车铣复合数控代码编译器的设计*
2011-09-29陶桂宝安祥波
陶桂宝 梁 涛 安祥波 杨 琳
(①重庆大学机械工程学院,重庆 400044;②重庆大学机械传动国家重点实验室,重庆 400044)
车铣复合加工是指在一台设备上完成车、铣、钻、镗、攻丝、铰孔、扩孔等功能的一项技术[1]。具有效率高、精度高、速度高等优点。车铣复合数控机床结构复杂,使得工件与刀具、刀具与夹具以及刀具与工作台间发生干涉碰撞的概率增大。因此,开发一个具有验证NC代码正确性功能的加工仿真软件十分必要,而NC代码编译模块作为仿真软件的核心部分之一,成为国内外专家研究的热点。
目前,国内外对于三轴数控加工机床的编译器技术研究已经相当成熟,而对于三轴以上复杂的数控加工机床编译器的研究报道相对较少[2-5]。编译器的程序开发方法主要有两种[6]:一种是直接用高级语言开发,如C++、VB、C等,其中包括加载正则表达式类[7]来作词法与语法分析的判别工具和自行创建规则库代码与判别代码编写[8];另一种是用词法分析程序的自动构造工具(LEX、YACC 及 ANTLR[9-10]等)生成词法分析程序。
本文采用Visual C++为NC代码编译器的开发平台,并以微软公司研发的GRETA正则表达式类库作为词法、语法和语义匹配和分析的工具,开发一种适合车铣复合数控加工的NC代码编译器。
1 NC代码编译器总体设计
NC代码编译器主要功能是对NC
代码进行校验和译码。代码校验的主要功能是检查代码在词法、语法和语义上的格式错误和逻辑错误。代码译码则是从数控程序中提取与控制基础运动部件运动有关的命令,计算出刀具在基础坐标系的位移量,从而得到机床的刀具运动轨迹,实现数控程序驱动的加工过程仿真。译码主要分为对程序的预处理、翻译处理、补偿处理等3个过程。
NC代码编译器首先读取NC文件并存储到相应的链表中,然后对链表中NC代码逐行进行词法、语法和语义的分析,即为第一次历遍。如果检查出程序的错误,编译器则把错误信息进行存储,并显示到特定位置,以便NC程序的修改。在校验结束后,对没有出现错误的NC代码进行译码,最终提取出刀位信息,并保存信息到链表中,这个过程成为第二次历遍。NC代码编译的总体流程见图1。
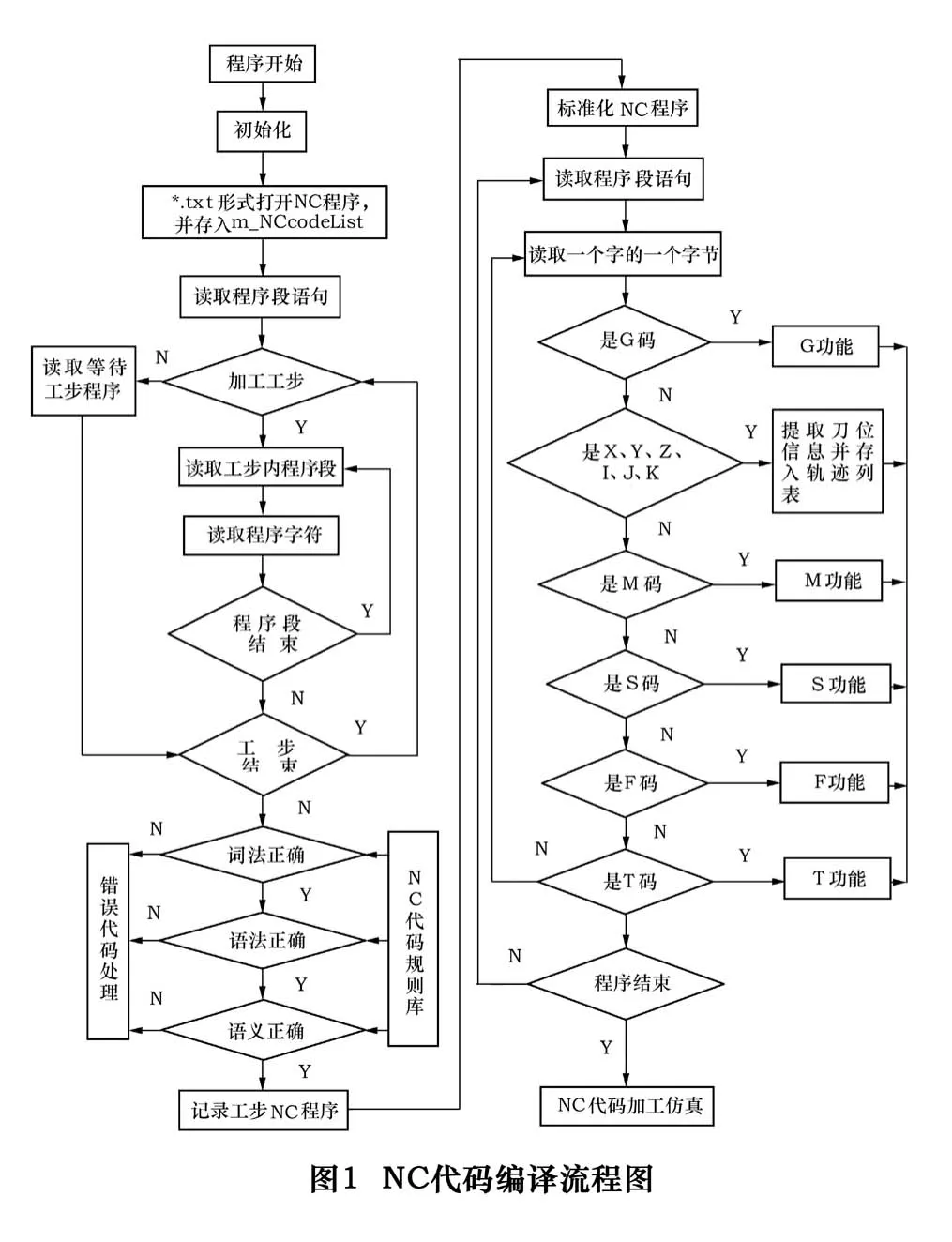
1.1 词法分析
语法分析是指先将NC程序从NC数据链表中按程序字依次读出,然后查找NC代码是否存在规定以外的字符及不能识别的指令,包括不属于数控系统的G代码和M代码,最后检查字符后面数字格式及极限错误的过程。具体实现方法为:首先将检查字符程序、词法分析程序、语法和语义分析程序设计为单个的子程序模块,然后在第一次链表历遍时,将这几个子程序同时进行检查。在语法分析程序需要一个字(字符)时,调用词法分析程序;字符检查程序则在词法分析程序运行时调用。采用这种方法,避免了代码的多次调用,减少了检查和搜索时间,提高了编译效率。
词法检查的主要任务包括:
①检查出数控系统不能识别的字符,即数控系统规定外的字符;
②根据建立的G代码和M代码规则库,识别出不属于系统的G代码和M代码;
③检查程序号的首字符是否与数控系统的要求相符;数值位数是否符合系统规定;
④检查程序段的数值(行号)是否在数控系统规定的数值范围内;
⑤检查坐标值代码后的数值是否在机床的行程范围内;
⑥检查S代码格式是否正确,设定的主轴转速值是否在主轴转速范围内;
⑦检查F代码格式是否正确,设定的主轴进量给是否在主轴进给范围内;
⑧检查T代码格式是否正确,其后面数值是否大于刀库的最大容量值。
1.2 语法与语义分析
语法分析是指以一个程序段为检查单位,根据程序指令查找相关的语法规则,然后调用相关的语法检查单元,再按语法规则要求继续读入字段,判断当前读入的字段是否与程序指令相匹配的一个过程。如果在程序段中出现了规则库中没有列出的字段或缺少了相应的字段,则会显示NC程序出现语法错误。语法分析的方法分为两种:即自顶向下分析和自底向上分析[8]。本文采用自顶向下分析方法,根据给定的代码为起始符,按照其语法规则,试图向下推导出下个字符段。如果分析字符与规定的字符段一致,则语法正确,反之,则语法错误。语法检查实现方法为:先建立相应的词法规则库,然后使用语法检查函数检查程序段内指令是否存在语法错误。
语义分析是指按照NC代码的语义规则,查询程序段间指令的逻辑关系是否正确的过程。其目的为检查程序中的语义错误。语义检查实现方法为:首先建立一个语义检查函数,检查整个程序的上下程序段之间是否存在语义错误。
语法和语义检查的主要任务列于表1。
1.3 NC代码编译
NC代码编译是指提取NC代码中有关控制机床部件运动的命令、动作指令和状态信息,并将其转换成仿真所需要的数据格式,存入相应的数据结构链表中的过程。
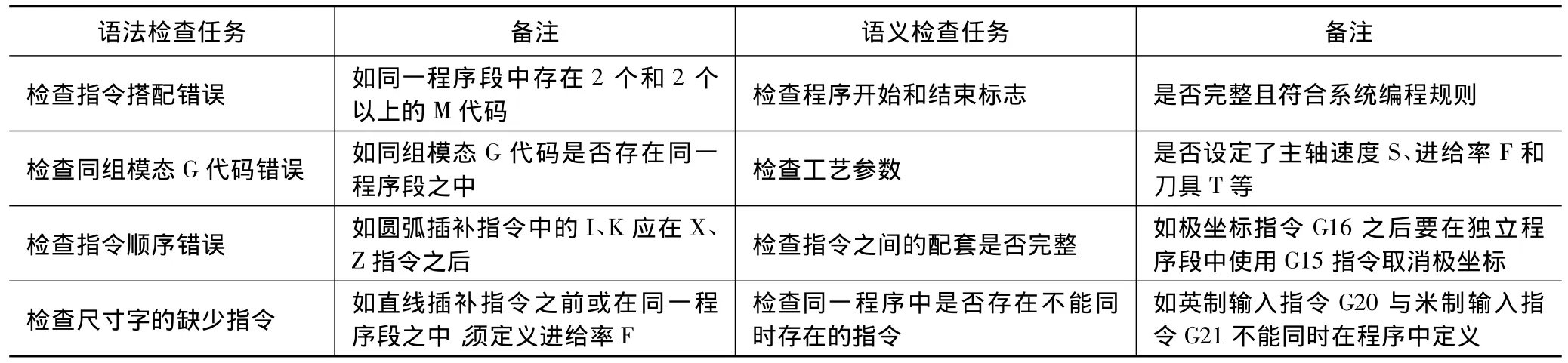
表1 语法与语义检查任务表
编译过程的第一步是预处理环节,即代码的标准化,其过程为:以每一行为单位作为字符流,滤去空格、拼数字、拼复合词,转化成“字地址符+数字”形式的指令单词序列,然后把单词序列进行划分和添加指定空格,最后将程序段重新写入链表文件。
编译过程的第二步是程序翻译,即将标准化后的程序代码逐行读入,提取其中的G、M、S、T、F等关键代码,分别调用相关函数进行刀位信息处理,然后将编译好的刀位信息以规定的格式存储到数据链表中。例如直线插补指令,需要提供插补起点和终点坐标值;圆弧插补指令,则需要提供圆心、圆弧半径和圆弧起点终点坐标值;固定循环指令,则要提供固定循环加工轨迹所要的点的坐标值和加工次数。
编译过程的第三步是补偿处理,即对刀具半径、长度及位置补偿指令建立相应的补偿模块,为刀具位置信息增加补偿值。
1.4 车铣复合数控代码的特点与其编译实现
车铣复合数控加工是一种高效的数控加工形式。车铣复合加工机床通常采用双刀或多刀同时车削、铣削加工工件,以达到缩短加工时间的目的,从而提高生产效率。在加工过程中,刀架的动作采用等待协调机制来控制,即在同一个同步时段中,如果其中一个刀架先完成加工任务,如主刀架先完成,则不需要等其余刀架是否完成而直接进入下一时段加工,否则需要等主刀架任务完成后才进行下一时段的加工。多通道分别控制机床刀架滑板,数控系统的等待协调指令则用于实现刀架的工作进程,其中通道1设为主通道。等待指令格式为 WAITM(n,1,2)或者 WAITE(m)。WAITM(n,1,2)中的n表示等待的工步匹配号(同步号),为任意正整数值,后边的1,2分别表示通道1和通道2;WAITE(m)中的m值取1或2,表示通道m的程序结束[11]。此外,车铣复合数控代码具有如下特点:
①以工步为基本单位,工步内包含有子程序调用;
②NC代码可以像高级语言具有分支和循环功能;
③工步内部和工步之间存在跳转指令;
④使用R参数和算术表达式;
⑤左右刀架NC代码中间存在信息通讯和协调,由等待协调指令控制。
由于车铣复合数控以工步为单位,编译程序首先要判断程序为加工工步还是等待工步,然后读取一个完整的工步信息代码,最后对代码进行数据处理、代码分析和代码编译。
另外,在规则库定义中,需要定义跳转、循环和等待指令标识;对R表达式、赋值表达式及算术表达式需建立相应的数据处理模块。
2 编译代码实现
本文以Visual C++6.0为程序开发平台,首先建立NC代码的程序基类CNCCode,用于处理NC程序的数据处理、词法分析、语法和语义分析、错误信息处理及NC程序编译过程。由于现存的数控系统(如FANUC、SIEMENS等)指定的NC代码标准与国际标准并不完全相同,使得代码编译器通用性不强。利用C++具有面向对象的特性即封装性和继承性,不同数控系统NC代码子类可继承CNCCode基类,子类则通过对规则库函数进行重载来定义各自系统中的不统一指令。从而使得编译器可以处理不同数控系统的NC代码,这样使得编译器具有可对更多的数控系统进行扩展和兼容。CNCCode类定义如下:


2.1 正则表达式的应用和规则库的建立
正则表达式(Regular Expression)是一种字符串匹配模式,即描述或者匹配一系列符合某个句法规则的字符串,常用于检索或者替换某个模式的文本内容。GRETA是微软研究院推出的一个正则表达式模板类库,包含了C++的对象和函数,使字符串的模式匹配和替换变得很容易。它们是rpattern:搜索的模式;match results/subst results:放置匹配、替换结果的容器[12]。GRETA执行搜索和替换的操作过程:首先需要定义描述匹配规则的字符串,用来初始化rpattern类的对象。然后把需要匹配的字符串作为传递参数,调用 rpattern类的函数(如 match()或者 substitute())。如果调用失败,函数返回false,否则,函数返回true,match_results类的对象就可以得到匹配后的结果。编译程序加载GRETA正则表达式类库作为NC代码查找的工具,方便地定义NC代码规则和检查代码的错误。GRETA匹配速度快,提高了编译器的编译速度。
首先应用正则表达式的语法规则,对关键字符和指令进行定义,再将它们添加到规则库定义函数,即完成了NC代码规则库的建立。部分关键字符的定义如下:

2.2 词法、语法和语义检查
编译程序首先打开NC程序,并把NC程序以行为单位地读入并储存到NC代码数据链表中。在第一次历遍NC代码数据链表时,调用语法检查函数,并运用GRETA正则表达式中的Match()函数,查找字符串是否能够与相应指令代码的规则相匹配,如果匹配,则语法正确,否则,语法中是否存在错误。在历遍过程同时,同样的调用字符检查函数和词法检查函数,检查是否存在错误。在语义检查函数中,则重点检查程序段间的逻辑错误。整个过程中,多次调用GRETA正则表达式Match()函数,检查所传递的字符串是否符合规则库中的子串。
其中语法检查函数中查找G00指令后面是否有任意一个坐标值的模块定义如下:

2.3 错误信息处理
NC代码编译器中的一个重要部分就是错误信息处理部分。主要功能是存储和显示错误的代码信息。这样便于用户修改错误的NC代码。本文先把词法、语法和语义检查出的错误NC代码添加到错误信息链表(m_ErrorInformationList)之中,同时记录出现错误的NC代码行数及总错误数量,最后把错误内容显示到信息视图之中。其中的G代码语法错误信息设置函数代码如下:

2.4 NC程序译码过程及刀位信息储存
影响机床运动的主要 G代码分别为G00、G01、G02、G03。因此,NC代码的译码对象即为这几个G代码。在此之前,须对影响刀位坐标信息的G代码进行译码,这样才能准确地把代码译成相应的刀位信息。如:编程规则(绝对值编程G90和相当值编程G91)、加工平面选择(G17、G18和G19)及工件坐标系定义(G92)等。
通过设置bool类型变量IsAbCdnate来判断NC程序是否是绝对值编程,当G90指令时IsAbCdnate设为true,而当G91指令时IsAbCdnate设为false。应用此法,即可处理那些影响刀位坐标信息的G代码。译好影响刀位坐标信息的G代码之后,就可对G00~G03代码编译。编译直线插补指令G01译码过程为:首先查询刀补指令G41/G42是否已经定义,如果定义则补偿刀具半径,如果没有定义,则坐标值不变;其次检查加工平面,确定坐标轴,根据编程规则,确定当前代码是绝对坐标还是相对坐标,最后进行坐标转化,即可得到刀位坐标信息。
编译好的刀位坐标信息还需转换成刀位起点和终点的坐标值,如果是圆弧插补则还要把NC代码转换为圆心坐标值和圆弧半径值。刀位坐标信息及加工工艺参数信息都需要做存储处理。本文就建立一个刀位信息基类CPosition和定于一个刀位信息链表m_PositionList。将刀位信息储存到CPosition类中的一个对象内,而将CPosition类的对象存储到链表m_Position-List之中。这样存放很方便,程序调用CPosition类数据也变得简单,同时更利于加工过程仿真时的数据提取。CPosition类的定义如下:

3 结语
本文以Visual C++作为程序开发平台,总体设计了NC代码的编译程序,并根据车铣复合数控代码的特点,分析了代码的词法、语法、语义,并检查了代码中存在的词法、语法、语义错误,最终将编译代码转化为刀位信息。本编译器具有良好的快速性、精度高、通用性和兼容性。编译器生成的刀位信息为车铣复合数控加工仿真系统提供了驱动数据,是数控加工仿真系统不可缺少的一个部分。
[1]复合加工谁执牛耳[J].现代制造,2004(21):20-24.
[2]Liu Y,Guo X,Li W,et al.An intelligent NC program processor for CNC system of machine tool[J].Robotics and Computer- Integrated Manufacturing,2007,23(2):160-169.
[3]LEEW B,GAO D,LI JG.An NC toolpath translator for virtual machining of precision optical products[J].Journal of Materials Processing Technology,2003,140:211-216.
[4]乐广军,周宏甫.数控代码语法检查及图形仿真系统的研究[J].计算机应用与软件,2005,22(4):56 -57,87.
[5]田超,郭斌.数控仿真中NC程序的通用转换技术[J].组合机床与自动化加工技术,2008(2):55 -56,59.
[6]陈辉,郭艳玲.用LEX构造数控编译器词法分析程序的研究[J].机电工程技术,2006,35(2):28 -30.
[7]任松涛,秦现生,白晶.NC代码解释器的开发[J].中国制造业信息化,2007,36(5):54 -57.
[8]游华云,叶佩青,杨开明.多数控代码解释器共存的设计与应用[J].计算机工程与应用,2007,43(12):1 -2,111.
[9]禹丹,严宏志,王继娜.基于ANTLR的NC代码编译器的设计与实现[J].计算机应用,2008,28(2):522 -524,527.
[10]伍抗逆,李斌,陈吉红.面向开放式数控系统平台的NC代码解释器开发[J].中国机械工程,2006,17(2):168-171.
[11]李晓磊,吴勇中,桂贵生.双刀车削数控加工仿真技术研究[J].制造技术与机床,2009(6):74-78.
[12]王心光,傅建中.虚拟数控加工中G代码编译器的研究[J].组合机床与自动化加工技术,2005(6):80-81,84.
