一种基于知网的情感计算方法*
2012-02-08沙有闯黄存东
沙有闯,黄存东
(安徽国防科技职业学院信息工程系,安徽六安237011)
情感计算是文本倾向性分析(Sentiment Classification)的基础,它的目标是让计算机能分辨人类的情感和调性。Peter D Turney等指出,倾向性分析是针对某篇文章中对某个事物(或产品)的评价、看法等信息进行文本情感分析与挖掘,进而得出该文章对该事物(或产品)的评价调性(即正面、负面或中性[1])。Tetsuya Nasukawa等的研究表明,文本倾向性分析的主要任务包括[2]:(1)提取能够体现文档情感的关键词或短语;(2)通过计算词语相似度等方法判断关键词的倾向性调性及调性的强度;(3)通过文本特征计算判断关键词与文档主题的关系。
自20世纪90年代以来,情感计算的研究取得了较大的进步,其研究方向主要包括基于语义的和基于机器学习的[2]。前者通过分析每个词体现出来的态度倾向来分析文本的情感倾向,并为其赋予相应的权值,最终通过组合这些倾向值来计算语句及文档的语义倾向。后者是基于已经标注好的训练集,再使用机器学习的方法构建两个分类器,分别代表正面训练集和负面训练集。
1 基于知网的情感词典构建方法
1.1 情感词汇的来源
知网是一个以中文(汉语)和英文(英语)的词汇所代表的概念为描述对象,用于描述概念间的关系和概念属性间的关系的自然语言处理系统[3]。知网中最重要的两个概念是“概念”和“义原”。“概念”是对词汇语义的一种描述。“义原”的作用是描述“概念”,每个概念都至少有一个“义原”。知网共有1 500个义原,这些义原分为10大类,可以分为3组:基本义原用来描述单个概念的语义特征;语法义原用于描述词语的语法特征;关系义原用来描述概念和概念之间的关系。对实词的描述可以由上述的10类义原组成的语义列表构成。
情感词汇是指能够明显表达情感倾向的词或短语。在知网中,可以根据词语的属性“良”、“莠”来抽取倾向性词汇,“良”即褒义词汇,“莠”即贬义词汇。抽取出来的倾向性词汇可以用于文本倾向性分析。
1.2 情感词汇构建
本文基于知网2007年10月22日发布的“情感分析用词语集(beta版)”[3],构建计算文本倾向性的情感词典。该词语集共包含中文情感分析用词语集和英文情感分析用词语集两个版本,每个版本分别有6个部分(如表1所示),分别包含“正面情感”词语、“负面情感”词语、“正面评价”词语、“负面评价”词语、“程度级别”词语和“主张”词语。此词语集共包含词语约17 887个。
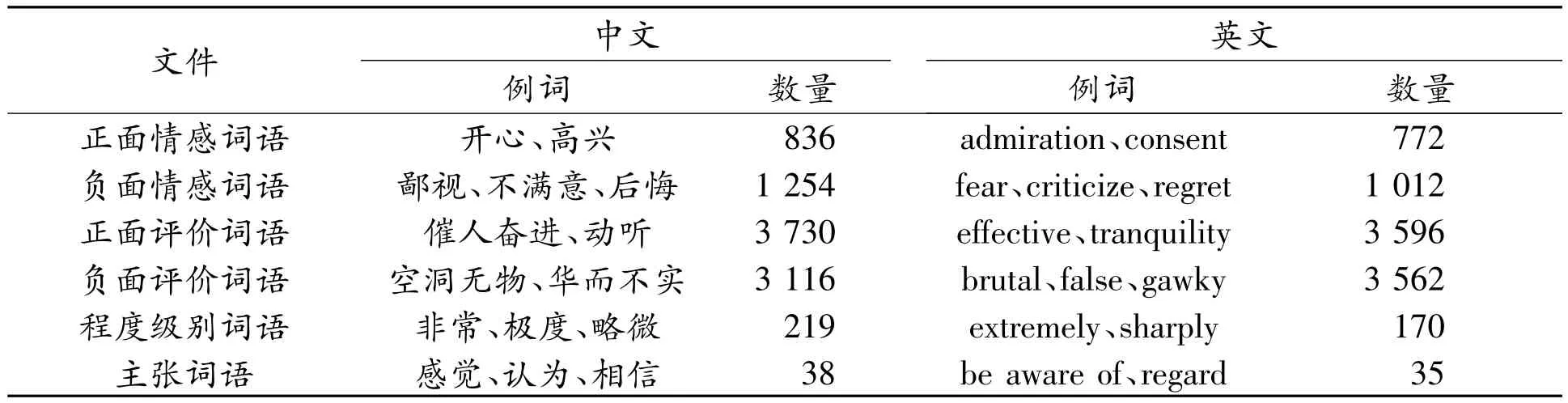
表1 情感分析用词语集构成
1.3 副词及加权方法
由于语义层次上的情感倾向不足以准确表达文本情感倾向,如“不理想”、“不甚理想”、“比较理想”和“非常理想”这四个词语都是关于正面的情感词“理想”的,但是其表达的含义不同,整个句子的语义倾向性强度也会发生不同程度的改变。因此,还应增加独立的程度副词词典,并为不同的程度副词赋值,以表示文本倾向性强度。具体的程度级别及赋值如表2所示。

表2 程度副词及加权
1.4 否定副词构成
否定副词在文本倾向性计算中是不可或缺的重要因素之一,它直接改变文本的倾向性。如上述的“不喜欢”和“喜欢”具有截然相反的倾向性。具体的否定副词列表如表3所示。

表3 否定副词表
2 基于知网的情感计算方法
2.1 情感计算模型及其分析
本文构建了一个情感计算模拟系统,系统框架结构如图1所示。本系统将随机从互联网上抓取的文档进行分词、标注词性等预处理后交由情感计算系统进行情感计算。具体计算过程包括以下4个步骤:
(1)文档情感词汇提取,提取能够代表文档情感特征的词汇用于度量文档情感倾向性;
(2)计算特征关键词的倾向性并综合程度副词的强度及否定副词,得出词语倾向性度量值;
(3)综合计算语句级的语句倾向性度量值;
(4)综合计算篇章级的篇章倾向性度量值。
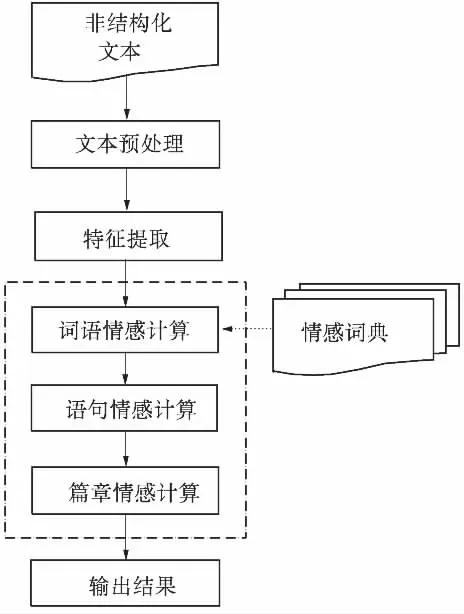
图1 情感计算系统框架结构图
2.2 基于知网的语义相似度计算
上述步骤中,词语倾向性的计算、语句倾向性计算及篇章倾向性的计算需要首先计算词语的语义相似度。刘群等[4]利用知网义原树中的距离计算义原相似度,进而得出词语的语义相似度。知网中,若词语有多种表达含义,则词语对应有多个义原。义原相似度的计算公式为:
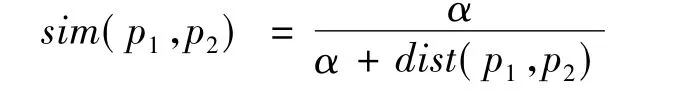
其中:α是正的可变参数;dist(p1,p2)表示义原树中的距离。
对于两个关键词W1、W2,它们的语义相似度通常基于其在义原树中的距离来计算其相似度。假设W1包含有n个义原x1、x2、…,xn,W2包含有m个义原y1、y2、…、yn,则W1、W2之间的语义相似度为其最大义原相似度,计算公式如下:
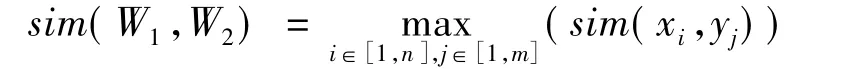
2.3 词语倾向性计算
对于任意一个词语,可以根据该词语情感词典中种子词的距离得到其倾向性度量值。其计算原理是将词语W与正面情感词典中的每个种子词进行比较计算得到其正面值,再将W与负面情感词典中的每个种子词进行比较计算出其负面值,再取其平均值之差,得到该词语的倾向性度量值。其计算公式为
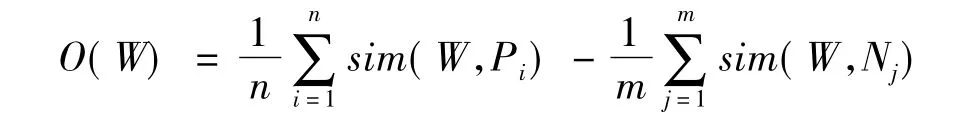
其中:n和m分别表示正面词典与负面词典中种子词的个数;Pi和Ni分别表示词典中的某一种子词。
如果计算结果大于0,则表示该词为正面词汇,反之,则表示该词为负面词汇。其数值的大小代表了该词的情感强度。
词语的情感强度不仅仅取决于词语本身的倾向性度量值,更重要的是该词语前面的程度副词和否定副词。例如,“肤浅”的倾向性度量值为-0.67,如果程度副词为“非常”,其强度就大大增强了,同理,如果在其前面加上否定副词变为“不肤浅”,其意义则会发生了根本性的变化。本文提取每个关键词前面的一个或两个副词,结合上述的赋值表给出新的词语倾向性计算公式:
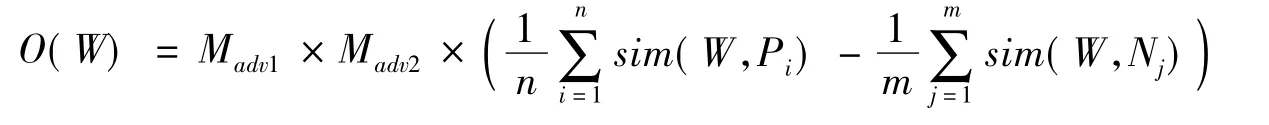
式中Madv1和Madv2分别表示两个副词的强度值。如果在关键词的前方遇到否定副词,则直接将其强度值定义为-1。
2.4 语句及篇章的文本倾向性计算
否定副词在文本倾向性计算中是不可或缺的重要因素之一,它直接改变文本的倾向性。如上述的“不喜欢”和“喜欢”具有截然相反的倾向性。
根据已建立的情感词典、程度副词词典和否定副词词典,能够快速地计算出词语的倾向性,据此可以得出语句和篇章的文本倾向性度量。将一篇文章分割为若干段落(Paragraph),将段落分割为若干语句(Sentence),将语句分割为若干关键词(Word),如果该关键词前方出现一个或两个副词,则一并提取,作为该情感关键词的度量因素之一。根据累加原则,语句级的倾向性计算公式为:
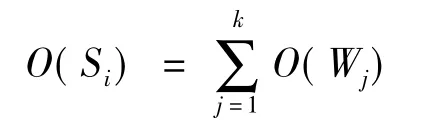
式中Wj表示构成语句Si的关键词。语句的倾向性度量值同词语倾向性度量值一样,正值表示正面情感,负值表示负面情感。
一个段落有若干语句构成,则段落级的倾向性计算公式为:
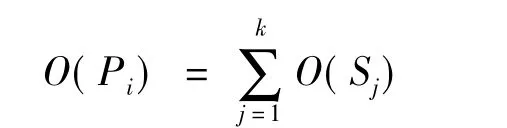
同理,篇章的倾向性计算公式为:
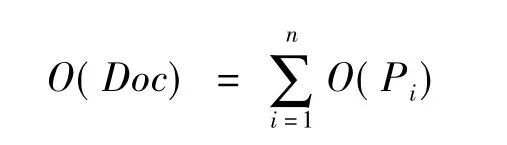
3 实验与结果分析
实验语料是从互联网上随机采集的部分网络购物的用户评价,共计683篇,并进行了人工情感分类,其中正面评价479篇,负面评价204篇。为了验证情感计算方法的有效性,本文使用查全率和查准率作为评价依据。由于文档的倾向性不只是正面和负面两种,还存在某些文档不具有褒贬性,因此需要设定一定的区间阀值对中性情感文档进行分类。经过试验发现,中性情感区间设置的越大,系统查全率越低,查准率越高。经过多次反复试验,本文认为将中性情感的区间阀值设置在[-0.6,+0.6]较为合理,作为中性文档,小于-0.6的作为负面文档,大于+0.6的作为正面文档。实验结果如表4所示。
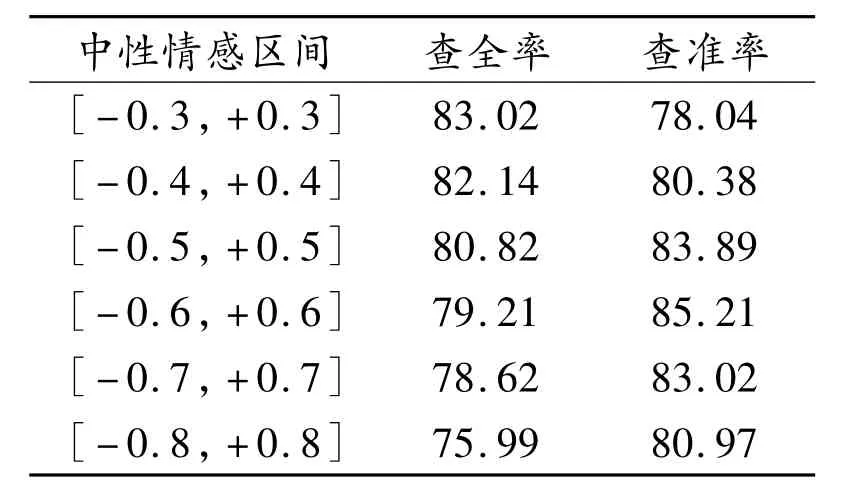
表4 实验结果%
4 实验与结果分析
本文提出了一种基于知网的情感计算方法。该方法能够基于知网构建情感词典,并依据词汇的情感程度进行加权计算其情感倾向。在设定一个合理阀值后,能较好的计算出词汇和篇章的情感倾向,有较高的查全率和查准率。下一步的工作集中在优化情感词典的构成,进一步细分情感词汇本身的倾向程度。
[1] Turney P D,Littman M L.Measuring Praise and Criticism:Inference of Semantic Orientation from Association[J].ACM Transactions on Information Systems,2003,21(4):315-346.
[2] Nasukawa T,Yi J.Sentiment analysis:Capturing favorability using natural language processing[C]//Proceedings of the 2nd International Conference on Knowledge Capture(K-CAP).New York:ACM,2003:70-77.
[3] 董振东.知网[CP/OL].[2012-03-24].http://www.keenage.com.
[4] 刘群,李建素.基于知网的词汇语义相似度计算[C]//第三届汉语慈湖语义学研讨会.台北,2002.
