一种基于二进制分辨矩阵的属性约简新算法
2012-02-23赵军,陈宸
赵 军,陈 宸
(重庆邮电大学计算机科学与技术研究所,重庆 400065)
0 引言
粗糙集(rough set)理论[1-2]能处理不一致、不完备和不精确信息,目前已被广泛应用于模式识别、医疗诊断、机器学习、决策分析等各个领域[3-5]。决策表的属性约简是粗糙集信息处理模型中的一个核心内容。所谓决策表的属性约简,就是要在保持条件属性相对于决策属性的分类能力不变的前提下,删除其中不必要的或者不重要的条件属性。已经证明,最优属性约简是一个NP难题[6]。于是,很多学者转而研究更为有效的启发式属性约简算法[7-13],这些算法从信息熵、正区域或分辨矩阵等不同的角度来度量属性的相对重要性。其中,信息熵概念依赖于样本分布概率估算的准确性,当样本规模较小时难以保证其约简性能;在后两者中,尽管基于分辨矩阵的算法时间复杂度相对略高,但这类方法却很直观,易于实现,因此在许多研究和应用中仍然受到重视。经典的分辨矩阵[14]以属性集合为矩阵元素,其空间复杂高、处理效率低,于是有人将其优化为二进制的分辨矩阵,在此基础上提出了新的属性约简算法[15-18],但这类算法的性能仍然有待进一步提高。
本文通过对分辨矩阵进行深入的分析,定义“加权重要度”来更好地刻画属性重要性。这一概念充分利用了分辨矩阵提供的信息,具有明显的物理意义,同时也具有较强的合理性。在此基础上,提出了一种基于“加权重要度”的启发式属性约简算法。仿真结果表明,该算法的综合性能优于参考算法。
1 粗糙集理论的基本知识[2]

其中,BM((i,j),c)表示决策表的第 i和第 j个样本通过条件属性c是否能区分出,若能区分出则为1,否则为0。属性c对应列上‘1’的个数就是c能分辨的样本对数,它能直接描述c的分辨能力;样本对(i,j)对应行上‘1’的个数就是能分辨(i,j)的属性数,其大小反过来能间接地表达相应属性对样本的分辨能力。
显然,若BM中某行上只有1个元素为‘1’,则对应的属性必然是核属性。
2 基于二进制分辨矩阵的加权属性重要度
相较于其他属性约简方法,分辨矩阵能充分表达属性对样本的分辨能力,这一概念在属性约简中的应用也非常广泛[19-22]。经典分辨矩阵以属性名称来表示矩阵元素,不但存储开销大,而且对矩阵的处理均是符号逻辑运算,因二进制分辨矩阵更具有计算简单、计算效率高等优点,并受到广泛关注。在度量候选属性重要性时,文献[15]提出以列方向上‘1’的总数为主,行方向上的为辅;只有当列方向上‘1’的总数相等时,把列对应的属性所在的列值为1的对应的行的“1元素”的数目相加,取和最小的属性。统计多行“1元素”的总个数,而不是单独考虑各行,这种方式过于笼统,必然会掩盖那些具有特殊意义的行所表达的特征,因此这种方式本身具有一定的不合理性。文献[16]则将矩阵行、列上的特征分开,但优先考虑行方向,而事实上,列方向特征对属性的描述能力更强。文献[17]通过统计属性频率综合利用了矩阵行、列两个方向的信息,但对这两者未予区分。文献[18]以列上“1元素”的频率作为属性重要度的度量,而忽略了分辨矩阵行上的特征。
基于此,本文提出了一种基于二进制分辨矩阵的算法,该算法定义在二进制分辨矩阵中的列方向和行方向上同时对属性进行度量的“加权重要度”,作为度量属性重要度的一种方式。

定义8中,属性的“列重要度”CI表明了属性所能区分的项在分辨矩阵中所占的比例,该值越大,表明属性能区分的项越多,属性重要性就越重要,是属性重要性的直接体现。
定义10中,属性的“行重要度”RI越大,包含该属性的最小项的长度越短,能区分相应样本的属性越少,间接表明属于该项的属性越重要。极端情况下,当某一行上‘1’的总数刚好为1个时,所对应的属性是核属性,一定属于约简集合,此时,该属性的“行重要度”为1,准确反映了核属性的特征。
定义11中,属性的“加权重要度”RCI是对属性的CI和RI进行加权后得到的结果,该值越大,说明属性越重要。
通过选择适当的加权参数α,β,能使加权结果体现出不同的特性。当α≪β时,属性的加权重要度取决于列方向上的特征;反之,当α≫β时,属性的加权重要度取决于行方向上的特征。
分辨矩阵列方向的特征直接表明了属性分辨样本对的数量,而行方向特征直接表明的是能够分辨相应样本对的属性的多寡,反过来间接地表明了相应属性的分辨能力。因此,从描述属性的分辨能力来看,分辨矩阵列方向上的特征更为重要,因此,在合成加权重要度时,一般取αβ。

3 基于加权属性重要度的属性约简算法
3.1 算法描述

3.2 算法复杂性分析
时间复杂度方面,本文算法与相关文献报道的基于二进制分辨矩阵的同类算法(如文献[15-18])相同,都为)。但由于本文算法是基于二进制分辨矩阵定义的“加权重要度”概念,将矩阵列与行两个方向的特征通过加权求和的方式集成为一个概念,与同类算法相比,本文的方式既充分利用了矩阵信息,在选择属性时又不必分别对列与行2个方向的特征进行排序,只需排序一次就可选出一个属性,减小了排序运算量,因此时间效率较同类算法更优。
空间复杂度方面,本文算法与基于经典分辨矩阵的属性约简算法相同,都为),但由于经典的分辨矩阵需要存储所有的区分对象,而采用二进制形式的分辨矩阵只需存储对称矩阵,其存储规模实际上比经典分辨矩阵减小了一半,并且将极其困难的符号逻辑运算化为简单整数运算,因此其效率比基于经典分辨矩阵的属性约简算法更优。
3.3 算法实例分析
二进制分辨矩阵BM中,有6个条件属性a,b,c,d,e,f;11 个项,如表1 所示。
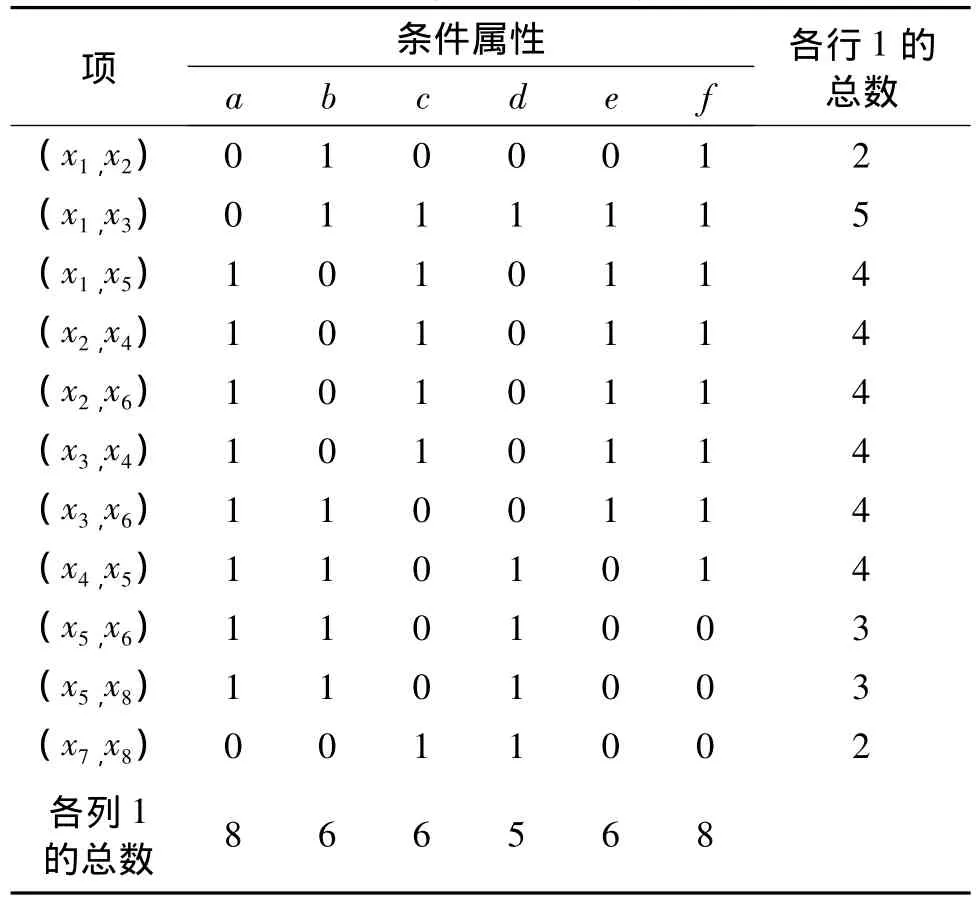
表1 二进制分辨矩阵Tab.1 Binary discernibilitymatrix

选择使 RCI最大的属性 f,加入约简集合REDU,删除f所在的列及在该列上值为1的行,得到表2的结果。

表2 删除属性f后的二进制分辨矩阵Tab.2 Binary discernibilitymatrix after removing the attribute f
同理,对表2继续计算RCI,可知属性d的RCI最大,加入到REDU中,删除d所在的列及在该列上值为1的行,得到空表,算法结束,此时REDU={d,f}。这一结果为该系统的最优约简,因为任何单一的条件属性均不能保持系统的相对正域。
而采用文献[15]介绍的同类方法,易得到约简集合REDU={a,b,c},这并不是系统的最优约简。
4 算法仿真测试结果及分析
本文选用了UCI中6组数据集,在2G RAM,2.4G CPU,WIN7系统的计算机下,vc6.0开发环境中进行实验。分别采用本文算法(算法1)、文献[15]的算法(算法2)、文献[7]中的 MIBARK 算法(算法3)和文献[8]中的CEBARKCC算法(算法4)进行属性约简。其中算法1中的加权参数取α=为二进制分辨矩阵的项的总数。实验得到了表3的结果。

表3 属性约简结果比较Tab.3 Attribute reduction comparison of different algorithms
从表3可以看出,实验采用的6组数据集中,在属性约简结果上,算法1和算法4都得到了最优约简,而算法2和算法3得到的结果有部分不是最优约简。在运行时间上,算法1的速度较算法3和算法4有较大提高,略快于算法2。从实验结果来看,本文提出的算法(算法1)的综合性能是最佳的。
5 结论
本文基于二进制分辨矩阵中行和列方向上的特征,定义了“加权属性重要度”概念来度量属性的相对重要性。这一概念充分考虑了列及行对属性重要性描述能力的差异,具有更好的物理意义及合理性。在此基础上,提出了一种启发式属性约简算法。仿真实验结果表明,该算法是高效可行的。下一步要研究的工作就是如何进一步减少分辨矩阵的存储空间,以降低算法的时间和空间复杂度,这对于大型数据集具有非常重要的意义。
[1]PAWLAK Z.Rough set[J].Communications of the ACM.1995,38(11):89-95.
[2]王国胤.ROUGH理论与知识获取[M].西安:西安交通大学出版社,2001.
WANG Guo-yin.Rough set theory and knowledge acquisition[M].Xi'an:Xi'an Jiaotong University Press,2001
[3]刘清.Rough集及Rough推理[J].计算机研究与发展,2003,7(40):969-970.
LIU Qing.Rough set and rough reasoning[J].Journal of Computer Research and Development,2003,7(40):969-970.
[4]ZIAKOW.Rough sets;Trends,challenges,and prospects[M]//ZIARKO W,YAO Y Y.Rough Sets and Current Trends in Computing(RSCTC 2000).Berlin:Springer-Verlag,2001:1-7.
[5]王珏,苗夺谦.关于Rough Set理论与应用的综述[J].模式识别与人工智能,1996,9(4):337-344.
WANG Jue,MIAO Duo-qian.Rough set theory and it'sapplication:A survey[J].Pattern Recognition and Artific-ial Intelligence,1996,9(4):337-344.
[6]WONG SK M,ZIARKOW.On optimal decision rules in decision tables[M].Poland:Bulletin of Polish Academy of Science,1985:693-696.
[7]苗夺谦,胡桂荣.知识约简的一种启发式算法[J].计算机研究与发展,1999,6(36):681-684.
MIAO Duo-qian,HU Gui-rong.A heuristic algorithm for reduction of knowledge[J].Journal of Computer Research and Development,1999,6(36):681-684.
[8]王国胤,于洪,杨大春.基于条件信息熵的决策表约简[J].计算机学报,2002,25(7):759-766.
WANG Guo-yin,YU Hong,YANG Da-chun.Decision table reduction based on conditional information entropy[J].Chinese Journal of Computers,2002,25(7):759-766.
[9]吴尚智,苟平章.粗糙集和信息熵的属性约简算法及其应用[J].计算机工程,2011,7(37):56-58.
WU Shang-zhi,GOU Ping-zhang.Attribute reduction algorithm on rough set and information entropy and it's application[J].Computer Engineering,2011,7(37):56-58
[10]吴静,邹海.基于属性重要性的属性约简算法[J].计算机应用与软件,2010,2(27):255-257.
WU Jing,ZOU Hai.Attribute reduction algorithm based on importance of attribute value[J].Computer Applications and Software,2010,2(27):255-257.
[11]刘高峰,牟廉明,张涛.基于改进区分矩阵的决策表增量式属性约简[J].计算机工程,2010,20(36):46-48.
LIU Gao-feng,MOU Lian-ming,ZHANG Tao.Incremental attributes reduction of decision table based on Imp-roved discernibilitymatrix[J].Computer Engineering,2010,20(36):46-48.
[12]李永华,蒋芸,王小菊.一种基于rough集的属性约简的改进算法[J].计算机应用,2008,8(28):2000-2002.
LIYong-hua,JIANG Yun,WANG Xiao-ju.An Improved algorithm for attribute reduction based on rough sets[J].Journal of Computer Applications,2008,8(28):2000-2002.
[13]YU Hong,YANG Da-chun.A Knowledge Reduction Algorithm Based on Conditional Entropy[J].The Journal of China Universities of Posts and Telecommunications,2001,8(3):23-27.
[14]SKOWRON A,RAUSZER C.The Discernibility Matrices and Functions in Information Systems[M]//Intelligent Decision Support Handbook of Applications and Advances of the Rough Sets Theory.Dordrecht:Kluwer Academic Publishers,1992:331-338.
[15]侯利娟,史长琼.基于分明矩阵的属性约简启发式算法[J].计算机工程与设计,2007,28(18):4466-4468.
HOU Li-juan,SHI Chang-qiong.Heuristic algorithm to rough set attribute reduction based on discernibilitymatrix[J].Computer Engineering and Design,2007,28(18):4466-4468.
[16]周海岩,杨汀.基于二进制可辨矩阵的属性约简算法的改进[J].计算机工程与设计,2003,12(24):35-37.
ZHOU Hai-yan,YANG Ting.A more efficient algorithm for attribute reduction based on the binary discernibility matrix [J].Computer Engineering and Design,2003,12(24):35-37.
[17]李龙澍,王慧萍,徐怡.二进制可分辨矩阵的最小属性约简算法[J].计算机技术与发展,2010,6(20):93-96.
LILong-shu,WANG Hui-ping,XU Yi.Algorithm for the least attribute reduction of binary discernibility matrix[J].Computer Technology and Development,2010,6(20):93-96.
[18]蒙祖强,史忠植.一种新的基于简化二进制可辨矩阵的相对约简算法[J].控制与决策,2008,9(39):976-978.
MENG Zu-qiang,SHI Zhong-zhi.Algorithm for relative reduction based on simplifried binary discernibilitymatrix[J].Control and Decision,2008,9(39):976-978.
[19]胡可云.基于概念格和粗糙集的数据挖掘方法研究[D].北京:清华大学,2001.
HU Ke-yun.Research on concept lattice and rough set based dataminingmethods[D].Beijing:Tsinghua University,2001.
[20]李智玲,胡彧.一种改进的区分矩阵属性约简算法[J].计算机系统应用,2008,17(10):51-55.
LI Zhi-ling,HU Yu.An improved algorithm for attribute reduction of discernibility matrix[J].Computer Systems and Applications,2008,17(10):51-55.
[21]HU X H,CERCONE N.Learning in relational database:Arough set approach[J].International Journal of Computational Intelligence,1995,11(2):323-338.
[22]NGUYEN SH,NGUYEN H S.Some efficient algorithms for rough setmethods[C]//Proceedings of the Conference on Information Processing and Management of Uncertainty in Knowledge Based Systems.Granada.Spain:[s.n.].1996:1451-1456.
(编辑:魏琴芳)
