逻辑斯特模型在社会学量化研究中的应用
2011-10-18储庆罗强强
储庆,罗强强
(1.中央民族大学民族学与社会学学院,北京100081;2.安庆师范学院,安徽安庆246133)
逻辑斯特模型在社会学量化研究中的应用
储庆1,2,罗强强1
(1.中央民族大学民族学与社会学学院,北京100081;2.安庆师范学院,安徽安庆246133)
随着对社会科学研究科学性要求的不断提高,越来越多的学者开始使用量化方法进行社会科学研究。从发表于国内学术杂志的一些量化研究文章来看,存在着诸多对量化研究的误解和一些对统计模型使用和解释上的偏差。文章以社会科学研究中最为常用模型—逻辑斯特模型为例,详细解析了模型使用前提和参数意义,避免了科学方法的误用。
科学方法;线性回归;逻辑斯特;社会学
纵观社会学学科重建30年来的发展,可以看出社会学研究中的科学性在不断加强,尤其是从近七、八年来发表在《中国社会科学》、《社会学研究》中的社会学论文更可以看出这一明显的趋势。虽然很多研究者在实际研究中使用的一些统计模型,但是仔细研读这些论文,还是会发现很多作者对一些模型的前提假设并不甚了解,对一些模型参数的实质意义与统计意义的区分比较模糊,这样导致一些明显有误的解释。本文将以在社会学量化研究中最为常用的模型之一逻辑斯特(Logistic)模型为例,系统分析社会学量化研究中模型使用的前提和参数的实际意义,避免科学方法的误用。
1 线性回归模型的回顾
1.1 线性回归模型的基本假定
回归分析是一种利用两个变量或几个变量之间的关系,从而一个变量(因变量、响应变量、结果变量)能被另一个或几个变量(自变量、解释变量、预测变量)所预测。线性回归就是用一条直线来拟合一个变量与另一个或几个变量之间的关系。线性回归分析也是对数据的一种简化。在线性回归分析中,研究者利用自变量的一个线性函数来尽可能地预测因变量的一批观测值。显而易见,这种预测不可能完全准确。从形式上看,回归分析将观测值分解为两个部分[1]:
因变量的实际观测值=回归线性方程所解释的部分+随机部分
回归线性方程解释的部分是研究者认为自变量与因变量之间存在的结构关系,随机部分包括现有方程中未能包括的其它结构关系、测量误差和“噪音”。对于个观测值有:
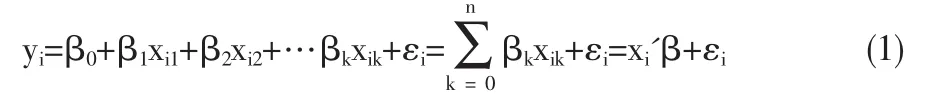
对于方程(1)来说,xiβ相当于回归线性方程所解释的部分,亦即研究者假设的自变量与因变量的结构关系,εi为随机部分。方程(1)是对所有观测值的完全拟合,而研究者的目的在于对复杂社会现象的简化,因此方程(1)只有理论意义,而无实际意义。
对于实际研究来说,不是预测具体的个观测值,而是对一定条件下yi均值的预测,即E(y|xi)。为了简化模型,必须对(1)式进行一些必要限制。
(1)随机部分的期望为零,即E(εi)=0;
(2)随机部分的协方差为零,即Cov(εi,εj)=0,i≠j;
(3)随机部分等方差,即Var(εi)=σ2;
(4)随机部分服从正态分布,即εi~N(0,σ2)。
在上述四项假定的情况下,我们可以得到关于E(y|xi)数学方程式:
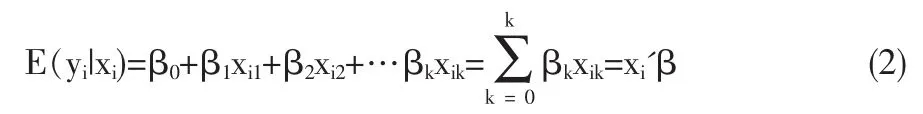
由于因变量Y是随机变量εi的线性函数,因此对εi的基本假定均适用于Y,只是Y的均值和方差与εi不一样而已。
1.2 线性回归模型的局限
线性回归模型以其简洁性和解释的方便性,在实际生产生活中有着广泛的应用。利用线性回归分析,可以对数据进行描述,对生产过程进行控制和预测。在应用线性回归模型时,研究者应对线性回归模型的假定条件保持足够警醒。现实中的大多时候研究不能直接应用线性回归模型,需要对数据进行一定的变换。实际研究中,线性回归模型的局限性主要表现在两个方面。
(1)模型的基本假定不足
线性回归模型最为基本的前提条件就是因变量与自变量之间的关系是线性。这一点在社会科学中不一定满足。比如工作年限对收入的影响就不是线性,刚工作时收入会随着工作年限的增长而增加,但到一定工作年限后收入会随着年龄的增长而下降,这是一个二次曲线关系。线性回归模型还假定因变量(也即残差)之间互相独立,且服从同一分布。在实际社会现象中,这项假定中的一项或几项常常不满足。比如社会科学中最为常见的收入变量,显而易见的是刚开始参加工作的时候人们之间的收入差异比较小,工作一定年限后人们之间的收入差异会加大——收入作为因变量不符合等方差的假设。遇到类似不符合线性回归模型基本假定的时候,处理的思路有二:一是采用其它模型拟合数据;二是通过对数据进行适当的转换,以使其符合线性回归模型的基本假定。由于线性回归模型具有的简洁性和解释的便利性,在可能的情况下,研究者都是采用后一种处理策略。比如对第一种情况,可以在工作年限变量上加上二次项,对于后一种情况,可以对收入取对数。如设收入为因变量y,工作年限为自变量x,若直接应用线性回归有:

显然(3)式不符合线性回归的基本假定,为使其符合线性假定,作如下变换有:

令y'=1ny,x1=x,x2=x2,则有:

式(5)即是标准的线性回归方程。
(2)与社会现象的实际状况不符
所谓与社会现象的实际状况不符常常是与线性回归模型的基本假定不符联系在一起的。这种与社会现实状况的不符,正是社会科学研究中广泛采用Logistic模型的原因之一。由线性回归方程可以看出,对因变量Y的取值没有任何限制,即Y的取值区间在[-∞,+∞]。但是,研究者所关注的一些社会现象常常是“是”和“否”的问题,即0和1变量。比如研究人们的婚姻意愿,研究者关心的结果只有两个取值:结婚和不结婚。在此情况下,若强行应用线性回归模型,有可能使因变量取值超出[0,1]的取值区间,没有实际意义。面对这种情况,同样有两种方式出来:一是换模型,二是进行数据转换。社会学研究中,最为常用的是进行逻辑斯特(Logit)转换。
2 逻辑斯特(Logistic)回归模型
Logit模型广泛应用于社会科学和生物科学中,在人口学和流行病学研究时,对某一因素对某些结果的相对风险的评估中尤其有用。逻辑斯特转换可以解释为成功对失败之发生比的对数,下面将从最简单的二分类变量开始对这一模型进行探讨。
2.1 二分类变量的逻辑斯特回归模型
2.1.1 Logit转换
在社会科学研究中,研究者面对的因变量很多时候是分类变量。最常见的分类变量就是二分类变量,又称(0,1)变量。习惯上二分类变量的结果通常被描述为成功或失败,比如一个高中毕业生能否上大学:上大学了就是成功,赋值为1,未能上大学认为是失败,赋值为0。对于二分类因变量,研究者的目标是以一组自变量为条件来估计或预测成功或失败的概率。这样问题就转化为,对概率p的回归分析。
由于概率取值区间是[0,1],因此直接对概率进行线性回归肯定不合适。这就要求能通过某种方式,对概率p进行转换,使得转换后的一个关于概率p的函数符合线性回归的基本假定,从而进行(广义)线性回归分析。Logitic回归模型就是对概率p进行Logit转换,转换的公式为:

公式(6)可以看作广义线性模型框架内的一个链接函数,得到的Logti模型为:

对(7)式进行变换,即可得到概率p:
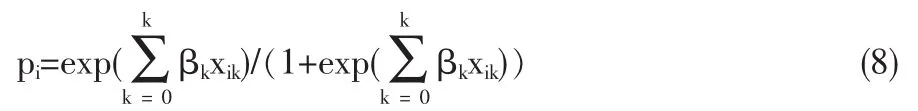
经过Logit转换后,对于x和β的所有可能取值,概率p始终在区间[0,1]内。随着p接近0,Logit(p)趋近于-∞;随着p接近1,Logit(p)趋近于+∞。使用一般化线性模型理论的术语,则Logit链接使模型在未知参数上呈现线性形式。
2.1.2 比数、比数比和相对风险
从一般线性回归模型的角度来思考,则得到事件的概率即8式后,似乎研究者的工作已经结束。Logistic回归模型之所以在社会科学得到非常广泛的应用,一个重要的原因在于logit(p)可以很容易的扩展为用来描述某一群体相对于另一群体的成功的比数之比。
⑴比数
在社会科学研究中,研究的兴趣可能并不主要在于事件发生的概率。比如还以前述上大学为例,研究的目的不在于一个人上大学的概率是多少,更令人感兴趣的问题时上大学与不上大学的两组人之间比较。上大学与不上大学的概率比为pi/(1-pi),由1.6式可知,这恰好是logit转换。比数定义为一个结果的概率对另一个结果的概率之比,公式为:

⑵比数比
线性回归模型的目的是在于用自变量来预测因变脸。线性回归模型得到极大的采用,就在于回归系数解释的简洁性和实质性意义:在保持其它自变量不变的情况下,回归系数代表某一自变量增加一个单位因变量的增加量。Logistic回归模型中的系数是否也具有类似的意义呢?
假设要研究性别与个人是否上大学的关系,Logit模型如下:
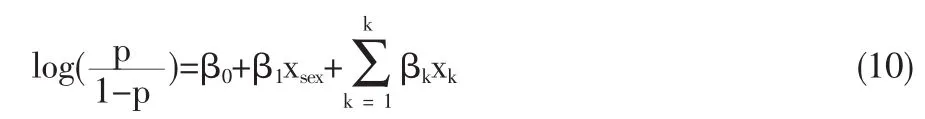
p为上大学的概率,xsex为性别,男性=1,女性=0,βkxk为其它控制变量。
研究者关注的是男女两性在上大学这一事件上是否有差异。分别令xsex=0和1,可以得到关于男性和女性上大学的对数比数的线性回归方程:

为得到男性与女性上大学的差异,将(12)式减去(11)式,有:

对(13)式进行变换:
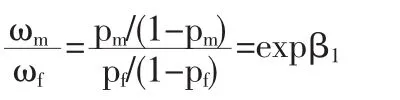
ωm/ωf即为比数比,比数比具有与线性回归系数类似的意义:在保持其它变量不变的情况下,男性上大学的比数是女性上大学的比数的expβ1倍。
⑶相对风险
比数比是与相对风险概念密切联系在一起,从理解上来说,相对风险的概念要比比数比的概念更为直观,更容易理解。风险是指在一定时间间隔内(通常称之为暴露期——explore)的概率。比如,假设100个人抽烟的人处在患肺癌的风险之中,观察10年,发现有15人得了癌症,则风险是15/ 100,或0.15。假定要研究抽烟与肺癌之间的关系,前述观察的100人均分为两组,结果发现控制组(戒烟)得肺癌的有5人,实验组(不戒烟)得肺癌的10人,则可以两组患肺癌的相对风险为:
若以前述的比数比的概念构造,则为:

事件发生的概率很小的时候,即r戒烟→0,r不戒烟→0,比数比将非常接近于相对风险。而在生物统计学和流行病学中的患病研究时,患病率一般来说都是非常小的,因此比数比的概念得到了广泛的应用。对于社会科学的研究者来说,弄清楚相对风险的概念,有益于加深对比数比涵义的理解。
2.2 多项逻辑斯特回归模型
前面讨论的只是二分类变量的Logit模型,从思路来说很容易将之扩展到一般分类变量(分类类别≥3)的情况,需要注意是,当涉及到3个或以上的分类时,需要考虑这些类别之间是否包含序次信息。
2.2.1 多分类定类变量的Logit回归模型
假设因变量分为三个类别,三个类别的概率分别记为:p1,p2,p3。与二分类变量略微不同的是,对于多分类变量,研究者需要先确定一个参照组。为不失一般性,这里制定第一类别为参照组。则可以建立多项逻辑斯特回归模型:

系数的解释与二分类变量类似,只是此事的比数比是相对于参照组的比数比。
2.2.2 多分类定序变量的Logit回归模型
当分类变量是定序变量时,当然也可以不考虑其包好的次序信息,直接应用上述定类变量的Logit回归模型。考虑变量自身的次序信息后,可以有三中稍微不同的处理方式。
⑴基线Logit模型
基线Logit模型实质与定类的Logit模型一样,只是在选择参考类别时,会考虑到序次信息,一般选择最低或最高序次作为参照。
⑵相邻Logit模型
相邻Logit模型的基本想法是比较一对相邻的类别,一般式可以表达为:
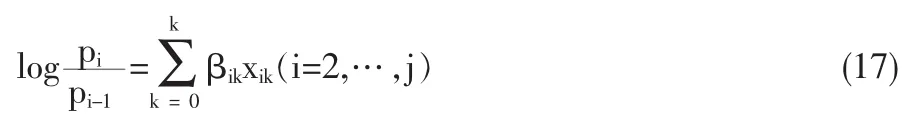
⑶累积Logit模型
累积Logit模型是用累积概率来计算比数,以某一类别为分界点,计算其上的概率与其下的概率的比率,一般表达式为:

3 小结
以上只是从便于理解和实际应用的角度,对逻辑斯特模型在社会学量化研究中的分析。在分析的过程中,笔者的分析始终围绕两方面来进行。第一,构建模型的目的是什么,或者说模型的适用范围是什么?第二,这一模型解决问题的基本思路是什么?至于模型背后复杂的数学推导过程,则不在本文论述之列。这两点本质上也是对利用模型进行量化研究的研究者的根本要求。研究者只有明了模型前提条件和基本思路,才能在实际科学研究中应用自如。否则,只能是照猫画虎,得出一些令人啼笑皆非的所谓研究发现。
在终极的分析中,一切知识都是历史;在抽象的意义下,一切的科学都是数学;在理性的基础上,所有的判断都是统计学(C.R.劳,2004:2)。不仅是社会学的量化研究,可以说所有的科学研究,在其最为本质的意义上都是对复杂的社会现象进行简化和抽象。因此,在构建模型的时候,不能本末倒置:社会现象本身是“本”,模型是“末”。换句话说就是,模型只是对现有观测数据的一种拟合——即使模型对数据完全拟合,也可能该模型是对现象本身的歪曲。
[1][美]丹尼尔·A.鲍威斯(Daniel A.Powers),谢宇[M].分类数据分析的统计方法,2009.
[2]郭志刚主编.社会统计分析方法——SPSS软件应用[M].北京:中国人民大学出版社,1999.
[3]王济川,郭志刚.Logistic回归模型:方法与应用[M].北京:高等教育出版社,2001.
[4][美]C.R.劳.统计与真理——怎样运用偶然性[M].北京:科学出版社,2004.
[5]王静龙,梁小筠编著.定性数据统计分析[M].北京:中国统计出版社,2008.
[6]张尧庭等编著.定性资料的统计分析[M].广西师范大学出版社,1991.
[7]Darrell Huff.How to Lie with Statistic[M].New York:W.W.Noton &Compand,1993.
[8]Kutner.AppliedLinearRegressionModels(4thEdition)[M].New York:McGraw-Hill Companies,2004.
(责任编辑/浩天)
C91
A
1002-6487(2011)05-0023-03
教育部人文社会科学研究资助项目(09YJC850006)
储庆(1981-),男,安徽岳西人,博士生,研究方向:社会学理论与方法。
罗强强(1981-),男,宁夏西吉人,博士生,研究方向:环境社会学。
