基于语义关联的文本分类研究
2011-06-05张浩,谢飞
张 浩, 谢 飞
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.皖南医学院 基础医学部,安徽 芜湖 241000;3.合肥师范学院 计算机科学与技术系,安徽 合肥 230601)
0 引言
随着信息技术和互联网的飞速发展,人们可以获得越来越多的电子信息资源,但同时也需要投入更多的时间对这些信息进行组织和管理。为了减轻这种负担,人们开始研究采用计算机进行文本分类。文本分类(Text Categorization)就是在给定的分类体系下,让计算机根据文本的内容确定与它相关联的类别。文本分类是自然语言处理的一个重要的问题,主要应用于信息检索、自动文摘、信息过滤、邮件分类等。
文本分类中一个重要的问题是特征选择,通过特征选择减少文本的特征向量维数,提高分类的效率和精度。特征选择的基本思想是构造一个评价函数,对特征集的每个特征进行评估,选择类别区分能力强的特征构造特征集。已有的一些特征选择方法(如互信息、信息增益等)在构造特征评价函数时,重点考虑词语与类别的关联性,没有考虑词语之间的语义关联性。本文提出一种基于语义关联的特征选择方法,通过计算词语在文档中的语义关联性,将那些没有被特征选择方法选择的词语,但却与被选择的词语具有密切语义关联的词语加入特征空间中。实验表明,本文提出的基于语义关联的特征选择方法提高了文本分类的精度。
1 相关工作
1.1 文本分类研究现状
文本分类的研究开始于20世纪50年代,在60—80年代,基于知识工程的文本分类方法占据主导地位,这类方法由于使用人工构造的知识库,分类准确度较高,但缺点是知识库构造困难,难以大规模地应用。90年代以来,随着电子文档的大规模出现,基于机器学习的方法得到了广泛的应用,具有代表性的分类模型有k近邻(KNearest Neighbor,简称 KNN)、朴素贝 叶斯(Nave Bayes,简称 NB)、决策树、神经网络、支持向量机(Support Vector Machine,简称SVM)、Boosting、Bagging[1]等。
文献[2]对常见的几种分类算法进行了比较,得出KNN和SVM是2种比较好的分类算法。KNN是一种懒惰的学习算法,不需要训练过程,当测试文档到来时,通过计算训练文档集中与待分类文档最近的k个邻居来确定测试文档的类别,因此当训练文本数量很大时,计算开销会比较大。SVM是一种基于统计学习的方法,具有很高的分类精度和良好的泛化能力,但是在大规模训练集上学习的时间和空间开销比较大。
国内很多学者对文本分类进行了深入的研究,取得了很好的成绩。如文献[3]提出一种基于机器学习的、独立于语种的文本分类模型;文献[4]在论述隐含语义索引理论的基础上,研究了隐含语义索引在中文文本处理中的应用;文献[5]使用最大熵模型对中文文本分类进行了研究;文献[6]提出一种以 WordNet语言本体库为基础,建立文本的概念向量空间模型作为文本特征向量的特征提取方法;文献[7]研究了混淆类的判别技术,改善了文本分类的性能;文献[8]针对Bagging算法弱分类器具有相同权重的问题,提出一种改进的Bagging算法;文献[9]提出一种基于模糊支持向量机的多主题文本分类算法;文献[10]针对特征空间中的冗余信息,提出一种基于聚类的文本特征选择方法;文献[11]研究了文本分类中用于协同的特征集分割问题;文献[12]利用类关联词实现对完全未标注文档的分类;文献[13]针对文本向量的高维性,提出用张量表示文本,提高了分类的精度。
1.2 文本表示
文本的特征表示是文本分类面临的首要问题,向量空间模型(VSM)[14]是应用最多且效果较好的方法之一。在向量空间模型中,假设项或特征的维数是n,每一个文档d可以表示为一个n维的向量,即

其中,ti为词条项;ωi(d)为ti在文本d中的权值,一般采用TFIDF向量表示法:

其中,tfi(d)为词条ti在文档d中出现的词频;N为所有文档的数目;ni为出现了词条ti的文档的数目,分母为归一化因子。
文档di和dj的向量表示为:di=(ωi1,ωi2,…,ωin)T,dj=(ωj1,ωj2,…,ωjn)T。di和dj的相似度可以用向量空间的夹角余弦定义,即

1.3 特征选择
文本分类要解决的主要问题之一是降低特征向量的维数,特征选择和特征抽取是2种重要的降低文本向量维数的技术。
传统的特征选择方法主要有:文档频率(DF)、信息增益(IG)、χ2(CHI)统计量、互信息(MI)等。文献[15]分析和比较了这4种方法,结合KNN分类器,得出IG和CHI方法效果相对较好的结论。本文选用IG方法。

其中,P(ci)为ci类文档在语料中出现的概率;P(t)为语料中包含词条t的文档概率;P(ci|t)为文档包含词条t时属于ci类的条件概率;P(¯t)为语料中不包含词条t的文档概率;P(ci|¯t)为文档不包含词条t时属于ci类的条件概率;m为类别数。
2 基于语义关联的文本分类方法
2.1 词语语义关联性
词语语义关联可以通过计算词语在文档中同一窗口中的共现性来度量,即“词共现模型”。其基于如下假设:2个词经常共同出现在文档的同一窗口(句子或段落),则认为这2个词在语义上关联,并且共现的概率越高,其相互关联越紧密。
本文采用Dice Coefficient[16]计算2个词语的关联度,其计算公式为:

其中,x、y为文档中2个词语;p(x)、p(y)为x、y在文档中出现的概率;p(x,y)为x与y在文档句子中共同出现的概率。
2.2 基于词语关联的文本分类算法
基于词语关联的文本分类算法(Text Categorization based on Semantic Relatedness,简称TCSR)描述如下:
(1)对训练文本集中每个文档d进行分词,去除停用词,根据(6)式计算词语x的平均关联度值,即

其中,y为文档d中词语;n为文档d中词语的个数。
(2)根据词语关联度值从大到小选择n个词语作为文档d的特征词。
(3)构造训练文档集的词语特征空间,将训练文本表示成空间向量形式。
(4)构造文本分类器,本文采用 KNN分类法。
(5)对新的测试文本,将测试文档表示为向量形式,根据构造的分类器判断测试文本的类别。
上述算法中参数单个文档选择的特征词数目n和KNN算法中k的值由实验确定。
3 实验结果及分析
3.1 文本分类数据集及评测标准
本文使用复旦大学建立的测试文档库测试的算法,表1列出了这些测试文档类的类名及其包含的文档数目。任意选取其中1 883篇作为训练集,934篇作为测试集。采取宏平均F1值来评价文档分类的性能[17]。
3.2 实验结果及分析
KNN文本分类方法中参数k值选择大小对文本分类性能的影响,如图1所示。实验中,k的取值范围为15~35,从图1可以看出,当k取值为20时,分类效果最佳。

图1 k值对文本分类性能影响
基于语义关联的特征方法中,单文档选择的特征词数目对文本分类的影响如图2所示。单文档选择的特征数目依次为20、30、50、80、100、120,对应的总特征词数目见表2所列。从图2可以看出,当单文档选择特征词数目为80时,分类效果最好。
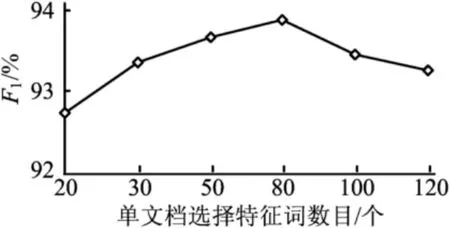
图2 单文档特征选择数对文本分类性能影响

表2 文本特征选择数与总特征选择数对应关系
基于语义关联(TCSR)、基于信息增益(TCIG)、基于χ2统计(TCX2)3种特征选择方法对文本分类性能影响的比较,如图3所示。从中可以看出,TCSR在选择特征数为22 851时,分类效果最佳;TCIG在选择特征数为13 762时,分类效果最佳;TCX2在选择特征数为18 214时,分类效果最佳。这说明,在取得最优分类效果时,基于语义关联的特征选择方法比信息增益和χ2统计方法选择的特征词数目数要多。这是因为基于语义的特征方法在选择重要特征词的同时,把与这些特征词密切相关的词语也选择了进来,所以总特征数比一般的特征选择方法要多。

图3 TCSR、TCIG和TCX2特征选择方法比较
从图3中还可以看出,在取得最优分类效果情况下,基于语义关联的特征选择方法比基于χ2统计特征选择和基于信息增益特征选择方法效果好,这说明本文提出的基于语义关联的特征选择方法能够提高文本分类的精度。
4 结束语
本文介绍了文本分类技术研究现状,讨论了文本的向量空间模型表示和特征选择等相关技术,提出了一种基于语义关联的特征选择方法,利用文档中词语之间的语义关联性抽取表示文档的特征词。实验表明,本文提出的基于语义关联的特征选择方法比传统的信息增益和χ2统计特征选择方法提高了文本分类的精度。
[1]苏金树,张博锋,徐 昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9):1848-1859.
[2]Yang Y,Lin X.A re-examination of text categorization methods[C]//The 22nd Annual ACM SIGIR Conf on Research and Development in Information Retrieval.New York:ACM Press,1999:42-49.
[3]黄萱菁,吴立德,石崎洋之,等.独立于语种的文本分类方法[J].中文信息学报,2000,14(6):1-7.
[4]周水庚,关佶红,胡运发.隐含语义索引及其在中文文本处理中的应用研究[J].小型微型计算机系统,2001,22(2):239-244.
[5]李荣陆,王建会,陈晓云,等.使用最大熵模型进行中文文本分类[J].计算机研究与发展,2005,42(1):94-101.
[6]张 剑,李春平.基于 WordNet概念空间模型的文本分类[J].计算机工程与应用,2006(4):174-178.
[7]朱靖波,王会珍,张希娟.面向文本分类的混淆类判别技术[J].软件学报,2008,19(3):630-639.
[8]张 翔,周明全,耿国华,等.Bagging算法在中文文本分类中的应用[J].计算机工程与应用,2009,45(5):135-137.
[9]秦玉平,王秀坤,艾 青,等.基于模糊支持向量机的多主题文本分类算法研究[J].小型微型计算机系统,2008,29(3):548-551.
[10]张文良,黄亚楼,倪维健.一种基于聚类的文本特征选择方法[J].计算机应用,2007,27(1):205-209.
[11]张博锋,苏金树.文本分类中用于协同的特征集分割[J].计算机科学,2009,36(2):203-210.
[12]韩红旗,朱东华,刘 嵩,等.关联词约束的半监督文本分类方法[J].计算机工程与应用,2010,46(4):113-116.
[13]何 伟,胡学钢,谢 飞.基于张量空间模型的中文文本分类[J].合肥工业大学学报:自然科学版,2010,33(12):1806-1810.
[14]Salton G,Wong A,Yang C S.On the specification of term values in automatic indexing [J].Journal of Documentation,1973,29(4):351-372.
[15]Yang Y.A comparative study on feature selection in text categorization[C]//Proceeding of the Fourteenth International Conference on Machine Learning(ICML’97),1997:412-420.
[16]Grzegorz K,Daniel M,Kevin K.Cognates can improve statistical translation models [C]//Proceedings of HLTNAACL 2003:Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics,2003:46-48.
[17]周 茜,赵名生,扈 旻.中文文本分类中特征选择[J].中文信息学报,2004,18(3):17-23.
