基于GPU的数学形态学运算并行加速研究
2011-10-09邢同举
张 聪,邢同举,罗 颖,张 静,孙 强
(电子科技大学 光电信息学院,四川 成都 610054)
数学形态学的应用几乎遍及计算机图形图像处理的所有方面,包括图像滤波、图像分割分类、图像测量、模式识别以及纹理分析与合成,其应用还涉及遥感监测、工业自动化检测测量、生物医学影像、图像压缩、军事、航空航天等众多领域。在运用数学形态学处理气象预报、工程计算和模拟等问题时,需要对巨大数据量进行多次重复计算,这些计算又必须在有限的时间内完成,比如在几秒或几分钟内完成。这就对数学形态学在处理这些问题时的运算速度提出了较高的要求。在数学形态学中,腐蚀和膨胀是最基本的两个运算,这两种对偶运算好比形态学字母表中的字母,其他运算都可以根据这两种运算表述[1],因此形态学处理速度决定于膨胀、腐蚀处理速度。
人们通过在腐蚀、膨胀处理中采用改进算法来提高其运算速度[2],但其速度也只能提高几倍,这在某些大数据量、实时性要求较高的应用中仍不能满足需要。针对这种情况,文章中提出了通过图形处理器(GPU)并行处理的方式对数学形态学运算进行加速。实验结果表明,通过GPU对数学形态学运算进行加速,其运算速度可达到1~2个数量级的提高。
1 膨胀腐蚀的基本理论
正文内容腐蚀运算:构造一个结构元素,结构元素的原点定位于待处理的目标元素上,结构元素完全包含在目标区域中时,则结构元素的原点所对应的目标像素点被保留,负责被腐蚀掉,置为背景点。膨胀运算:构造一个结构元素,结构元素的原点定位在待处理的目标元素上,当有目标点被结构元素覆盖时该点被膨胀为目标点。
膨胀腐蚀运算中存在一些重要的运算性质,在设计算法时使用这些性质往往能简化处理过程和提高运算速度。对偶性便是其中的一个重要性质,对偶性可用下面公式来表示:(XΘB)C=XC⊕B;(X⊕B)C=XCΘB。 这两个公式表明,图像膨胀等价于该图像的补被相同结构元素腐蚀所得结果的补,反之亦然[3]。在本文中讨论主要集中在腐蚀运算的并行加速,而膨胀运算可以通过待处理图像补的腐蚀运算求得。
2 GPU简介
2.1 GPU硬件架构
与CPU相比,GPU有着很高的计算吞吐量,这主要在于GPU和CPU不同的设计理念。GPU最初设计就是为了图形处理,由于图像渲染的高度并行性,GPU设计者通过增加数学逻辑单元(ALU)和控制单元(Control)的方式提高处理能力和存储器带宽。这样就在GPU硬件架构中形成了众多的流处理器,Nvidia GTX 280的架构[4]如图1所示。
图1中:Nvidia GTX 280中有30个完整前端流多处理器(SM),每个流多处理器包含8个流处理器(SP)。每个SP又可看成一个SIMD处理器。每个SM拥有独立的完整前端,包括取指、译码、发射和执行单元等,但每两个SM共享一条存储器流水线。SP不具有独立的处理器核,它们有独立的寄存器和指令指针,但没有取指和调度单元构成的完整前端。

图1 Nvidia GTX 280架构Fig.1 Nvidia GTX 280 architecture
2.2 CUDA软件开发环境
由于GPU具有很高的计算吞吐量,利用GPU进行通用计算已经引起了人们的关注[5-8]。CUDA架构正是专门为了GPU通用计算而设计的一种全新模块,它使得开发人员无需再过多地考虑严格的资源限制和编程限制。CUDA C是在CUDA GPU上的编程语言,CUDA C语言本质上是对C的简单扩展,它的出现使得开发人员不需要学习计算机图形学和着色语言,就可以编写出高效的GPU并行程序。
CUDA 编程模型[9]将 CPU 作为主机(Host),GPU 作为设备(Device)[10]。在这个模型中GPU和CPU协同工作,CPU上负责逻辑性较强的事务处理和串行计算,GPU则专注于执行高度并行化处理任务。运行在GPU上的CUDA函数称为内核函数(kernel),一个完整的CUDA程序是由Host串行代码和Device上的kernel函数共同组成的,如图2所示。
运行在设备上的kernel函数定义和普通C语言函数基本一致,当需要被主机调用时,只需在函数定义前面加上__global__修饰符__global__void Copy(char*src, char*dst)。在主机调用kernel函数时,需要传递额外的参数,如:Copy<<<blocksPerGrid, threadsPerBlock>>>(ptr_src, ptr_dst)。kernel函数是以线程网格(Grid)的形式组织的,每个Grid由若干个线程块(block)组成,每个block由若干线程(thread)组成。调用kernel函数所需传递的额外参数blocksPerGrid和threadsPerBlock分别是Grid和block的维度设计。
3 基于GPU的腐蚀运算加速实现
图像腐蚀采用(2n+1)×(2n+1)且系数全为 1的模板,即进行n尺寸腐蚀。要确定某一像素点是否被腐蚀掉,只需将模板中心对准当前待处理像素点,查看被模板覆盖的所有像素点,如果全为目标点则当前待处理像素点保留为目标点,否则腐蚀掉。腐蚀可进一步转化为邻域像素点灰度值求和的问题,每一个像素点都由被模板覆盖所有像素点灰度值的和决定。由此,确定每一点是否被腐蚀掉,所要执行的操作是相同的,只是所处理的数据不同而已。这是典型的单指令多数据问题,具有很好的并行性。
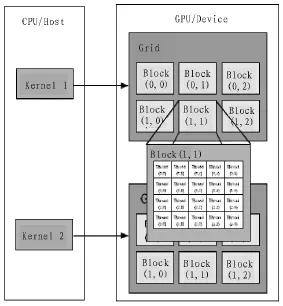
图2 CUDA编程模型Fig.2 CUDA programming structure
3.1 实现时需要注意问题
在GPU上编码实现腐蚀运算时,为了正确地执行和尽可能地提高执行效率需要注意几个问题:1)避免当前处理的像素点被已处理像素点所干扰。在具体实现时,生成一幅和原图同样大小的新图,每个线程将处理结果存放在这幅新图中,而运算数据则从原图中获取;2)充分利用GPU硬件资源,尽可能为每个像素点都开辟一个线程,目前GPU每个block允许开辟的线程数量已达到1 024个,每个Grid允许每一维开辟的block数量为65 535。所以对几乎所有的二值图像,都能实现为每一个像素点开辟一个线程;3)腐蚀运算访问内存模式具有很强的空间局部性,GPU纹理缓存是专门为了加速这种访问模式而设计的,在这种内存访问模式下,使用纹理内存能减少内存流量是性能得到提高。4)block维度设计时,每个block的线程数量应该为64的倍数[11],这样GPU的性能才能最大限度地提高。
3.2 实现过程
上面已经提到CUDA编程模型是GPU和CPU协同工作的,所以GPU腐蚀运算的实现过程是CPU和GPU共同完成的。CPU负责内存分配、Grid和block的维度设定、启动在GPU上运行的kernel函数并向其传递参数、最后从GPU获取处理结果。GPU负责大量并行运算,并将处理数据保存下来。其具体显现步骤如下:
1)读取待处理图像,根据图像大小在device上开辟显存devSrc,并将图像数据复制到这块显存上,并将其绑定二维纹理内存;
2)在device开辟和devSrc同样大小的显存devDst,用于GPU保存处理结果。在host上开辟和devDst同样大小的内存hostDst,用于接收GPU处理的结果;
3)根据待处理图像大小,设计grid和block的维度。为了提高性能将 block 维度固定为 dim3 blockDim(16,16),则 grid的维度则根据图像宽度width、高度height和block的维度设定,可设定为 dim3 gridDim( (width+15)/16,(height+15)/16);
4)启动kernel函数,并将设定好的参数传递到kernel函数中;
5)kernel函数执行完毕,将处理结果传回host。host保存并显示结果。
4 实验结果及分析
文章所采用实验平台为:Interl(R)Xeon(R)CPU 5160,主频 2.99 GHz,Windows7操作系统,显卡为 GForce GTX 570。文章中所处理的为 1 024×1 024、7 350×5 700 的图像。表格1为在对大小为1 024×1 024的图像进行不同尺寸腐蚀运算时,CPU串行腐蚀和GPU并行腐蚀所耗用时间对比。
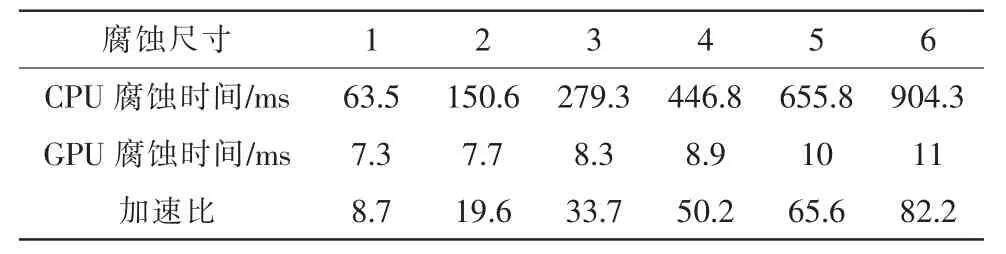
表1 在不同腐蚀尺寸下CPU和GPU腐蚀时间对比Tab.1 The comparison of the erosion time between CPU and GPU in different erosion sizes
从表格1中可看出,随着腐蚀尺寸的增大,即随着运算时间复杂度的增加,CPU串行腐蚀运算所耗用时间大幅度增加,GPU并行腐蚀运算所耗用时间没有大幅增加,GPU并行运算加速比越来越大。
在图3中,可以看到在对图像进行同一腐蚀尺寸的腐蚀处理时,GPU腐蚀处理大小为7 350×5 700的图像比处理1 024×1 024的图像加速比要高。当腐蚀尺寸增加到6时,对于1 024×1 024的图像加速比可达到 80左右,对于7 350×5 700的图像加速比可达150左右。GPU并行运算之所以有这么高的加速效果,主要因为它有如此多的数学逻辑单元,所以能同时运行较多的线程。它通过大量线程的切换来隐藏访存延迟,当某个线程被阻塞了,马上切换到其他线程进行处理,所以当待处理数据规模越大时,GPU资源就越能被充分利用,加速效果就更好。
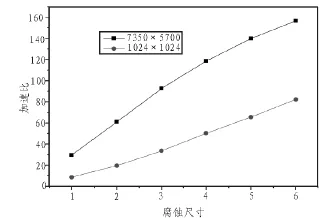
图3 对不同大小图片,GPU加速比随着腐蚀尺寸的变化而变化Fig.3 In different size of images,the speedup of GPU changes when the erosion size changes
5 结 论
通过GPU并行处理的方式,使形态学运算速度大幅提高。实验结果表明,随着待处理数据规模的增加和处理复杂度的增加,GPU并行腐蚀运算的加速效果显著增加。在本实验平台上GPU并行腐蚀运算可达到150倍的性能提升,目前,还未见任何优化算法达到如此高的加速效果的报道。本文还在支持CUDA的较低档的型号为GT220的显卡上进行了测试,在其上进行并行腐蚀运算也可达到10倍以上的性能提升。可见,在数学形态学运算时,同时考虑性能和成本两方面,GPU相对于CPU都有绝对的优势[12]。所以,在涉及数学形态学运算的领域,GPU并行运算是一个必然趋势。
[1]Solille P.形态学图像分析原理与应用[M].北京:清华大学出版社,2008:47-48.
[2]陆宗骐,朱煜.数学形态学腐蚀膨胀运算的快速算法[C]//第十三届全国图象图形学学术会议,2006-11-06,2006:306-311.
[3]孙即祥.图像分析[M].北京:科学出版社,2005:183-184.
[4]Garland M,Grand S L,Nickolls J,et al.Parallel computing experiences with CUDA[J].Micro,IEEE,2008,28(4):13-27.
[5]Nickolls J,Dally W J.The GPU computing era[J].IEEE Micro,2010,30(2):56-69.
[6]Hawick K A,Leist A,Playne D P.Parallel graph component labelling with GPUs and CUDA[J].Parallel Computing,2010,36(12):655-678.
[7]Ufimtsev J S,Schulten K.GPU-accelerated molecular modeling coming of age[J].Journal of Molecular and Modelling,2010,29(2):116-125.
[8]吴恩华,柳有权.基于图形处理器(GPU)的通用计算[J].计算机辅助设计与图形学学报,2004, 16(5):601-612.
WU En-hua,LIU You-quan.General purpose computation on GPU[J].Journal of Computer-aided Design& Computer Graphics, 2004, 16(5):601-612.
[9]Harish P,Narayanan P J.Accelerating large graph algrithms on the GPU using CUDA[J].Computer Science,2007(4873):197-208.
[10]NVIDIA Corporation,NVIDIA C 3.1,NVIDIA CUDAC Programming Guid Version 3.1[S].2010.
[11]左颢睿,张启衡,徐勇,等.基于GPU的快速Sobel边缘检测算法[J].光电工程,2009, 36(1):8-12.
ZUO Hao-rui, ZHANG Qi-heng, XU Yong, et al.Fast sobel edge detection algorithm based on GPU[J].Opto-electronic Engineering, 2009, 36(1):8-12.
[12]Seung I P,Ponce S P,HUANG Jing,et al.Low-cost,highspeed computer vision using NVIDIA's CUDA architecture[C]//2008 37th IEEE Applied Imagery Pattern Recognition Workshop,2008:1-7.
