基于类型论的汉语分词系统TTCS
2011-10-30高东平
高东平
(中国医学科学院医学信息研究所,北京 100020)
基于类型论的汉语分词系统TTCS
高东平
(中国医学科学院医学信息研究所,北京 100020)
针对汉语分词中的未登录词识别和歧义消除这两个瓶颈问题和目前方法的不足,将类型论的思想引入到汉语分词领域中,提出了类型匹配模型,以类型论函数贴合为主要算法,融合了全切分、统计,前后缀识别信息等多种技术手段,将分词、未登录词识别、歧义消除,词典的动态扩充有机的融合到一个统一的理论模型当中。在此理论框架的基础上,最后实现了基于类型论的汉语分词系统TTCS。
类型匹配;汉语分词;歧义消除;未登录词;类型论
众所周知,歧义和未登录词是汉语分词的两大瓶颈。从1983年第一个实用分词系统CDWS[1]的诞生至今,国内外的研究者对汉语分词中的这两个问题进行了广泛的研究。从众多研究方法来看,多数是针对其中之一进行的研究。例如,针对歧义问题,有基于规则的方法[2-3],也有针对某一类歧义的处理,如引入向量空间解决组合歧义问题[4],用条件随机域的方法处理组合歧义问题[5]等。对于未登录词识别的研究,主要的出发点是综合利用未登录词内部构成规律及其上下文信息。未登录词识别处理的对象主要是人名、地名、译名和机构名等命名实体。
在现有的研究中,对于分词算法、切分排歧和未登录词识别的解决方案多数是相对独立进行的。只有少数学者给出相对统一的模型框架将三者进行有机的融合[6-7]。
本文借鉴类型论的思想,针对汉语的特点,对汉语类型重新进行设计,并在此基础上提出了一种基于类型匹配的模型,旨在将歧义消除、未登录词识别、词典动态扩充等任务融合到一个相对统一的理论模型中。在我们的分词系统中,词典中的每个词不再标注其词性,而是标注类型。通过句子类型匹配和短语类型匹配模型可以计算寻找出恰当的切分。在文章的第一部分我们描述了TTCS系统的流程,给出了类型与规则的设计,并对设计背后的动机进行了详细阐释;在第二部分我们介绍了在类型论框架下,歧义和未登录词识别的解决方案;文章最后对此系统的设计进行了总结和讨论。
一、基于汉语类型论的分词系统TTCS
(一)TTCS的系统流程
基于类型逻辑的汉语分词系统(TTCS)的基本设计流程如图1。
(二)类型论与语句生成
类型逻辑语义学主要是指蒙太格语法的内涵类型逻辑。蒙太格把范畴语法与内涵类型逻辑联系在一起,通过句法范畴到逻辑类型的映射给范畴语法的句法分析提供了严格的模型论语义解释[8]。以蒙太格语义学为代表的逻辑语义学把语句的句法分析和语义解释看成是同构的。即认为词的组合成句及其语义的模型论解释有着一一对应的关系,也就是说,语义解释是从句法代数到语义代数的同构映像。类型论使得这种同构映像成为可能[9]。从逻辑的观点看,语句S的两个关键成份为谓词和论元。较简单的语句的谓词仅含单个动词或形容词,论元仅由专名充当。从外延的角度看,专名指称个体(在类型论中记作e),语句指称真值(记作t),谓词指称个体的集合[10]。在类型论中,如果把e和t设定为基本类型,则其它较复杂的类型都可以根据以下定义得到:
定义1[10]:类型的集合S是最小集,使得:
(1)e,t∈S;
(2)如果a,b∈S,那么ab∈S;
(3)此外,S中不包含其他元素。
其中,e,t为基本类型,e代表个体,t代表真值。
(2)中的a﹑b可以是基本类型,也可以是复杂类型。这样,谓词可以通过e和t来间接定义。
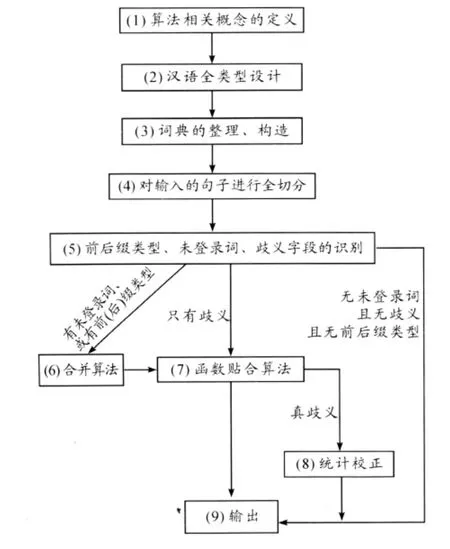
图1 TTCS流程图
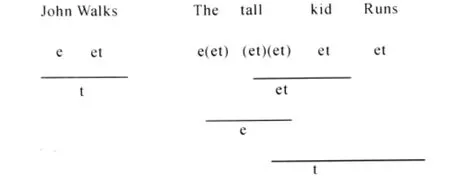
将上述类型与具体的词汇及其逻辑表达式相匹配,可以得出一些结构较为简单的语句的组合过程。例如:“John Walks.”
(三)汉语类型设计
汉语的句法结构有其特殊的地方。再加上考虑到汉语分词系统设计的实际情况,我们需要将类型重新定义。在这一小节,我们将给出汉语的类型设计,以及在后文计算中用到的相关概念。
定义2:汉语类型的集合S是最小集,使得:
(1)e和t为基本类型;f为辅助类型;
(2)如果a,b为辅助类型之外的类型,则(ab)为类型。
(3)如果a,b之中存在辅助类型,若a,b之间存在匹配规则,则(ab)为类型。
其中f={f1,f2,f3,n,q,p,s,x}。其中,f1,f2,f3主要指函数类型;x类型主要包括助动词,叹词,拟声词,助词,语气词等,n指数词;q指量词;p,s分别指前、后缀。
定义3(函数贴合):令g是类型为ab的表达式,如果(是类型为a的表达式,那么g(a),g(b)分别是类型为b和a的表达式。
定义4:一个句子是真歧义的当且仅当有两种不同的切分方式使得每一种类型函数贴合后的结果都是t。
定义5:一个切分是正确的,当且仅当存在一种贴合方式使得类型函数贴合的最后结果是t。一个切分是可接受的当且仅当它存在一种贴合方式可以得到一个类型函数贴合结果。
表1中每一种类型设计都是语言学知识的体现。例如:趋向动词(分为简单趋向动词(上,下,来,去)和复杂趋向动词(起来,出去)),它们既可以单独做谓语,也可以在别的动词或形容词后作趋向补语。故我们将其类型设计为:et(et),et类型。
更多的类型设计参见笔者的前期研究成果[11-12]。

表1 TTCS中的类型设计
(四)多类型指派的讨论
在类型逻辑的经典阶段,它是通过对基本表达式指派一个或多个范畴组成,来使被计算的函数-论元组合匹配实际的语法字串。然而,由于自然语言是非常灵活的,同一个词在不同语句中的作用,在不同语句中的词性显然不尽相同。为了处理众多语言学中的问题,后来的很多学者,已经有了诸多不同的提议,如增加类型改变的范畴机制,或者是增加类型组合的更多的模式等。这是至今为止,大量文献里普遍采用的方法,例如,Geach为了说明否定的多态性,引入了他的递归规则,来提升基本类型tt为((et)(et))(不及物动词否定),((e(et))(e(et)))(及物动词否定)[13]。此种相同的改变也可以解释非常不同的事实,比如在及物动词接受复杂的命题短语对象时遇到的人所共知的困难[14]:
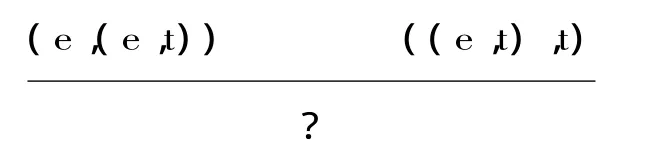
这在基本的框架下是没有函数贴合规则可以实现的。Geach的解决方式是让直接对象表达式“适应语境”[14]:
其他很多的类型改变规则也已经因为句法和词法的需要而被提出。
但是与这种传统的研究路线不同,我们在设计TTCS系统时,采用每个词进行多类型指派的方法,而不采用类型改变方法来解决自然语言中遇到的各种问题,原因有下述几点:
首先,类型改变自身也存在一定的问题,即类型改变的规则是非常宽松的,而事实上,某些类型变换确实是不可接受的。如“主目上升”规则: (a,c)⇒(((a,b),b),c)这种一般性的范式是无效的[14]。
而在TTCS中,我们对每个词进行多类型指派不但可以实现类型改变的目的,而且还可以减少类型改变在实际语言中不可接受的情况。原因很简单,因为类型改变作为规则而言,是对于任何类型都成立的,但是,我们进行多类型指派,是针对每一个词的,例如,有的类型改变规则将不及物动词可以类型改变为及物动词,如果作为规则应用,则所有不及物动词都可以改变为及物动词。但是在汉语中,虽然有很多不及物动词也确实是及物动词,但是显然也有很多词只能作为不及物动词使用,因此对于汉语分词的具体任务而言,我们在构建词典时,对每一个词根据其语言学特征,进行多类型指派可以很好的解决类型改变过于宽松这一问题。
另外,类型改变的另一优点,比如通过类型提升解决及物动词接受复杂的命题短语对象时遇到的困难:(e,(e,t))和((e,t),t)的匹配问题,类似的这类现象,在TTCS中,我们则是直接将函数的组合描述成:(e,(e,t))((e,t),t)⇒(e,t)来进行解决。
再有,对于解决汉语分词的实际问题而言,时空开销是我们必须要考虑的一个因素,虽然在我们的算法设计中,也应用到了一些递归算法,但是实际效果分词速度是可以接受的,如果我们不采用多类型指派的方法,而改为给出大量类型改变规则的方法,分词速度将会明显变慢。且分词的准确度也会受到一定影响。
第四,采用多类型指派的方法,可以通过分词过程很清晰的看出句子的结构,以及每个词在句子中的角色。
(五)类型贴合运算规则设计
类型函数贴合算法中的类型贴合规则,主要是根据语言学知识所进行的设计。规则设计的合理度和全面度直接影响着分词系统的准确度。
在TTCS系统中,部分类型贴合规则如下(更多规则见参考文献[11-12]):
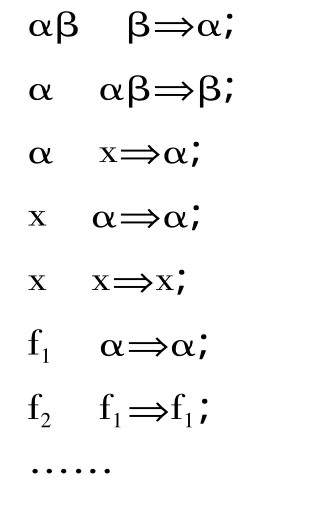
其中有α出现的为规则模式,即α可以替换为任意类型,其他为具体规则。
如果切分序列类型函数贴合的结果是t,则说明是正确的切分。
如果切分序列类型函数贴合存在最后的类型则是可以接受的切分。
具体算法如下:
第(1)步:读取类型序列;
第(2)步:对类型序列中相邻类型(从第一个类型开始),运用上述类型贴合规则逐步进行贴合,直到不再有可以贴合的相邻类型为止。
第(3)步:对贴合结果进行判断,如果只有一种切分是正确切分则直接输出;如果两种切分都是正确切分,则进行统计校正;如果不存在正确切分,存在可以接受的切分,则输出可以接受的切分;如果既不存在正确切分也不存在可以接受的切分,则输出全切分后排在第一个的序列作为切分结果。
一个合法的句子总是可以匹配成t的,本文中设计出“可以接受的切分”,是考虑到汉语中经常使用逗号将一个完整的句子分为几部分,而对于逗号切分出的部分,匹配结果应该是一个类型(对应汉语中的一个成份),这样可以减少匹配次数,提高分词效率。
二、TTCS对歧义和未登录词的处理
(一)对歧义的处理
在TTCS中,交叉歧义、组合歧义识别通过已有方法进行判断:
(1)令S=C1C2…Cn是需要切分的字符串,检测是否至少存在两种不同的切分路径 S1=W1W2…Wn和S2=W1’W2’…Wm’,其中Wi,Wi’∈LexiCon。
(2)如果存在至少两种不同的切分路径,且Wi和Wi’是两种切分下第一个不同的词,若Wi的长度大于Wi’的长度,且Wi’+Wi+1’的长度大于Wi的长度,则称字串Wi’Wi+1’是S中第一个具有交叉歧义的字串。
(3)如果Wi’+Wi+1’的长度等于Wi的长度,则称字串Wi’Wi+1’是S中第一个具有组合歧义的字段。
在我们的系统中,对歧义的处理主要基于以下几个步骤:
(1)对输入的句子进行全切分;
(2)歧义识别;
(3)对全切分结果执行函数贴合运算
(4)选择可以接受的结果
(5)输出
(二)未登录词的识别
在TTCS系统中,未登录词的识别主要是基于未登录词合并算法和类型贴合运算而进行的。在我们的未登录词合并算法中,主要处理了下面三种情况:
Case1.type(Ci)=p;其中Ci是预合并单词的词头;
Case2:type(Ci)=s;其中Ci是预合并单词的词尾;
Case3:type(Ci)=‘?’;起哄‘?’是对词典中没有的词进行的标记。
每一种情况又包含数种子情况(对于预合并单词的词头是p类型,预合并单词的词尾是s类型的情况,我们在算法编写过程中归入到了第一种情况进行处理)。
考虑到越界问题,我们将Case1又分为以下三种情况来处理:
Case1.1:Ci后只有Ci+1;
Case1.2:Ci后只有Ci+1,Ci+2;
Case1.3:Ci后多于Ci+1Ci+2
Case2:也同样分为:
Case2.1:Ci前只有Ci-1且不是p类型
Case2.2:Ci前只有Ci-1,Ci-2
Case2.3:Ci前只有Ci-1,Ci-2,Ci-3
在每种情况下又将Cj(j=i-1,i-2,i+1,i+ 2,i+3……)分为未登录词,单字词,多字词几种情况来处理。是单字词时,我们又细分为是否具有连词类型,介词类型,判定动词类型几种子情况。
未登录词的识别过程概述如下:
(1)前、后缀类型、未登录字的识别;
(2)在具有前、后缀类型、未登录字时,执行合并算法;
(3)将合并算法的结果进行类型函数贴合运算;
(4)根据类型函数贴合运算结果选择正确的合并结果(正确的合并结果既为识别出的未登录词)
三、结论
本文主要目的是将类型逻辑的思想和方法引入到自然语言信息处理领域,来解决汉语分词问题。从类型逻辑的研究趋势来看,目前大量学者意识到了用其描述各种不同自然语言的重要性以及用其解决各种不同自然语言中特殊问题的可行性及价值。因此,学者们纷纷用其为工具,对荷兰语、意大利语、日语、汉语等各种语言中的特殊问题进行研究、刻画[15-16]。因此对汉语类型论进行研究,对于类型逻辑本身而言,也是具有重要意义的。
在本文中,我们从根本上突破了传统类型论的定义,引入了辅助类型来解决未登录词识别问题,使类型论可以描述的语句范围有了明显扩展。当然,辅助类型的引入也是出于汉语语句比较松散,且非常灵活这些因素而考虑的。
在TTCS系统的设计中,除了文中详述的内容之外,还涉及到统计校正和词典的动态扩充等问题,这些由于篇幅问题我们没有展开,但这些问题的解决对于我们系统的完整性及应用的方便性都具有重要作用。
[1]梁南元.书面汉语自动分词系统-CDWS[J].中文信息学报,1987(2):101-106.
[2]张仕仁.利用语素词规则消除切分歧义[C]//1998年中文信息处理国际会议论文集.北京:清华大学出版社,1998.
[3]Zheng J H,Wu F F.Study on segmentation of ambiguous phrases with the combinatorial type[C]//Collections of papers on Computational Lingustics,Beijing: Tsinghua University Press,1999.
[4]Xiao Luo,Maosong Sun,Benjamin K Tsou.Covering Ambiguity Resolution in Chinese Word Segmentation Based on Contextual Information.COLING’02 Proceedings of the 19th international conference on Computational linguistics,vol1,Stroudsburg,2002.
[5]Ying Xiong,Jie Zhu.A New Machine Learning Method for Chinese Overlapping Disambiguity—Conditional Random Fields[C]//Proceedings of the Sixth International Conference on Machine Learning and Cybernetics,HongKong,2007.
[6]刘群,张华平,俞鸿魁,程学旗.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,41(8),1421-1429.
[7]Gao Jianfeng,Li Mu,Wu Andi,et al.Chinese Word Segmentation and Named Entity Recognition:A Pragmatic Approach[J].Computational Linguistics,2006,31 (4):531-574.
[8]邹崇理.自然语言逻辑研究[M].北京:北京大学出版社,2000.
[9]蒋严,潘海华.汉语语句的类型表达[C]//1998中文信息处理国际会议论文集.北京:清华大学出版社,1998.
[10]Gamut L T F.Logic,Language,and Meaning(Vol2)[M].The University of Chicago Press,1991.
[11]Gao Dongping,Niu Zhendong,Lv Lening,et al.Chinese Unknown Word Recognition Based on Functional Applications of Type Theory[C]//IITA2008,Published by IEEE Computer Sociey,2008.
[12]Gao Dongping,Guo Jiahong.Dealing with Chinese Overlapping Ambiguity Based on Type Functional Application[C]//2009 International Conference on Artificial Intelligence and Computational Intelligence,Published by IEEE Computer Sociey,2009.
[13]Geach P.A Program for Syntax[M].Davidson D.Harman G.eds.,Springer,1972.
[14]约翰·范本特姆.逻辑、语言和认知[C]//刘新文,郭美云,等,译.逻辑之门——约翰·范本特姆经典著作(卷II).北京:科学出版社,2008.
[15]Otake R,Yoshimoto K.A Multimodal Type Logical Grammar Analysis of Japanese:Word Order and Quantifier Scope[C]//Annual Conference of the Japanese Society for Artificial Intelligence,Springer,2007.
[16]Angelov K.Type-theoretical Bulgarian grammar[C]// Advances in Natural Language Processing,Proceedings,Berlin:Springer,2008.
Chinese Segmentation System TTCS Based on Type Theory
GAO Dong-ping
(The Institute of Medical Information,Chinese Academy of Medical Sciences,Bejing 100020,China)
Chinese unknown word recognition and disambiguation are difficult problems of Chinese word segmentation.We introduce a method based on type theory for Chinese word segmentation in this paper.The model of type functional application is employed attempting to resolve Chinese ambiguity and unknown word recognition.A Chinese word segmentation system TTCS is proposed that it unites techniques including omni-segmentation,statistical method,prefix and suffix information expansion and so on.A major advantage of the TTCS is that it can deal with Chinese word segmentation,unknown word recognition,disambiguation and the dynamic expansion of the dictionary in a unified theoretical model.
type functional application;Chinese word segmentation;disambiguation;Chinese unknown word recognition;type theory
B81
A
1674-8425(2011)08-0061-06
2011-06-30
国家社科基金“面向自然语言信息处理的范畴类型逻辑研究”(09BZX046)资助。
高东平(1979—),女,河北人,博士后,副研究员,研究方向:自然语言处理、逻辑学、情报学。
(责任编辑 邝坦励)
