利用DSP底层结构提高MPEG-4编码的实时性
2011-11-06李桂菊
李桂菊
(中国科学院长春光学精密机械与物理研究所,吉林长春130033)
1 引言
美国TI公司推出的TMS320C6000系列数字信号处理器在运算单元、总线结构,片内存储器结构和流水处理等方面都有其独特之处。该系列主要包括 62XX、64XX和 67XX 3大类,其中的64XX基于特殊的硬件结构和高速处理能力,在通信、精确制导武器和数字图像处理等需要高速运算的应用领域具有强大的优势,已成为实时图像处理系统的首选器件[1~6]。
DSP硬件结构的特殊性使其处理能力的提升不仅仅依靠越来越快的时钟速率来实现,更主要依靠开发者对数据流程的合理安排及并行处理结构的充分利用[7-11]。文献[11]在 TMS320DM642 DSP平台上实现了H264视频编码器,并对二级缓存优化做了深入探讨,但由于H264标准是以算法的复杂性换取压缩质量,所以尽管做了大量优化,还只是达到了QCIF和CIF尺寸的视频基本可以满足视频监控的要求。文献[12]提出了一种支持同时多线程的动态分发超长指令字(VLIW)数字信号处理器(DSP)架构,它虽然能提高处理器的指令吞吐率,但实现调度过于复杂。本文以MPEG-4视频序列编码标准[13]的图像压缩算法为例,论述了利用DSP底层结构提高图像处理实时性的一些方法。
2 TMS320C64XX底层结构特点
TMS320C64XX系列是面向数字信号处理的定点芯片,该芯片的内部结构是在TMS320C62XX基础上加以改进的,其性能特点如下[14]:
(1)DSP内核采用超长指令字(VLIW)体系;
(2)CPU内核有两组共8个可并行运算的单元,64个32 bit的通用寄存器;
(3)支持8/16/32/64 bit的数据类型,两个乘法累加单元一个时钟周期可同时执行4组16 bit×16 bit乘法或8组8 bit×8 bit乘法;
(4)采用两级高速缓存结构;
(5)64个通道的EDMA。
3 利用DSP底层结构提高MPEG-4编码效率
3.1 合理配置二级缓存加快处理速度
TMS320C64XX芯片采用了两级高速缓存结构。一级缓存L1cache包含了数据缓存L1D和程序缓存L1P两部分,而二级缓存L2cache则是数据、程序共用的,可以通过寄存器配置。L2全部为SRAM,作为片内存储器,也可配置其中的一部分为cache。CPU执行程序时,先访问一级缓存内的程序代码和数据,若代码或数据不在一级缓存内,再访问L2,若L2中没有所需代码,就要访问外部存储器,由于一级缓存、二级缓存和片外存储器访问速度差异很大,所以合理利用二级缓存结构,可以提高编码器的运行速度。
TMS320C64XX系列不同芯片的内存容量相差较大,采用不同芯片针对二级缓存的优化方法不同。以TMS320C6416为例,片内包括16 KB程序 cache(L1P)、16 KB数据 cache(L1D)和1 024 KB的统一程序/数据空间(L2)。
(1)针对L1的优化
由L1P的工作原理可知,L1P首先一次性读入512组连续的代码指令,CPU发出的32位取指地址被解析,以确定在L1P中的地址,然后读入该地址指令送入CPU中执行。若CPU发出的取指地址不在L1P内,就要清除L1P中的无用代码,重新从L2读入一组连续代码。若程序跳转间隔较大,或循环体内代码过长,都会降低L1P的命中率。L1P的优化就是将连续的运算过程放在一起,减少循环体内的代码长度,尽量用条件语句代替分支转移语句。例如MPEG-4每个宏块的编码过程都是DCT变换、量化、逆量化和逆DCT变换,编码时将DCT变换和量化放在一个循环体内,逆量化和逆DCT变换放在一个循环体内。这样既可以减少图像的存取次数,又可以避免循环体过长。合并后的代码会一次性映射入L1P内进行宏块运算,减少了L1P读缺失,提高了编码效率。
L1D的工作原理与L1P类似,如果CPU所需的数据不全在L1D中,就需要不断地从L2或从外部存储器读入。L1D的优化就是将当前CPU所需要读取的有用数据放在一起,而且这些数据应该按照cache line大小进行对齐,这样可以使L1D cache的使用效率达到最大。
(2)针对L2的优化
由于TMS320C6416芯片的L2可以配置为片内SRAM,也可以配置为高速缓存,针对MPEG-4编码器,由于其程序代码和所要处理的数据量都较大,不可能将所有的代码和数据都放入片内。要使程序代码在片内外之间传送而不影响程序的执行效率很难实现,而传输数据则可通过优化存储器结构而不影响CPU执行时间。所以针对L2的优化优先保障程序代码都放在片内,然后放置每个宏块编码所必需的数据,余下的空间配置为cache,按此原则,将L2在SRAM/CACHE的配置比例设为960 Kbyte/64 Kbyte。
为了能将使用频率高的代码和数据尽量留在cache中,就要将连续的运算过程或连续存取的数据放在一起,对代码结构和数据结构重新组织,这时利用段的设置来指定部分程序和数据的位置是很必要的。TI的代码产生工具生成的目标文件是以段的形式组织在一起的,这些段包括编译器自动产生的代码段(.text)、全局变量段(.bss)、堆栈段(.stack)等,用户也可以自己定义段,段的地址可由*.cmd文件指定。由于MPEG-4的初始数据表较多,如DCT系数表、可变长编码表等,可用静态数组来定义这些表格,并把这些数组以段的形式安排在固定空间,把可能连续调用的数据放在一起。
为进一步提高CACHE命中率,还应尽量减小代码尺寸,不同类型变量在DSP内部存放机制不同,char型是单字节变量,不受位置限制,short型是双字节变量,以2的整数倍为边界存放,int是4字节变量,以4的整数倍为边界存放。为此对较大数组考虑能否用short型代替int型,变量定义时应将同类型变量放在一起,以减小代码尺寸。
3.2 利用EDMA可级联特性提高CPU效率
TMS320C64XX的数据存储空间从内到外依次为CPU内部寄存器、一级缓存L1D、二级缓存L2、片外存储空间4个层次。各层次数据传递流程如图1所示。在L2与外部存储器之间数据传送由EDMA完成,而在CPU与L2之间可由CPU控制存取,而L2内部的数据传送既可由EDMA完成,也可由CPU完成。
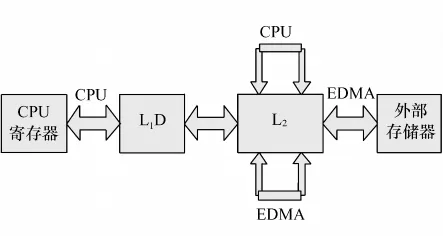
图1 DSP存储空间数据传递流程Fig.1 Flowchart of DSP data transmission between memories
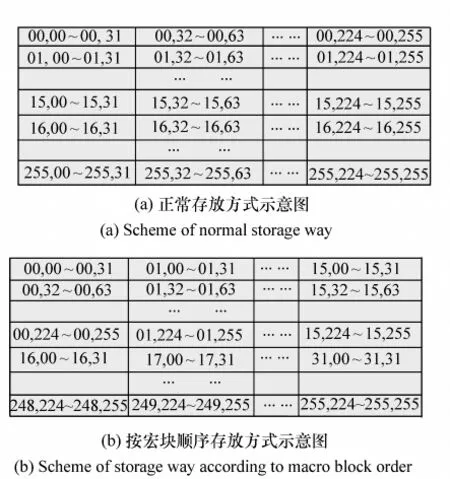
图2 256 pixel×256 pixel大小的图像存储方式示意图Fig.2 Schematic diagram of storage way for image with size of 256 pixel×256 pixel
TMS3206416D的EDMA控制器共有64个增强通道,并且可以设置不同通道的优先级。EDMA控制器用来处理片内L2SRAM和片内外设以及外部存储空间之间的数据搬移。
针对所设计的压缩平台,外接SDRAM经过FPGA挂在DSP的EMIF总线上,SDRAM的访问方式设置成FIFO形式,对给定的起始地址,一次最少存取64 bit,每次启动EDMA之后只能从给定的存储器首址顺序搬移一段数据。MPEG-4编码器以宏块为单位进行编码,每个宏块大小为16 pixel×16 pixel,这样EDMA就很难按宏块存取,为了在该硬件平台中发挥EDMA的作用,重新安排参考图像的存储结构,存放格式如图2所示,图2(a)为256 pixel×256 pixel大小的图像正常存放方式示意图,图2(b)为按宏块顺序存放示意图。存放顺序为第一个宏块的第一行,第一个宏块的第二行,…,第一个宏块的第16行,然后存第二个宏块的第一行,第二个宏块的第二行,以此类推。这样参考图像可以按宏块读入,进行宏块编码时,在片内开辟乒乓结构的双缓冲区。一个用于接收待编码的数据并输出编码后的重构图像数据,另一个用于对已接收的数据进行编码,而数据的传送采用EDMA完成。这样,可以同时完成数据编码和传输工作,有效地改善编码效率。
编码I帧时,当前图像由于不能按宏块读取,将图像分成n条,每条16行,即一个宏块的高度,每条开始时读入该条图像到内存,编码每个宏块时,用EDMA搬移一个宏块到乒乓缓冲区,一行所有宏块编码完,再读下一条16行图像。由于不需要运动估计,所以每个缓冲区只需分配当前图像和重构两个宏块区域。
编码P帧时,当前图像仍然按条读入,编码每个宏块时,用EDMA搬移一个宏块到乒乓缓冲区。设搜索范围为[-15,16],包括搜索范围在内的参考图像大小为48 pixel×48 pixel,即9个宏块。因此每个缓冲区的大小包括:48 pixel×48 pixel大小的参考图像、16 pixel×16 pixel大小的当前图像及16 pixel×16 pixel大小的重构图像。由于片内搬移比片外到片内搬移快,每个宏块编码传输启动5个读通道的EDMA:1个通道搬移运算缓冲区参考图像后32列×48行到传送缓冲区参考图像的前32列;3个通道EDMA从外部存储器参考图像区读一个宏块放到内存数据传输区后16列;另一个通道搬移当前图像宏块。每个宏块还启动一个写EDMA,将重构图像写到外部存储器中。这6个EDMA通道级联,每个宏块编码前设置一次,EDMA会将所需的图像数据导入数据传输缓存区,同时,CPU编码另一个缓冲区中的数据。由于CPU和EDMA都要访问数据缓冲区中参考图像区,设置CPU的优先级高于EDMA。宏块编码结束时两个区域指针交换,两个缓冲区交替使用来提高CPU效率。乒乓缓冲区的操作过程如图3所示。
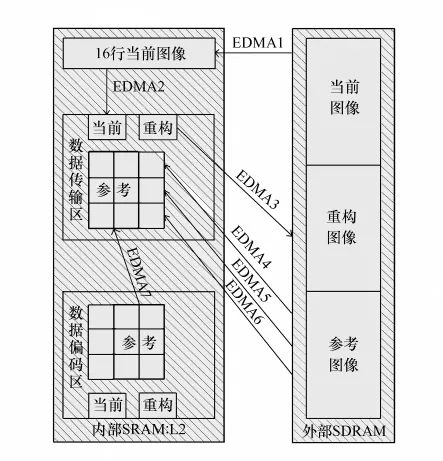
图3 乒乓操作过程示意图Fig.3 Scheme of Ping-Pang operation process
3.3 利用可并行执行的多功能单元提高CPU处理能力
直接移植到DSP上的MPEG-4视频编码器远远不能达到实时的要求,因此还需要结合TMS320C64XX的特点进行优化。程序框架和主函数采用C语言编写,可增加程序的易读性,一些初值的设置编译器也能自动帮助完成,既准确又不耗时。而对耗时较多的模块采用汇编优化,在数据安排上要考虑二级缓存特性。编码的计算量主要集中在运动估计、离散余弦变换、量化、反量化、逆离散余弦变换和可变长编码几个模块,需要利用汇编语言进行优化,同时要考虑DSP特性。
TMS320C64XX芯片内核具有超长指令VLIW字处理能力。每次读取与256 bit程序总线宽度对应的取址包,即每个取址包有8条指令,分成1~8个执行包,每个执行包是并行执行的指令,送入相应运算单元。指令以取址、译码和执行的硬件流水线运行。CPU内部的8个运算单元分为两组,分别为(M1、D1、S1、L1和 M2、D2、S2、L2),在一个时钟周期内8个单元可以同时运行,但8个单元所完成的功能不尽相同,M单元的指令与其它单元不通用,只运行乘法、点积、位计数等指令。除M单元指令外,有些指令只能在某一特定的运算单元执行,如跳转指令只能在S单元运行,存储器访问指令只能在D单元运行等,但也有部分指令在D,S和L中都能运行。
在用汇编优化程序时,除按一般编写步骤(将C源代码翻译成线性汇编代码,确定最小迭代间隔,资源分配,安排模迭代间隔和安排剩余指令)之外,还要考虑运算单元与指令之间的对应关系,改写代码。
下面以几个实例来介绍提高汇编程序效率的技巧。
(a)修改指令,尽量利用M单元
由于M单元的特殊性,如果算法不涉及乘法运算,就不能用到M单元,这样8个可并行工作的运算单元,一次最多能并行执行6条指令,处理能力会降低25%。为提高运算效率,应修改指令,尽量利用M单元。例如,计算4个8位像素和,可改写为点积方式:

另外,还可用M单元作为循环初始条件的判据。例如从存储器读出数据经过计算后,将处理结果存回到存储器帧中,由于读指令的延时间隙不为0,开始几次循环,结果还没计算出来,此时不应存数据,实现该功能一般是设一个初值为2的寄存器,每个循环减1,当为0时,存结果,但这样会增加DSL单元的压力。此时可以利用寄存器赋初值为0XFFFF8000,每个循环乘2(用低16位的乘法指令MPY实现)为0时,存数。

其中前两条指令在进入循环体之前执行。
(b)访问存储器尽量使用半字或字访问字节型数据
由于DSP单元都是32 bit宽,许多指令也支持高低半字或4个字节分别操作,当对8 bit的短数据或16 bit半字进行操作时,可以字为单位同时读取,然后再用内部函数对数据进行运算。即使不能直接使用支持高低半字或4个字节的指令,也可用其它指令将字按字节或半字分别存入寄存器组中。这样可以减少访问数据存储区的次数,降低D单元的压力,相应地提高程序的运行速度。
(c)利用C64新增加的一个单元同时做4个8 bit或2个16 bit算术运算
C64XX增加了对打包数据的处理[15],可在一条指令内对2个16 bit或4个8 bit的数据进行运算。例如在运动估计中要计算两个块(8×8)的绝对差之和。如下代码一次计算8个点。从上面几个例子中可以看出,在汇编优化时,通过改写代码,合理利用指令,平衡各单元利用率,可进一步提高CPU效率。

4 实验与分析
在TMS320C6416硬件平台上对MPEG-4视频标准编码器进行移植和优化,DSP的时钟频率为800 MHz,输入图像为 512 pixel×512 pixel的灰度图像,SDRAM大小为32 Mbyte,分成32个1 Mbyte的块,每块可存一幅图像,分别存储输入图像、参考图像及重构图像,FPGA有一个精度为1 μs的计数器,其值可由软件清零、读入,用以记录每帧的编码时间,并可随码流输出。对图4所示的室内景物运动序列进行压缩实验,截取其中的40 frame,1 个I frame,39 个 P frame,压缩信噪比为33.09,输出码率为1.5 Mbit/s。平均压缩时间为30.3 ms,没有丢帧现象,可以满足实时编码的要求。

图4 实时采集的图像序列(压缩后图像)Fig.4 Real-time images(after compression)
5 结论
占用的内存空间进行优化;利用EDMA级联特性在内存开辟双缓冲区,同时完成视频数据编码和传输的工作,有效地改善了编码效率,使该平台具有较高的数据吞吐能力和处理速度。实验结果表明:该编码器可以对 512 pixel×512 pixel,30 frame/s的视频图像进行实时编码,并已应用在实际工程中。
本文在TMS320C6416平台上对MPEG-4视频编码器进行了优化,包括对8个运算单元能并行执行的特性进行汇编优化;根据DSP芯片两级高速缓存的工作特点,对编码器中代码和数据所
[1]许廷发,赵思宏,周生兵,等.DSP并行系统的并行粒子群优化目标跟踪[J].光学 精密工程,2009,17(9):2236-2240.XU T F,ZHAO S H,ZHOU SH B,et al..Particle swarm optimizer tracking based on DSP parallel system[J].Opt.Precision Eng.,2009,19(9):2236-2240.(in Chinese)
[2]李玉文,周家锐,沈琳琳.基于DM6446平台的实时人眼检测系统[J].深圳大学学报理工版,2009,26(10):420-424.LI Y W,ZHOU J R,SHEN L L.Real time eye detection system based on DM 6446[J].J.Shenzhen University Sci.Eng.,2009,26(10):420-424.(in Chinese)
[3]安博文,潘胜达.基于FPGA+DSP的超分辨率成像系统设计红外技术[J].红外技术,2010,32(9):523-526.AN B W,PAN SH D.Design of super-resolution imaging system based on FPGA+DSP[J].Infrared Technol.,2010,32(9):523-526.(in Chinese)
[4]李胜勇,姜涛,朱强华.红外序列图像中小目标实时检测系统设计与实现[J].红外技术,2010,32(8):471-474.LI SH Y,JIANG T,ZHU Q H.Design and implement a real-time system for small target detection in infrared image sequence[J].Infrared Technol.,2010,32(8):471-474.(in Chinese)
[5]杨明极,曾稹.基于DSP的WAP实时图像浏览平台的研究[J].哈尔滨理工大学学报,2010,15(10):45-48.YANG M J,ZENG ZH.Research of WAP real-time image browsing piatform based on DSP[J].J.Harbin University of Science and Technol.,2010,15(10):45-48.(in Chinese)
[6]贾浩,崔慧娟,唐昆.基于TMS320DM6437平台的视频系统设计与实现术[J].电视技术,2010,34(11):43-47.JIA H,CUI H J,TANG K.Design and implementation of video system based on TMS320DM 6437 platform[J].Video Eng.,2010,34(11):43-47.(in Chinese)
[7]宋立锋,戴青云.分数像素精度运动估计的DSP优化方法[J].通信学报,2009,30(6):114-119.SONG L F,DAI Q Y.Technique of DSP optimization on fractional-pixel-accurary motion estimation[J].Communication J.,2009,30(6):114-119.(in Chinese)
[8]赵峰,袁东风,张海霞,等.多DSP图像压缩实时并行处理系统[J].光学 精密工程,2007,15(9):1451-1455.ZHAO F,YUAN D F,ZHANG H X,et al..Multi-DSP real-time parallel processing system for image compression[J].Opt.Precision Eng.,2007,15(9):1451-1455.(in Chinese)
[9]周雅贇,徐元欣,方健,等.基于TMS320DM642的MPEG-4编码器设计和优化[J].电视技术,2005,29(6):36-38.ZHOU Y Y,XU Y X,FANG J,et al..Implementation of mpeg-4 video encoder based on TMS320DM642[J].Video Eng.,2005,29(6):36-38.(in Chinese)
[10]曾明霞.基于DSP的MPEG-4视频编码器研究与实现[D].南京:南京理工大学,2007.ZENG M X.Research and implementation of MFEG-4 video coder based on the the DSP[D].Nanjing:Nanjing University Science and Technology,2007.(in Chinese)
[11]刘刚.H.264视频编码器在DSP上的实现与优化[D].长春:中国科学院长春光学精密机械与物理研究所,2010.LIU G.Implementation and optimization of H.264 video encoder based on DSP[D].Changchun:Changchun Institute of Optics,Fine Mechanics and Physics,Chinese Academy of Sciences,2010.(in Chinese)
[12]沈钲,孙义和.一种支持同时多线程的VLIW DSP架构[J].电子学报,2010,38(2):352-358.SHEN ZH,SUN Y H.Architecture design of simultaneous multithreading VLIW DSP[J].Electronic J.,2010,38(2):352-358.(in Chinese)
[13]钟玉琢,王琪,贺玉文.基于对象的多媒体数据压缩编码国际标准—MPEG-4及其校验模型[M].北京:科学出版社,2000.ZHONG Y ZH,WANG Q,HE Y W.Based on Video Object Multimedia Data Compress Encode International Standard-MPEG-4and Video Verification Model[M].Beijing:Science Press,2000.(in Chinese)
[14]李方慧,王飞,何佩琨.TMS320C6000系列DSPs原理与应用[M].2版.北京:电子工业出版社,2003.LI F H,WANG F,HE P K.DSPs Principle and Applying of TMS320C6000[M].2nd ed.Beijing:Electronics Industry Press,2003.(in Chinese)
[15]TMS320C64x/c64x+DSP CPU and Instruction set reference guide[G].Dallas:Texas Instruments Incorporated,2005.
