基于角色及语义相似性的语义Web服务发现
2012-01-09李伟黄颖
李伟,黄颖
(1.江西理工大学信息工程学院,江西赣州341000;2.赣南师范学院数学与计算机科学学院,江西赣州341000;3.武汉大学软件工程国家重点实验室,武汉430072)
基于角色及语义相似性的语义Web服务发现
李伟1,黄颖2,3
(1.江西理工大学信息工程学院,江西赣州341000;2.赣南师范学院数学与计算机科学学院,江西赣州341000;3.武汉大学软件工程国家重点实验室,武汉430072)
在Web服务发现过程中由于容易忽视用户角色的作用,往往导致难以发现到合适的Web服务.在传统本体语义Web服务发现的基础上,结合RGPS(Role-Goal-Process-Service)元模型框架,文中提出了将用户的角色加入服务发现本体中,使用KM算法计算采用二分图最优匹配获得的词汇语义间的相似度,同时结合使用“WordNet”进一步计算词汇语义的相似性,进而提高查找的准确率,最终找到能够满足不同用户需求的语义Web服务.实验结果表明服务发现方法在查准率和查全率方面相比传统基于关键词的方法有一定的改善.
语义相似性;Web服务发现;角色
0 引言
Web服务带来了异构领域间交流的变革,故而在不同方面的协作很重要.但不断增长的Web服务也带来新的挑战,例如Web服务发现.如何在浩瀚的Web服务中找寻所需的服务已成为一个亟待解决的问题[1].目前服务发现主要分为两种,一种是基于语法的服务发现,其中UDDI(Universal Dscription Discovery and Integration)是众多发展和支持Web服务的解决方案中最受瞩目的一个.UDDI上的Web服务发现,是通过对UDDI上的服务注册信息进行关键词精确匹配实现的,主要是对服务ID或名称、或是服务的有限的属性值进行匹配[2].UDDI Web服务注册中心为用户带来寻找Web服务的便捷的同时,也存在着查准率和查全率不高的问题[3].
语义Web服务利用语义Web技术,使得Agent能够进行服务的自动发布、发现、选择、组合、调用执行等[4].语义Web服务使用语义Web本体对Web服务进行标识和处理,它使用本体推理工具对Web服务进行基于本体的描述,从而实现Web信息的自动处理.本体是语义Web中的重要概念,是描述语义Web中语义知识的建模手段,它形式化定义了领域内共同认可的知识,是语义Web体系中的核心[5].将语义Web中基于本体的知识标识手段来描述Web服务的语义,使计算机可以理解Web服务,就可克服当前Web服务中存在的问题,从而支持服务的自动发现,提高Web服务的查询效率.文献[6]提出用OWL-S语言描述服务,通过计算服务的属性和接口的输入输出概念匹配程度得到服务匹配结果.Hau J[7]通过计算两个OWL对象的相似度来得到两个服务描述之间的语义相似性,Wang Y Q[8]提出了一种基于WSDL的语义服务匹配算法,该算法利用WSDL描述中的标识符的语义以及WSDL中操作、消息及数据来计算两个WSDL文件的相似性.佐治亚大学的LADIS实验室针对多本体环境下的服务发现提出了一种基于语义的服务发现算法[9].但是上述方法都忽视了用户角色在服务发现过程中的重要性.
文中结合RGPS元模型框架,提出将用户的角色加入服务发现本体OWL-S中,使用KM算法计算采用二分图最优匹配获得的词汇语义间的相似度,同时结合使用“WordNet”进一步计算词汇语义相似度,从而发现所需的服务.
1 相关研究
1.1 语义相似度计算
词汇语义相似度在文献[4][10]中曾提及,吴建等人针对“WordNet”和“HowNet”的组织结构特点提出两个词汇语义相似度算法[10].
“WordNet”中词汇语义相似度的计算词汇语义相似度:

在式(1)中l1,l2是o1,o2分别所处的层次,a是相似度为0.5时o1,o2之间的距离,a 是一个可调节的参数,a〉0.
“WordNet”中在词语的距离越大,其相似度越低.在考虑节点间的路径长度的同时还应该考虑词语所处节点的深度和该深度上节点密度对相似度计算的影响.同样距离的两个词语,词语相似度随着其所处层次的总和的增加而增加,随着层次差的增加而减小.
有研究者采用向量空间理论基于语义词典对词语的相似度进行定量研究.明尼苏达大学的Siddharth Patwardhan和Ted Pedersen于2006年提出了一种基于WordNet情境向量来计算单词相关度计算方法GlossVector[11].该方法引入了GlossVector的概念,将每个单词都映射到向量空间中去.单词w的Gloss Vector被定义为该单词解释E中所有有效单词的一阶上下文向量的叠加.图1给出了单词fork的Gloss Vector计算过程.在Wordnet中,fork的解释为“cutlery used to serve and eat food”,其中有效单词为cutlery,serve,eat,food,故该单词的Gloss Vector即为上述各单词相似度的叠加.而后,通过计算两个单词对应的Gloss Vector夹角的余弦值来确定单词之间的相似度.实验表明,使用该方法计算得到的相似度与人工计算的相似度之间的相关系数可达到0.9,远远高出其他相似度计算方法.

图1 一阶Context Vectors和Gloss Vector
1.2 RGPS元模型框架
武汉大学软件工程国家重点实验室(SKLSE)提出了RGPS需求元建模框架,用来指导将混乱无序的需求信息整理成协同有序的结构化需求规格.RGPS需求元建模框架包括角色-目标-过程-服务(Role-Goal-Process-Service)四层[12].通过这四个层次之间的关联,该框架能够为需求模型的互操作提供有力的支持.在RGPS需求元建模框架的基础上,业务开发者能够从不同的角度、在不同的层次、以不同的粒度对用户需求进行描述和刻画.因此,RGPS需求元建模框架可以更好的促进人网协同,利用网络资源之间的交互与协同来满足用户的个性化多样化的需求.
其中角色层的分析在整个RGPS元建模框架中占据了重要的基础性地位.由于角色体现了与用户所处的组织相关的信息,这些信息对于保证需求的完备性和一致性起到了至关重要的作用.在用户提出需求时,首先要明确这个用户所扮演的角色,然后就可以根据他的角色,推理出某些用户尚未提出的、同时又是这类角色公共的角色目标以便完善用户的需求[13].
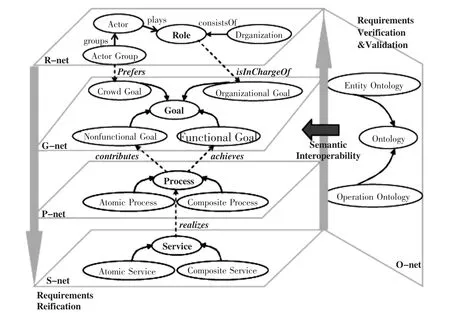
图2 O-RGPS模型框架
2 基于词汇语义相似度的Web服务发现
2.1 语义相似度的计算
文中1.1节介绍了基于词汇语义相似度的计算,文献[10]将配对计算相似度并求相似度和的最大值的问题,等同于组合优化问题中的指派问题(assignment problem),并采用匈牙利算法计算,其时间复杂度为O(n3).但是匈牙利算法仅是考虑了最大匹配问题,文中使用OWL-S本体中,根据其在“WordNet”中词种匹配的情况给予本体不同的权值,故文中采用二分图最优匹配来计算词汇语义间的相似度.
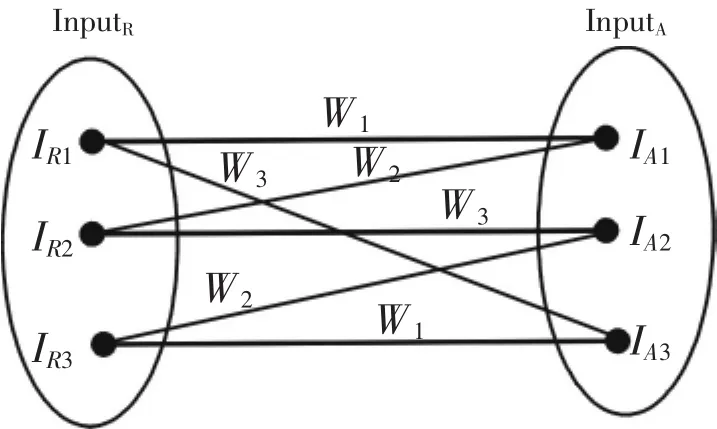
图3 输入语义匹配二分图
二分图最优匹配的经典算法是由Kuhn和Munkres分别在1955年和1975年独立提出的KM算法,匈牙利算法被Edmonds提出之后,原有的KM算法利用匈牙利树得到了更好的实现.
KM算法中的基本概念是可行顶标(feasible vertex labeling),它是节点的实函数并且对于任意弧(x,y)满足l(x)+l(y)≥w(x,y),此外一个概念是相等子图,它是G的一个生成子图,但是只包含满足l(xi)+l(yi)=w(xi,yj)的所有弧(xi,yj).
它的依据是如果相等子图有完美匹配,那么该匹配是最大权匹配.KM算法主要就是控制了怎样修改可行顶标的策略使得最终可以达到一个完美匹配,首先任意设置可行顶标(如每个X节点的可行顶标设为它出发的所有弧的最大权,Y节点的可行顶标设为0,然后在相等子图中寻找增广路,找到增广路就沿着增广路增广.如果没有找到增广路,就考虑所有现在在匈牙利树中的X节点(记为S集合),所有现在在匈牙利树中的Y节点(记为T集合),考察所有一段在S集合,一段不在T集合中的弧,取:

显然在公式(2)中当把所有S集合中的l(xi)减少delta之后,一定会有至少一条属于(S,T)的边进入相等子图,进而可以继续扩展匈牙利树,为了保证原来属于(S,T)的边不退出相等子图,把所有在T集合中的点的可行顶标增加delta.随后匈牙利树继续扩展,如果新加入匈牙利树的Y节点是未盖点,那么找到增广路,否则把该节点的对应的X匹配点加入匈牙利树继续尝试增广.
复杂度分析:在不扩大匹配的情况下每次匈牙利树做上述调整之后至少增加一个元素,因此最多执行n次就可以找到一条增广路,最多需要找n条增广路,故最多执行n2次修改顶标的操作,而每次修改顶标需要扫描所有弧,这样修改顶标的复杂度就是O(n2),总的复杂度是O(n4).但是这个界通常情况下达不到.
依据在“WordNet”中权值分配的原则,利用KM算法查找最大权值匹配,算法如下:
step1:初始化可行顶标的值.
step2:获取每个节点的最大权值.
step3:寻找、修改并返回可增广路.
step4:搜索下一节点,计算匹配数.
step5:构造二部图,设置初始匹配.
step6:根据标记数组把最后一次寻找可增广时未扩展的节点加到已扩展节点的末尾,计算修改可标记结点价值的最小值.修改可标记节点值,继而修改二分图.
step7:若未找到完备匹配则修改可行顶标的值.
step8:重复步骤(2)、(3)直到找到相等子图的完备匹配为止.
实施KM算法后原来的二分图可以得到良好的匹配效果,如图4所示.

图4 输入语义匹配子二分图
2.2 用户角色的添加
OWL-S服务本体增强了对Web服务语义的描述能力,但由于在对Web服务进行表征建模时,OWL-S仅仅考虑对Web服务本身的描述,忽略了Web服务描述与用户需求之间的对应关系.根据RGPS需求元建模框架,用户的需求实现可以划分到角色、目标、过程和服务四个层面,而OWL-S服务本体所描述的内容仅能够与过程层和服务层的需求描述对应,无法与角色层和目标层需求描述相对应.为了克服上述缺点,解决其服务描述与用户需求脱节的问题,文中引入RGPS框架用于指导Web服务本体的构建,使Web服务本体能够对服务对应角色、服务的功能属性和非功能属性进行描述,实现Web描述与用户需求描述的对应,让业务开发者很容易根据用户需求发现需要的Web服务,提高开发者的工作效率.
为了增加角色描述信息在OWL-S本体中增加了角色类Role及其数据属性RoleName;而后,增加了Profile类的一个对象属性hasRole,其定义域为Profile类,值域为Role类,用于指定Profile所对应的角色类.
在服务发现过程中,服务的选择与用户的角色之间存在密切的关系,对于众多角色选择的服务可以考虑给予OWL-S本体更高的权值.
3 实验
3.1 实验环境
软件环境:Win7系统,MyEclipse8.5,OWLSAPI,Xampp,PelletReasoner.
硬件环境:CPU为4核Intel Corei5 2.8GHz,内存为1TB.
数据来源:OWL-TC,该测试集包括service、queries、ontology、domain、wsdl数据集;WordNet 2.1.
说明:Pellet Reasoner可以对OWL中定义的概念之间的subclassof等关系进行推理计算.OWL-S API用来处理具体的OWL-S文件内容.OWL-TC中Ontology数据集存储了服务中所用到的本体服务,请求信息.Xampp是一个本地Apache HTTP Web服务器,使数据可以在本地进行测试.
3.2 实验结果及分析
Web服务匹配是通过度量所需服务和众多候选服务间的相似程度,选择与所需服务最为相似的一个或多个服务的过程.其中计算所需服务和候选服务间的相似程度是关键.2010年东南大学已经完成了“WordNet”对中文词汇数据库的建设,故而“WordNet”已基本能进行中文词汇的相似性判定,从而查找用户最终所需要的服务.
文中针对服务语义匹配的查准率和查全率进行对比试验,查准率是指查询返回符合查询条件的Web服务数量与查询返回Web服务总数量的比率,查全率是指查询返回符合查询条件的Web服务与测试样本集中符合查询条件的Web服务的比率.

图5 查准率比较图
文中针对基于语义及用户角色的方法记为SDSR、基于语义的方法记为SDS以及基于关键字的方法记为SDKW进行对比实验.主要采用OWL-TC中domains,queries与services三个数据集,对下面8个领域的数据进行实验:communication,economy,education,food,travel,geography,weapon,simulation.每个数据集中服务个数不等,取queries数据集中的服务需求与相应领域服务集中的服务进行匹配.
经过仿真性能测试,发现基于关键词的Web服务发现方法,和文中中提到的两种基于词汇语义相似度的Web服务发现方法的平均查准率为44.7%、70.8%、77.5%,平均查全率为65.6%、91.4%、93.5%.具体测试结果如图5、图6所示.其中,SDS是基于“WordNet”计算词汇语义相似度,RDSR在上述方法的基础上添加了用户角色.在上述两种基于词汇语义相似度的服务发现方法中,设相似度阈值为40%,即查询结果仅返回与查询条件相似度在40%以上的服务.阈值是一个经验值,可以在不同情况下进行调整.

图6 查全率比较图
由实验结果图5、图6可得,基于关键词的服务发现方法查准率和查全率都比较低.基于词汇语义相似度的两种服务发现方法查准率达70%以上,查全率达90%以上,与基于关键词的服务发现方法相比性能有较大提升.
4 结语
文中介绍了基于语义相似度和基于角色及语义的服务发现匹配算法.传统的基于WSDL的服务描述语言缺乏对服务的语义描述,文中用语义本体来描述服务以解决该问题,结合“WordNet”以提高匹配准确度,之后添加用户角色,进一步提高服务发现的准确率.文中提出的算法在查准率和查全率上要优于现有UDDI上的基于关键字的服务发现机制.下一步研究还将提供更加详细的服务匹配信息以提高服务匹配的精确度以及研究在语义匹配的基础上进行服务的自动组合和执行等.
[1]岳昆,王晓玲,周傲英.Web服务核心支撑技术研究综述[J].软件学报,2004,15(3):428-442.
[2]喻坚,韩燕波.面向服务的计算——原理和应用[M].北京:清华大学出版社,2006:204-228.
[3]UDDI org.Universal description,discovery,andintegration of businesses for the web[EB/OL].http://www.uddi.org/,2004-10-01.
[4]吴开贵,万红波,朱郑州.一种基于语义的本体概念相似度的计算方法[J].计算机科学,2008,35(5):123-125.
[5]王慧,胡健.一种新的语义Web服务描述模型[J].江西理工大学学报,2010,31(5):57-59.
[6]Meditskos G,Bassiliades N.Structural and role-oriented web service discovery with taxonomies in owl-s[J].IEEE Transactions on Knowledge and Data Engineering,2010.22(2):278-290.
[7]Hau J,Lee W,Darlington J.A semantic similarity measure for semantic web services[C].Web Service Semantics Workshop at WWW2005,2005.
[8]Wang Y Q,E Stroulia.Semantic structure matching f or assessing web service similarity[J].Lecture Notes in Computer Science,2003 2910:194-207.
[9]Ound hak ar S.Semantic web service discovery in a multi-ontology environment[D].Athens:The University of Georgia,2004.
[10]吴健,吴朝晖,李莹,等.基于本体论和词汇语义相似度的Web服务发现[J].计算机学报,2005,28(4):595-602.
[11]Patwardhan S,Pedersen T.Using WordNet based context vectors to estimate the semantic relatedness of concepts[C].Proceedings of the EACL 2006 Workshop Making Sense of Sense-Bringing ComputationalLinguisticsandPsycholinguisticsTogether,2006:1-8
[12]何克清,何杨帆,王翀,等.本体元建模理论与方法及其应用[M].北京:科学出版社,2008:26-34.
[13]Wang J,He K Q,He Y F,et al.Towards service-oriented semantic interoperability based on connecting anthologies[C].2009 International Conference on Interoperability for Enterprise Software and Applications,2009:28-33.
Web service discovery based on semantic similarity and role
LI Wei1,HUANG Ying2,3
(1.Faculty of Information Engineering,Jiangxi University of Science and Technology,Ganzhou 341000,China;2.Faculty of Mathematics and Computer,Gannan Normal University,Ganzhou 341000,China;3.State Key Laboratory of Software Engineering,Wuhan University,Wuhan 430072,China;)
It′s hard to find the fittest Web Service because of neglecting the role of users in the course of Web service discovery.On the basis of traditional ontology semantic Web service discovery,combining with RGPS meta model framework,the role of users is added into the ontology of OWL-S,and KM algorithm is taken to calculate the semantic similarity of vocabularies by bipartite graph optimal match."WordNet"is utilized to further improve the semantic similarities of vocabularies and the search accuracy so that the Web services can meet the needs of different users.Experiments show that the proposed method can achieve better results than traditional keywords method in precision ratio and recall ratio.
semantic similarity;Web service discovery;role
TP391
A
2012-05-25
江西省教育厅科技资助项目(GJJ12368,GJJ11216)
李伟(1980-),男,讲师,主要从事智能计算和数据挖掘等方面的研究,E-mail:nhwslw@gmail.com.
2095-3046(2012)05-0060-06
