声纹识别中的语言属性映射
2012-02-23靳玉红
靳玉红
(西南科技大学信息工程学院,四川绵阳 621010)
0 引言
在说话人识别领域,系统性能受到训练数据和测试数据长度的制约,可用数据越少系统性能越差。一般实际应用场合中所能获得的话者注册和测试语音都是集中在几秒到几十秒之间,而目前该领域主流算法都是针对几分钟的训练和测试时长来设计的。研究表明,当测试语音长度缩短到10 s或更短时,性能急剧下降[1]。特别是当所获得的训练语音时长也很短时,采用当前主流算法的话者识别系统性能远远低于实际可用的水平[1]。在许多实际场合,譬如军事上的说话人监控可能只有几秒可用于识别的数据,网上银行的声纹验证从客户体验角度也不宜要求过多数据,这些限制条件极大地制约着话者识别系统的应用和拓展。可见,在当前背景下,如何在短时上提高说话人识别的准确率,具有非常高的紧迫性。
在真实的与文本无关的说话人识别系统中,给定目标说话者的训练和测试集合一般都会存在不匹配的问题。这种不匹配包括训练和测试的语言属性变化、信道传输类型、说话者自身身体状况、情绪变化,以及环境噪声等因素[2-4]。这些因素之中,近年来被研究者重点关注的是训练和测试语音时长在约5 min条件下的信道不匹配问题,而语言属性不匹配问题只有较少的研究者做了一些初步尝试[4]。原因在于长时的话者识别任务中,训练和测试语句中包含的足够多的数据量几乎能全部覆盖所有的音素,从而减轻了语言属性失配问题对说话人识别系统性能的影响。然而,在短时的识别任务中,训练和测试语句通常仅含有音素集合中的几个音素,而当前主流用于说话人识别的特征参数,如梅尔刻度式倒谱参数(melfrequency cepstral coeffcient,MFCC)、线性预测倒谱系数(linear prediction cepstrum coefficient,LPCC)等特征提取方法均来自于语音识别[5],这就使得从少数几个音素中提取出来的声学特征参数中引入的语言属性失配问题严重降低了短时话者识别准确率。
解决短时话者识别中语言属性失配问题的研究工作目前还处于萌芽阶段。在美国约翰霍普金斯大学举办的关于说话人识别专题研讨会上的总结报告中(JHU workshop 2008),语言属性失配在短时话者识别中的影响开始受到重视[5-6]。一些著名研究机构(Brno大学,MIT,SRI等)从单音素及音素类对目标说话人建模和测试角度分析了语言属性变化带来的话者识别性能的变化,给出了在美国国家技术和标准署(NIST)举办的说话人测试评测短时任务中初步的验证性实验结论[5]。
本文从消除特征参数中带来的语言属性信息的角度出发,提出了一种语言属性映射方法(linguistic attribute projection-LAP)。首先分析了语言学信息差异影响短时话者识别系统的程度,然后在模型域中估计出短时语音的语言属性空间,最后通过映射的方法在统计参数超矢量空间中减去语言属性的影响。文中的实验结果显示该方法能在较大程度上消除语言属性变化信息,提高短时说话人识别的系统性能,从而证明了语音中同时包含的语言属性信息和说话人身份特性信息是可以在一定程度上分开的。
1 语言属性映射方法
通过引文[8-9]可以得出,从最后的识别性能上看,在文本相关条件下的声纹识别系统远远优于文本无关环境下的声纹识别系统。这就充分说明了正是“文本内容”这个语言学上的信息差异引起了声纹识别系统的性能差异。在本文中,我们将“文本内容的差异性以及声纹识别中训练和测试文本不匹配情况”定义为语言属性的差异性。下面分为3小节分别介绍高斯混合模型(Gauss maxture model,GMM)均值超向量的形成和语言属性空间的估计,以及在声纹识别中消除语言属性的空间映射方法。
1.1 GMM均值超向量
由于训练语言的每一句话的长度不同,因此这里采用均值超向量[8]来构建训练样本。本文采用模型为GMM,对每一句话的不等长的特征进行建模,给定GMM通用背景模型公式为
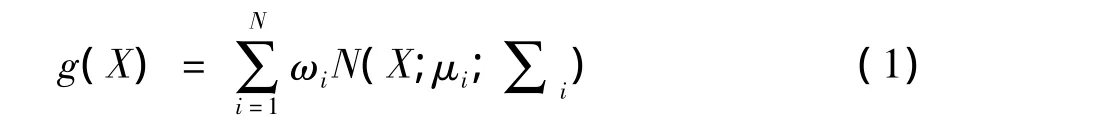
(1)式中:ωi为高斯混合的权重;N(·)为高斯混合函数;μi为高斯混合的均值;∑i为高斯混合的协方差。这里假设采用的方差矩阵为对角阵。
对于给定的目标说话人的语音,通过最大后验自适应(maximum a-posteriori,MAP)方法得到说话人的GMM通用背景模型,并对参数进行更新。由于得到的均值不仅可以抓住最能反映该语音信息的统计量,而且还能便于匹配建模和比较,因此一般只更新均值向量。将所有均值拼接起来就得到了GMM均值超向量,具体形成过程如图1所示。
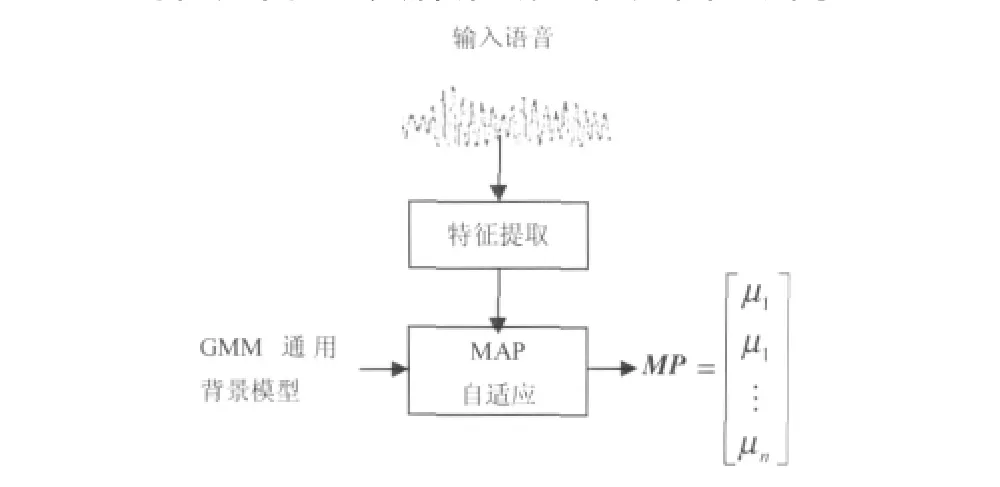
图1 GMM均值超向量形成过程Fig.1 Formation process of GMM mean supervector
一般来讲,高斯数从几百到2 048,每个高斯数的维数是38或39(由前端语音参数的维数决定)。本文中,取高斯混合数目为256,声学参数的维数为39。
1.2 语言属性空间估计
本节主要阐述语言属性空间(LA空间)估计的算法步骤及原理。我们的出发点来源于对扰动属性干扰算法NAP[3]在处理复杂信道问题上的更深层次的理解和改进。首先定义一个矩阵L,L的每一列代表一个用来训练语言属性空间的高斯混合模型的均值超向量[10-11],在本文中该向量的维数 D=256×39,假设有M个训练样本,则L可以写成公式(2)的形式为
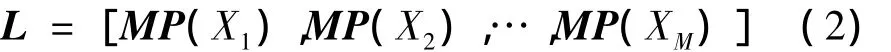
给定L的定义后,可以计算其协方差矩阵C为

由C的前面K个最大特征向量支撑起来的空间即为语言属性空间。但L是一个D×M的高维矩阵,倘若直接做特征向量分解的话计算量非常大,内存空间也要求特别大,这在实际应用中是不可取的。在本文中,我们采用一种巧妙的方法来计算语言属性协方差矩阵C的特征值和特征向量,令G=LTL,我们首先计算G的特征向量η,从而C的特征向量可以由η推导得到为Lη。为了保证训练出来的LA空间不仅捕获了开发集合中训练数据的语言属性特性,而且又不会将说话人身份特性空间也同时平滑掉,在本文中训练LP空间时引入一个加权矩阵Q来达到此目标。从而形成如下最终的语言属性空间估计公式:

diag(y)表示对角方阵,其对角线上元素为y,其他元素为0,1表示全为1的列向量。由于加权矩阵的引入,所求得的空间不仅充分利用了开发集合中训练语句中语言属性的信息,而且还使用了说话人的身份标注信息,从而使得估计出来的语言属性更为纯净。对(4)式做特征值分解得到最终的语言属性空间为

在这里需要特别说明的是训练语言属性空间对开发集合的数据要求比较高,需要每个不同说话人的训练语音能够涵盖到大部分的音素类或者全部覆盖到音素类。这样训练出来的语言特性空间才会比较鲁棒,在实际系统中更具推广性。
1.3 语言属性消除映射
在声纹识别系统中,我们希望得到的用于识别的特征,可以尽量去除不能反映说话人身份特性的其他信息。我们的目标是最大程度的消除对声纹识别系统干扰很大的语言属性信息。当语言属性空间LP估计出来后,通过映射公式(7)来对语言属性进行消除:
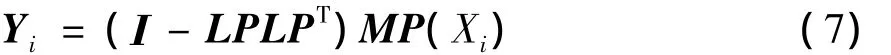
(7)式中:Yi表示最后用于建模和测试的均值超向量;I表示单位矩阵;LP为1.2节中估计出的LP空间;MP(Xi)是原始的高斯混合均值超向量。通过映射后的Yi将被用作后面声纹识别系统建模和测试的特征。通过后面实验结果表明该特征应用于文本无关的声纹识别系统中,能够在较大程度上消除语言属性的影响,提升声纹识别系统的性能。
2 实验设置
2.1 数据库
本文采用自己录制的数据集进行实验,录制环境为安静的办公室环境,数据格式为16 kHz采样、16 bit量化。该数据集一共有200个目标说话人,每人有100~170句录音。每句录音长度约为7~15 s,每个说话人的语音几乎覆盖到所有的中文音素类。实验的训练集合为:从该数据集中挑选出女声49人,男声45人作为目标说话人,每人挑选一句约10 s左右的语音作为注册语音,即每个说话人只有一句注册语音。测试语音从目标说话人的数据中除注册语音之外的数据中挑选出女声805句,男声681句作为测试。训练集合之外的说话人用作训练语言属性空间的开发集合。详细的实验配置见表1。
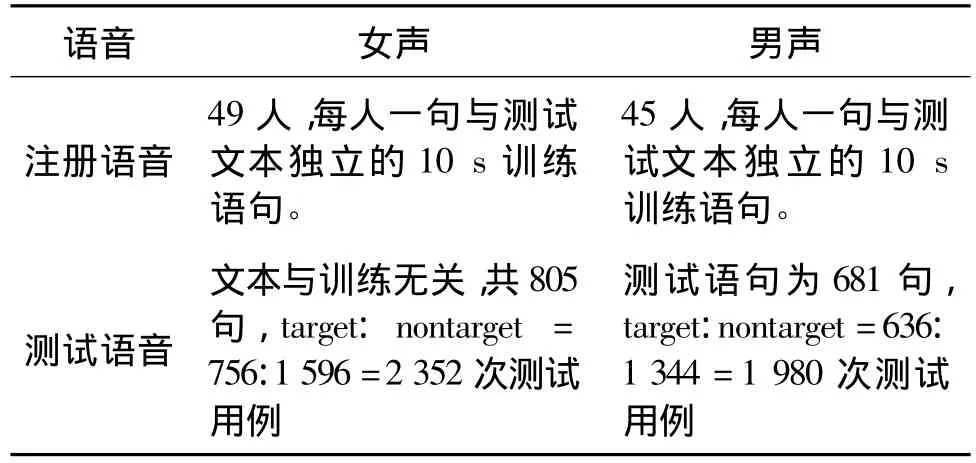
表1 详细实验配置Tab.1 Detailed experiment configuration
2.2 特征参数提取
本文采用的是MFCC参数,对于MFCC参数提取的语音信号先去直流,再预加重(因子为0.97),经过帧宽25 ms、帧移是10 ms的汉明窗。在抽取MFCC特征参数的同时,采用基于能量的寂静帧检测算法去除寂静音。抽取0-12维MFCC,总计为13维,特征参数通过CMS(cepstralmean subtraction)和RASTA(RelAtive SpectrAl)[12-13]进行倒谱域滤波去除信道卷积噪声,通过一阶差分、二阶差分总计构成39维,特征再通过高斯化模块[14]以提高识别率。
2.3 系统描述
2.3.1 基线系统描述
本文由于在实验中所使用的数据为短时的语音数据,所以本次任务为短时的声纹识别任务。为了更好地验证本文所提出方法的有效性,这里给出2套最经典的声纹识别系统作为基线系统做对比试验。系统1是基于产生式模型的高斯混合通用背景模型(Gaussmaxturemodel-universal backgroundmodel,GMM-UBM)系统[14],系统 2 是基于区分行模型的混合高斯超向量-支持向量机(Gaussmaxturemodel-support vector machine,GMM-SVM)系统[11]。下面分别介绍这2套基线系统中关键的参数配置。
GMM-UBM(系统1)中的混合高斯数目为256,最大后验概率自适应MAP[14]的相关因子取16,采用性别相关的通用背景模型(universal background model,UBM),UBM模型训练使用开发集合的数据训练得到。GMM-SVM(系统2)系统中,高斯混合均值超向量采用GMM-MAP的方法先做自适应,然后将GMM模型中的均值拼接起来成为超向量作为SVM的训练语言属性空间LP的特征。SVM采用线性核函数进行分类,惩罚系数C=1 000,SVM的负例样本为开发集合中挑出的数据,男声2 617句,女声3 011句。
2.3.2 GMM-LAP-SVM 系统描述
本文所提出的语言属性映射方法主要是基于GMM-SVM框架上的特征变换,将其称为 GMMLAP-SVM系统(系统3)。该系统中训练语言属性空间LP的数据与其支持向量机模型训练中负例数据相同,LP空间的前面最大特征值对应的特征向量个数 K为60。GMM-LAP-SVM 与基线系统 GMMSVM不同的地方是前者将高斯混合超向量在估计出的语言属性空间中做了映射后的超向量Yi作为SVM的输入特征向量,而后者是直接将高斯混合超向量作为SVM的输入数据。由于本文数据库环境为干净办公室环境,没有信道等其他干扰因素,这种实验环境使得文本内容差异性带来的语言属性不匹配成为降低系统性能的最重要的因素,所以试验结果可以更有力的验证所提方法的有效性。
3 实验结果及相关分析
本文中衡量系统性能的指标采用美国国家标准局NIST标准中的等错误率(equal error rate,EER)为评测性能的指标[1]。各个系统的结果如表2(Female列表示女声测试的性能,Male列表示男声测试的性能)所示。

表2 短时声纹识别任务上不同系统的实验结果Tab.2 Experiment results of comparison systems(EER%)
对比表2中GMM-UBM系统与GMM-SVM系统的结果,可以看出在短时的声纹识别任务上,由于数据量不够的原因,使得均值超向量的特征不能准确地捕捉住说话人身份特点,因此基于产生式模式的GMM-UBM的性能稍好于GMM-SVM系统。但是,一旦将语言属性消除的算法加入到GMM-SVM的特征映射之后,系统的性能得到了很大的提升。从表格的第4行可以看出,本文所提的 GMM-LAP-SVM系统性能比传统的在短时声纹识别中表现良好的GMM-UBM系统在女声测试中提升了17.03%,在男声测试中提升了14.50%。
对比表2的第5行与第3行,在采用同样的配置条件下,采用本文所提方法的系统性能比基线系统GMM-SVM性能在女声测试中提升了20.39%,在男声测试中提升了23.07%。通过与2套传统方法的实验结果做比较,得到的结论都一致性,证明了本文所提LAP方法的有效性。
将GMM-LAP-SVM的得分与系统1进行融合,融合权重设为0.5,融合后的性能比最好的单系统GMM-LAP-SVM性能仍有较大的提升。与系统1融合后EER结果:Female为5.06%,Male为4.72%。
4 结论和展望
本文提出了一种语言属性映射技术且基于该技术构建了一种话者确认系统。语言属性映射首先在模型域中估计出语音的语言属性空间,最后通过映射的方法在统计参数超矢量空间中消去语言属性的影响,得到能够能更纯净反映话者身份特性的超矢量特征并用于建模和测试。该系统能够很好地解决在文本无关的声纹识别系统中的由于语言属性差异引起的训练和测试不匹配问题,实验结果证明了本文所提方法的正确性和有效性。另外,有关在声学参数中反映文本内容和说话者身份内容的更深层次的理论知识还有待进一步的研究。
[1]NIST.The2008 NISTSpeaker Recognition Evaluation[EB/OL].(2008-08-28)[2012-03-02].http://www.itl.nist.gov/iad/mig//tests/sre/2008/official_results/index.html.
[2]LONG Yanhua,YAN Zhi-Jie,SOONG,F K,et al.Speaker Characterization Using Spectral Subband Energy Ratio Based on Harmonic Plus Noise Model[C]//Acoustics,Speech and Signal Processing(ICASSP),2011 IEEE International Conference on,[s.l.]:Conference Publications,2011:4520-4523.
[3]STURIM D E,CAMPBELLW M,REYNOLDSD A,et al.Robust Speaker Recognition With Cross-Channel Data:MIT-LL Results On The 2006 NIST SRE Auxiliary Microphone Task[C]//Acoustics,Speech and Signal Processing,2007.ICASSP 2007.IEEE International Conference on,[s.l.]:Conference Publications,2007:V-49 - IV-52.
[4]SOLOMONOFF A,QUILLEN C,CAMPBELLW.Channel Compensation For SVM Speaker Recognition[C]//Proc.of Odyssey:The Speaker and Language Recognition Workshop,Toledo,Spain;[s.n.],2004:57-62.
[5]BURGET L,BRUMMER N,REYNOLDS D A,et al.Robust speaker recognition over varying channels[R].Baltimore,Maryland:Johns Hopkins University CLSP SummerWorkshop,2008.
[6]BIRKENESO,MATSUI T,TANABE K,et al.Audio,Penalized Logistic Regression with HMM Log-Likelihood Regressors for Speech Recognition [J].Speech,and Language Processing,2010,18(6):1440-1454.
[7]WOLFELM,YANGQian,JIN Qin,etal.Speaker identification using warped MVDR cepstral features[C]//Interspeech,Interspeech 2009,Brighton,U.K:Conference Publications,2009:912-915.
[8]REYNOLDS D A,HECK L P.Speaker Verification:From Research to Reality[C]//Tutorial,ICASSP 2001,Salt Lake City,Utah:[s.n.],2011.
[9]REYNOLDS D A.An overview of Automatic Speaker Recognition Technology[C]//Acoustics,Speech,and Signal Processing(ICASSP),2002 IEEE International Conference on,[s.l.]:Conference Publications,2002:IV-4072-IV-4075.
[10]LIQ,HUANGY.Robust Speaker Identification Using an Auditory-based Featur[C]//Acoustics,Speech,and Signal Processing(ICASSP),2002 IEEE International Conference on,[s.l.]:Conference Publications,2010:4514-4517.
[11]CAMPBELL W M,STURIM D E,REYNOLDS D A.Support Vector Machines Using GMM Supervectors for Speaker Verification[J].IEEESignal Processing Letters,2006,13(5):308-311.
[12]HERMANSKY H,MORGANN,BAYYA A,etal.RASTA-PLP speech analysis technique [C]//Acoustics,Speech,and Signal Processing(ICASSP),1992 IEEE International Conference on,[s.l.]:Conference Publications,1992:I.121-I.124.
[13]XIANG B,CHAUDHARI U V,NAVRATIL J,et al.Short-time Gaussianization for robust speaker verification[J].Acoustics,Speech,and Signal Processing(ICASSP),2002 IEEE International Conference on,[s.l.]:Conference Publications,2002:681-684.
[14]REYNOLDSD A,QUATIERIT F,DUNN R B.Speaker Verification using Adapted Gaussian Mixture Models[J].Digital Signal Processing,2000,10(1-3):19-41.
(编辑:魏琴芳)
