基于垂直分布方法的关联规则算法及改进
2011-05-17杨振华
杨振华
(西安文理学院 计算机科学系,陕西 西安710065)
数据库中大量的数据与数据之间存在着某种联系,这种数据之间的联系就属于一种重要的知识,也是进行数据挖掘的对象,即关联规则挖掘[1]。在众多的关联规则挖掘算法中最著名的是Apriori算法[2]。它的基本思想是使用一种逐层搜索的迭代算法。但是Apriori算法也有明显的缺点:每次都会产生大量的候选频繁项集,而且候选频繁项集呈指数级增长。每产生一个频繁项目集就需要扫描一次完整的数据库。这些都需要耗费巨大的系统资源而且算法的执行速度、效率也比较低。因此人们提出了许多改进的Apriori算法,本文吸取前人的经验提出了一种新的改进Apriori算法,称为Apriori-Evo算法。
1 Apriori算法分析
Apriori算法的基本步骤是:首先扫描事务数据库D中的事务,统计各个项目出现的次数来产生频繁项目集L1,然后由 L1×L1进行连接运算生成候选 2-项集 C2,扫描数据库统计各个候选2-项集出现的次数,确定其中的频繁 2-项集 L2。再由 L2×L2进行连接运算产生候选3-项集C3,一直反复进行这个过程生成频繁k-项集Lk,直到无法再生成频繁项目集为止。
Apriori的算法描述如下:

主算法逐层迭代产生 L1→C2→L2→C3→L3…直到Lk=φ为止。到此所有的频繁项目集都找到了。
procedure aproiri_gen(Lk-1:frequent(k-1)-itemset;min_sup:support)

代码中 apriori_gen()函数[3]主要完成两个动作:连接和剪枝运算。Lk-1与Lk-1进行连接生成候选频繁项集。然后剪枝部分利用Apriori的性质删除掉包含非频繁子集的候选。
Apriori算法的主要缺点是会产生大量的候选项集,如果频繁1-项集有10 000个,则候选2-项集的个数将超过10 000 000个,算法实现时,大量的候选2-项集都被存放在哈希树中,对它们的统计和测试所需要的开销会很大;每产生一个频繁项目集就需要将整个事务数据库扫描一遍,大大降低了系统I/O效率。
2 对Apriori算法的改进
关联规则具有如下性质:
(1)对于项目集 X和它的任意子集 Y,如果 X是频繁的,则它的子集Y一定也是频繁的。
(2)对于项目集 X和它的任意子集 Y,如果 Y是非频繁项目集,则X也一定不是频繁项目集。
(3)X是k维项目集,如果频繁项目集Lk-1中包含的X的子集个数小于k,则X不可能是频繁项目集。
利用它的性质对Apriori算法从以下三方面进行了改进。
(1)在剪枝阶段减少扫描Lk-1的次数
进行剪枝的工作原理是:根据关联规则的性质,Ck中的一个项集如果是频繁项集,那么它一定有K个k-1项频繁子集,且这K个k-1项频繁子集一定都在Lk-1当中。因此以往的对Ck的剪枝过程都是先取出一个候选k项集,然后产生它的K个k-1项子集,再扫描一次Lk-1查看这K个k-1项子集是否都在 Lk-1中,如果不是则剪掉这个候选k项集,如此循环。如果产生m条候选k项集,就需扫描Lk-1项集m次。然而频繁项集具有性质3[4]。所以不需要扫描 Lk-1次。首先进行 Lk-1×Lk-1的连接运算生成所有的候选项集Ck,然后取出Lk-1中的第一个频繁k-1项集,查看该k-1项集是Ck中哪些k项集的子集,如果是子集,则对相应的k项集进行计数。然后再从Lk-1中取出第二个频繁k-1项集,再到Ck中去查看它是哪些k项集的子集,直到Lk-1中的各个项集都比对完成。最后,查看Ck中的每个k项集,如果它的计数小于k,则它不可能是频繁k项集,需要删除。因为频繁k项集一定有k个k-1项子集存放在Lk-1中。这样整个剪枝步骤只需要扫描Lk-1一次,提高了剪枝步骤的效率和开销。
(2)统计阶段减少扫描的工作量
对于数据库D中的事务数据先把它转换成一个矩阵。矩阵结构[5]如下,其中T为事务,I为项目集:

矩阵的一列对应数据库D中的一条事务记录,例如记录 T1:I1,I2,I5和 T2:I2,I3,I5对应的矩阵。
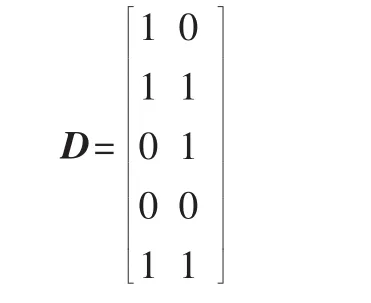
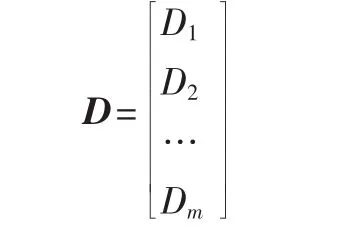
向量 Di与向量 Dj的内积运算记为:[Di,Dj]=di1×dj1+di2×dj2+…+din×djn。
对于Apriori算法过程中产生的候选2-项集C2中的一个项目集(I2,I3),以往需要扫描数据库 D中每一条事务来统计(I2,I3)的支持度。现在只需要对行向量D2与D3做内积运算就可以了。 它们内积[6]的和就是(I2,I3)的支持度。 对于项目集(I1,I2,I5,I7)只需要对 D1、D2、D5、D7这四个行向量相应的列元素做与运算,然后各个列的运算结果相加,就得到了该项目集的支持度。
(3)对用于连接的频繁项目集进行精简,减少无用候选的产生。
对于产生的频繁项目集Lk-1,Apriori算法直接用它连接产生候选频繁项目集Ck。但实际上Lk-1中的有些项目集已经对产生Lk不起作用了,包含这些项目集的候选k-项集一定不是频繁的,因此可以对频繁项目集Lk-1进行精简。
根据频繁项集的性质[7],当要用Lk-1连接产生Ck时,首先统计Lk-1中各个项目出现的次数,如果该项目出现的次数小于k-1,则该项目所在的项目集不用来链接生成Ck[8]。
例如:有频繁 3-项目集{I1,I2,I3},{I1,I2,I5},{I1,I3,I4},{I1,I3,I5},{I1,I3,I6},{I1,I4,I5},{I1,I4,I6}。 如果直接用它们进行连接产生的候选 4-项集为:{I1,I2,I3,I5},{I1,I3,I4,I5},{I1,I3,I4,I6},{I1,I3,I5,I6},{I1,I4,I5,I6}共 5 个。
按照统计频繁 3-项集中 I1出现 7次,I22次,I34次,I43次,I53次,I62次。在频繁4-项集中的每一个项目在频繁3-项目集中应该出现3次,所以应该从频繁 3-项目集中去除掉:包含 I2、I6(出现次数小于 3)的项目集,只保留{I1,I3,I4},{I1,I3,I5},{I1,I4,I5}。 而它们产生的Ck为{I1,I3,I4,I5}只有1个。这样新产生的候选频繁项集的数据将大幅减少。
综上所述,从三个方面改进了Apriori算法,以此大幅度提高了数据挖掘的效率。新算法的描述如下:


3 实验结果分析
在由Lk-1连接产生Ck阶段Apriori算法,每产生一个Ck的项目集就扫描一次Lk-1,一共需要进行|Ck||Lk-1|k次运算,而Apriori-Evo算法只需要扫描 Lk-1一次,只需要进行|Lk-1||Ck|次运算。在扫描事务数据库D统计各个候选频繁项集的支持度阶段,Apriori算法每产生一个频繁项集{I1,I2…}就需扫描整个数据库一次。Apriori-Evo算法每产生一个频繁项集{I1,I2…}只需要 I1、I2所在的行做运算即可。最后,由Lk连接产生Ck+1阶段,Apriori算法直接用Lk进行连接。而Apriori-Evo算法先删除掉Lk中对产生Lk+1没有作用的项目,缩小了产生的Ck体积。本文从三个方面对原有算法进行了改进。最后,通过实验将改进的Apriori算法与原来的算法进行了比较,从数据库中分别提取 1 000、2 000、3 000、4 000条记录进行数据挖掘,最小支持度设为25%,运行时间如图1所示。

实验结果表明,改进的Apriori-Evo算法确实在关联规则数据挖掘的速度和效率方面有很大的提高,而且随着事务数据的增多,提升效果更加明显。
新的算法从三个方面对原有的算法进行了改进,减少了产生的候选频繁项集Ck中项集的数据,也减少了剪枝过程中的运算次数,在统计支持度阶段减少了需要扫描的数据库中的事务数。而且计算机进行向量运算和位运算速度更快,程序也会更容易实现。实验证明,新算法在系统的开销和时间效率上都有很大的提高。
[1]HAN J,KAMBER M.数据挖掘:概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2001.
[2]AGRAWAL R,IMIEL NSKI T,SWAM I A.Mining asso-ciation rules between sets of items in large database[A].In Proc.of the ACM SIGMOD Intl Conf.on Management of Data[C].Washington D.C.,1993:207-216.
[3]AGRAWAL R,SRIKANT R.Fast algorithms for mining association rules[C].Morgan Kaufmann,San Francisco,CA:Proceedings of the 24th International Conference on Very Large Databases,1998:478-499.
[4]李绪成,王保保.挖掘关联规则中Apriori算法的一种改进[J]. 计算机工程,2002,7(28):104-105.
[5]罗芳,李志亮.一种基于压缩矩阵的Apriori改进算法[J].科技资讯,2010(4):19.
[6]刘以安,羊斌.关联规则挖掘中对 Apriori算法的一种改进研究[J].计算机应用,2007,27(2):418-420.
[7]盛立,刘希玉,高明.挖掘关联规则中AprioriTid算法的改进[J].山东师范大学学报(自然科学版),2005,20(4):20-22.
[8]叶福兰,施忠兴.Apriori算法的改进及应用[J].现代计算机,2009(9):95-126.
