中国商业银行信用风险度量研究
2011-09-12孙宁华
孙宁华,刘 杨
(1.南京大学 经济学院;2.渣打银行 南京分行,南京 210093)
中国商业银行信用风险度量研究
孙宁华1,刘 杨2
(1.南京大学 经济学院;2.渣打银行 南京分行,南京 210093)
信用风险是商业银行面临的主要风险,信用风险的度量模型有专家判断法、信用评分法、神经网络分析法以及现代违约概率模型等。通过比较分析LOGIT模型和KMV模型,选取了能够体现公司盈利能力、营运能力、资本结构、偿债能力、成长能力和现金流量的28个指标,运用逐步回归方法建立LOGIT模型,发现该模型能够提前一年较好地预测出公司的违约情况。在分析KMV模型时,通过GARCH-M模型计算出企业股权价值波动率,并运用上市公司数据得出样本公司的股权价值和违约点,从而计算出样本公司的资产价值和资产价值波动率,最后得出KMV模型的判别结果。上述分析表明我国商业银行应以LOGIT模型作为判别模型,以KMV模型作为追踪模型,将LOGIT模型与KMV模型相结合来判断贷款企业的信用风险水平。
信用风险;LOGIT模型;KMV模型
一、引言
美国次级贷款危机仍然对全球的金融市场乃至实体经济产生着深远的影响。此次金融危机暴露出金融行业对风险管理的重视不足,对风险的识别能力仍需加强。从事房地产抵押贷款业务的商业银行,背离了银行业一贯坚持的审慎信贷标准,没有仔细审查客户的还款能力,低估了抵押品的市场风险。投资银行的高杠杆率以及资产证券化的过度衍生也放大了房地产市场和衍生品市场的风险,并波及全球金融市场。因此,风险的识别和度量对于商业银行的健康发展至关重要。
信用风险的度量方法主要有专家判断法、信用评分法、神经网络分析法和违约概率模型。
专家判断法是传统的信用分析方法。该方法的最大特征是信用评价是由商业银行中经过长期训练、具有丰富经验的信用评估专家做出的,并由他们进行最后的决策。专家的经验和判断是信用分析和决策的主要基础,这种方法的主要问题是对信用风险的评估缺乏一致性。
信用评分法包括线性概率模型、多元判别分析模型、LOGIT模型和PROBIT模型。Beave首先运用统计学方法建立了单变量的财务预警模型,选取了美国1954~1964年间资产规模大致相同的79家经营失败和79家经营良好的企业进行对比,发现现金流量/负债总额、资产收益率和资产负债率是具有较好预测性的财务比率[1]。Altman提出了Z值模型[2],1977年Altman,Haldeman和Narayanan对原有的Z值计分模型进行了修改并推出了ZETA模型,变量由5个增加到了7个[3]。它所选变量更加稳定,适用范围更广,对企业违约的辨认能力也增强了。多元判别分析模型是根据观察到的一些统计特征对判别对象进行分类,以确定对象的类别。该模型的特点是己经掌握了一定时间范围内每个类别的若干个样本,分析其特征并总结出分类的规律性,建立判别公式并得出判别结果。LOGIT模型不要求变量满足多元正态分布和等协方差等假设条件,因此在预测企业是否违约时得到了较为广泛的应用。
神经网络分析模型的原理是模拟人类或其他生物的神经系统对变化的自适应能力,是一套人工智能预测系统。神经网络的结构包括一个输入层、若干个中间隐含层以及一个输出层。神经网络分析模型可以模拟相关变量投入后对企业信用风险的影响。通过学习训练范例的过程,神经网络分析模型可以找出输入变量与输出变量间的关系,之后建构预测模型。神经网络模型的最大缺陷是随机性较强,而且要得到一个较好的神经网络模型非常耗费精力和时间,所以应用受到一定限制。另外,神经网络分析模型还因为缺乏坚实的理论基础而受到批评。
目前应用广泛的现代违约概率模型包括KMV模型,Credit Metrics模型,Credit Risk+模型和Credit Portfolio View模型。
1993年KMV公司提出了KMV信用风险度量模型,该模型基于BSM期权定价理论,利用股权价值、股权价值的波动率以及企业违约点估算企业的资产价值和资产价值的波动率,并据此求得违约距离,从而得到企业预期违约率。KMV模型可以充分利用资本市场上的数据,对公开上市公司进行信用风险的量化度量分析。由于KMV模型所需输入的数据来自股票市场,而非历史财务数据,因此预测结果更加具有时效性。
VaR方法是度量给定的资产或负债在给定的置信水平下最大的价值损失额。J.P.摩根银行和其他合作者创立了Credit Metrics模型用于度量非交易性金融资产。Credit Metrics模型依赖于历史平均违约率和违约时的资产收回率,以此为基础确定信用资产组合未来的价值变化,通过基于VaR的方法计算整个组合的风险暴露。
瑞士信贷银行CSFP于1997年提出了基于保险精算理论的Credit Risk+模型。它假定违约率是随机的并且在信用周期内显著波动。Credit Risk +方法假设一个贷款企业以概率P违约或者以概率1-P不违约。Credit Risk+模型先按照投资组合中每笔贷款风险暴露的大小将贷款分组,假定每组内贷款风险敞口相同,从而使得每组贷款的损失分布遵循泊松分布,之后将各组损失汇总得到整个投资组合的损失分布。
1997年Mckinsey公司提出了Credit Portfolio View模型,该模型纳入了如失业率、汇率以及政府支出等宏观因素变量,并模拟不同信用等级公司的违约和信用等级转移概率的联合条件分布。Credit Portfolio View模型的思想是违约率和信用等级转移概率是与宏观经济变量紧密联系的,经济繁荣时违约率和信用等级转移概率降低,反之则增加。
我国国内学者也对我国商业银行信用风险度量进行了一定的研究。吴世农,卢贤义应用Fisher线性判定模型、多元线性回归模型和LOGIT回归模型对我国上市公司进行分析,预测上市公司的财务困境,结果表明LOGIT模型误判率最低[4]。沈沛龙,任若恩根据《新的资本充足率框架》的基本原理,把Credit Metrics同我国商业银行的信贷风险管理实践相结合,研究适合我国国内商业银行特点的内部信用风险度量分析和管理的基本框架[5]。李萌应用LOGIT模型,结合主成分分析法和t检验对商业银行信用风险进行实证分析,结果表明公司偿还能力和流动性对信用风险的影响最大,而且LOGIT模型具有很好的识别和预测能力[6]。都红雯,杨威提出了我国应用KMV模型实证研究中存在的五大问题并提出相应的对策建议[7]。李萌,陈柳钦构造了基于BP神经网络的商业银行信用风险分析模型,分析结果表明单隐层BP神经网络模型对企业信用风险具有较强的识别能力[8],但推广能力还有待提高。
在上述研究结果基础上,本文选取预测效果较好且应用较为广泛的LOGIT模型和KMV模型做比较分析。我们将区域风险因素以虚拟变量的形式加入LOGIT信用风险度量模型中进行分析,从而显著增强了该模型的预测准确率。这说明我国商业银行在运用LOGIT模型作为信用风险度量模型时应考虑区域风险因素。此外,通过比较LOGIT模型和KMV模型对于企业违约情况的预测结果,本文提出了适合我国商业银行度量信用风险的模型应该是将LOGIT模型作为判别模型,KMV模型作为追踪模型。
二、LOGIT模型对信用风险度量的实证研究
(一)模型说明及样本的选取
LOGIT模型中解释变量既可以是连续变量也可以是离散变量,还可以是虚拟变量,并且不要求它们服从多元正态分布,这与企业财务数据的实际情况较为相似,因此在信用风险度量中应用广泛。其基本函数形式如下:

LOGIT模型在分析企业财务状况及信用风险水平时,xi为反映企业经营状况的财务比率指标或其他变量,ci则表示相应指标的权重。
本文分别选取2008年1月至2008年12月和2009年1月至2009年12月这二个时间段内被特殊处理的公司以及与之相对应的财务状况良好的上市公司作为样本,利用2008年的样本公司建立LOGIT模型,并将其应用于判断和预测2009年样本公司的财务状况和信用风险中。
(二)指标的选取
通过综合考虑会计学以及我国商业银行信用风险评价指标,同时兼顾数据的可得性和可量化原则,本文选取了28个财务比率指标,见表1。数据来源于WIND数据库。
(三)实证研究
LOGIT模型对多元共线性较为敏感,自变量间的多元共线性会导致由于标准差增大而降低LOGIT模型的预测能力,所以本文首先对自变量间的相关性进行检验。本文通过利用SPSS软件进行两个变量的相关性分析,发现变量X2与X4,X5与X6,X2与X11等变量之间显著相关,多重共线性显著。
解决多重共线性的方法包括主成分分析,岭回归以及逐步回归等多种方法。本文采用逐步回归法消除变量间的多重共线性。利用SPSS软件采用混合逐步回归法来筛选变量,筛选出的变量为X3、X10、X12、X18,设*ST公司的观测值为0,经营状况良好的公司的观测值为1,建立LOGIT回归方程如下:
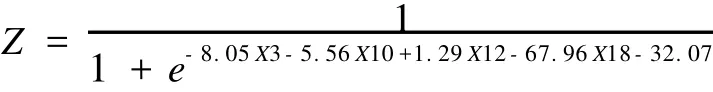
将该模型运用于2009年样本公司2008年的财务比率数据,此时判别准确率见表2。
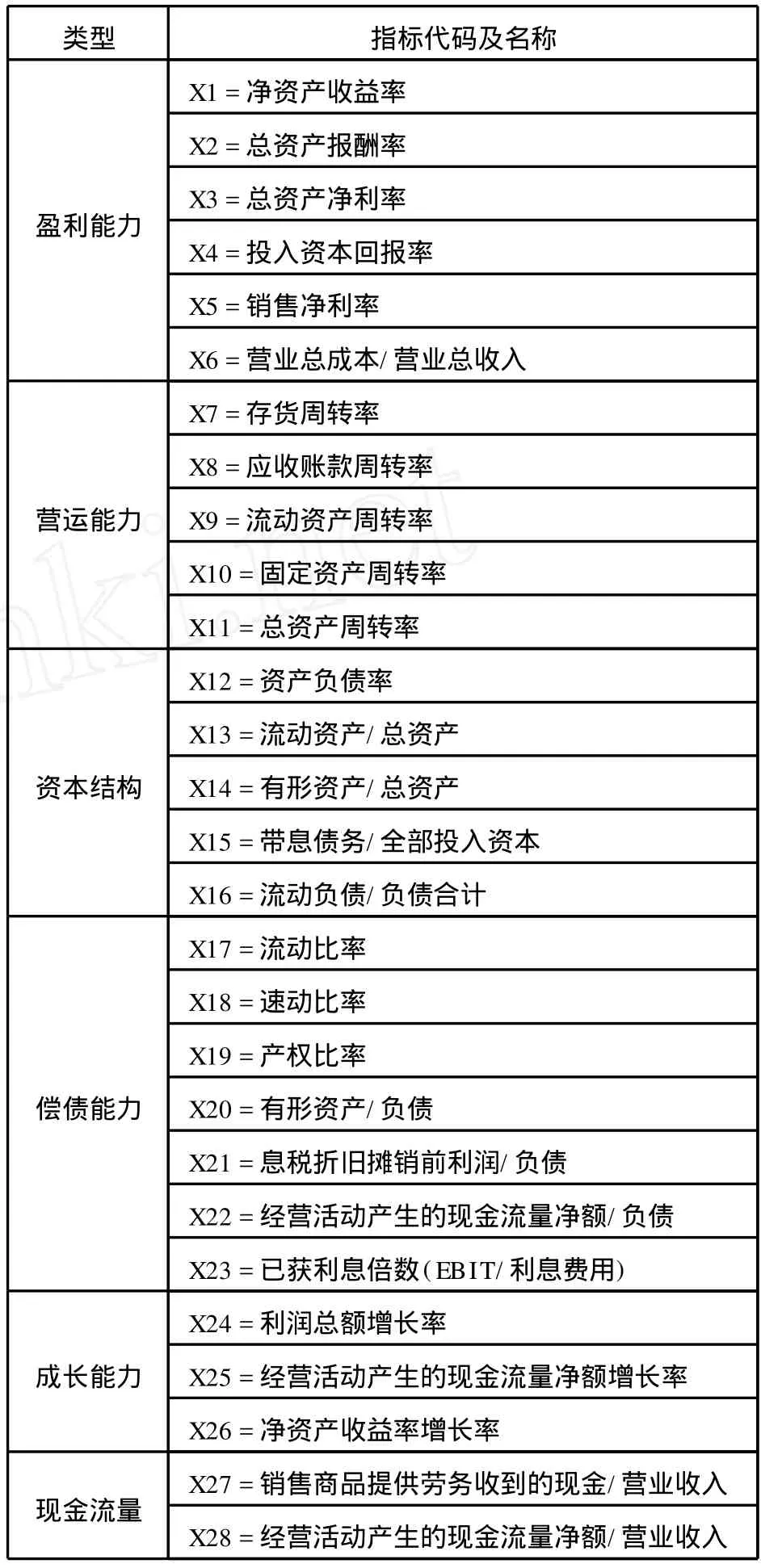
表1 LOGIT模型指标
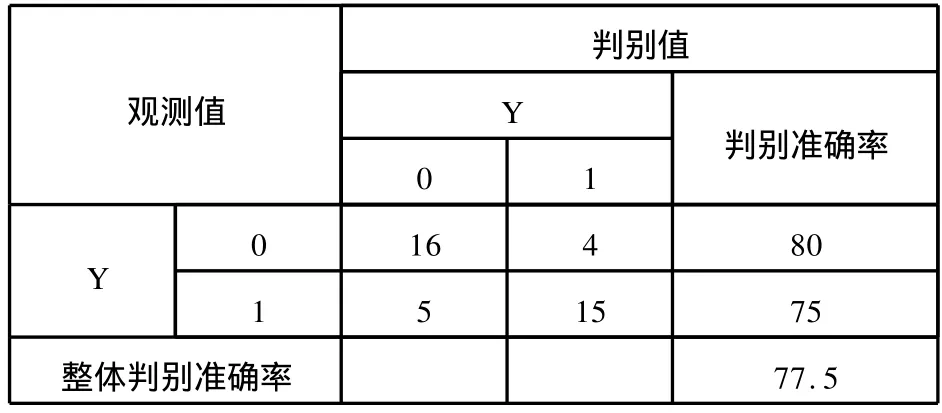
表2 LOGIT模型判别准确率
表2表明,将*ST公司误判为正常公司的概率为20%,将正常公司误判为*ST公司的概率为25%,模型整体判别准确率为77.5%,有较好的判别结果。
将该模型运用于2009年样本公司2007年的财务比率数据,此时预测准确率为:
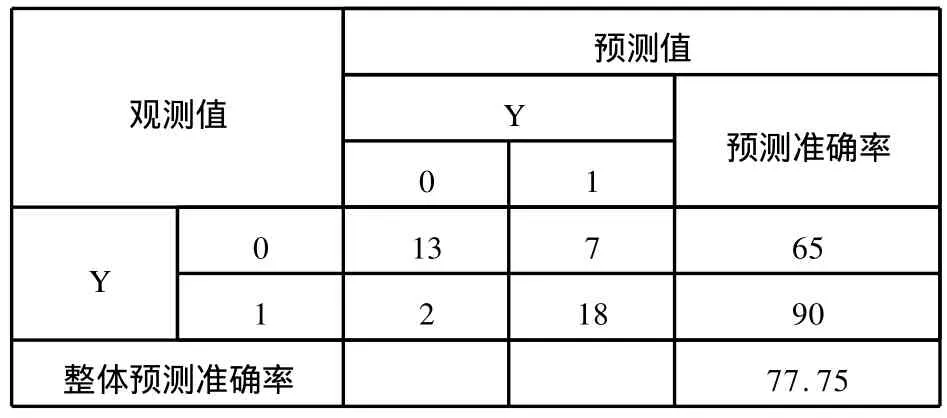
表3 LOGIT模型预测准确率
结果发现将*ST公司预测为正常公司的概率为35%,将正常公司误判为*ST公司的预测率均为10%,模型整体预测准确率为77.75%,也有较好的预测结果。
国外商业银行的信用风险度量模型一般不加入区域风险因素,因为发达国家市场化程度很高,区域间经济趋同性较强,因此区域因素在信用风险的识别和度量过程中并不显著。而我国尚未完全形成统一的市场经济体系,东部发达地区和西部欠发达地区间经济差异十分显著,因此将信用风险度量模型应用于预测客户会否违约时,在模型中加入地区差异因素可能会加强模型的预测效果。本文将我国分为经济发达地区和欠发达地区,其中经济发达地区设为1,欠发达地区为0,得到回归模型如下:
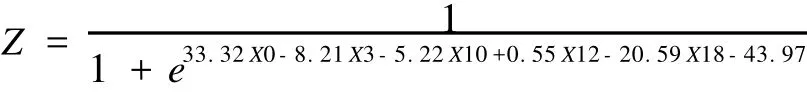
将2009年样本公司2008年的财务数据和样本公司所在省份的区域虚拟变量带入上述模型中,此时预测准确率见表4。

表4 加入区域因素后LOGIT模型判别准确率
结果发现将*ST公司误判为正常公司的概率为5%,将正常公司误判为*ST公司的概率为20%,模型整体判别准确率为87.5%,有很好的判别结果。相比较于未加入区域风险因素的原模型,判别准确率提高了10%。
将2009年样本公司2007年的财务数据和样本公司所在省份的区域虚拟变量带入上述模型中,此时预测准确率见表5。
结果发现将*ST公司误判为正常公司的概率为30%,将正常公司误判为*ST公司的概率为10%,模型整体预测准确率为80%,有很好的预测结果。相比较于未加入区域风险因素的原模型,预测准确率提高了2.5%。
(四)实证结果分析
经过实证分析发现,LOGIT模型能够很好的判别样本公司是否违约且当被用来提前一年预测公司的财务风险时,有较好的效果。研究结果显示,反映企业盈利能力的总资产净利率、反映营运能力的固定资产周转率、反映资本结构的资产负债率和反映偿债能力的速动比率在该模型中占较大比重。随着总资产净利率、固定资产周转率、速动比率的下降, Y值逐渐减小并接近于0,说明当贷款公司的这些比率下降时,公司的经营状况不佳,信用风险水平提高;随着资产负债率的增加,Y值逐渐减小并接近于0,说明当贷款公司的这一比率提高时,公司负债相比较于资产过多。这些情况都应引起贷款银行的警惕和足够重视。
此外,区域因素能够增强模型的预测能力,说明我国地区间的经济差异较为显著,且这种差异可以用来解释公司的违约情况,商业银行在对不同区域的公司投放贷款时可能面临不同程度的区域风险。因此经济发达地区企业的违约可能性较低。所以我国商业银行在建立信用风险度量模型时,应考虑加入区域因素来增强模型的预测能力
三、KMV模型对信用风险度量的实证研究
(一)KMV模型原理
KMV模型的理论基础是Black-Scholes期权定价理论。KMV模型的基本思想是把公司的资本价值作为看涨期权,公司负债作为看跌期权。由于受到宏观经济环境、行业风险、外汇风险等因素的影响,假定公司的资产价值Vt是一个变量,任意时刻t公司资产价值的变化服从对数正态分布并服从几何布朗运动:
其中μ为公司资产价值的期望值,σ表示公司资产价值的标准差,Zt为公司资产价值变动的随机量,Zt∈N(0,1)。
KMV模型原理可以用图1表示,当公司资产价值高于违约点(DPT)时,贷款公司选择归还贷款本息并获得投资收益;当公司资产价值低于违约点时,贷款公司选择违约,公司选择违约的概率为ED F。
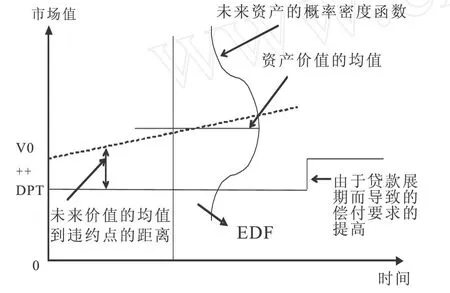
图1 KMV模型的预期违约率原理
(二)假设条件
(1)当贷款公司的资产价值大于违约点时,贷款公司不会违约;而当贷款公司的资产价值低于违约点时,贷款公司会选择对债权人即商业银行违约。
(2)贷款公司的资本结构只包括长期债务、短期债务和所有者权益。
(3)市场上存在一个无风险利率并且该利率一定时间内固定不变的。
(4)在债务合约的有效期内,贷款公司没有任何现金支付,也没有其他债券的发行而且没有破产成本。即如果公司无法偿还债务,违约只在债务合约到期时发生。
(5)公司的资产市场价值服从伊藤过程。
(6)市场是无摩擦的,即没有交易成本、税收而且所有的资产都可以无限细分。
(7)贷款合约到期时,公司的资产价值服从正态分布。[10]
(三)违约率的计算步骤
1.计算资产价值VA和资产价值波动率σA
依据Black-Scholes期权定价理论,公司股权市场价值和资产市场价值之间满足如下关系:

F是公司债务面值,即公司的违约值,本文用DPT进行计算。T-t是债务合约到期时间。VE是公司股权市场价值。N(.)是零均值,标准差为1的标准正态分布。
依据伊藤定理(Ito’s Lemma),公司股权价值的波动率与资产价值的波动率存在以下关系:

2.估算违约点DPT
KMV模型假设贷款公司的资本结构包括长期负债(L TD)和短期负债(STD),违约点是长期负债和短期负债的结合。经过大量的实证研究,KMV公司发现在临界值大约等于流动负债加一半长期负债处,公司违约最为频繁。因此KMV近似地将违约点表示为公司短期负债(STD)加上长期负债(L TD)的一半:

3.计算违约距离DD
违约距离表示的是资产价值分布的均值与违约点之间的标准差个数,因此不同的上市公司可以使用该指标相互比较。
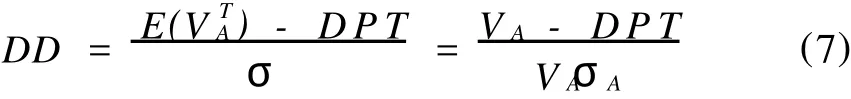
4.估计预期违约率EDF
理论预期违约率(EDF)的计算过程如下:

根据公式(1),因为Z服从正态分布,所以有:


可以推导出d就是至违约点的距离DD。
预期违约率可以表示为ED F=N(-DD)
但是由于我国尚未建立经验预期违约率数据库,直接计算理论预期违约率可能造成较大偏差,因此本文通过比较违约距离DD与违约距离的平均值来区分违约公司和经营状况良好的公司,若违约距离大于平均值,则认为该公司不会违约;若违约距离小于平均值,则认为该公司会选择违约。
(四)实证研究
1.股权价值和无风险利率的选取
由于本文中的样本公司均已在2007年完成了股权分置改革,因此采用样本公司2007、2008年总市值作为公司的股权价值进行计算。此外,本文分别选取2007年和2008年银行一年期定期存款利率的均值作为无风险利率进行计算。
2.股权价值波动率的计算
投资者认为金融资产带来的收益应当与为其承担的风险成正比,金融资产风险越大,投资者的预期收益就越高。GARCH-M模型通常应用于股票等预期风险与预期收益密切相关的金融领域,股票风险越大,相应的预期收益率也就越高,假设股票的预期收益的变动依赖于一个常数项及条件标准差。
均值方程可表示为:
yt=γ+ρ σt+ut,t=1,2,……,T
方差方程为:
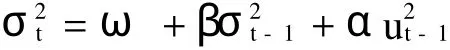
随机抽取*ST东电2008年1月1日到12月31日交易日股价数据进行检验,首先利用最小二乘法估计yt=γ+ut,结果如下yt=-0.003067+ut,但是观察残差图,可以注意到波动成群的特性,说明误差项可能具有条件异方差性。

图2 *ST东电残差图
因此对该式进行ARCH LM检验,得到了滞后阶数p=1时的ARCH LM检验结果:

F-统计量5.751791概率值(P值) 0.017227 T*R2统计量5.665040概率值(P值) 0.017306
此处P值小于0.05,拒绝残差序列不存在ARCH效应的原假设,证实存在ARCH效应。
应用GARCH-M模型进行估计,结果如下:
均值方程:
yt=2.024σt-0.083+ut,
方差方程:

方差方程ARCH和GARCH项的系数之和等于0.835,小于1,满足参数约束条件。由于系数之和接近于1,表明条件方差所受的冲击是持久的,即冲击几乎对未来所有的预测都有重要作用。
对该式进行ARCH LM检验,得到了滞后阶数p=1时的ARCH LM检验结果:

F-统计量0.008537概率值(P值) 0.926460 T*R2统计量0.008607概率值(P值) 0.926083
此时P值均大于0.9,接受原假设,说明利用GARCH-M模型消除了残差序列的条件异方差性。因此本文利用GARCH-M模型来计算股权价值波动率。
(五)实证研究结果
本文利用迭代的思想通过C++编程来计算KMV模型的结果。根据样本公司2008年度第三季度的股权价值、股本波动率及违约点等数据,应用KMV模型估算样本公司三个月后是否违约(在KMV模型中,本文仍然借用LOGIT模型的表示方式,即0代表*ST公司,1代表财务状况良好的公司),得到结果如下:

表6 KMV模型预测准确率
具体来说,将*ST公司误判为非ST公司的概率为30%,将非ST公司误判为ST公司的概率为25%,总体预测准确率为72.5%,预测准确率较高。
根据样本公司2007年末数据,应用KMV模型估算一年后是否违约,结果如下:
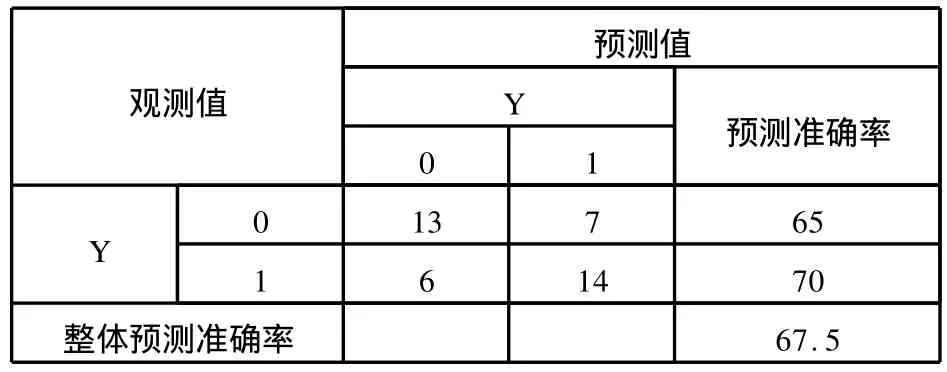
表7 KMV模型预测准确率
具体来说,将*ST公司误判为非ST公司的概率为35%,将非ST公司误判为*ST公司的概率为30%,总体预测准确率为67.5%,结果对于商业银行有一定的参考意义。
为了研究KMV模型对于公司信用风险水平变化的追踪能力,本文选取二组公司,每组四个。一组为*ST公司,另一组为财务状况良好的公司,进行比较分析。
结果发现*ST公司位于违约距离均值以下或者违约距离有明显下降趋势;非ST公司位于违约距离均值以上或者违约距离有上升趋势。
本文经实证研究发现,KMV模型有较好的追踪我国上市公司信用风险水平变化的效果,但是对于违约情况预测准确率却较低。
四、结论
(一)适用我国的信用风险度量模型
经过实证研究发现,LOGIT模型的预测准确率明显高于KMV模型,在提前一年的情况下, LOGIT模型能够以80%的准确率预测出公司是否会违约,而KMV模型对此的预测准确率仅约为70%,因此LOGIT模型可以更好地应用于预测我国企业是否违约。但是LOGIT模型没有对企业的追踪能力,无法像KMV模型一样根据资本市场价值的变化及时做出反应,KMV模型具有较好的预测企业信用风险变化情况的能力,因此KMV模型可以应用于追踪我国企业信用风险的变化趋势,从而帮助商业银行更好地预测企业是否会违约。我国商业银行使用信用风险度量模型时,可以应用LOGIT模型作为预测模型,并应用KMV模型作为追踪模型,当贷款企业的违约距离呈现出明显的下降趋势时,应引起商业银行的高度重视。将LOGIT模型与KMV模型相结合是我国商业银行度量信用风险的较好选择。
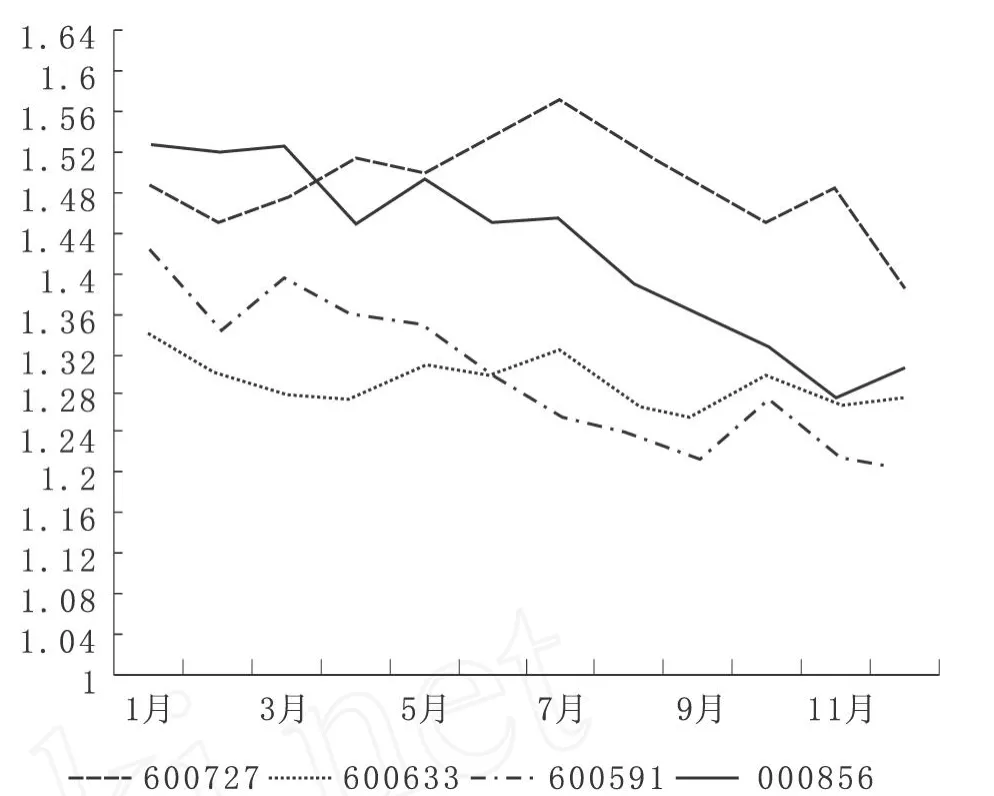
图3 *ST公司违约距离趋势
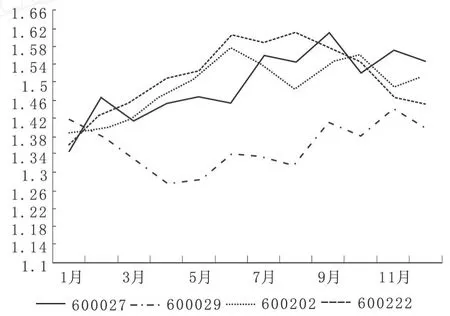
图4 非ST公司违约距离趋势
(二)提高信用风险度量模型预测能力
首先,完善公司信用风险信息数据库。信用风险度量模型的准确运用需要建立在大量公司信用信息的历史数据基础之上。我国商业银行信用评级体系尚不健全,公司信用历史数据积累不足,对于LOGIT模型而言,这会影响对模型本身的分析和评价;对KMV模型而言,这会影响公司违约点的设定和对于预期违约率的计算,因此对于信用风险度量模型的应用有着重要影响。
其次,加强对于证券市场及上市公司数据披露的监管。LOGIT模型应用上市公司财务报表中的财务比率对信用风险水平进行计算,KMV模型应用上市公司的股本数据和违约点数据进行计算,这就要求上市公司的数据必须及时、准确、真实可靠。但是,近年来我国上市公司财务丑闻事件频发,上市公司财务数据失真一方面会直接影响信用风险度量模型的准确性,另一方面会引起市场参与者对于证券市场的不信任,影响证券市场的长期发展,因此不利于商业银行使用上市公司的股本数据估算信用风险。
最后,建立外部评级体系,加强银行间的交流与合作。我国外部评级机构还在起步发展阶段,因此商业银行难以直接应用外部评级机构所提供的信用数据,这给巴塞尔新资本协议中内部评级法初级法的应用带来了一定困难,外部评级体系的建立有助于商业银行应用内部评级法。关于违约率和违约公司的数据是每个银行的机密。但是过度保密可能制约银行间关于信用风险度量的交流与合作,商业银行可以通过开展研讨会等形式,在不泄露本行机密的情况下加强银行间关于违约数据积累和违约模型应用的交流与合作。这样有利于我国商业银行更好地应用信用风险度量模型。
[1]Beaver,W.,1967,“Financial Ratios as Predictors of Failures in Empirical Research in Accounting”,Supplement to the Journal of Accounting Research,vol.4.
[2]Altman,Edward I.,1968,“Discriminate Analysis and Prediction of Corporate Bankruptcy”,Journal ofFinance,Vol.9.
[3]Altman,Edward I.,Haldeman,Robert G,Narayanan, P.,1977,“ZETA Analysis”,Journal of Banking&Finance,Vol.6.
[4]吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001,(06).
[5]沈沛龙,任若恩.我国商业银行信用风险的度量与控制[J].北京航空航天大学学报,2000,(04).
[6]李萌,陈柳钦.基于BP神经网络的商业银行信用风险识别实证分析[J].南京社会科学,2007,(01).
[7]都红雯,杨威.我国对KMV模型实证研究中存在的若干问题及对策思考[J].国际金融研究,2004,(09).
[8]李萌.LOGIT模型在商业银行信用风险评估中的应用研究[J].管理科学,2005,(04).
[9]Fischer Black,Myron Scholes,1973,“The Pricing of Options and Cooperate Liabilities”,The Journal of Political Economy,Vol.6.
[10]詹原瑞.银行信用风险的现代度量与管理[M].北京:经济科学出版社,2004.
Abstract:Credit risk is the main risk taken by commercial banks.Credit risk measurement models include Expert Judgment,Credit Scoring,Neural Network Analysis as well as Modern Default Probability Model.In this paper,LOGIT model and KMV model are compared.The 28 indexes are selected to reflect the company’s profitability,operating capabilities,capital structure,solvency,growth ability and cash flows.Forward Stepwise Regression is used to establish LOGIT model,which can predict company default 1 year before actual default.Then Assets Values of KMV model is calculated,through GARCH-M model Asset Volatility is calculated,and then the default rates of sample companies are estimated.Finally we get the discriminating result.Through comparison we bring forward that LOGIT model is fit for discriminating,at the same time KMV model is better for tracing.These two models should be combining to judge credit risk level of corporation in debt.
Key words:credit risk;LOGIT mode;KMV model
责任编辑:许瑶丽
A Study on Credit Risk Measurement of Chinese Commercial Banks
SUN Ning-hua,LIU Yang
(School of Business,Nanjing University,Nanjing 210093,China)
F832.332
A
1672-0539(2011)03-017-08
2011-02-28
孙宁华(1968-),河南人,南京大学经济学院经济系副教授,经济学博士,康奈尔大学经济学系访问学者,《经济研究》等杂志匿名审稿人;刘杨(1985-),黑龙江人,渣打银行南京分行,南京大学经济系硕士研究生。
