基于关联规则的数据挖掘技术在中医诊断中的应用
2011-11-24欧凤霞王宗殿
欧凤霞, 王宗殿
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.安徽中医学院 医药信息工程学院,安徽 合肥 230038)
1 数据挖掘在中医诊断中的作用
中医是中国的传统医学,几千年来为中华民族的繁衍做出了重要贡献,但现代中医的发展也面临着诸多挑战.中医学说在理论和临床上自成体系,一病多治,重复性较差,这给中医治疗的应用、传承和发展造成了很大困难.灿烂悠久的中医文化荟萃了众多中医名家的学术和临床医学资源,利用现代数据挖掘技术探讨中医诊断与治疗的规律,对推动中医文化的学术研究和现代中医的发展有重要作用.
数据挖掘是从数据库或数据仓库中发现隐藏的、未知的和有用的信息的过程.近年来,从不断膨胀的医院数据库提取有用信息为疾病的诊断和治疗提供科学的决策,已成为人们关注的焦点.本研究的基本思路是在收集众多治疗典型病例的医案的基础上,从不完整甚至不一致的数据中,利用数据挖掘技术,挖掘出典型病例的用药规律.
2 数据挖掘前中医诊断信息的预处理
中医诊断主要依靠望、闻、问、切四诊收集脉象、舌像、神色形态、症状等的机体反应来诊察疾病,“辨证论治”是中医的基本特征之一[1].在中医的临床诊疗过程中,患者所表现的各种症状和体征,是辨证的依据,称为“证候”;通过对证候的辨识而确定的病理本质,称为“证素”;由病位、病性证素所构成的诊断名称,称为“证名”.证候、证素和证名,共同组成了“证素辨证体系”[2].证素辨证研究的核心问题是证素的确认,即通过临床收集到的信息寻找构成证的基本元素.如果一组症状群呈现稳定的相互关系,就可以确定病位与病性的最小单位.准确地判断证素,便抓住了疾病当前的病理本质.
临床上收集的四诊资料存在不完整性、含噪声和不一致性等特点,不能直接用于数据挖掘.在进行数据挖掘之前,必须对中医临床上的数据进行规范化的预处理,图1是中医临床数据规范化预处理的流程图.
3 基于关联规则数据挖掘技术的应用
数据挖掘的方法有关联规则、序列模式、神经网络、分类规则和聚类分析等,采用不同的技术可以发现不同类型的知识.本文主要介绍关联规则技术在肝病中医诊断上的应用,找出肝病的症状与处方、症状与辨证、辨证与处方之间的关联规则.

图1 病历数据预处理流程Fig.1 Medical record data pretreatment flowchart
3.1 关联规则的概念[3]
设D是事务数据库,I=(i1,i2,…,im)是所有项目的集合,其中Ij,j=1,…,m是一个项目.每个事务Ti是一个项集,Ti⊆I.
定义1 设A,B为项集,则称A→B为规则,其中A⊂I,B⊂I,且A∩B=φ.
定义2 设D是事务集,A,B为项集,且有规则A→B.如果D中包含A∪B事务的比例为s%,称A→B有支持度s%,即概率P(A∪B).
定义3 设D是事务集,A,B为项集,且有规则A→B.若D中,c%的事务包含A的同时也包含B,则称A→B有置信度,即条件概率P(B|A).
定义4 设D是事务集,A,B为项集,若A→B满足最小置信度c和最小支持度s,则称A→B为关联规则.
Support(A→B)=P(A∪B)
Confidence(A→B)=P(B|A)
关联规则的挖掘过程主要包含2个阶段:第一阶段必须先从原始资料集合中找出所有的高频项目组(Frequent Itemsets),第二阶段再由这些高频项目组中产生关联规则(Association Rules).
3.2 关联规则在肝病中医诊断中的具体应用途径
本文的数据来源为临床和文献[6],共1 128例肝病病例.这里所采用的每个病例数据都包含了症状、辨证、治法和处方等若干方面的信息,部分数据如下:
(1)某女,20岁
症状:纳差,恶心,厌油,口不苦,微渴喜热饮,乏力,大便色黄,日行1~2次,尿黄而自利,皮肤瘙痒,有搔抓痕;舌质暗,苔薄黄,舌下脉络增粗延长,脉弦细.
辨证:湿热血虚型.
治法:清热利湿活血.
处方:茵陈15 g,丹参15 g,丹皮15 g,杏仁15 g,赤芍60 g,葛根30 g,瓜蒌30 g,生大黄9 g,半夏15 g,川芎15 g,栀子12 g,黄苓15 g.
(2)某男,32岁
症状: 频繁恶心,但无呕吐;胸闷明显,胸脘胀满,纳差,口黏;大便不爽,小便色黄不利,胃脘部有振水声;舌质红,苔薄黄,脉弦.
辨证: 湿邪弥散三焦(黄疸).
治法:宣畅三焦.
处方:杏仁15 g,蔻仁15 g,生薏苡仁30 g,黄芩15 g,赤芍90 g,葛根30 g,滑石30 g,茵陈15 g,半夏15 g,川朴15 g,木通15 g.
…………
从以上原始病例可以看出,症状、辨证、治法和处方都是一些中医习惯用语,没有一个统一的标准.因此,在进行研究之前,必须编制一些程序对这些病历中的症状术语、症状之间的逻辑关系、辨证、治法和方药等做规范预处理.通过相关中医书籍对所有的症状作了统计和归类,得到了用于挖掘实验的症状描述,把每个症状用数字来表示.例如:1001代表纳差,1002代表恶心……1025代表脉弦,1026代表肝掌……
辨证论治是中医认识疾病和治疗疾病的基本原则.辨证是决定治疗的前提和依据,论治是治疗疾病的手段和方法.为了便于挖掘,把每种辨证也用数字来表示.例如: 2001代表湿热血瘀型,2002代表血瘀血热型……2030代表营卫不和证,2031代表脾虚血瘀证……
药名的预处理相对比较简单,可以根据中药库的国家标准命名来对药名进行预处理.例如:3001代表莱菔子,3002代表姜半夏……3079代表茵陈,3080代表桂枝……
经过预处理的病例数据主要是用数字来表示的,并且包含了症状、辨证、治法、处方这四维数据.
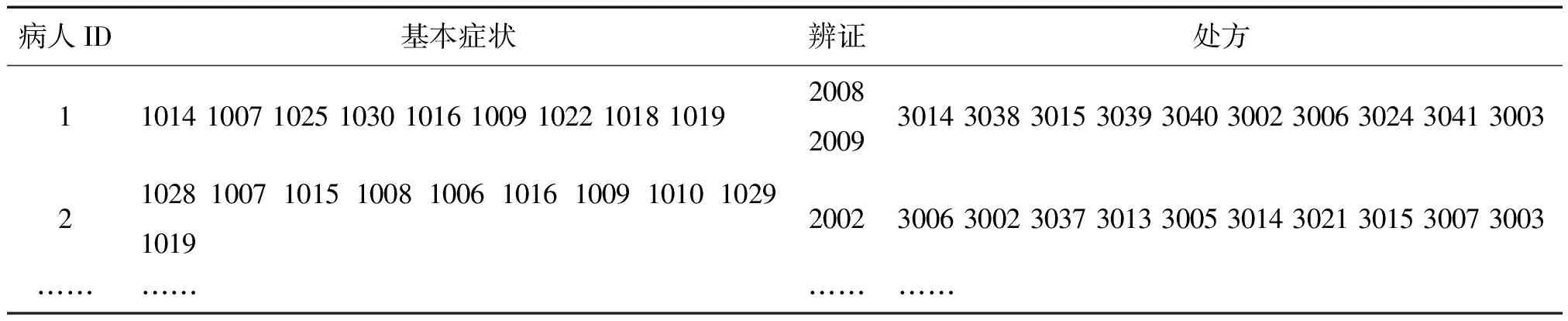
表1 病人基本的数据格式Tab.1 Patient basic data formats
根据表1所示的数据格式和内容,这里需要挖掘症状与辨证、症状与处方、辨证与处方的制约关系的数据,即:
(1)基本症状和辨证之间的关联规则:基本症状(x,Ai)→辨证(x,Bj);
(2)基本症状和处方之间的关联规则:基本症状(x,Ai)→处方(x,Dj);
(3)辨证和处方之间的关联规则:辨证(x,Bj)→处方(X,Dj).
这是一个二维关联规则挖掘模型,如果要得到症状与辨证、症状与处方、辨证与处方之间的关联规则,可以将模型降为一维,再运用关联规则算法来挖掘这一维新的数据,筛选挖掘结果,去掉不符合规则的,留下合适的规则,从而挖掘出症状与辨证、症状与处方、辨证与处方之间的关联规则.

表2 病人的事务数据库Tab.2 Patients transaction database
本文采用频繁模式增长(frequent-Pattern growth)的关联算法,简称FP-增长.将提供频繁项集的数据库压缩成一棵频繁模式树(FP-tree),保留项集关联信息;然后,将这种压缩后的数据库分成一组条件数据库,每个数据库关联一个频繁项,并分别挖掘每个数据库.
下面给出一个简单的例子说明基本的挖掘过程.表2是需要挖掘的事务数据库.
假设现在要挖掘基本症状和处方之间的关联规则,即基本症状(x,Ai) →处方(x,Dj),则需要将“基本症状”和“处方”这2项数据合并为一个新的维,设为x,合并后的病人数据如表3所示.

表3 合并后的病人数据Tab.3 Data after the merger of patient
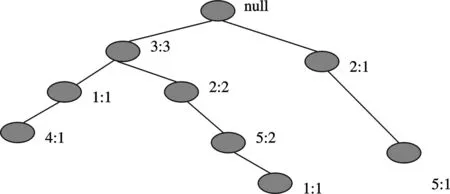
图2 FP-树挖掘结果Fig.2 FP-trees mining results
取最小支持度为2、最小置信度为60%,运用关联规则得到的挖掘结果见图2.具体步骤如下:
(1) 扫描合并后的病人事务数据库,收集频繁项集和它们的支持度.按支持度降序排序,得到频繁项表L=[3∶3,2∶3,5∶3,1∶2,4∶1].
(2)创建FP-树.事务数据库中的第一条事务{1,3,4},按照L中的排序为{3,1,4},则先建立null结点,然后依次有结点3、1、4,并把计数都置为l;第二条事务{2,3,5},按照L中的排序为{3,2,5},则把“3”结点的计数增加到2,在“3”分支下建立结点2和5;其余依次类推,就可以得到图2所示的FP-tree.
然后,对这个FP-tree进行挖掘,对L中的项进行倒序考虑:
(1)先考虑“4”,它的路径由分支<3,1,4∶1>形成,考虑“4”为后缀,它的对应前缀路径是<3,1>,但支持记数为1,小于设定的min-sup(2),所以该路径不能产生频繁模式.
(2)再考虑“1”,它的路径由分支<3,2,5,1∶1>和<3,1∶1>形成,考虑“l”为后缀,并考虑最小支持度为2,则这2个路径均不能产生频繁模式.
(3)再考虑“5”,它的路径由分支<3,2,5∶2>和<2,5∶l>形成,考虑“5”为后缀,并考虑最小支持度为2,则它的对应前缀路径只能是<3,2∶2>,则该路径产生的频繁模式为<3,2,5∶2>.
(4)再考虑“2”,它的路径由分支<3,2∶2>形成,考虑“2”为后缀,并考虑最小支持度为2,则它的对应前缀路径是<3,2>,则该路径产生的频繁模式为<3,2∶2>.
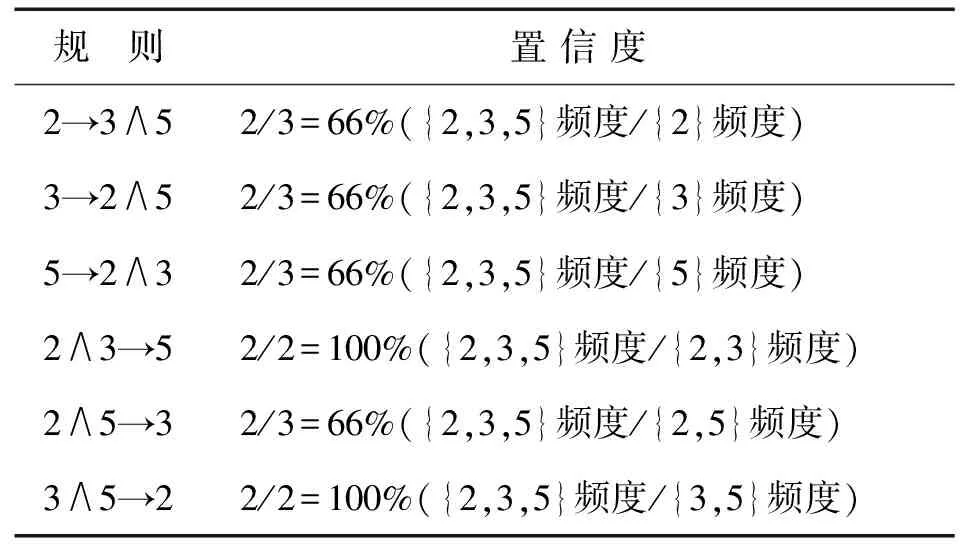
表4 关联规则及其置信度Tab.4 Association rules and confidence
挖掘过程到此结束,发现频繁模式<3,2,5∶2>和<3,2∶2>,但2和3表示基本症状,5表示处方,则上述的2个频繁模式只有<3,2,5∶2>符合要求,即挖掘基本症状和处方之间的关联规则.因此,这个例子能得到一个频繁集{2,3,5},非空真子集有{2},{3},{5},{2,3},{2,5},{3,5},从而得到的关联规则及其置信度见表4.
本例中1、2、3表示基本症状,4、5表示药名,需要对上面的规则进行筛选,保留含有这两维数据并且是由基本症状推出药名或由药名推出基本症状的规则,最后得到2个规则见表5.

表5 筛选后得到的关联规则及其置信度Tab.5 Association rules and confidence after filtering
表5中“5→2∧3”表示5这种药有66%的可能性是用来治疗2,3这2种病状的;“2∧3→5”则表示2和3这2种病状通常是用5这种药来治的.
这就是该模型的基本思想,其他几维数据间的关联规则也可以类似挖掘.
3.2.1 基本症状和处方的关联规则
挖掘基本症状和处方之间的关联规则,就是想得知哪些基本症状的组合一般是由哪些药的组合来治疗的.取最小支持度频数为5、最小置信度为80%,得到表6中的一系列结果.

表6 基本症状和处方Tab.6 Basic symptoms and the prescription
从(1004,1006,1050,1002)→3079规则的置信度是100%,表明“皮肤黄”、“舌苔黄腻”、“尿黄”、“恶心”这4种症状同时出现的时候,必须要用茵陈这种药.查阅中医药知识可以知道,黄疸就有“皮肤黄”、“舌苔黄腻”、“小便黄”、“恶心”这4种症状.黄疸是由于血清中的胆红素升高所致,茵陈具有明显的保肝利胆的作用,能够促进胆汁分泌,促进胆酸和胆红素排出,这说明这个关联规则是符合中医传统知识的.

表7 辨证和基本症状Tab.7 Differentiation and basic symptoms
3.2.2 基本症状和辨证之间的关联规则
挖掘基本症状和辨证之间的关联规则,就是想知道哪些症状的组合是何种辨证.取最小支持度频数为3、最小置信度为60%,得到的结果见表7.
从2018→(1001,1007,1049,1002),这条规则的置信度是100%,表示“脾虚湿困”这个辨证一般会有“纳差”、“舌苔腻”、“大便溏泻”、“恶心”这4种症状.中医认为脾主运化水湿,脾虚则运化功能低下,引起水湿停滞;水湿的停滞,反过来又影响脾的运化,故饮食减少、胃脘满闷、大便溏泻,舌苔厚腻等.由此可见,这个关联规则是符合中医传统知识的.
3.2.3 辨证和处方之间的关联规则
挖掘中医中辨证和处方之间的关联规则可以得到对病因的用药方法.取最小支持度频数为5、最小置信度为80%,得到的结果见表8.

表8 辨证和处方Tab.8 Differentiation and prescription
关联规则(3078,3087,3098,3013,3012)→2010的置信度为100%,表示白芍、橘皮、茯苓、木香和川楝子的组合可以用来治疗“脾气虚证”.根据传统的中医疗法,脾气虚证要用温中健脾的方剂来治疗,一般选用香砂六君子汤和黄芪建中汤加减.前方中,党参、茯苓、白术、炙甘草为四君子汤健脾,橘皮、木香、砂仁和胃降逆;后方中,黄芪益气补中,白芍、桂枝、炙甘草、生姜、大枣、怡糖为小建中汤.由上面的传统经典用药可以知道,该规则的前4种药都是治疗脾气虚证的必要中药,但是川楝子却不是经典的治疗脾气虚证的药.查阅中医药的书籍可知,川楝子是一种行气止痛、行气疏肝的中药,一般可以用于治疗胃脘痛和胁痛.但是,它也可以治疗胃脘部饱胀、满闷不舒的症状,而胃脘部饱胀又是脾气虚证的一个非常重要的特征.因此,对中医的用药挖掘是非常正确和有意义的.
4 结束语
正确的诊断对于确立治疗原则、指导用药以及调理康复无疑是非常重要的,用关联规则挖掘出的“理—法—方—药”之间的关联规则是中国中医药学的宝贵经验,它促进了中医诊断学的规范化研究,也为中医的现代化注入了新的活力.
参考文献:
[1] 朱文峰.中医诊断学[M].北京:中国中医药出版社,2000.
[2] 朱文锋.证素辨证学[M].北京:人民卫生出版社,2008.
[3] Jiawei H, Micheline K. Data Mining: Concepts and Techniques[M]. San Fransisco:Morgan Kaufman Puclishers, 2001.
[4] 谢邦昌.数据挖掘Clementine应用实务[M].北京:机械工业出版社,2008.
[5] 薛飞飞,陈家旭.数据挖掘在中医诊断学中的应用[J].中医杂志,2009,50(3):200-202.
[6] 中国中医药管理局中医肝病重点专科协作组.中医肝病病案例选[M].上海:上海科技教育出版社,2006.
