基于多小波变换的文本图像文种识别
2011-10-09顾立娟刘才斌郝玉保
顾立娟,刘才斌,吴 勇,郝玉保
(1.武汉军械士官学校 湖北 武汉 430075;2.75719部队 湖北 武汉 430074)
文本图像文字种类的自动识别是对以图像形式呈现、由不同语言文字构成的文本图像,提取能用于计算机识别的底层特征,实现语言文字种类的识别和分类。在海量信息处理中,作为文本图像分析的重要组成部分和OCR系统的前端处理技术,文本图像的语言文字种类识别成为海量信息处理中面临的一个基本的研究课题。
目前,针对语言文字种类识别进行的研究可以划分为基于统计特征、基于符号匹配和基于纹理特征的文种识别3大类。基于统计特征和符号匹配的文种识别算法具有较高的识别准确率,但对文本图像的倾斜、噪声等鲁棒性比较差。基于纹理特征的文种识别算法提高了对图像质量退化的鲁棒性,逐渐成为研究重点。目前的算法主要有基于Gabor滤波器法[1]和基于小波变换法[2]基于灰度级共生矩阵法[3]及基于小波变换的共生矩阵法[3]。Gabor滤波具有旋转不变性,文种识别率较高,但是计算量很大;小波变换存在快速算法,大大减小了计算量,但识别率不高。
针对目前文本图像文种识别方法存在的一些问题,本文提出了一种基于多小波变换的文本图像文种识别方法。多小波[4-6]是多个尺度函数构成的小波,既保持了传统小波良好的时域与频域的局部化特性,又将光滑性、紧支性、对称性、正交性完美地结合在一起,更适合于提取图像的纹理特征。本文采用多小波变换提取文本图像的纹理特征进行文种识别,在2个不同质量的图像库上进行的实验结果表明,该算法对多文种的识别非常有效并对图像质量退化具有很强的鲁棒性。
1 多小波变换原理
所谓多小波是指小波函数的构造是由多个尺度函数完成的。为了与多小波相区别,称传统小波为单小波。
令 φ=(φ1,φ2,…,φr)T和 ψ=(ψ1,ψ2,…,ψr)T分别为 r阶多小波的多尺度函数和多小波函数。类似于单尺度情况,φ和ψ满足双尺度方程:

其中,矩阵Hk为低通矩阵滤波器,Gk为高通矩阵滤波器。
多小波的分解和重构算法为:
分解过程:
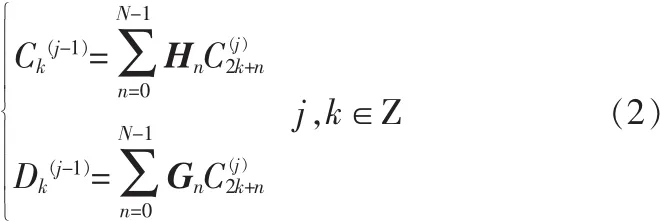
合成过程:
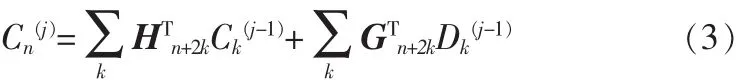
多小波有r个尺度函数,变换后每个子带有r×r个子图,而单小波只有一个尺度函数,变换后的每个子带只有一个子图。容易证明,L级多小波变换将图像分解为r2×(3L+1)个子图。例如:当L=1时,双小波分解每个子带有16个子图数,而单小波只有4个。
多小波与单小波本质上是一致的,但多小波变换是采用向量滤波器组来实现的。为了解决输入数据矢量化问题,首先要对信号进行预处理,即在多小波变换前,采用预处理方法矢量化初始数据,使其进入塔式算法的输入变为r维数据。然后通过r×r的预滤波器Q(w),获得用于多小波分解的初始矢量信号Ck(0),再进行多小波分解。图1所示为多小波的分解过程。

图1 多小波分解过程结构图Fig.1 Chart of multi-wavelet decomposition process
由于多小波由多个尺度函数构成,所以多小波函数的设计具有更大的灵活性。这样构造出的多小波既可以保持单小波的时频域局部化特性,又能克服单小波的缺陷,可同时具有正交、对称、短紧支撑和高阶消失矩等优良特性。在处理文本图像中的文字信号时,正交性可保持能量,对称性既适合于人眼的视觉系统,又使信号在边界易于处理,所以本文采用多小波变换提取文本图像的纹理特征进行文种识别。
2 基于多小波变换的文种识别
2.1 多小波变换纹理特征提取
一幅图像 f(m,n),大小为 N×N,其平均能量定义为:

不同的文本图像有不同的平均能量,进行多小波变换之前,对各个文本图像的能量进行归一化:

本文选择2个尺度函数构成的多小波来对g(m,n)进行分解。多小波函数采用'bigm2'双正交多重小波,预处理采用双正交插值预滤波方法,对图像进行两级多小波分解,得到24个细节子图,4个逼近子图。图2为图像的两级多小波分解示意图。
鉴于文本图像的文字笔画在各个方向、各个频率的能量分布存在差异,本文计算多小波两级分解得到的24个细节子图的能量均值和标准差作为特征:

图2 图像两级多小波分解示意图Fig.2 Schematic diagram of image two levels multi-wavelet decomposition
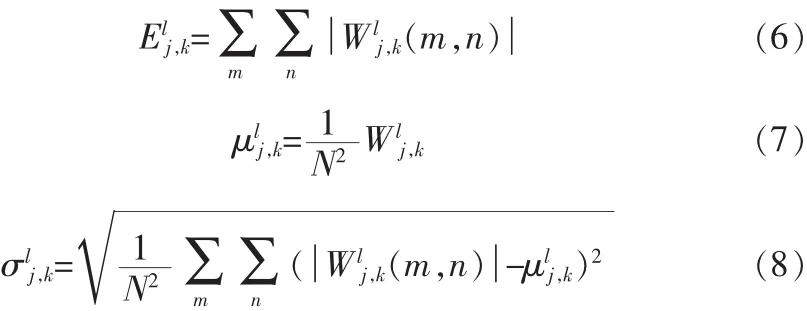
其中 Wlj,k为细节子图;l=1,2,3,4, 表示每级分解同一个方向上的 4 个细节子图;j=1,2,表示分解级数;k=1,2,3,分别代表H,V,D 3个方向,N为图像尺寸。
据式(6)~(8)计算得到48维多小波能量统计纹理特征矢量:
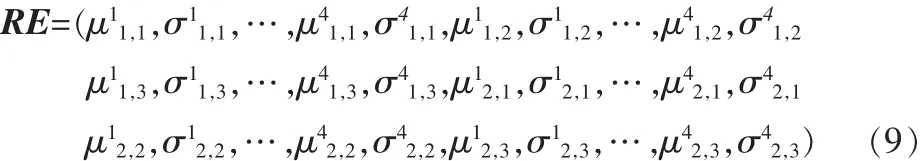
2.2 特征对文种的区别能力分析
对于相似文种的特征,类内距离越小,类间距离越大,特征的识别能力越好。可以定义不同种类两两之间的类内距离和类间距离的差值比例rate作为重叠率,来衡量特征的区别能力:

式中,RE 表示特征 矢量,n,ni,nj表示不同的种 类 ,k=1,2,…,K 表示样本的数量,x=1,2,…,X 表示对应的特征值索引。 indisn、outdisni,nj表示类内、类间距离。 根据 Bayes准则,重叠率越小,特征的分类能力越强。
本文建立了包含阿拉伯、缅甸、柬埔寨、中、英、印地、日、韩、俄、藏10种文种的图像库,其中中日、英俄、阿拉伯、印地、柬埔寨、藏文在纹理方面相对比较接近,从图像库1中抽取中、日、英、俄、阿拉伯、印地、柬埔寨、藏8种文种的图像各100幅作为实验图像检验多小波能量统计特征对不同文种的区别能力。据式(9)计算实验图像的多小波能量统计纹理特征矢量。 据式(10)~(15)计算中日,英俄,阿拉伯印地,柬埔寨藏之间的重叠率。
作为对比,对曾理等人提出的基于单小波变换的文种识别特征提取方法[3]进行了同样的实验。采用“Daubechies7”小波对图像进行两级分解,提取每个细节子图的能量比例纹理特征,得到6维特征矢量。同样依式(10)~(15)计算实验图像中不同文种的重叠率rate。实验结果如表1所示。

表1 特征的区别能力比较Tab.1 Comparison of ability to discriminate different features
由表1可见,基于多小波的能量统计纹理特征对文种的区别能力要优于基于单小波的能量比例纹理特征,对文种识别更有效。
2.3 基于LIBSVM的文种识别
如何寻找不同文种特征间的最优分类面是文种识别的关键所在。目前文种识别使用最多的分类工具是SVM[7](Support Vector Machines,支持向量机)。但用于对多维特征向量进行多分类时,SVM的参数优化过程变得相当复杂。鉴于此,本实验采用LIBSVM[8]分类软件。LIBSVM是由Chih_Chung和Chih_jen Lin开发的一个SVM工具,广泛应用于SVM、回归和分类估计,并且支持多类分类,通过交叉确认法可以得到最佳的参数来提高识别的准确率。本文选取径向基函数(RBF)为核函数。用LIBSVM随机抽取2/3样本用于训练,余下的1/3用于测试。
首先将图像进行能量归一化处理,然后进行多小波分解,提取能量统计纹理特征,建立纹理特征库。通过LIBSVM软件从库中随机抽取样本进行训练,得到SVM的最优参数,用此参数对测试样本进行识别。图3为本文提出算法的文种识别流程图。

图3 文种识别流程图Fig.3 Flow chart of the script identification
3 实验结果与分析
图像库1中文本图像是从杂志和书籍上扫描得到的,在采集过程中出现了轻微的噪声、笔画断裂等质量退化现象。图像库2对图像库1中的图像做了±1~±5°之间不等角度的倾斜,所包含的文本行为3~8行不等。2个图像库均包含阿拉伯、缅甸、柬埔寨、中、英、印地、日、韩、俄、藏10种文种图像各300幅。图像大小为128×128像素,8位灰度图像。图4、图5所示为图像库1、2中的部分文本图像。

图4 图像库1中的部分文本图像Fig.4 Part of document images in the image database No.1

图5 图像库2中的部分文本图像Fig.5 Part of document images in the image database No.2
为了验证算法对不同样本的适应能力,对每个图像库各进行了5次实验。实验时用LIBSVM从图像库中每种文种随机抽取200幅用于训练,余下的100幅用于测试。
为了验证算法的有效性,同时对曾理等人提出的基于单小波变换的文种识别方法[3]进行了实验。实验参数在本文2.2节给出。
在Intel 1.8 GHz和1 G内存的Windows XP Professional微机环境下,用MallabR2006a为实验平台进行实验。
表2中表示的是每种算法的特征提取时间,其中T指代时间。表3中表示的10种文种的识别结果以及平均识别率。取5次实验结果的平均值:


表2 特征提取速度比较Tab.2 Comparision of the feature extraction efficiency
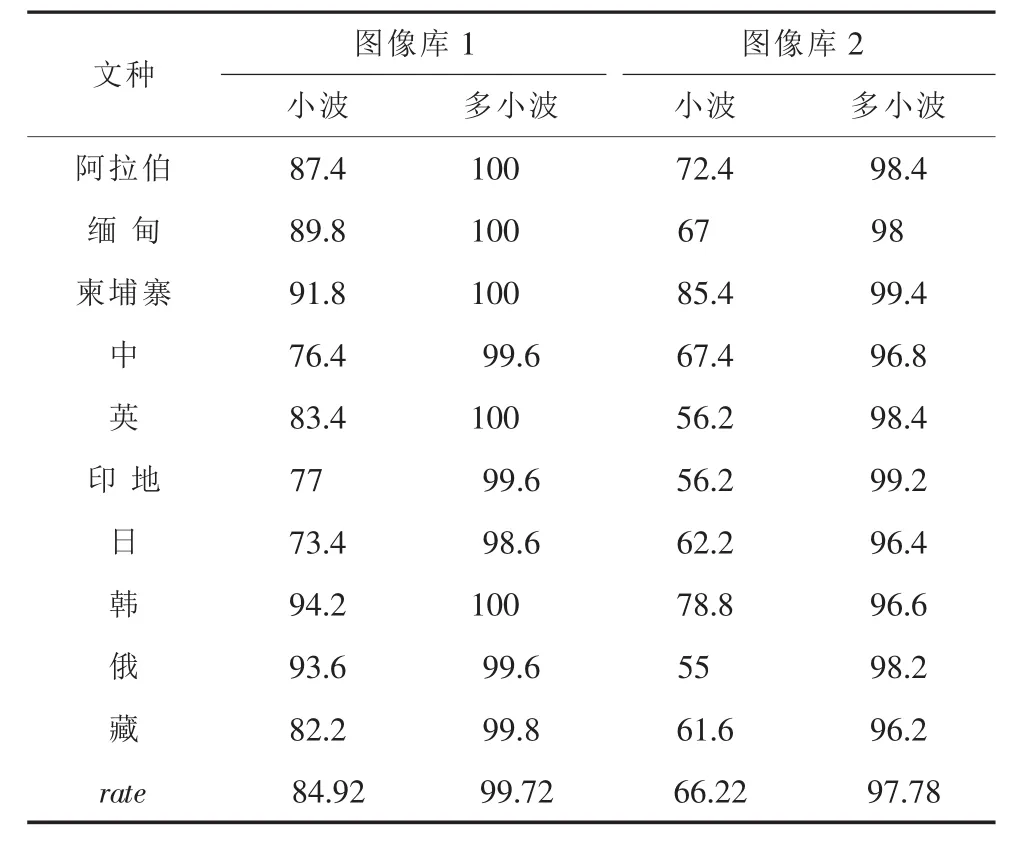
表3 识别结果(%)Tab.3 Result of recognization(%)
由表2、表3所示的实验结果可以看出,多小波变换在计算速度上要低于单小波变换。但对多文种的图像库,基于多小波变换的文种识别算法具有很高的识别准确率,对质量较好的文本图像几乎可以进行精确的文种识别,性能远远优于单小波特征提取方法。在图像质量较差、单小波识别率迅速下降的情况下,本文算法仍具有较高的识别准确率。
4 结 论
本文在对文本图像纹理特征进行深入分析的基础上,针对文本图像纹理特征具有很强的方向性及以文字行为周期的准周期性,采用多小波变换来提取文本图像的纹理特征进行文种识别,在对包含10种文种、图像质量退化程度不同的图像库上进行实验时,识别精度均很高。相对于单小波变换而言,多小波变换同时具有正交、对称、短紧支撑和高阶消失矩等优良特性,在提取图像纹理特征进行文种识别方面更为有效,对噪声、笔画断裂等质量退化现象有很强的鲁棒性。
[1]TAN T.Rotation invariant texture features and their use in automatic script identification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(7):751-756.
[2]曾理,唐远炎,陈廷槐.基于多尺度小波纹理分析的文字种类自动识别[J].计算机学报,2000,23(7):699-704.
ZENG Li, TANG Yuan-yan, CHEN Ting-huai.Multi-scale wavelet texture-based script identification method[J].Chinese Journal of Computers,2000,23(7):699-704.
[3]Busch A,Boles W W,Sridharan S.Texture for script identification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(11):1720-1732.
[4]StrelaV.Multi-wavelets:theoryandapplications[D].Cambridge:Mass Inst Technic,1996.
[5]Strela V,Tan H H,Tham J Y.Symmetric-anti-symmetric orthogonal multi-wavelets and related scalar wavelets[J].Journal of Applied and Computational Harmonic Analysis,2008(8):258-279.
[6]Xia X G, Geronimo J S, Hardin D P, et a1.Design of pre-filters for discrete multi-wavelet transform[J].IEEE Transaction Signal Processing,1996,44(1):25-35.
[7]Vapnik V.The nature of statistical learning theory[M].New York:Springer-Verlag,1995.
[8]Chang C C, Lin C J.LIBSVM:a library for support vector machines[EB/OL]. (2011).http://www.csie.ntu.edu.tw/~cjlin /libsvm.
