形式语义模型与复合汉语NP的语义刻画
2011-10-30李可胜
李可胜
(合肥师范学院外语系,合肥 230601)
形式语义模型与复合汉语NP的语义刻画
李可胜
(合肥师范学院外语系,合肥 230601)
汉语名词词组NP的指称意义复杂,特别是在没有形式标记时,往往存在单数/复数、全称/存在量化、概称/特指、有定/无定等歧义。而传统的语义模型结构简单,在刻画汉语NP的这些语义特征时,难以贯彻组合性原则。采用具有代数格性质的语义模型,将NP的语义统一处理成集群,并使用相应的分布算子,这样在刻画汉语NP的语义时,可以有效地贯彻组合性原则。
形式语义学;加合/集群;复合NP;代数语义结构
自然语言(简称NL)的形式语义学通常包括两部分:首先将语义模糊并且高度依赖语境的NL语句翻译成严谨缜密的逻辑表达式,同时需要构造语义模型来解释逻辑表达式的意义。在某种程度上,逻辑表达式可以看成是NL的语义,但是逻辑表达式的本质仍然是一种语言的形式,而非语言的意义。把NL语句翻译成逻辑表达式,类似于将英语翻译成汉语,只是语言形式做了改变,并没有说清楚语义是什么。在形式语义学中,翻译NL语义的逻辑表达式最终需要在语义模型中得到解释,才真正完成了语义的形式刻画。NL的语义也只有得到模型论的解释,才能被计算机“理解”,因此“模型概念是形式语义学的核心”[1]。但是传统语义模型结构简单,很难刻画指称意义复杂的汉语名词词组(简称NP)。本文将汉语NP的语义统一看成是集群,并尝试用具有代数格结构的语义模型进行模型论解释。
一、传统语义模型与复杂指称名词
(一)传统语义模型的特点
依据邹崇理的看法[1],用抽象的数学方法构建一个基本框架,用来表现语言所涉及的外部世界基本要素,例如,个体、性质及关系等;再把NL语句的各种成分同基本框架中的相关要素对应起来,这就是NL的语义模型,然后据此就可以刻画NL语句的意义,这便是NL的模型论解释。为了讨论的便利,下文将用来翻译NL的逻辑表达式直接称为NL的语义。
传统一阶逻辑的语义模型是一种简单结构模型,其论域是一个非空简单个体集合,一般不涉及个体的构造方式以及彼此之间的结构关系。通常情况下,专名(proper name)的语义是个体,通名(common noun)的语义是个体的集合。假设语境中只存在张三、李四和王五三人,身份都是学生,并且张三和李四在睡觉。用模型M1来刻画,M1的论域中存在三个原子个体,记作‖zhang‖,‖li‖和‖wang‖(分别代表张三,李四和王五)。专名“张三”的语义是zhang,在M1中的所指是‖zhang‖。通名和谓词的语义都是个体的集合,如“学生”和“睡觉”的语义分别是学生'和睡觉',在M1中分别指称集合{‖zhang‖,‖li‖,‖Wang‖}和{‖zhang‖,‖li‖}。注意,后面常直接用‖P‖来表示P的外延集。
在M1中,验证一个NL语句,先将该语句译成一阶逻辑公式,然后在模型中给予验证。如“张三睡觉”译成睡觉'(zhang),在M1中,zhang的所指‖zhang‖属于睡觉'的外延集‖睡觉'‖(记作‖zhang‖∈‖睡觉'‖),所以‖睡觉'(zhang)‖=1。而对复数词项的验证就是对单数个体验证的合取或析取。如“所有的学生都在睡觉”和“有些学生在睡觉”,分别译成∶∀x(学生'(x)→睡觉' (x))和∃x(学生'(x)∧睡觉'(x))。在M1中,逐个验证‖zhang‖,‖li‖和‖wang‖是否在‖睡觉'‖中。因为‖wang‖∈‖睡觉'‖,所以‖∀x (学生'(x)→睡觉'(x))‖=0,而‖∃x(学生'(x)∧睡觉'(x))‖=1。
如果语句中仅包含专名或简单量化NP(即类似于some men,all men,the man的NP),传统语义模型是足够的。一旦包含了语义更复杂的NP,则很难给出满意的语义刻画了。
(二)汉语NP的所指意义分析
汉语NP的所指复杂,特别是在没有句法标记时,往往存在单数/复数、全称量化/存在量化、概称/特指、有定/无定①按一般文献的定义,NP的特指和概称都是有定用法。有定用法是指说话双方都能确定NP所指的个体,而无定用法是指说话者能确定NP所指的个体,但听话者不一定能确定。等歧义。比如,“他家的猫”在“他家的猫在院子里叫”中存在单数/复数歧义,可以指一只猫,也可以指多只猫;同时还有全称量化/存在量化歧义,可表示“他家所有的猫都在院子里叫”,也可表示“他家的猫中,有一部分在院子里叫”。又如,“猫在院子里叫”中的“猫”是一种有定和特指用法;在“猫到处可见”中是概称,指猫这一类动物,而在“她养了猫”中,是无定用法。
基于传统语义模型的形式语义学,对于NP的这些歧义,只能用多个不同逻辑式来表示。比如,“他家的猫在院子里叫”的两种语义分别表示为:∀x(猫'(x)∧他家的'(x)→在院子里叫'(x))和∃x(猫'(x)∧他家的'(x)∧在院子里叫'(x))。
但这种方式不符合组合性原则,即一个复合表达式的语义是其组成成分语义的函项。不符合组合性原则,就意味着对于每个不同的复合表达式,都必须独立地指派不同的逻辑表达式。考虑到自然语言句子数量的不可穷尽性,对自然语言语义的组合运算,显然是不现实的。更重要的是,这也没能完全解决问题。比如,把“猫到处可见”的语义表示成∀x(猫'(x)→到处可见'(x))或∃x(猫' (x)∧到处可见'(x))都不合适。前者的模型论解释是:所有x,如果x(‖猫'‖),则x(‖到处可见'‖),即“所有的猫到处可见”;后者的解释是:至少存在一个x,x∈‖猫'‖并且x∈‖到处可见'‖,即“至少有一只猫到处可见”。事实上,正确理解应该是“在不同的地方能见到不同的猫,但每个地方总是能见到某种猫”。
为了能在形式语义模型中,通过组合性的方法来处理汉语NP的语义。本文提出,除了专名或使用数量词(如“一”或“这只”等)之外,汉语的NP都不直接指称事物个体,而指称事物的类(kind)。只是在与句子其他成分发生组合运算时,NP通过特定算子的作用,才可以指称个体。换句话说,“猫”、“白猫”和“他家的猫”都不直接指称猫个体或个体的集合,而指称特定范围内的猫所形成的类。
从认知的角度分析,类是一种概念。这种概念是对集合内个体的特征进行抽象而得到的。概念并不等同于集合本身,也有别于构成集合的个体,而是一种有着独立地位的概念个体。对类的性质进行讨论,并不等同于讨论该类所有个体的共性。比如,当人们说“三班的学生搭起了帐篷”,并不是意味着三班的所有学生都参加了搭帐篷的活动。只要搭帐篷的学生来自三班,即使只是其中的少数,这句话也是恰当的。也就是说,“三班的学生”是一个整体概念,某个属性为“三班的学生”所具有,并不意味着三班的所有学生都有这种属性。
问题在于,一个NP只有指称个体的集合,才能与其修饰语进行组合运算。如果将类看成是不同于个体集合的一种独立个体,则无法与其修饰语进行语义的组合运算。例如,通常认为“白猫”指称白色的猫构成的集合,该集合是猫的集合与白色个体的集合的交集。但如果将“猫”看成是指称所有的猫所形成的类,而类是不同于个体集合的独立个体,则与白色个体的集合之间不存在交集,则“白猫”的语义所指就不能从“猫”和“白色”的语义所指中得到。
二、NP语义的代数结构
汉语NP的类指称语义在具有代数结构的语义模型中才能得到很好的刻画。自20世纪70年代以来,有很多学者讨论了 NL的代数语义结构[2-6]。
(一)加合与集群的概念
要了解代数结构语义模型,首先要了解加合和集群。Link提出[3]:语义模型的论域中不仅存在通常意义上的原子个体,而且还存在加合(Sum)。加合是原子个体通过递归而生成的新个体。用a,b,c表示论域中的原子个体,则a⊕b表示由个体‖a‖和‖b‖生成的加合,而(a⊕b)⊕c表示由加合‖a⊕b‖和‖c‖生成的加合。假定γ是由α和β生成的,则α和β是γ的构件,其中α和β可以是原子个体或加合。构件关系用符号“∏”表示,如α∏γ表示α是γ的构件。加合并不是个体的简单相加,而是新的个体。从集合论的角度看,{‖a1⊕…⊕an‖}和{‖a1‖,…,‖an‖}不同,前者只含1个元素,而后者是n个;‖a1⊕…⊕an‖和{‖a1‖,…,‖an‖}也不同,前者是个体,后者是个体的集合[1]。
Landman则认为[5,6]:构件相同的加合,在论域中的地位也可能不同。比如John和Bill组成的两个委员会C1和C2。显然C1和C2不能视为同一个委员会,而是具有相同结构的不同个体。如图1[5]:
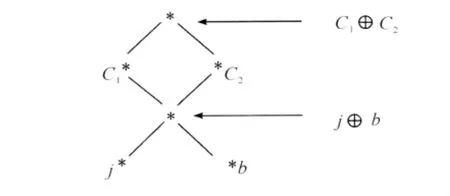
图1 相同构件加合的不同论域地位
j⊕b表示j和b生成的加合,C1和C2表示由加合作为原子个体而生成新的个体。为此,Landman引入新的原子个体概念——集群(Group),并用符号↑表示集群形成(Group Formation)算子,用↓表示成员分解(Member Specification)算子。↑将表示加合的语义表达式转换成表示集群的语义表达式;而↓的作用相反。显然有↓(↑(a⊕b))=a⊕b成立。①关于集群的本质有不同的看法,Landman认为j⊕b通过↑只能生成一个集群↑(j⊕b),而C1和C2是↑(j⊕b)的不同内涵性质。而Link认为↑(j⊕b),C1和C2是三个不同的集群。本文采用Landman的观点,因篇幅原因,关于集群内涵性质的模型论解释,将另文讨论。
Link接受了集群的概念[7],并在语义模型中增加集群运算函项γ,γ将论域中的加合个体转换成数量不同的集群个体。在特定模型中,a⊕b被解释成加合‖a⊕b‖,而↑(a⊕b)被解释成原子个体γ(‖a⊕b‖)。集群与加合的不同之处在于:加合和集群都是复数个体,但加合是非原子个体,集群是原子个体。在没有应用算子↓之前,集群所具有的性质是不可分的,而加合是可分的。另外,非集群的原子个体称为纯原子个体。
(二)语义的代数结构
含有加合/集群的语义结构是一种代数语义结构。a⊕b在语义模型中指称个体‖a⊕b‖,而‖a⊕b‖是‖a‖和‖b‖通过二元运算∪i生成的,②∪i的下标i表示个体(individual),下面的≤i也是如此。即‖a⊕b‖=‖a‖∪i‖b‖。论域中的个体因为∪i运算而形成的关系是一种偏序关系(记作≤i)。直观地看,≤i是一种部分/整体关系。比如,因为‖a‖是‖a⊕b‖的构件(记作a∏a⊕b),所以有‖a‖≤i‖a⊕b‖。
∪i运算是封闭的,即论域中的个体经过∪i运算,得到的加合仍然是论域中的个体。同时∪i运算满足等幂律(即‖a‖∪i‖a‖=‖a‖)、交换律(即‖a‖∪i‖b‖=‖b‖∪i‖a‖)和结合律(即(‖a‖∪i‖b‖)∪i‖c‖=‖a‖∪i(‖b‖∪i‖c‖)=(‖a‖∪i‖c‖)∪i‖b‖。假设论域中的原子个体集A={‖a‖,‖b‖,‖c‖},则由A生成的个体如图2[7]。
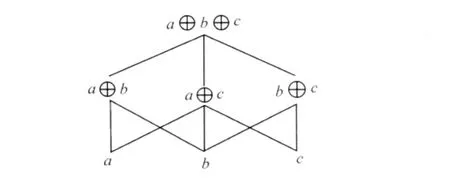
图2 代数语义结构的加合运算
图2所示是一个代数结构〈P(A),≤i〉,其中的任意两个元素都存在上确界,③上确界(记作Sup)指对于P(A)中的任意子集S1和S2,P(A)中都存在另一个子集S3,S3等同于S1和S2中的并集。设S1={a,b},S2={b},则sup{S1,S2}={a,b}。如果S中的任意元素都满足自反性,反对称性和传递性,并且都存在一个上确界,则这个代数结构是一个上半格结构。因为语言学中的case也被翻译成“格”,本文用代数格来表示lattice。因为≤i满足自反性、反对称性和传递性。据数学中的格论(theory of lattice),由A所生成的语义结构是一个(不包含0元素的)上半格代数结构,而含有这样语义结构的模型就是具有代数格的语义模型。图2中的个体不是三个,而是七个,如果将集群作为原子个体也考虑进去,则个体的总数更多。如图3所示,这仍然是一个上半格。但只有两个个体是纯原子个体(a和b),算子↑将加合a⊕b转换成集群↑(a⊕b),并作为新原子个体参入∪i运算,构成新加合,最终图3中也有七个个体。
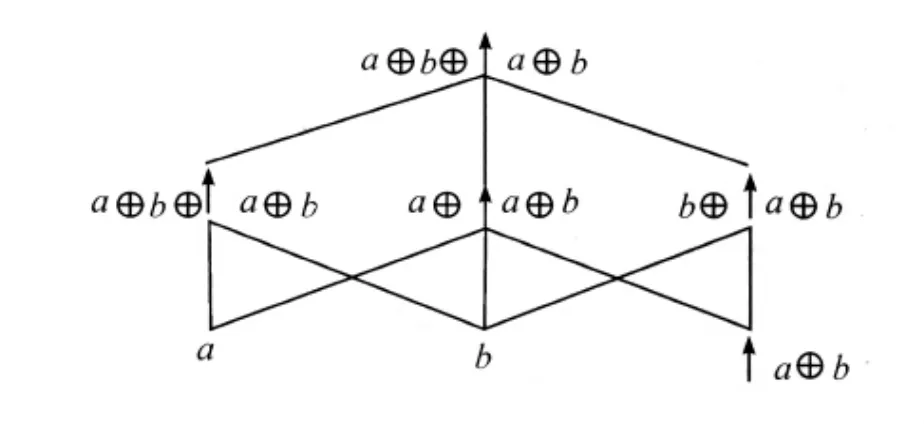
图3 代数语义结构的集群运算
(三)基于代数格结构的LCP系统
从前面的分析不难看出,汉语NP的语义就是一种上半格代数结构。本节将构造一个具有代数格结构的语义模型,以及基于该模型的LCP系统来刻画NP的语义,这里的CP表示Chinese Plurality。
LCP采用Link的做法,用P表示原子个体的性质。星算子*作用于P上,表示包括加合在内的所有个体的性质。比如在M1中,睡觉'的外延集是{‖zhang‖,‖li‖},*睡觉'的外延集是{‖zhang‖,‖li‖,‖zhang⊕li‖}。用σ表示加合符号,σx*P(x)表示最大加合,规定:
设{‖a1‖,…,‖an‖}是具有性质P的纯原子个体集合,则σx*P(x)表示该集合生成的最大加合‖a1⊕…⊕an‖,↑σx*P(x)表示该集合生成的最大集群γ‖a1⊕…⊕an‖,{‖a1‖,…,‖an‖}是σx*P(x)和(σx*P(x))的生成集。
此外,LCP用 σx*P1·…·*Pn(x)表示由‖P1‖、…‖Pn-1‖和‖Pn‖的交集所生成的最大加合。比如,σx*三班的'·*好'·*学生'(x)表示‖三班的'‖∩‖好'‖∩‖学生'‖所生成的最大加合,即同时具有性质“三班的”,“好”和“学生”的所有个体生成的最大加合。
LCP主要针对汉语 NP的语义进行模型论解释。除上面的规定之外,为了节省篇幅,下面只给出必要定义。
D.1 LCP的语义模型 M=〈D,A,A0,γ,‖‖〉,满足:
1)D是模型M中含有集群的个体论域,具有不含0元素的上半格代数结构,A是D的原子个体集,A0是纯原子个体集,A0⊂A。
2)D中个体的类型为e,∪i是D上的二元运算,≤i是D上因∪i运算形成的序列关系。
3)γ是将加合转换成集群的一对一映射。
4)‖‖是LCP的解释函项,对常元,变元以及其他合式表达式的解释如常。
D.2 ↑是集群形成算子,↓是成员分解算子,二者都是一对一映射,满足:
如果a是非纯原子个体,则:
1)如果a是加合,则↓a=a,↑a为集群;
2)如果a为集群,则↑a=a,↓a是加合;
否则,↑a=↓a=a。
D.3 如果a是集群,则:
1)na表示由n个纯原子个体生成的最大集群(n≥0)。
2)sa,da和pa分别表示由单个纯原子个体,两个纯原子个体和多个纯原子个体所生成的最大集群。(s表示单数,d表示双数,p表示复数)
D.4
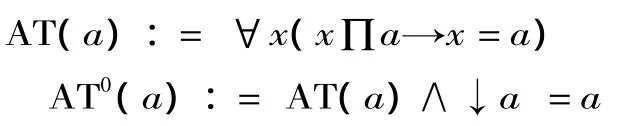
(AT(a)表示a是原子个体,定义为:所有的x,如果x是a的构件,则x就是a本身,即原子个体的构件就是其自身;AT0(a)表示a是纯原子个体,定义为:a是原子个体,并且对a应用算子↓得到的仍然是a。)
D.5 转换算子SET-GROUP算子,NP分布算子DistrNP,DP存在分布算子DistrDP-∃和DP全称分布算子DistrDP-∀等的定义见第3节。
LCP中的常项、变项、合式表达式等的规定遵循最一般的谓词逻辑的做法。D.1中的解释函项‖‖对常元,变元和其它合式表达式的解释如常。例如,将个体常元a解释成论域D中的特定个体,将n元谓词常元Pn解释成D中个体的n元序对集合,将公式解释为真值(即1或0)。对NL的翻译,涉及到的各种算子,均在下面具体运算时给出定义和说明,没有说明的都遵循蒙太格语法的一般原则。
LCP中的基本语义规则:
TD.1 ‖θP(a)‖=1当且仅当‖a‖∈‖θP‖。(上标θ可以是*,也可以为空)
TD.2 ‖AT(a)‖=1当且仅当‖a‖∈A;‖AT0(a)‖=1当且仅当‖a‖∈A0。
TD.3 ‖a∏b‖=1当且仅当‖a‖≤i‖b‖。
TD.4 ‖a⊕b‖=‖a‖∪i‖b‖。
TD.5 如果‖P‖不是空集,‖*P‖的外延是由‖P‖中的所有个体构成的集合;否则‖*P‖是空集。
TD.6 ‖a⊕b‖∈‖*P‖当且仅当‖a‖∈‖*P‖且‖b‖∈‖*P‖。
TD.7 ‖a‖∈‖*P‖且‖a‖∉A,则‖↑a‖=γ‖a‖∈A。
TD.8 ‖a‖∈A且‖a‖∉A0,则‖#a‖∈A且‖#a‖∉A0,并满足:
1) 如果#是大于0的自然数,则|A0∩{x|x∏↓a}|=n;①||表示集合的基数,如|A0|表示A0的基数。数学中,基数表示集合中元素的个数;语言学中,基数是对应量词的“数”,比如,“三位学生”中的“三”。
2) 如果#是s,则|A0∩{x|x∏↓a}|=1;
3) 如果#是d,则|A0∩{x|x∏↓a}|=2;
4) 如果#是p,则|A0∩{x|x∏↓a}|≥3;
TD.9 ‖σx*P(x)‖=Sup‖*P‖;
‖σx*P1·…·*Pn(x)‖=Sup‖*P‖,其中‖P‖=‖P1‖∩…∩‖Pn‖。
TD.10 逻辑符号∨,∧,→,﹁的解释如常;λ抽象和还原以及类型运算定义如常。LCP不涉及内涵类型。
以上规定,均排除a的所指为空的情况。TD.1是谓词逻辑通常的真值定义。TD.3规定,如果a是b的构件,则在论域中的≤i关系中,‖a‖位于‖b‖之前。TD.4,TD.5和TD.6的意义见前文对加合的讨论。TD.7中的条件“‖a‖∈‖*P‖且‖a‖∉A”表示‖a‖是加合,γ将加合‖a‖映射到一个原子个体,即↑a的所指——集群。TD.8中的“A0∩{x|x∏↓a}”表示A0与↓a的构件集形成的交集,也就是na的生成集。TD.8规定,如果a是集群,#a仍是集群,并且满足:如果#是大于0的自然数n,则a的生成集的基数为n;如果#是s或d或p,则生成集的基数分别等于1或等于2或大于等于3。TD.9规定,加合σx*P(x)被解释成‖*P‖的上确界,即‖P‖所生成的最大加合;而加合σx*P1·…·*Pn(x)被解释成‖P1‖、…‖Pn-1‖和‖Pn‖的交集所生成的最大加合。
三、NP的语义运算和解释
先以“三位好学生都在睡觉”为例,说明汉语NP的句法语义组合过程,如图4:
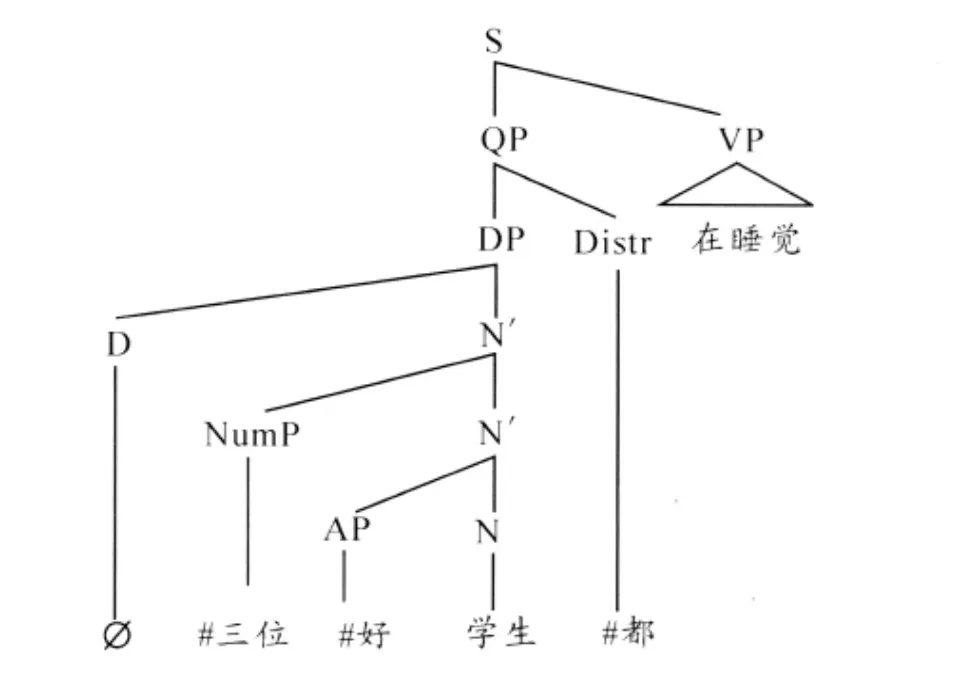
图4 NP的句法语义组合过程
本文将各节点的N和N'都统一称为NP,并规定NP的语义是集群。NP与限定词(包括隐性成分Ø)组合投射成DP。限定词的语义作用是将集群(即NP的语义)进行存在量化,并进行类型提升。这样DP的语义就是集群所具有的性质集。DP需要投射成量化词组QP才能与VP组合。本文将“都,所有…都…,全,每;有些”等词的语义看成是DP分布算子,作用是对DP的语义进行全称分解或存在分解,将集群的性质分解到集群的生成集中所有或部分个体上;如果没有类似词语,则DP直接投射成QP。从图4可看出,任何节点的NP都有可能直接与限定词组合而投射成DP,这就要求任何节点NP的语义都必须是集群,但这种做法为语义的组合运算带来困难。
例如,按形式语义学的通常做法,名词“学生”的语义被看成是所有学生个体构成的集合;形容词“好”的语义是所有具有性质“好”的人或事物构成的集合,“好学生”的语义就是二者的交集。如果“学生”语义不是集合,而是原子个体——集群,则与“好”的语义之间就不存在交集,“好学生”的语义就会落空。
为解决这一问题,在投射成DP之前,NP的每一步投射,其对应的语义运算过程,都要对中心语的语义应用NP分布算子DistrNP,然后与姊妹节点的语义组合运算,所得结果通过转换算子SETGROUP,得到新NP的语义。DistrNP和SET-GROUP的定义如下:

算子DistrNP作用于 NP的语义,所得结果表示:在集群‖a‖的生成集中,至少有一个纯原子个体具有性质P。这正是形容词对NP的作用,比如,学生中至少有一个成员具有性质“好”,“好学生”才有所指,否则语义为空。语义运算过程如下((表示“翻译成”,AP表示形容词词组):
①NP:“学生”⇒σy*学生'(y)
②对①应用DistrNP得到:λP.∃x(AT0(x)∧x∏↓(↑σy*学生'(y))∧P(x))
③AP:“好”⇒λx.好'(x)
④NP:“好学生”⇒λP.∃x(AT0(x)∧x∏↓(↑σy*学生'(y))∧P(x))(λz.好'(z))
=∃x(AT0(x)∧x∏↓(↑σy*学生'(y))∧λz.好'(z)(x))
=∃x(AT0(x)∧x∏↓(↑σy*学生'(y))∧好'(x))
=∃x(学生'(x)∧好'(x))
⑤对④应用SET-GROUP得到:↑σx*好'·*学生'(x)
需要说明的是第④步,当②与③组合运算时,为了同②中的x区分,先将③中的x换成z,然后进行λ-还原,得到∃x(AT0(x)∧x∏↓(↑σy*学生'(y))∧好'(x)),意思是:‖↑σy*学生'(y)‖的生成集中,至少有一个个体属于‖好'‖。根据加合的定义和TD.4,如果x是加合↓(↑σy*P (y)))的构件,同时又是纯原子个体,则x必然具有性质P,所以从∃x(AT0(x)∧x∏↓(↑σy*P (y)))可得到∃xP(x)。这样,∃x(AT0(x)∧x∏↓(↑σy*学生'(y))∧好'(x))就可以化简成∃x (学生'(x)∧好'(x))。其模型论的解释为:至少存在一个x,x∈‖好'‖∩‖学生'‖,满足这样条件的x构成的集合就是“好学生”的语义所指。SET-GROUP的语义作用就是以这样的集合为生成集生成最大集群。①如果只有一个x满足条件,则生成集是独元集。依据D2,所生成的最大集群等同于该独元集中的唯一的纯原子个体本身。
NP与形容词的组合运算方式可以推广到与其他修饰语的组合运算,如做定语的名词以及表示领属关系的词语等,而且可以递归组合。比如,“好学生”和“三班的”组合,按照上面步骤① -④,可得到∃x(AT0(x)∧x∏↓(↑σy*好'·*学生'(y))∧三班的'(x))。因为从∃x(AT0(x)∧x∏↓(↑σy*好'·*学生'(y))),可得到∃x(学生' (x)∧好'(x)),所以∃x(AT0(x)∧x∏↓(↑σy*好'·*学生'(y))∧三班的'(x))可化简为∃x(学生'(x)∧好'(x)∧三班的'(x))。再应用算子SET-GROUP,得到↑σx*三班的'·*好'·*学生' (x),其语义被解释成由集合{x|x∈‖三班的'‖∩‖好'‖∩‖学生'‖}所生成的最大集群。
在LCP中,基数词被看成集合的基量算子N#,并规定如果a指称集群,则N#(a)=#a。比如,“三位学生”中“学生”的语义是↑σx*学生'(x),应用算子N3后得到3↑σx*学生'(x)。在模型中的解释:3↑σx*学生'(x)∈A且3↑σx*学生'(x)∈A0,满足:|A0∩{x|x∏↓(3↑σx*学生'(x))}|=3,即3↑σx*学生'(x)是原子个体,且其生成集的基数是3。
指示词+量词与NP组合时,其中的量词也要求使用算子N#。比如“这些(群)、这位(个,头…)、这双(对)”中的“些(群)、位(个,头…)、双(对)”等。如:
“(这)群学生”⇒p↑σx*学生'(x)
“(这)位学生”⇒s↑σx*学生'(x)
“(这)对猫”⇒d↑σx*猫'(x)
(语义中都不包括“这”,在模型中的解释见TD.8)
再考虑限定词,LCP将“这,那”以及“这些,这个”看成是限定词。如果NP前无限定词,则认为存在空限定词Ø。通常情况下,限定词的语义作用被看成是对NP的语义范围做出限定,比如“这些学生”表示学生中的特定部分。但在LCP中,NP都指称集群,而集群是原子个体,不可能再进一步限定,所以限定词都被翻译成存在量化式,如下所示:
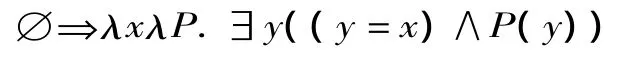
这(那)⇒λxλP.∃y(∀z(z=x↔y=z)∧P(y))
如前所述,如果“这,那”后面有量词,算子Nn先对NP进行运算,然后再与“这,那”的逻辑式组合。比如下面的例子:
DP:“Ø学生”⇒λxλP.∃y((y=x)∧P(y)) (↑σx*学生'(x))=λP.∃y((y=↑σx*学生' (x))∧P(y))
DP:“这位学生”⇒λxλP.∃y(∀z(z=x↔y=z)∧P(y))(s↑σx*学生'(x))=λP.∃y(∀z(z=s↑σx*学生'(x)↔y=z)∧P(y))=∀z(z=s↑σx*学生'(x)↔y=z)
DP:“这三位学生”⇒λxλP.∃y(∀z(z=x↔y=z)∧P(y))(3↑σx*学生(x))=λP.∃y(∀z(z=3↑σx*学生'(x)↔y=z)∧P(y))
LCP将“所有,都,全,每,一些,有些”等看成是DP分布算子DistrDP,并参与到DP投射成QP的过程中。DP分布算子分为两种:全称分布算子DistrDP-∀和存在分布算子DistrDP-∃。分别定义如下:
DistrDP-∀(φ):=λP.(…∧∀y(y∏↓x→P(y))∧…)
DistrDP-∃(φ):=λP.(…∧∃y(y∏↓x∧P(y))∧…)
φ是DP的语义,是类型为<<e,t>,t>、形如λP.(…∧P(x)∧…)的合取式。DistrDP的语义作用就是用∃y(y∏↓x∧P(y))或∀y(y∏↓x→P(y))来替换合取式中的P(x),即如果合取式有P(x),则DistrDP-∀表示:对于任意的y,如果y是↓x的构件,则y具有性质P;DistrDP-∃表示:至少存在一个y,y是↓x的构件,并且y具有性质P。
下面给出一些语义组合运算的范例,其中就包含了DistrDP:
①NP:“好学生”⇒σx*好'·*学生'(x)
②DP:“Ø好学生”⇒λxλP.∃y((y=x)∧P (y))(↑σx*好'·*学生'(x))=λP.∃y((y=↑σx*好'·*学生'(x))∧P(y))
③对DP应用DistrDP-∀得到QP:λP.∃y((y=↑x*好'·*学生'(x))∧∀u(u∏↓y→P(u)))
④对DP应用DistrDP-∃得到QP:λP.∃y((y=↑σx*好'·*学生'(x))∧∃u(u∏↓y∧P(u)))
⑤VP:睡觉⇒λx.睡觉'(x)
⑥S:“好学生睡觉了”⇒λP.∃y((y=↑σx*好'·*学生'(x))∧P(y))(λz.睡觉'(z))=∃y((y=↑σx*好'·*学生'(x))∧睡觉'(y))
⑦S:“好学生都睡觉了”⇒λP.∃y((y=↑σx*好'·*学生'(x))∧∀u(u∏↓y→P(u)))(λz.睡觉'(z))=∃y((y=↑σx*好'·*学生'(x))∧∀u(u∏↓y→睡觉'(u)))
⑧S:“有些好学生睡觉了”⇒λP.∃y((y=↑σx*好'·*学生'(x))∧∃u(u∏↓y∧P(u)))(λz.睡觉'(z))=∃y((y=↑σx*好'·*学生'(x))∧∃u(u∏↓y∧睡觉'(u)))
②中的DP直接投射成QP,然后直接与⑤运算,得到⑥,即“好学生睡觉了”的语义,①为了讨论不过于复杂,汉语分析均不考虑时态等因素。在模型中的解释:至少存在一个y,y的值与↑σx*好'·*学生'(x)的值相同,并且y∈‖睡觉'‖。这并不能保证↑σx*好'·*学生'(x)的生成集中的个体也属于‖睡觉'‖。“好学生都睡觉了”中多了一个“都”,②蒋严[8]和潘海华[9]均认为“都”只有一个意义,即全称量化,即总括义。包括“连…都”中的“甚至”义和所谓的表“已经”的意义,都是通过一定的句法和语用机制从总括义中推导出来的。这里只考虑基本意义,即直接对NP进行全称量化的“都”。③应用DistrDP-∀对“好学生”的语义进行全称量化得到QP,然后与⑤的组合运算得到⑦,其模型论解释为:↑σx*好'·*学生'(x)的生成集{u |u∈‖学生'‖∩‖好'‖}(‖睡觉'‖,即(σx*好'·*学生'(x)的生成集是‖睡觉'‖的子集。换句话说,{u|u∈‖学生'‖∩‖好'‖}中的任意个体都是‖睡觉'‖的成员,也就是从“学生都睡觉了”中可推导出“其中的任何一个学生都在睡觉”,但同样的推导在⑥中得不到。④对“好学生”的语义进行了DP存在量化得到QP,然后与⑤的组合运算得到⑧,在模型中的解释:↑σx*好'·*学生' (x)的生成集{u|u∈‖学生'‖∩‖好'‖}中,至少有一个成员属于‖睡觉'‖。
四、结束语
汉语是句法标记贫乏的语言,因此在做形式语义刻画时,需要做出一些特殊处理,如汉语照应算子处理,形容词性的谓语句等[10-11]。LCP将汉语NP的语义看成是集群,并用具有代数格结构的语义模型加以形式刻画,比较满意地表现了NP语义的逻辑蕴涵和推导。从国外的研究现状来看,具有代数格结构的语义模型是当代形式语义学研究语词指称意义的基础,如Landman对事件语义学的研究[6],Chierchia和 Fox对性质的研究[4,12]等。事实上,代数格结构的语义模型大大地提高了语义模型解释NL语义的能力,使得形式语义学对NL语义的研究,从仅验证句子的真值拓展到对语词指称意义的量化处理,并正在改变人们的一贯看法,即在研究NL的语义时,基于数理逻辑的形式语义学长于处理语句的真值意义,而短于处理词汇的指称意义。
[1]邹崇理.自然语言逻辑研究[M].北京:北京大学出版社,2000.
[2]Carlson.A united analysis of the English bare plural[J].Linguistics and Philosophy,1977(1):413-457.
[3]Link G.The Logical analysis of plurals and mass terms: A lattice-theoretical approach[C]//Bäuerle R,et al.Meaning,Use,and Interpretation of Language,Stanford: CSLI Publications,1998.
[4]Chierchia G.Reference to Kinds Across Languages[J].Natural Language Semantics,1998(6):339-405.
[5]Landman F.Group(I)&Group(II)[J].Linguistics and Philosophy,1989(12):559-605,723-744.
[6]Landman F.Events and Plurality:the Jerusalem Lectures[M].Kluwer Academic Publishers,2000.
[7]Link G.Algebraic Semantics in Language and Philosophy[M].Stanford:CSLI Publications.1998.
[8]蒋严.语用推理与“都”的句法/语义特征[J].现代外语,1998(1).
[9]潘海华.焦点、三分结构与汉语“都”的语义解释[C]//语言研究与探索(13).北京:商务印书馆,2006.
[10]张晓君,满海霞.带有受限缩并规则的兰贝克演算中的照应算子[J].重庆理工大学学报:社会科学,2011 (4):6-11.
[11]贾改琴.形容词性谓语句的逻辑语义分析[J].重庆理工大学学报:社会科学,2011(5):10-16.
[12]Fox C.The Ontology of Language:Properties,Individuals and Discourse[M].Stanford:CSLI Publications,2000.
Formal Semantic Model and Formalization of Chinese NP’s Reference
LI Ke-sheng
(Department of Foreign Languages,Hefei Normal University,Hefei 230061,China)
Chinese NPs are noted for their complex reference,which is likely to be ambiguous between singularity/plurality,general/specific reference,and universal/existential quantification,especially,when there is no syntactical marker.Considering the traditional semantic model is too simple to be adequate for the representation of Chinese NP’s reference,the paper constructs a semantic model with an algebraic structure,which,combing with the relevant operators working in the projection of NP to QP,offers a satisfactory representation of NP’s reference.
formal semantics;sum/group;composite NP;algebraic structure of semantics
H030;B81
A
1674-8425(2011)08-0053-08
2011-06-06
国家社科基金重大招标项目“自然语言信息处理的逻辑语义学研究”(10&ZD73)的阶段性成果之一;教育部社科基金资助项目“基于事件特征的连动式语义组合机制研究”(10YJC740058)的系列成果之一。
李可胜(1972—),男,安徽广德人,博士,副教授,研究方向:理论语言学、语言逻辑。
(责任编辑 魏艳君)
