用于相似字识别的手写汉字特征优化方法
2012-03-23高学温文欢金连文
高学,温文欢,金连文
(华南理工大学电子与信息学院,广东广州510640)
经过多年研究,尽管已经取得了大量进展,手写汉字识别,特别是无约束的手写汉字识别仍然是文字识别领域最困难的问题之一[1].2010年,中国模式识别会议(CCPR2010)组织的手写汉字识别比赛结果表明[2],针对GB2312-80一级字符集的脱机手写汉字识别,最好的系统仅可以达到89.89%的首候选识别率.手写汉字识别的困难主要表现在大量相似汉字的存在、以及不规则的书写变形等.一些相似汉字间的差别极其细微,例如,“干”和“于”、“大”和“太”等,由于无约束手写汉字中的书写变形的影响,将会导致这些相似字难以正确识别.同时,CCPR2010的测试结果也显示,目前系统已经可以达到98.64%的10候选正确识别率.因此,如何改善相似汉字的识别性能是提高无约束手写汉字识别系统性能的关键问题之一.本文针对手写汉字的特征提取问题,提出了一种用于相似字识别的特征优化方法.
根据汉字笔画的方向属性,人们提出了许多有效的汉字特征提取方法[3-10].本文首先介绍手写汉字识别中常用的几种典型特征提取方法,进而提出一种特征优化的解决思路.弹性网格特征是手写汉字识别中的常用特征之一.Jin等[3]提出了一种方向分解弹性网格特征提取方法,通过弹性网格技术将汉字图像划分为子网格,在每个子网格中,通过求均值,得到子网格的特征值.Gabor特征是另一种常用的手写汉字特征[4].利用二维Gabor滤波器,Huo等[5]提出了一种用于大类别手写汉字识别的Gabor特征提取方法.通过将具有L个方向的二维Gabor滤波器组与汉字图像分别做卷积,得到像素点的L维Gabor特征值.然后根据汉字图像的均匀网格划分,取每个子网格中心点的特征值构成汉字特征向量.梯度特征是目前手写汉字识别中最广泛使用的特征之一[4,9].它最初由Liu等[6]提出并应用于手写数字的识别,后来在手写汉字识别中也取得了较好效果[7,10],该方法利用Sobel算子得到像素点的水平和垂直梯度,并通过梯度向量分解得到像素点的L维梯度编码.联机手写汉字识别中常用的方向特征[8],也采用了类似的笔画分解过程.为了提取手写汉字的梯度特征或者方向特征,通常利用弹性网格或均匀网格划分将汉字图像划分为一些子区域,在每个子区域中通过加权求和运算,例如求均值[7]或者高斯模糊化[8-10]等得到子区域的特征值.然而,这些基于区域划分的特征提取方法,所提取特征无法有效地利用嵌入在子区域内的区分信息,特别是对于差别细微的相似汉字.为了弥补这种不足,一个简单的解决方法是,提高子区域划分的分辨率,提取更高维的汉字特征.极端情况下,可以将每个像素看作一个子区域.然而,这种方法将会导致所提取的特征向量维数过高,例如,对于常规64×64大小的汉字图像采用8方向的分解方法,将得到64×64× 8=32 768维的特征向量.由于目前的手写汉字识别系统中[9-10],特征向量一般会采用LDA(linear discriminant analysis)变换进行特征降维,原始特征向量维数过高将导致LDA算法中的散度矩阵为奇异的.另外,这种方法也会导致LDA变换矩阵的存储量过大而不实用.
受二维线性区分分析(two-dimensional LDA,2DLDA)变换[12-13]在人脸识别中成功应用的启发,本文将汉字特征提取过程和特征降维结合起来,提出了一种基于2DLDA变换的特征优化方法,并用于手写相似汉字的识别.文献[14]给出了一些初步的实验结果.本文结合手写汉字的梯度特征提取过程,对基于2DLDA变换的手写汉字特征优化方法进行了分析和识别实验.
1 2DLDA变换算法
LDA变换[11,15]是手写汉字识别中广泛使用的一种特征降维变换方法,它通过寻找一个最优的线性变换矩阵,将模式向量从高维空间投影到低维空间,以使模式类间散度最大化和类内散度最小化.由于在优化过程中引入了模式类间的区分信息,经过LDA变换后的特征向量不仅可以具有较低的维数,而且识别性能也会得到明显改善.2DLDA变换算法[13,16-17]可以看作是LDA变换针对二维模式矩阵的降维变换的扩展.在2DLDA变换中,进行降维变换的输入模式不再是一维的向量,而是二维的模式矩阵.2DLDA变换通过寻找最优的行向和列向的线性变换矩阵,从而实现模式矩阵的降维变换.由于2DLDA变换中的类间和类内散度矩阵具有较低的维数,算法的时间复杂度可以大大降低,因而在高维模式的压缩变换中具有明显的优势.

以使模式类间散度最大化和类内散度最小化.式中: Y为变换后的低维模式矩阵,变换后的矩阵行和列数分别为d1、d2(d1<m,d2<n).
2DLDA中变换矩阵的优化问题包括列向变换矩阵Z的优化和行向变换矩阵U的优化.设、分别为考虑列向变换矩阵Z时的类内散度矩阵和类间散度矩阵,类似于LDA算法中的Fisher优化准则,变换矩阵Z的优化准则可以定义为
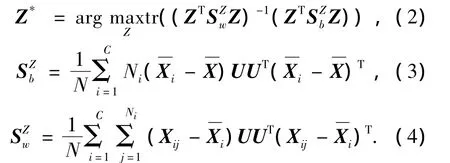
同理,行向变换矩阵U的优化准则可以定义为
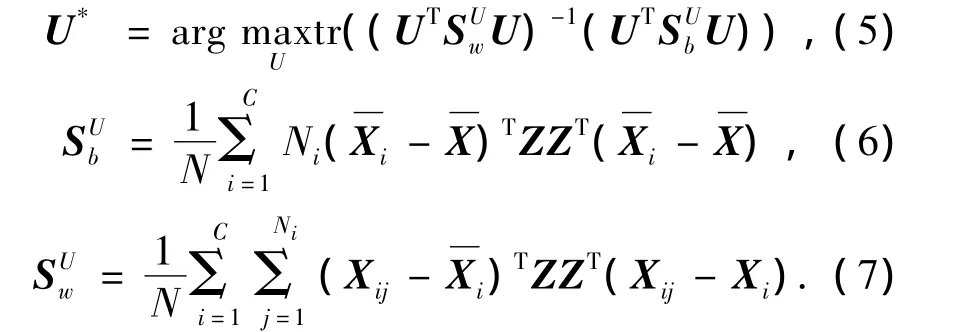
式中:
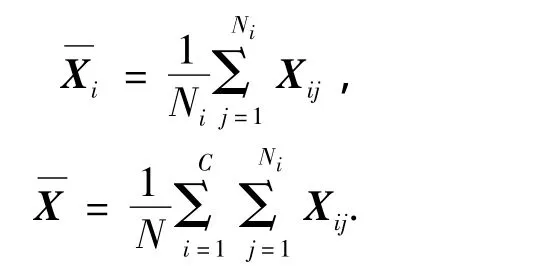
可以证明[9]:最优变换矩阵Z和U*分别由矩阵的d1和d2个最大特征值对应的特征向量构成.特征向量的计算则可以通过特征值分解方法来实现.然而,由于在求解最优变换矩阵的过程中,行向和列向变换矩阵是相互依赖的,难以实现Z和U的同时优化.Ye等[16]给出了一种迭代优化方法,即先固定U,并根据式(2)~(4)求解Z,然后再固定Z,根据式(5)~(7)求解U.经过一定的迭代次数,得到最优的变换矩阵Z*和 U*.Noushath等[13]给出了另一种简单有效的方法,即先固定U为单位矩阵,并根据式(2)~(4)求解最优变换矩阵Z*,反之亦然.Noushath的方法可以看作是迭代优化方法当迭代次数为0时的一个特例.Yang等[17]则采用先固定U为单位矩阵,并根据式(2)~(4)求解最优变换矩阵Z*,然后再利用得到的Z*,根据(5)~(7)求解U*.文献[17]的方法可以看作是迭代优化方法当迭代次数为1时的一个特例.
2 梯度特征优化
梯度特征是手写汉字识别中最常用特征之一,其有效性已经得到了广泛的验证[4,7,9].本节将基于梯度特征描述我们的特征优化方法,手写汉字识别中的其他常用特征,例如Gabor特征等,其优化方法可以采用类似的过程.
如果将特征提取与降维变换看作一个整体,典型的手写汉字特征提取过程可以分解为:1)特征属性计算;2)网格划分与特征向量构建;3)LDA特征变换.特征属性计算主要根据手写汉字的笔画结构特点,在每个像素点计算描述汉字笔画形状及其变化信息的特征属性值,并形成特征属性矩阵.设输入汉字图像为f(i,j),i=1,…,p;j=1,…,q,像素点(i,j)的特征属性值为aij,则有特征属性矩阵A为
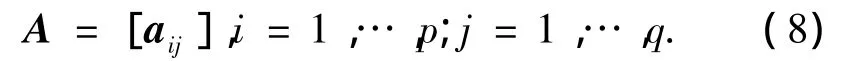
不同的手写汉字特征提取方法,特征属性值的计算过程不同.对于梯度特征,则首先利用3×3的Sobel算子(如图1)计算汉字图像每个像素点的水平和垂直方向的梯度值,然后取L个等间隔(间隔为2π/L)的方向,并分别将每个像素点的梯度向量分解到最相近的2个方向,如图1所示.因此,每个像素点(i,j)可以得到L维的特征属性值(矢量)aij.在大多数的手写汉字识别系统中[4,7,9],8方向的梯度特征通常能够获得最好的汉字识别率,本文实验测试中也将采用这种参数设置.
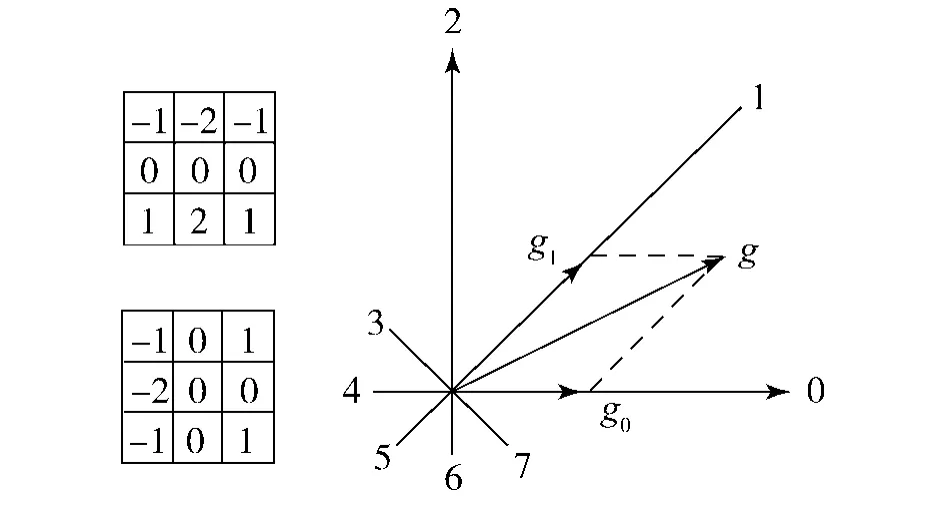
图1 Sobel算子和梯度向量分解Fig.1 Sobel operators and gradient vector decomposition
网格划分与特征向量构建则首先根据汉字图像的笔画像素分布,将图像划分为D×D个子网格(子区域),如图2所示.当采用均匀网格划分时,汉字图像通常会进行非线性归一化的预处理,以适应手写汉字的书写变形.然后,根据汉字图像的网格划分,对每个子网格内像素点的特征属性值进行求均值或者高斯模糊化等加权求和运算,得到该子网格的L维特征值,组合得到手写汉字的特征向量 .由于弹性网格可以线性归一化为统一大小,为表述简便并不失一般性,本文假设汉字图像采用均匀网格划分.如果将特征属性矩阵A按每个网格内像素点的属性值为一行重新排列后的新属性矩阵为M,则:
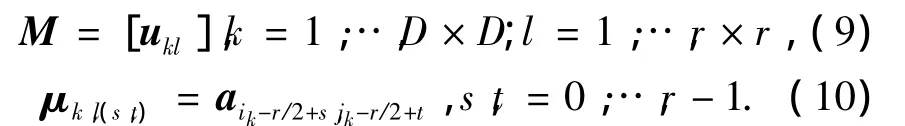
式中:μkl为属性值重新排列后,汉字图像的第k个子网格的第l个像素点的属性值;(ik,jk)为第k个子网格区域的中心坐标,r×r为子网格区域大小;s,t分别为子网格区域的第l个像素点在该子网格内的行列坐标,l=l(s,t)=s×r+t.

图2 汉字图像的网格划分Fig.2 Grid partition of Chinese character images
梯度特征向量v则可以表示为
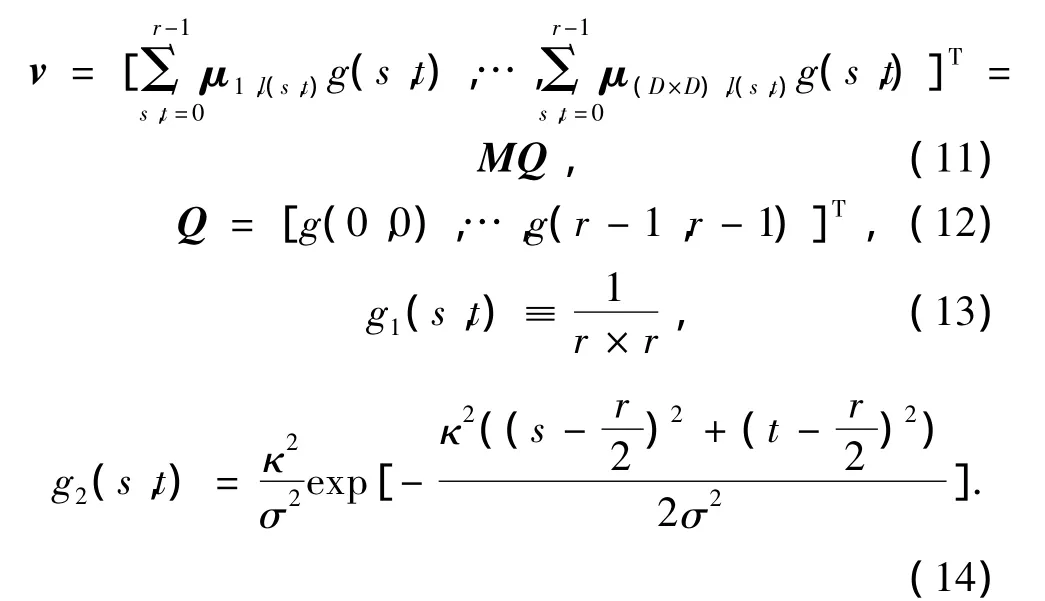
式中:g(s,t)为子网格区域的梯度特征提取中的加权系数,g1和g2分别对应求均值与高斯模糊化运算,κ,σ为常量.
设W为基于特征向量v的LDA变换矩阵,则经过LDA变换的梯度特征y可以表示为
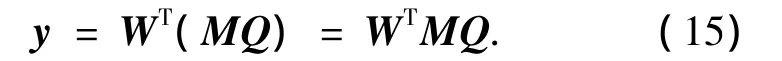
从式(15)可以看出,经过LDA变换的梯度特征向量y的计算过程具有类似2DLDA变换的形式(如式(1)).二者的区别在于:在传统的梯度特征提取过程中,行方向的变换矩阵Q则采用如式(12)、(13)的经验参数设置,因而难以获得最有效的汉字区分特征.需要说明的是,在实际的高斯模糊化运算中,式(14)的作用域可能会超出子网格区域.在这种情况下,根据式(14)的作用域大小,通过将汉字图像划分为部分重叠的子网格,则这种高斯模糊化运算同样可以涵盖在式(11)所表述的框架中.
鉴于 2DLDA变换在人脸识别中的成功应用[12-13,15],本文提出利用2DLDA变换进行手写汉字特征的优化,即利用2DLDA算法通过对样本区分信息的学习,最大化类间散度和最小化类内散度,如式(2)、(5),分别实现列向和行向变换矩阵W、Q的优化,避免了式(13)、(14)中的经验参数设置,从而可以有效地发现训练样本中的区分信息,提高手写汉字特征的识别性能.另外,利用2DLDA变换进行特征优化,变换矩阵Q的列数可以不再限定为1.本文中将根据实验结果来确定变换后特征矩阵的最佳列数(即行向降维后的维数).
本文实验中分别采用Noushath的方法[13]和Ye的迭代优化方法[16]进行了测试.在迭代过程中,变换后模式矩阵的行和列数分别取D×D、r×r,在最终的特征变换中,则分别取d1和d2个最大特征值对应的特征向量构成最优变换矩阵Z*和U*,实现特征降维.需要说明的是,传统的LDA变换中,由于类间散度矩阵的秩最大为C-1,仅存在最多C-1个非零特征值对应的特征向量,变换后的特征向量维数最大只能取C-1.对于2DLDA变换,变换后的模式矩阵的行和列维数最大可能超过C-1.以列向变换为例,其类间散度矩阵如式(3).不失一般性,设U取单位矩阵.令和分别为m×n维矩阵的第j列向量.则:
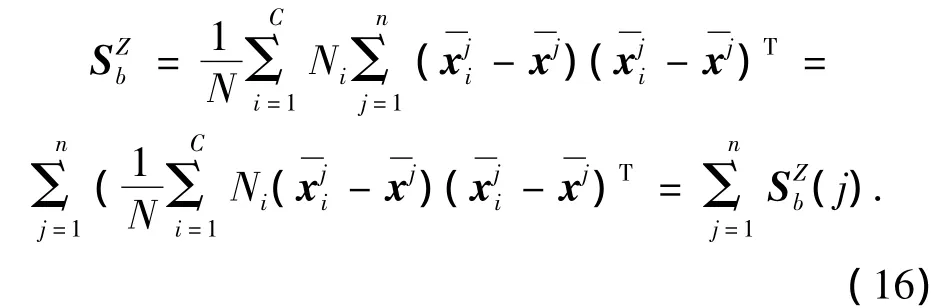
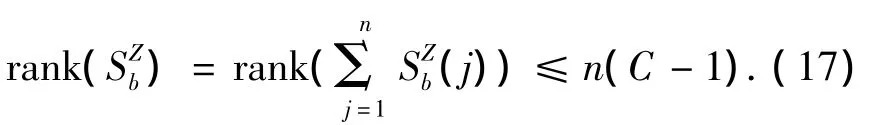
因此,经过2DLDA变换后的模式矩阵的行数上限为n(C-1).
在梯度特征的优化实验中,文中采用了均匀网格划分方法.为了适应手写汉字的书写变形,在属性矩阵计算和特征优化之前,手写汉字图像采用基于线间隔的非线性形状归一化方法[18],将汉字图像归一化为64×64,然后均匀划分为8×8=64个子网格,并计算每个像素点的8方向梯度特征属性值.
3 识别实验及讨论
为了验证本文提出的手写汉字特征优化方法的识别性能,我们利用 863手写体汉字样本字库HCL2000中的样本进行了汉字识别实验.HCL2000[19]是由北京邮电大学发布的一套脱机手写汉字识别样本库,手写汉字扫描分辨率为300DPI,并被线性归一化为64×64的二值图象.实验中,从中随机选择了200套汉字样本,其中100套作为训练样本,100套作为测试样本.
本文从国标GB2312-80一级字库中选取15组易于混淆的相似汉字集作为测试对象,其中每组包含10个相似汉字,由另外单独训练的分类器给出的10个候选字构成.图3给出了一些相似汉字样本.实验中,对15组相似汉字集分别进行识别测试,分类器则采用最小欧氏距离分类器.

图3 实验中的相似汉字样本Fig.3 Some samples of the selected similar Chinese character sets in experiments
第1个实验测试了2种不同2DLDA变换矩阵求解方法,对优化后的手写汉字梯度特征识别性能的影响.实验结果如图4所示.

图4 不同2DLDA变换矩阵求解方法的识别结果Fig.4 Recognition results with the different ways of computation of 2DLDA transformation matrices
从图4(a)、(b)中可以看出,不同的行向压缩维数下,识别率相对稳定,且行向压缩维数d2为1时,识别率相对较高.表明经过优化的手写汉字梯度特征,每个子网格取1个特征分量时,已经能够获得较好的区分能力.而随着列向压缩维数的增加,识别率将会显著提高.当识别率增加到一定程度,再增加列向压缩维数,并不能改善汉字特征的区分能力.从图4(c)可以看出,变换矩阵求解中不进行迭代优化,经过优化后的梯度特征,其识别性能具有一定的优势.因此,以下实验中,变换矩阵求解中不再进行迭代优化,且行向压缩维数d2取1.
第2个实验对比了在相同特征压缩维数下,本文方法优化后的梯度特征与传统梯度特征的识别性能.在传统梯度特征提取中,采用了以下3种策略: 1)利用弹性网格技术将汉字图像划分为子网格,在每个子网格中求梯度属性的均值,构成梯度特征向量(记为M1);2)将汉字图像划分为均匀网格,并在每个子网格中求梯度属性的均值,构成梯度特征向量(记为M2);3)将汉字图像划分为均匀网格,并在每个子网格中利用高斯模糊化运算,构建梯度特征向量(记为M3).在上述特征提取中,均采用8×8的网格划分.当采用均匀网格时,首先采用基于线间隔的非线性归一化方法[17]将汉字图像归一化为64 ×64.在高斯模糊化运算中,波长等参数则采用文献[8]中推荐的设置.在传统梯度特征提取中,特征向量均利用LDA变换进行特征降维.图5为几组不同相似字的行向变换中,最大特征值对应的归一化后特征向量的值(仅给出了前16个分量).从图5可以看出,对于不同的相似字组,其最大特征值对应的特征向量具有明显的差别,表明其区分信息的位置各不相同.对于同组相似字,特征向量各分量的值不同,表明不同位置的像素点对区分信息的贡献也有差别.
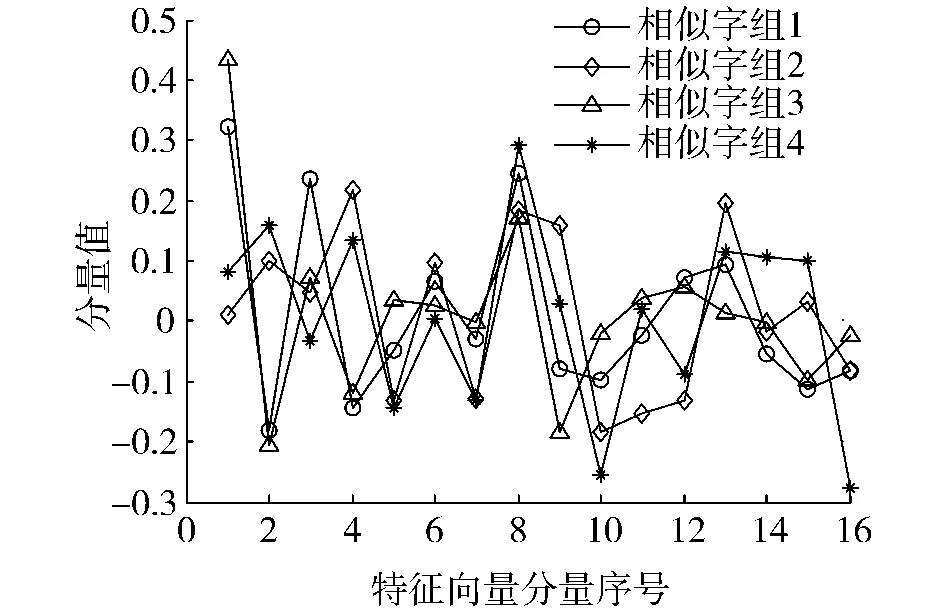
图5 不同相似字的行向变换中,最大特征值对应的归一化后特征向量的值(前16个分量)Fig.5 Normalized eigenvectors corresponding to the largest eigenvalue in row vector transformation for several different sets of similar characters (The first 16 elements)
识别性能的实验结果如图6和表1所示.图6(a)可以看出,对于不同的相似汉字集,在特征压缩到相同维数的情况下,经过本文方法优化后的梯度特征,其识别性能均高于经过LDA变换后的3种典型梯度特征.对于本文方法,则为固定行向压缩维数为1时,不同列向压缩维数的识别率.

图6 相同压缩维数下不同梯度特征的识别结果比较Fig.6 Recognition results comparison of different gradient features with the equal reduced dimensions

表1 不同梯度特征的最好识别结果Table 1 The best recognition rate obtained with different gradient features
图6(b)可以看出,相对传统方法,本文方法的识别率具有明显的提高.在表1中,我们总结了3种典型梯度特征提取方法和本文方法所获得的最好识别率.可以看出,相对于具有最好性能的传统梯度特征提取方法 M3,手写汉字识别错误率可以降低48.86%(优化后的特征维数为1×23)和36.39% (优化后的特征维数取),识别率得到明显改进.实验结果表明,本文提出的特征优化方法可以有效地发现训练样本中的区分信息,验证了本文方法的有效性.
4 结论
本文介绍了一种基于2DLDA的手写汉字特征优化方法,并用于相似汉字识别.通过将特征提取与降维变换结合起来,并设计统一的线性区分分析优化准则,实现特征的优化.实验结果表明:
1)相对于传统的特征提取和LDA变换,基于2DLDA的优化方法可以有效地发现相似汉字间的区分信息,改善识别性能;
2)经过优化的特征,其识别性能要优于传统通过经验参数设置所提取的特征.相似手写汉字识别是进一步提高无约束手写汉字识别系统性能的关键问题之一,所提出的方法可以用于改善相似字的识别性能.另外,所提出的方法也可以应用于其他常用手写汉字特征,例如Gabor特征等优化过程中.
[1]LIU C L,FUJISAWA H.Classification and learning methods for character recognition:advances and remaining problems[M]//MARINAI S,FUJISAWA H.Machine Learning in Document Analysis and Recognition.Berlin:Springer -Verlag,2008:139-161.
[2]LIU C L,YIN F,WANG D H,et al.Chinese handwriting recognition contest 2010[C]//Proc of 2010 Chinese Conference on Pattern Recognition.Beijing,China,2010:1-5.
[3]JIN L W,WEI G.Handwritten Chinese character recognition with directional decomposition cellular features[J].Journal of Circuits,System,and Computers,1998,8(4): 517-524.
[4]DING K,LIU Z B,JIN L W,et al.A comparative study of Gabor feature and gradient feature for handwritten Chinese character recognition[C]//Proc of 2007 Int Conf on Wavelet Analysis and Pattern Recognition.Beijing,China,2007:1182-1186.
[5]HUO Q,GE Y,FENG Z D.High performance Chinese OCR based on Gabor features,discriminative feature extraction and model training[C]//Proc of IEEE Int Conf Acoustics,Speech,and Signal Processing.Salt Lake City,2001: 1517-1520.
[6]LIU C L,NAKASHIMA K,SAKO H.et al.Handwritten digit recognition:investigation of normalization and feature extraction techniques[J].Pattern Recognition,2004,37 (2):265-279.
[7]LIU H,DING X.Handwritten character recognition using gradient feature and quadratic classifier with multiple discrimination schemes[C]//Proc of 8th Int Conf on Document Analysis and Recognition.Seoul,2005:19-23.
[8]BAI Z L,HUO Q.A study on the use of 8-directional features for online handwritten Chinese character recognition[C]//Proc of 8th Int Conf on Document Analysis and Recognition.Seoul,2005:262-266.
[9]LIU C L.Normalization-cooperated gradient feature extraction for handwritten character recognition[J].IEEE Trans Pattern Analysis and Machine Intelligence,2007.29(8): 1465-1469.
[10]LONG T,JIN L W.Building compact MQDF classifier for large character set recognition by subspace distribution sharing[J].Pattern Recognition,2008,41(9):2916-2925.
[11]FISHER R A.The use of multiple measurements in taxonomic problems[J].Annals of Eugenics,1936,7:179-188.
[12]MING L,YUAN B.2D-LDA:a statistical linear discriminant analysis for image matrix[J].Pattern Recognition Letters,2005,26(5):527-532.
[13]NOUSHATH S,HEMANTHA K G,SHIVAKUMARA P. (2D)2LDA:an efficient approach for face recognition[J].Pattern Recognition,2006,39(7):1396-1400.
[14]GAO X,WEN W H,JIN L W.A new feature optimization method based on two-directional 2DLDA for handwritten Chinese character recognition[C]//Proc of the 11th Int Conf Document Analysis and Recognition.Beijing,China,2011:232-236.
[15]RAO C R.The utilization of multiple measurements in problems of biological classification[J].J Royal Statistical Soc.B:Methodological,1948,10:159-203.
[16]YE J,JANARDAN R,LI Q.Two-dimensional linear discriminant analysis[C]//Proc of the 8th Annual Conf on Neural Information Processing Systems.Victoria,British Columbia,Canada,2004:1569-1576.
[17]YANG J,ZHANG D,YONG X,et al.Two-dimensional discriminant transform for face recognition[J].Pattern Recognition,2005,38(7):1125-1129.
[18]LEE S W,PARK J S.Nonlinear shape normalization methods for the recognition of large set handwritten character[J].Pattern Recognition,1994,27(7):895-902.
[19]ZHANG H,GUO J,CHEN G,et al.HCL2000—a largescale handwritten Chinese character database for handwritten character recognition[C]//Proc of The 10th Int Conf Document Analysis and Recognition.Barcelona,Spain,2009:286-290.
