网易、支付宝等著名的网站也有类似的安全机制,用于防止暴力破解账号。可以说,验证码在网络安全维护方面起着至关重要的作用。最近斯坦福大学的研究团队带来了一个通用破解工具:Decaptcha,它能够以极高的成功率识别出许多网站上的验证码,包括暴雪官方网站、eBay,以及维基百科等,能够成功识别66%Visa支付网站 Authorize.net上的验证码图片,并可以顺利攻陷暴雪娱乐网站70%的验证码。来自斯坦福的这个研究团队随后指出,任何可辨识率超过1% 的验证码系统都不应再继续使用。
文中针对某游戏网站的验证码,采取先分割后识别的思路。根据验证码的特点按照近似颜色统计的方法对其进行分割,然后进行了字符修正:旋转和归一化。在识别方面,采用BP神经网络方法,取得了较好的结果,识别率达到70%以上,每个验证码的平均破解时间为1.625 s。
1 验证码机制
主要针对网络中最流行的基于文本图像的验证码破解。以某游戏网站为例,如图1所示。

图1 某游戏网站验证码
由于无法得知该网站验证码生成的原理,先从其网站上随机获取了100个验证码作为研究样本。通过分析这些样本,观察到该网站验证码有以下特点:
(1)每个验证码都是由4个字母或者数字组成,其中只出现了7个大写字母和9个数字。比较难以区别的例如0和O没有出现,但是出现了I和1。
(2)涉及字符的字体格式不确定,比如同一个数字5就有3种字体格式。
(3)每个验证码字符出现在图片上的位置是随机的,偏左偏右或者偏上偏下都有可能。
(4)图片中存在各种颜色的干扰点和干扰线,背景色是统一的近似于白色或米色(245,245,245)和前景色完全不同。
(5)每个字符的颜色都不一样,字符之间存在粘连。
(6)字符有不同程度的旋转,旋转角度在-20°~20°之间。
上述发现的特征就是破解该游戏网站验证码的关键点。
2 破解过程
验证码破解包括字符提取、字符修正和字符识别。利用前节分析得到的特点,可以将验证码破解过程概括如下:
(1)在字符提取阶段对图片进行预处理降低提取难度,采用颜色统计法提取字符。
(2)在字符修正阶段采用改进旋转算法修正字符,然后归一化。
(3)在字符识别阶段,采用BP神经网络算法对单个字符进行识别。
破解工作是建立在100个研究样本基础上的,为确保研究的正确性和适用性,在该网站另外选取100个测试样本进行验证。
2.1 字符提取
先通过预处理,去除各种干扰点、干扰线,再按照近似颜色统计法和上下扫描法,提取出每个字符。提取的目的是将一个个字符找出来,背景色设置为白色,字符颜色即前景色设置为黑色。
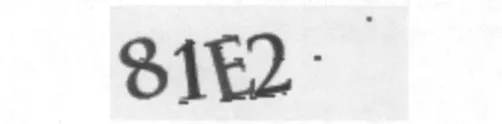
图2 去干扰后的验证码
如图2所示,虽然干扰无法去除干净,但并不妨碍对其进行字符提取。通过之前的特征观察,每个字符的颜色不相同,有别于背景色,且字符之间存在粘连,但是分割并不困难,只需采用近似颜色统计法,统计出除了背景色出现最多的4种颜色,再将这4种颜色的像素点分别呈现在4个模板上。
近似颜色:如图3(a)所示,人眼很容易看出这个字符8是紫色,但是放大看,有淡紫色、深紫色,这个具体要看如何从计算机角度把它们归为一类,从而完整提取出字符“8”。如果只是统计出现最多的紫色(93,44,180),显然会使得提取的字符不完整,如图3(b)所示。
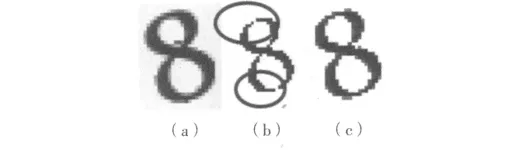
图3 字符“8”
一般在描述一个颜色时采用RGB数值。每种类别的颜色在RGB数值上没有明显的规律,比如紫色色系:(93,44,180)、(131,94,196)、(150,119,204),虽然能看出B分量最大,G分量最小,但是数值上的规律并不明显,所以需要寻找别的途径。
HSV颜色模型[1]是一种从视觉角度定义的颜色模式,这个模型中颜色的参数分别是:色彩H,纯度S和明度V。如表1所示,以紫色为例,同一色系的H值是近似的。

表1 紫色HSV举例
按照这个思路,可以将统计出现最多的颜色和它的近似色也找到一起保留在提取的字符上,这样可以减少因为颜色问题造成的字符破损,如图3(c)所示。
颜色排序:颜色出现次数的排序并不代表验证码本身4个字符的顺序,可以采用上下扫描法,对图片进行从上至下、从左至右的顺序扫描,第一次出现的且在4类颜色之中的即为第一个字符颜色,以此类推。提取的结果如图4所示。

图4 提取的字符
2.2 字符修正
通过对字符的研究发现,当旋转角度不同时,包围字符的矩形框的面积不同。当字符转正时,此时包围它的矩形的面积最小。之前的特征分析已经说明字符的旋转角度在±20°之间,那么当旋转字符的时候可以在正负20°之间,每2°旋转一次,求得包围字符矩形的面积,再比较所有矩形面积找到面积最小时的角度,这就是要旋转的角度。如图5所示,图5(a),图5(b)是旋转前图;图5(c),图5(d)是旋转后图,可以看出图5(c),图5(d)较为相似。

图5 旋转前的字符和旋转后的字符
2.3 字符识别
采用基于BP神经网络的识别方法,对单个字符识别的准确率达89%,对100个测试样本的识别成功率达到70%,平均破解时间为1.635 s,在准确率和速度上都取得理想的效果。
2.3.1 BP神经网络结构以及算法
常见的是3层BP神经网络,包括输入层、隐含层和输出层,如图6所示。

图6 典型的3层BP神经网络拓扑结构
BP神经网络[2]由信息的正向传播和误差的反向传播两个过程组成。结合图6和图7,具体表现为:输入层接收来自外界的输入信息,并传递给隐含层;隐含层负责信息变换,然后将处理的信息传递到输出层;经进一步处理后,由输出层向外界输出处理结果,完成一次正向传播学习过程。当目标输出与目标输出相差太大时,进入误差的反向传播阶段。误差e按误差梯度下降的方式修正各层权值,向隐含层、输入层逐层反传。信息正向传播和误差反向传播交替进行,调整各层权值,完成神经网络的训练学习,一直进行到输出误差减少到可以接受的程度,或者预先设定的学习次数为止。
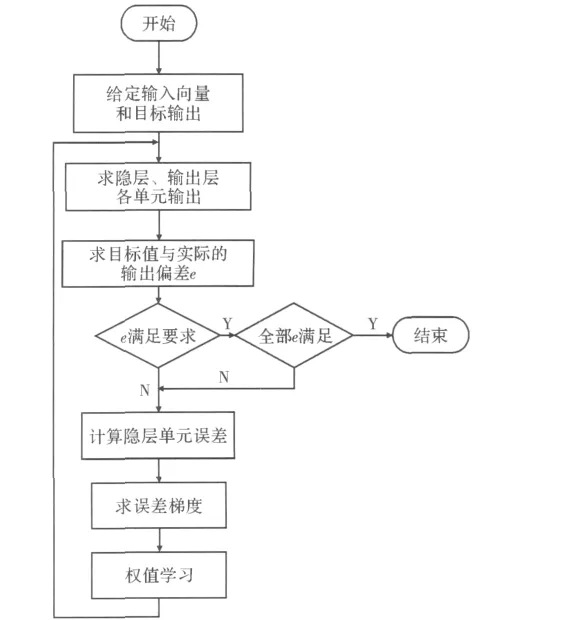
图7 BP神经网络算法框图
对于3层BP网络,假设输入层模式向量为X=(x1,x2,…,xn),目标输出为 T={t1,t2,…,tn},输出层输出向量为Y={y1,y2,…,ym},输入节点与隐含节点之间的权值为wji,隐含层神经元阈值为θj;隐含节点与输出节点之间的权值为Tkj,输出层神经元阈值为γk,i=1,2,…,n,j=1,2,…,q,k=1,2,…,m,激励函数为f(·)。其中f(·)为Sigmoid函数f(x )其输出的动态范围为[0,1]。
(1)信息正向传播过程。
1)输入层:神经元i的输出等于输入值xi。
2)隐含层:对于第j个隐含层神经元,其输入值为其前一层各神经元的输出值netj的加权和
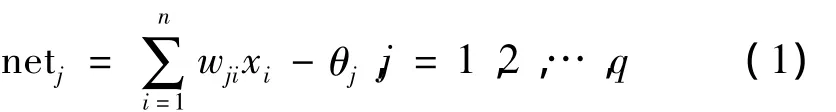
隐含层的输出值Oj=f(netj),f为Sigmoid函数。
3)输出层:对于第k个输出神经元,其输入值netk为隐含层各神经元输出值的加权和

输出层的输出值为yk=f(netk),f为Sigmoid函数。
(2)误差的反向传播过程。
1)误差函数E为

其中,tk,yk分别为第k个输出神经元的目标输出和实际输出。
2)BP学习算法通过E调整连接权值和阈值,权值修正量为

其中,η为学习速率。
3)对于输出层与隐含层之间的权值T与阈值γ
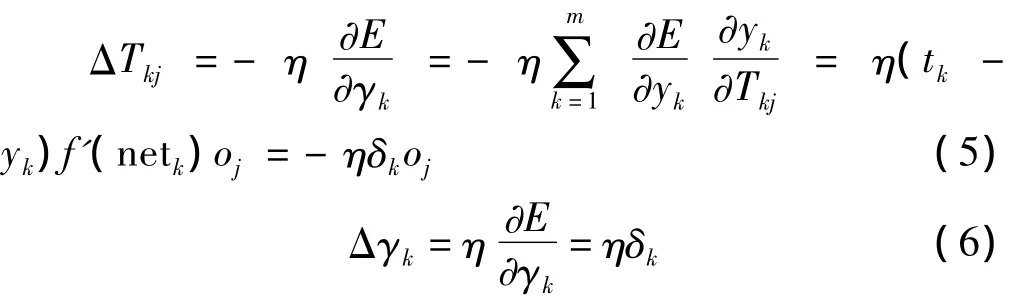
4)对于隐含层与输入层之间的权值W与阈值θ

2.3.2 BP神经网络各层设计
将BP神经网络的思想用于该游戏网站验证码的识别上,就是一个寻找待识别的字符属于哪一类别的分类过程。合理的3层的设计可以提高网络学习速度,同时也能使网络具有良好的识别速度和精确度。
(1)训练样本的选择原则。
1)每个类别均要选取样本,个数视情况而定。根据之前的特征总结,验证码共有16个类别:1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,I,它们出现的概率各不相同,所以在选取样本时无需每个类别的个数相同。
2)样本个数不是越多越好。一般来说样本数越多,训练结果越能正确反映其内在规律,但当样本数达到一定数量后,网络的精度难以提高,无谓地增加只会降低训练速度,而正确率并没有明显变化。所以选择原则:训练样本数是网络连接权总数的5~10倍。
3)样本要求交叉输入。相同类别的样本要尽可能离得远些,防止同类别的样本对权值的修正过大而产生振荡,因为如果同一类别的样本放在一起,会使前一类样本对权值的修正立刻被后一波集中的样本对权值的修正所破坏,导致前一类的映射失效,如此反复,结果会使网络产生振荡。
4)同类别样本的多样性。根据特性总结,每个类别的字符基本都有3种字体,而BP神经网络并不具有不变识别的能力,所以要使网络对字符的旋转、字体类型都能很好地识别,就要多样化的选择各种可能情况的样本,保证识别率。
(2)输入层设计。
BP神经网络输入层的结点个数通常由求解问题的影响因素决定。对于图像识别,影响因素就是图像的识别特征。这一步至关重要,一个好的特征选取将会大大提高识别率。通过对样本字符的观察,发现不同的字符在左右上下区域以及中心区域的字符点个数有较大的区别,所以最后选取了11个特征输入如图8所示。在高10和20,宽6和12处将图片分割成9部分,分别计算每部分的像素个数作为9个特征输入,统计图片中心作为第10个特征输入,再把前9个统计个数相加作为第11个特征输入。所以输入层一共有11个神经元。

图8 特征选取示例图
(3)隐含层设计。
一个合理的隐含层单元数是至关重要,太少可能训练出的网络不收敛,也可能无法准确提取出样本的特征,过多会使网络结构复杂,从而增加训练时间,可能还会将样本中非规律性的内容如干扰和噪声存储进去,反而降低泛化能力。
实际中可参考以下经验公式

其中,m为输出层神经元数目;n为输入层神经元数目;a为1~10之间的常数。文中n为11;m为4,参考两个公式,并结合实际实验效果最终选取隐含层的神经元数为n1=7。
(4)输出层设计。
输出层的节点数由输出值的表达方式决定,一般来说,如果目标类别数为m,则输出层至少取log2m个神经元。预计输出是16个类别,所以设计输出层为log216=4个。
(5)初始值的选取。
权值的初始化决定了网络的训练从误差曲面的哪一点开始,对于学习是否达到局部最小、训练时间的长短以及是否能够收敛的关系很大。初始化主要是将BP网络模型中所有神经元之间的连接权值均赋值为<1的随机数。文中初始的权值取(-0.5,0.5)之间的随机数。
(6)期望误差和训练次数的选取。
在BP神经网络训练过程中,需要一些合适的值作为训练结束的标志。
期望误差,即实际输出和预期输出的差值所能容忍的范围。过大会使得精确度低,过小就需要更多的训练时间或者增加隐含层节点个数来实现。经过多次实验,选取0.01作为期望误差。
当然有时会发现训练较长时间仍未到达期望误差,这时就需要考虑给定训练次数来结束训练,根据实验一般约为9000就可以达到期望误差了,所以这里就选择了10000作为训练结束的候选项。
2.3.3 BP神经网络改进学习
在实际应用中BP神经网络算法存在以下一些问题:
(1)BP算法本质上为梯度下降法,但是它要优化的目标函数又较复杂,所以网络连接权值收敛到一个解时,并不能保证此时的误差为误差曲面上的最小值,而可能是一个局部最小解,使得寻找不准确。
(2)学习率的选择缺乏有效的方法,基本都是通过实验和经验大致选择且固定不变,学习率选择过大,易导致学习不稳定;反之,学习率选择过小,则可能导致过长的学习时间等。
针对以上缺陷,在实际破解过程中加入了以下改进学习算法:
(1)模拟退火算法。
梯度下降法较适合局部最优解的寻找[3],通过查找资料,认为可以采用模拟退火算法,它是一种启发式随机算法,特点是既能向目标函数降低的方向迭代,又能以一定概率接受目标函数升高的情况,当迭代参数足够好时,这种迭代就可跳出局部最优点,从而获得全局最优解。
(2)变学习速率算法。
可以考虑在训练过程中自动调整学习速率的方法[4],检查权值的修正是否真正降低了误差函数,如果是,则增加学习速率,反之,就应该减少学习速率的值。可以采用以下的调整公式

当新误差超过旧误差一定倍数时,学习速率将减小;当新误差小于旧误差时,学习速率将被增加;否则学习速率不变。此方法可以保证网络总是以最大的可接受的学习速率训练。
3 实验结果
文中,给出了随机选取的100个研究样本的实验结果,并对第二次随机选取的100个测试样本进行了验证。
3.1 成功率和识别时间
首先对100个研究样本进行统计分析。在字符提取阶段,分割成功率为100%。在字符识别阶段,采用BP神经网络算法实验发现不同的期望误差对结果的影响如表2所示。

表2 不同期望误差下的识别率和识别时间统计
从表中可以看出,期望误差对结果影响较小,综合比较采用0.01。
对100个研究样本的识别成功率为89%,平均破解时间为1.635 s,对另外100个测试样本的识别成功率为70%,平均破解时间为1.625 s,与研究样本的成功率相比略有降低,但仍是理想的结果,所以可以认为破解了该游戏网站的验证码。因为一个好的验证码设计标准[5]是使人的识别率能达到80%,机器的识别率不足0.01%,而程序的识别率至少为 70%,超过了0.01%。
以1 h为例,可以成功破解1548个,如果使用多个机器同时灌水或者发送免费邮件,将会消耗较大的网站资源,对其他用户正常使用造成影响。
3.2 改进建议
70%的识别率说明了该网站的验证码在设计时存在着许多安全漏洞,有待改进。根据文中所使用的破解方法,提出一些针对性建议。
(1)可以将每个验证码上的字符颜色变成相同的,这样在分割阶段会困难,因为粘连的字符分割至今没有很好的解决方法。
(2)字符可以加大扭曲程度,提高识别难度。
(3)增加背景干扰,如和字符颜色相近的一些宽且短的线条等。
4 结束语
分析了基于BP神经网络的文本验证码的破解。虽然破解工作只是针对某个游戏网站,但是对于其他采用类似验证码机制的网站也适用。文中涉及的方法和思路也可以为其他类型的验证码破解提供新思路。研究验证码的破解有助于更好地发现设计漏洞,维护网络安全。
[1] 邓建全.二维矢量场可视化系统研究与实现[D].北京:北京邮电大学,2010.
[2] 樊振宇.BP神经网络模型与学习算法[J].软件导刊,2011,10(7):66 -68.
[3] 胡山鹰,陈丙珍,何小荣.模拟退火法用于连续变量问题全局优化初探[J].计算机与应用化学,1996,13(1):7-13.
[4] 方帅.BP网络模型的改进方法综述[J].沈阳建筑工程学院学报:自然科学版,2001,17(3):197 -205.
[5] VON AHN L,BLUM M,LANGFORD J.Telling humans and computer apart automatically[J].Communications of the ACM Information Cities,2004,47(2):56 -60.
[6] TURING A M.Computing machinery and intelligence[J].Mind,1950,5(9):433-460.
