数据挖掘在普通高校大学生体质健康数据中的应用
2011-10-26王晓贞
王晓贞
(中国矿业大学体育学院,江苏 徐州 221116)
理论与方法探索
数据挖掘在普通高校大学生体质健康数据中的应用
王晓贞
(中国矿业大学体育学院,江苏 徐州 221116)
本文运用数据挖掘技术中关联规则FP-growth算法,对普通高校大学生体质健康数据进行数据分析,利用最小支持度和最小置信度,挖掘出满足条件的频繁项集,从挖掘的规则中发现有价值的数据模式,找出我国不同地区大学生体质各项指标的等级分布情况,发现某地区大学生体质某项指标的不足,进而分析出其中的原因,为有效地提高学生的体质健康水平及体育教学的改革提供参考。
体质数据;数据挖掘;关联规则;普通高校;大学生
教育部于2002年7月正式颁布试行《大学生体质健康标准》(以下简称《标准》),开始对全国高校大学生进行“大学生体质健康”测试。《标准》实施几年来,大部分高校都有了较全面的体质数据的记录和统计,面对大量的数据,原来对体质数据进行均值分析或是套用规定的评价公式评价分析的数据库管理方式和数据统计方法已经逐渐不能适应“健康体育”的建设需求。如何从这些大量的数据中,深入寻找体质各项指标与其他各种因素间的相互联系,发现诸多因素之间的动态变化规律,从而对大学生体质数据进行深层分析,使之及时准确地提供有价值的信息成为我们研究的重点。本文运用数据挖掘技术对普通高校大学生体质健康测试数据进行分析,找出体质数据中有用的模式和规则,为有效地提高大学生体质健康水平和高校的体育教学改革提供参考。
1 数据挖掘介绍
1.1 数据挖掘的产生及涵义
数据挖掘(DataMining)简记为DM,就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据库或数据仓库中提取隐含的、先前未知的、对决策者有潜在价值的知识和规则。在1989年举行的第11届国际联合人工智能学术会议上,人们首次提出了基于数据库中知识技术,直到1995年,人们才在美国计算机年会上首次提出数据挖掘概念。
1.2 数据挖掘的模式和方法
数据挖掘通过预测未来趋势及行为,做出前瞻的、基于知识的决策。其挖掘的目标是从数据库中发现隐含的、有意义的知识模式。这些模式一般有两种,即信息型模式和预测型模式。信息型模式不是用来解决一个特定的问题,而是从数据库挖掘出某领域专家可能不知道的、有兴趣的知识模式,给这些专家提供一些建议,从而为决策提供指导。常用方法有聚类分析和关联分析等。预测型模式通常用来解决一个特定的问题,根据数据库中的已知的属性的值来预测另一些未知的属性值的分布,以此达到预测的目的。常用方法有回归分析、线性模型、关联规则、决策树预测、遗传算法、神经网络等。
1.3 数据挖掘的基本过程和步骤
数据挖掘是一个完整的过程,该过程从大型数据库中挖掘先前未知的、有效的、可实用的信息,并使用这些信息做出决策或丰富知识。其基本过程见图1。
数据挖掘的基本过程中各步骤的大体内容如下:(1)确定研究对象,清晰地定义出研究问题。(2)数据准备。①数据的选择。搜索所有与研究对象有关的内部和外部数据信息,并从中选择出适用于数据挖掘应用的数据。②数据预处理。研究数据的质量,将数据中哪些噪声数据、空缺数据和不一致数据清除掉,为进一步的分析做准备。③数据转换。将预处理后的数据进行规范化和聚集,转换成数据挖掘算法需要的格式。(3)数据挖掘。对所得到的经过转换后的数据运用合适的数据挖掘算法进行数据的挖掘。(4)结果分析。解释并评估结果,通常用可视化技术将挖掘结果以合适的形式提供给用户,让用户对模型结果做出解释。(5)知识的同化。将分析所得到的知识集成到业务信息系统的组织结构中去。

表1 示例数据库
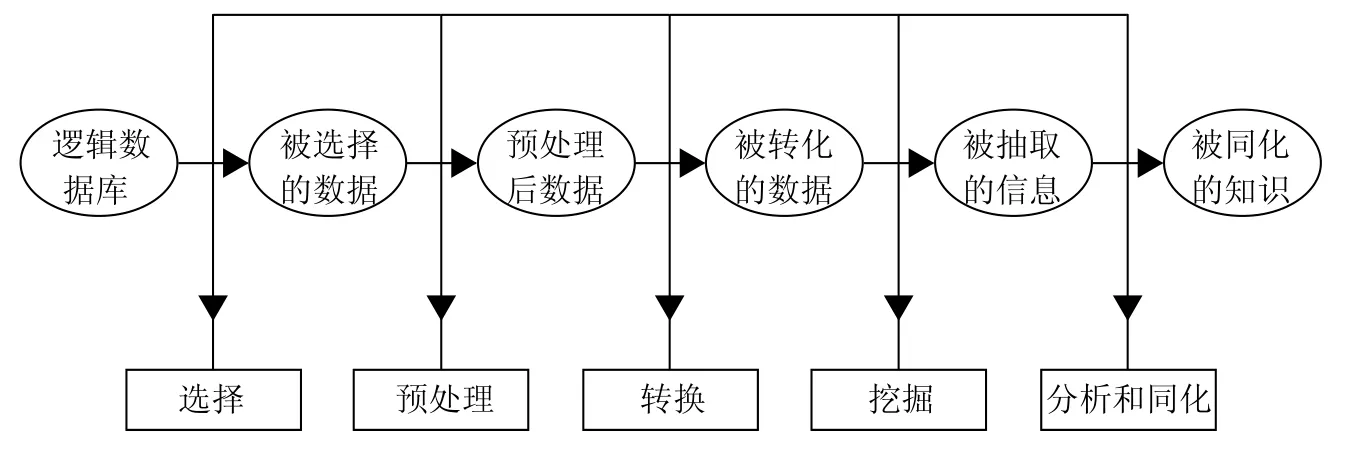
图1 数据挖掘的基本过程和步骤

表2 通过创建FP-Tree挖掘频繁模式
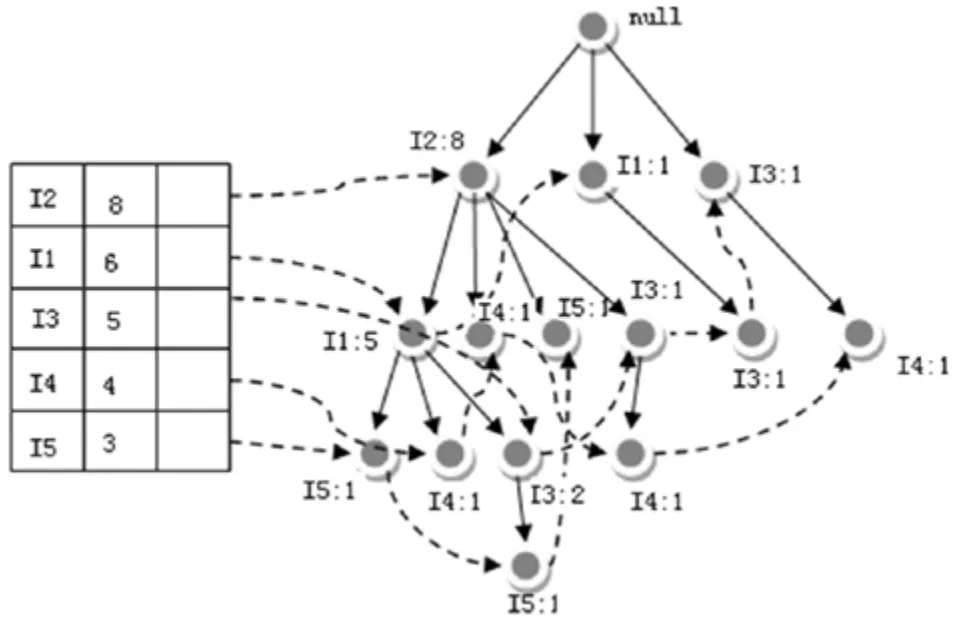
图2 FP-Tree结构图

表3 全国地区分布表

表4 导出的我国六大地区大学生体质各项指标的关联规则
2 基于关联规则普通高校大学生体质数据的挖掘
2.1 关联规则
关联规则的概念和模型是1993年Rakesh Agrawal等人提出的。关联规则挖掘是在大量的数据中发现数据项之间的关系,是当前数据挖掘研究的主要模式之一,它侧重于确定数据中不同领域之间的联系,找出满足事先给定支持度和可信度阈值的多个域之间的依赖关系。关联规则的挖掘问题可以分解成两个子问题:(1)找出所有频繁项集。这些项集出现的频率满足最小支持度min_sup,即这些项集在数据库中的频繁性不小于最小支持计数。(2)从频繁项目集合中生成所有置信度不小于用户定义的最小置信度min_conf的关联规则,即对于任一个频繁项目集F和F的所有非空真子集S,如果sup(F)/sup(F - S)≥ min_conf,则(F - S)S就是一条有效的关联规则。
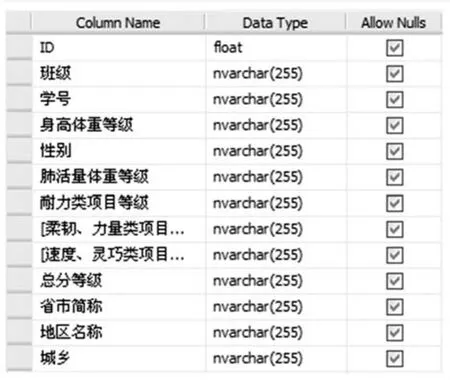
图3 体质健康数据表结构

图4 部分体质健康数据
经典的关联规则算法主要是Apriori和FP-Growth两种算法,其他关联规则的算法都是基于这两种算法的改进。Apriori算法是最早提出的关联规则算法,其优点是能够有效地产生出所有关联规则,存在的问题是Apriori算法对数据库扫描次数太多,产生的候选集过大,扫描数据库需要花费大量的时间。FP-growth算法一种挖掘频繁模式的有效算法。该算法的优点运行速度快,运行过程中只需要两次扫描数据库,第一次扫描数据库得到频繁1-项集;第二次扫描利用频繁1-项集过滤数据库中那些非频繁项,同时生成FP-tree。
FP-growth比Apriori算法相比要快一个数量级,特别是在数据项集大的情况下更显得效率高些。因此,本文选择使用的是一个基于FP-tree的频繁模式挖掘算法对普通高校大学生体质健康数据进行关联规则挖掘。
2.2 FP-Growth算法
频繁模式增长 FP-growth(frequent pattern-growth)算法是由 Han 等人于2000 年提出,该算法是一个具有影响力的频繁模式挖掘算法。算法只需扫描 2 次数据库,第一次扫描数据库,得到 1-频繁项集;第二次扫描数据库,利用 1-频繁项集过滤掉数据库中的非频繁项,同时生成 FP-tree。 由于 FP-tree 蕴涵了所有的频繁项集,随后的频繁项集的挖掘只需要在 FP-tree 上进行。整个挖掘过程由两个阶段组成,第一阶段建立 FP-tree,即将数据库中的事务构造成一棵 FP-tree;第二阶段为挖掘 FP-tree,即针对 FP-tree挖掘频繁模式和关联规则。(表1)
第一阶段,FP-tree 的创建。 图2描述了一个基于表 1 所示的示例数据库构造的FP-tree 的例子。
第二阶段,FP-tree 的挖掘。表 2 列举了图 2所示 FP-tree 挖掘的结果(最小支持度计数为 2)。
2.3 FP-growth 算法在普通高校大学生体质健康数据中的应用
2.3.1 挖掘前数据的准备本次挖掘的数据库中主要包含以下一些数据表,如学生来源信息表(学号、姓名、系别、班级、生源所在地、城乡)、学生体质测试成绩表(学号、姓名、性别、班级、身高、体重、肺活量、柔韧力量类项目成绩、速度灵巧类项目成绩和耐力类项目成绩)。全国地区分布表见表3。
2.3.2 使用关联规则算法 FP-growth 挖掘大学生体质数据主要过程
(1)数据的预处理。①数据的清洗:根据获取的原始数据的特点,体质测量数据中的身体情况异常的,如生病、受伤或身体残疾的学生的测试数据以及因事请假或无故缺测的学生,其数据值为空或是不完整数据,这些数据都将被视为噪声删除而被清理。②数据的消减:学生来源信息中只保留学号、性别、籍贯、城乡与挖掘分析相关的属性,学生体质表中有些属性重复反映身体素质的某些因素,我们将选择删除这些冗余的属性,如50米跑和立定跳远两项指标均反应的是学生下肢爆发力和身体的协调性,台阶实验和女生800米跑或男生1000米跑反应的是学生的心血管系统的机能和肌肉耐力水平,根据研究需要选择把反应各类素质的指标我们从中选择一项。最后消减后的数据有身高、体重、肺活量、立定跳远、台阶试验、握力、仰卧起坐7项指标。③数据的变换:根据大学生体质健康测试评分标准,我们将原学生体质表中的成绩先转换成得分然后再转化成相应的等级,每项指标的等级都分为优秀、良好、及格和不及格4个等级,使得每个数据指标对分析结果都具有相当的影响度,从而使数据挖掘的结果更加合理。另外,还要对某些指标进行组合。由于体质数据指标中有些指标是几个指标组合起来才有意义,因此要预先对一些指标进行组合。例如,将体重与握力指标组合在一起形成握力体重指数,肺活量与体重指标组合在一起形成肺活量体重指数,同样将所得指数转化成相应的等级。
(2)数据的挖掘。将 FP-growth 算法应用在普通高校大学生体质健康数据中,挖掘出大学生体质各项成绩的等级分布与地区之间隐含着的关联。
2.3.3 基于FP-Growth算法的体质健康数据关联规则挖掘的实现采用SQL Server2005作为后台数据库,经预处理以后,体质健康数据在数据库中的存储情况如图3和图4所示。
当取最小支持度(Min-sup)为0.10,最小置信度(Min-conf)为0.45时,通过FP-Growth算对普通高校大学生体质数据进行关联规则挖掘,得出我国六大地区大学生体质各项指标的关联规则见表4。
2.3.4 普通高校大学生体质健康数据挖掘结果分析从表4中1~6的6条规则我们可以看出,我国6大地区身高体重指数等级中正常体重的百分比的数值基本上都在45%~50%之间,说明我国大学生体质指标中身高体重等级的正常值相对较低。体质指标中身高体重的等级分为肥胖、超重、体重较低、营养不良、正常体重5个等级,除正常体重等级外,其他4个等级均属于不正常的等级。因此,从数据的挖掘结果来看,我国大学生的有近一半的学生出现体重指标不正常的现象,有的因体重过高出现肥胖或超重,有的体重过低而出现体重较低或营养不良。
身高、体重作为身体形态特征的两项重要基本指标,不仅反映了学生骨骼生长发育的基本特点,而且可以较为准确地反映学生生长发育水平。随着我国综合国力的提高,生活水平的普遍改善,如若不加以正确引导,热量、脂肪等会摄入过多及食物结构不合理,加之营养科学知识的宣传普及滞后,会导致学生肥胖和超重现象的发生。
另外,当前人们越来越注重体型,保持良好体型的观念已经深入人心。但由于受到女性“以瘦为美”审美观的影响,使得许多在校女大学生过分追求苗条的身材,有些甚至不吃早餐和节食,造成营养不良,从而体重较轻和营养不良的比例较高。而大多数男生则很少受到这种思想观念的影响,体重较轻的比例较小,但超重和肥胖率略高。因此,加强营养学知识的传授,特别是一日三餐营养的合理搭配,要引导学生培养良好的饮食习惯。
从规则7和8可以看出,华北地区和西北地区大学生速度、灵敏类等级不及格分别是69%和66%,这两条规则的置信度都较高,说明华北地区和西北地区大学生的速度、灵巧类素质相对于我国其他地区较差。测试速度、灵巧类素质我们所选的项目是立定跳远,立定跳远主要是测量向前跳跃时下肢肌肉的爆发力。力量(最大力量)在体育运动和日常生活中都是非常重要的身体素质。腿部的爆发力是以腿部力量为基础,没有力量就谈不上爆发力,也谈不上肌肉的耐力。立定跳远成绩较差的主要原因可能是我们的体育课教学中缺乏有针对性的下肢力量的练习或者在平时的体育锻炼中下肢练习不足。
规则9反应东北地区学生肺活量体重等级不及格的百分比达到63%,说明东北地区学生肺活量体重等级普遍低于我国其他地区。分析原因认为,可能与东北地区在校学生缺乏锻炼尤其是有氧运动有关,从而导致呼吸肌力量下降,呼吸机能的潜力减小,呼吸深度变浅。
规则10反应出东北地区大学生耐力类项目不及格者达61%。规则9和10的数据说明心肺机能对于肺活体重指数和台阶试验起着决定性的作用,当学生心肺机能较低时这两项指标的也会较低,两者之间有一定的相关性,而提高心肺机能最有效的锻炼就是进行有氧运动。因此,应注意加强有氧运动的练习,从而提高其心肺机能。
本文主要运用FP-Growth算法对普通高校大学生体质健康测试数据进行关联规则的挖掘,从大量的数据中我们得出我国普通高校大学生正常体重等级普通较低,各地区间没有明显差异,华北、西北地区学生下肢爆发力较差,东北地区学生心肺机能水平较其他地区低。这些有价值的规则和信息,对我们建立行之有效的体育教学改革思路提供参考依据。
[1] Fayyad U,Piatetsky-Shapiro G,Smyth P. the KDD process for extracting useful knowledge from volumes of data [J].Communications of the ACM,1996,39(11):27-34.
[2] Jiawei Han,Micheline Kambr.Data Mining Concepts and Techniques [M].San Francisco:Morgan Kaufmann Publishers,2000.
[3] 陈文伟.数据仓库与数据挖掘教程[M].北京:清华大学出版社,2006.
G807.4
A
1674-151X(2011)05-109-04
10.3969/j.issn.1674-151x.2011.05.053
投稿日期:2010-11-17
王晓贞(1970 ~),副教授,硕士研究生导师。研究方向:体育教育训练学和体育社会学。
