正向最大匹配分词算法的分析与改进
2011-07-04吴旭东
吴旭东
同济大学软件学院,上海 201804
0 引言
在自然语言处理中,“词是最小的能够独立活动的有意义的语言成分”[1],而汉语和英语等其它西文比起来,有着自身的特点。英语、法语等欧美语言在书写时就以词为基本构成单位,以空格作为分词的依据;而汉语在书写时是一大串汉字的字符串,从形式上根本没有词的概念。中文分词指的就是将一个汉字序列切分成一个一个单独的具有实际意义的词,它是中文信息处理的基础。中文自动分词的现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法[2]。
在基于字符串匹配的分词算法中,词典的设计往往对分词算法的效率有很大的影响。本文通过对影响正向最大匹配算法效率因素的分析,设计一种带词长信息的分词词典,同时在该词典基础上,对正向最大匹配算法做出一些改进,以提高分词的效率。
1 正向最大匹配分词算法介绍和分析
1.1 正向最大匹配分词算法介绍
最大匹配算法是最基本的字符串匹配算法之一,它能够保证将词典中存在的最长复合词切分出来。传统的正向最大匹配分词算法(Maximum Matching,简称MM算法)的算法流程如图1所示。
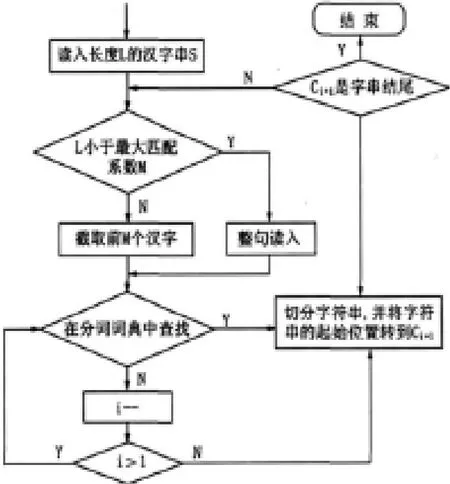
图1 MM 算法流程图
假设分词词典中的最长词的字数为M,令其作为最大匹配系数。假设读取的汉字序列字数为L,判断L是否小于最大匹配系数M。如果L大于最大匹配系数M,则截取前M个汉字作为待匹配字段进行匹配,否则取整个汉字序列作为待匹配字段直接在分词词典中进行匹配。若字典中存在这样一个字数为M的词,则匹配成功,匹配字段被作为一个词切分出来;若词典中找不到这样的词,则匹配失败,将待匹配字段中的最后一个字去掉,将剩下的汉字序列作为待匹配字段重新在字典中进行匹配处理……如此进行下去,直到匹配成功,即切分出一个词,或者直到剩余字串的长度为1为止,即为一个单字。这样就完成了一轮查找匹配,然后取剩下的汉字序列以同样的方法进行匹配处理,直到文档被扫描完为止。
1.2 算法分析
正向最大分词算法有个弊端,就是在算法开始前必须先预设一个匹配词长的初始值,而一般这个值是词典中最长词的长度,这个长度限制是最大匹配算法在效率与词长之间的一种折中。词长过长效率就比较低,词典中各个词的长度都不一致,有点较长,而有的却只是二字词或三字词。如果词长过长,在查找短字词时,将会出现许多无效的匹配,这在很大程度上影响了分词的效率。而如果初始值选取的过小,那么长词就不能得到有效的切分,达不到最大分词的目的。
根据汉语中词条的分布情况统计,在汉语中双字词语最多,而4字以上的词则比较少,如下表所示。可见,当初始值设置过长时,无效匹配的次数将在很大程度上消耗算法的效率。

表1 词条分布情况表
同时,在确定了词首字,在字典开始查找后,在以该词首字为前缀的词语中,词的长度一般都不是逐字减少的。比方说该字可能包含一个10字长的词语,但是并不含有9字,8字长的词语,而这时如果还是采用逐字减一的方法去匹配,又将增加无效匹配的次数,影响算法的效率。
2 改进的正向最大匹配分词算法
针对如上对正向最大匹配分词算法的分析,得出该算法在效率上存在的缺陷主要有:一固定最大匹配系数,二逐字递减的匹配。算法改进时将在这两方面做文章,使最大匹配系数能以词首字的改变而动态改变,同时在减字匹配过程中,不是每次都逐字减一再去字典匹配,而是利用词首字中包含的词长信息,来不定长的减字,以减少无效匹配的次数,从而在一定程度上提高算法的效率。
2.1 分词词典的设计
词典的组织结构为首字索引结构,所有以同一个字为首的词条都组织在一起。词典由两部分组成,一部分是首字索引,另一部分是词典的正文。索引部分由字和以该字为前缀的词条的词长信息两部分组成。正文部分为词条内容和词条长度两部分信息组成。其中词条长度是用来给词条排序的,以词长从大到小来组织词典的正文,同时在匹配过程中,先用词长比较来代替直接比较字符串的方法,在词长相等的情况下再比较字符序列,来提高匹配的效率,而且词长信息能有效的记录已查询列表的索应信息,从而在改变词长继续查找时,能高效地减少匹配次数。其机构如图所示。

图2 词典结构
Step1:取出待处理的汉字序列的首字,在首字hash表中查找,如果存在该字,则转step3;
Step2:不存在则是单字,分出该单字word,转step6;
Step3:取出该字的信息,包含词长信息和词典信息,转Step4;
Step4:遍历词长列表,按序分别取出词长设为匹配词长,然后在词典中查找,词典包含了词长值,在查找时先比较词长,若相等则再比较字符序列,转step5;
Step5:如果存在某一词长匹配成功,则分出该词word,转step7;
Step6:如果全部词长匹配都不成功,则说明是单字,分出该单字word,转step7;
Step7:从待分词序列中去掉已分出的词word,若汉字序列没有分词结束,转step1,否则结束。
例如:对语料“中华人民共和国是一个强大的国家”,使用本算法的处理过程如下:
1)取序列首字“中”在首字hash表中查询,存在该字则取出该首字信息,遍历词长信息列表得到,以该字为前缀的最长词
2.2 分词算法
长为14,则再取序列中余下的13个字“华人民共和国是一个强大的国”,在词典中匹配,发现匹配不成功;再取下一个词长得到词长为10,取序列为“华人民共和国是一个”,还是不成功……直到词长为7时,匹配“中华人民共和国”成功,取出该词。在匹配过程中,充分利用词长信息,在字符比较之前,先通过比较词长来筛选,在词长相等的情况下,才比较字符序列;
2)然后再取首字“是”,查找首字hash表,不存在以该字为前缀的词,分出单字“是”;
3)接着处理首字“强”,按照上述方法依次处理余下的字串;
4)最后得到的分词结果为:中华人民共和国/是/一个/强大/的/国家。
由以上的一次分词过程可以看出,动态设置最长匹配词长的方法,有效的避免和减少了传统MM算法(静态设置匹配词长的方法)的比较次数,大大的提高了长词匹配的效率。同时,利用比较先词长再比较字符的方法,也在一定程度上提高的算法的效率。
3 结论
本文主要通过对影响正向最大匹配算法效率的因素的分析,提出对该算法的一些改进,以及设计了相应的词典结构,以在匹配过程中尽可能的减少了比较的次数,在一定程度上提高了分词的效率。本文没有提供对歧义和未登录词的处理,而这是影响基于词典分词算法准确率的重要因素,这将是今后需要解决和处理的方向。
[1]朱德熙.语法讲义[M].商务印书馆,1982.
[2]张启宇,朱玲,张雅萍.中文分词算法研究综述情报探索,2008,l1.
[3]胡锡衡.正向最大匹配法在中文分词技术中的应用[J].鞍山师范学院学报,2008,10(2):42-45.
[4]孙茂松,左正平,黄昌宁.汉语自动分词词典机制的实验研究[J].中文信息学报,2000,14(1):1-7.
