基于句法依存分析的文本水印算法
2011-07-05吴戈文大化
吴戈,文大化
(1.长春理工大学 电子信息工程学院,长春 130022;2.中国科学院 长春光学精密机械与物理研究所,长春 130033)
目前,数字水印被普遍认为是抵抗各种多媒体产品盗版及解决相关版权纠纷的“最后一道防线”。因此从水印技术角度来看,它的应用前景之广泛和经济价值之大受到了整个业界的瞩目。进入21世纪,人们对网络逐渐从认识过渡到熟悉,网络即给人们合法使用提供了方便,同时也使盗版也变得更加轻易,因此数字作品的管理、保护不仅成为业界迫切需要解决的问题,而且对非法使用数字作品的维权也成为司法界执行版权纠纷的要求。
电子文档就是以数据方式存于计算机中的文件,目前,即使视频和音频数字作品依托互联网快速发展,但文本数据依然是互联网上使用最多和传播最广的一种信息模式。因此如何保护电子文本版权,维护原创作者的权益,以及充分利用文本数据作载体进行隐蔽通信,对信息安全具有重要意义和实用价值。
1 文本水印
文本水印作为一种保护文本数据信息的技术,它的目的是保护在文本媒体中隐藏的信息不被非法使用者侵犯并可利用水印检测技术恢复和保留在数据中,从而实现文本所有权和跟踪对作品的侵权行为。目前已有的大部分文本信息隐藏方法集中于两个方面:一种是采用基于文本数据格式的方式,通过改变文本的排版特征嵌入隐秘信息。这种方法由于对媒体本身改动过于明显,很容易受到重新排版的影响,同时也很容易受到敌手的攻击,甚至隐秘信息被识别。另一种是基于自然语言算法的信息隐藏,其方法按照水印嵌入粒度可分为词汇层、句子层和篇章层。本文从句子层角度出发进行探讨的。
不论想在哪种载体(文本、图像、视频、音频等数字载体)中嵌入水印,都需要利用原有载体中存在的冗余现象。对于文本而言,由于其句法结构存在冗余,同时,由于语言在长期发展过程中形成的同一意思可用不同句式表达的特点,所以可以通过句法分析来寻找水印的嵌入点。
2 依存句法分析水印算法
2.1 算法思想
依存句法分析[1]有一个重要特点:绝大多数句子以动词为核心词,少量句子以形容词为核心词;同时由于很多句中都存在主谓关系(SBV),即存在依赖于核心词的名词、代词,图1为依存句法分析示例。根据上述特点并结合与句子中核心词有关的词汇用法,考虑到副词则是既有结构意义又有语用意义的词,所以可以考虑利用其结构意义设计水印算法。

图1 依存句法分析示例Fig.1 Example of dependency parsing
对于依存于核心词的主谓关系(SBV),要通过遍历找到构成主谓关系(SBV)的两个词中间是否还含有其他句法关系。如果除了状中结构(ADV)外,不再含有其他关系,则可以考虑删除状中结构(ADV)来嵌入水印信息;否则结构过于复杂,计算时间过长,不予考虑。如果原来主谓关系(SBV)的两个词中间没有其他句法关系,则可通过增加能构成状中结构(ADV)的词来嵌入水印信息。
由于核心词主要为动词和形容词,依存于核心词的构成主谓关系(SBV)的另一个词主要是名词和代词;而依存于核心词构成状中结构(ADV)的主要是副词,整个算法的关键就在于对副词的删减和增加上,所以要对副词进行分类讨论。
2.2 水印嵌入规则
针对副词的水印嵌入原则,提出以下句子结构特点:
(1)相对程度副词中的较高级、比较级、较低级中的各个词可以增删而基本不影响语义,而相对程度副词中的最高级和绝对程度副词都不能增删而只能替换。
(2)程度副词中的较高级、比较级、较低级中的各个词可以增删而基本不影响语义,而相对程度副词中的最高级和绝对程度副词都不能增删去而只能替换。
(3)范围副词的句子中,如果是全部总括型,可以删去;如果是部分总括型,不能删去可替换。在含统计性范围副词的句子中,如果是全部统计,可以删去;如果是部分统计型,不能删去可替换。如果是含有限定性范围副词或外加性范围副词,可以删去;
(4)基于语气副词特点提出对于表示或然语气“也许、或许”等词可以删去;表示必然语气“一定、必然、必定”等词可以删去;表示料定语气“果然、果真”等词可以删去;表示必要语气“必须、一定、务必”等词以及表示侥幸语气“幸亏、幸而、幸好”等词不能删去。
(5)对于不适合进行删去处理的副词,建立副词同义词词典,采用替换的方法嵌入水印。
2.3 算法流程
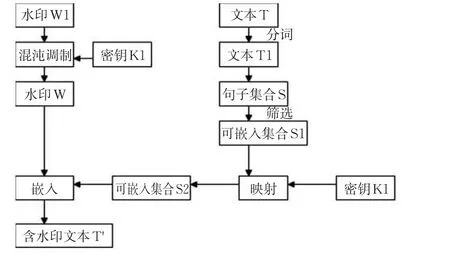
图2 基于句子分析的水印嵌入算法流程Fig.2 Flow chart of watermarking embedding algorithm
2.4 水印的嵌入和提取
水印嵌入的具体步骤如下:
Input:文本T,密钥K1,密钥K2,用户信息。
Output:含水印文本T’。
(1)使用拥有者和用户信息产生二进制水印序列W1,用密钥K1对W1进行混沌调制,得待嵌入水印信号W。
(2).利用分词系统对T进行分词,找到所有的句号、问号、惊叹号。建立句子集合
(3).对每个句子进行句法分析。找到每个句子的核心词(HED),对核心词前的句法结构进行分类,把含有SBV+ADV关系的句子合成一个子集S1,把其中构成ADV结构的副词合并成一个子集C’。
(4)计算S1的句子数目N,N=num(S1)

(6)利用密钥K2,把S1映射到与水印信息长度相同句子集合S2中。

(8)output T’
水印提取基本上是水印嵌入的逆过程,这里不再详尽叙述。
3 实验结果
本文选用了北大CCL语料库中的句子,截止2009年7月其规模已经达到4.77亿字。这里仅选取其现代汉语中的部分免费语料进行实验,选取的语料共10684个分句。对10684个句子利用哈工大的LTP平台进行分析,其中主要副词及可进行替换的情况统计如表1。
从表1中的数据可以得出水印嵌入容量为9.75%,高于文献[3]的算法。与文献[4]进行鲁棒性比较的结果如表2,从表中可以看出在实现比较容易的情况下,本文的方法在鲁棒性方面不弱于已经获得广泛认同的基于TMR树的方法。
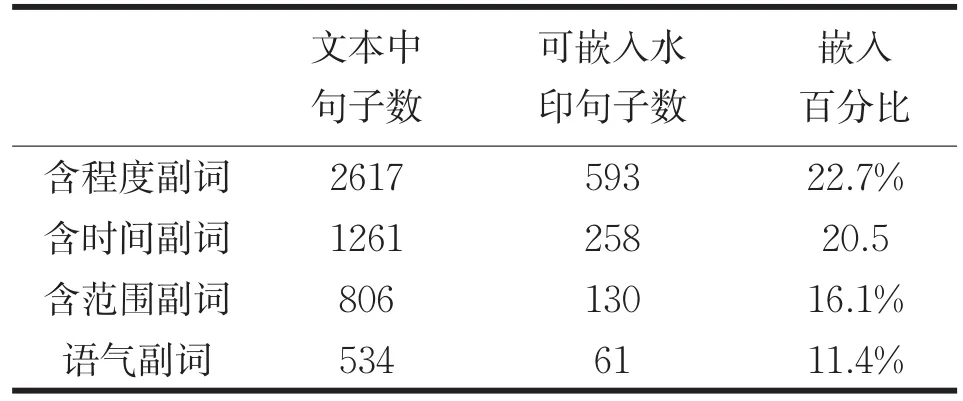
表1 实验文本中副词格变换的统计Tab.1 statistics of adverbs exchanging in texts
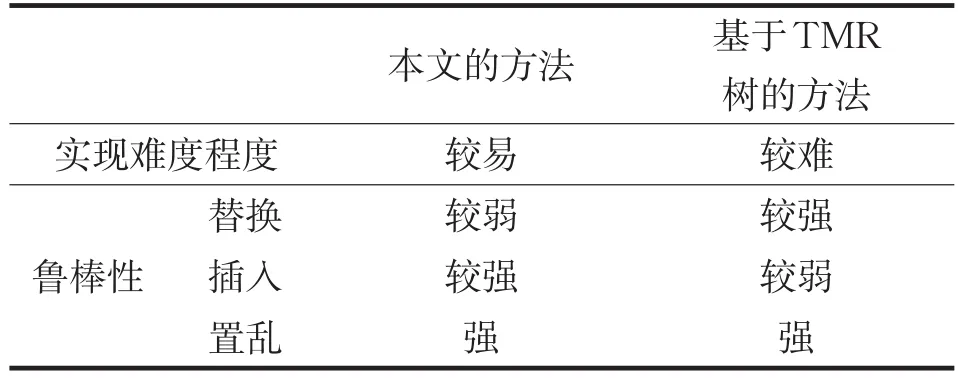
表2 与其他算法鲁棒性比较Tab.2 robustness comparison with other algorithms
4 结论
本文提出一种基于中文文本的句子层分析的信息隐藏方法,其特点是利用文本中大量存在的SBV⊃ADV结构,而对ADV结构中的副词进行合理的替换和增删通常对文本含义的表达不会产生较大的影响,这样就可以实现将信息嵌入到文本中的目的。实验结果表明本算法具有较好的鲁棒性和较大的水印容量。
[1]姜传贤,陈孝威.基于文本重要内容的鲁棒水印算法[J].自动化学报,2010,9(9):1250-1256.
[2]孙星明,殷建平,陈火旺,等.汉字的数学表达式研究[J].计算机研究与发展,2002,9(6):707-711.
[3]Gupta G,Pieprzyk J,Wang H X.An attack-localizing watermarking scheme for natural language documents[A].Proceedings of the ACM Symposium on Information,Computer and Communications Security[C].Taipei,2006:157-165.
[4]Atallah M J,Raskin V,Crogan.Metal Natural language watermarking:Design,Analysis and Proof-of-Concept Implementation[A].Proc of the 4th Information Hiding Workshop[C].Pittsburgh,2001:193-208.
