聚类算法及聚类融合算法研究
2011-03-26赵向梅王艳君刘林
赵向梅,王艳君,刘林
(西安欧亚学院信息工程学院,陕西西安710065)
俗话说:“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程称为聚类[1]。为了找到效率高、通用性强的聚类方法,人们从不同角度提出了许多种聚类算法,一般可分为基于层次的,基于划分的,基于密度的,基于网格的和基于模型的聚类算法5大类。
1 常用聚类算法介绍
1.1 基于层次的聚类算法
基于层次的聚类算法对给定数据对象进行层次上的分解,直到某种条件满足为止,可分为凝聚算法和分裂算法。例如在自底向上的凝聚算法方案中,初始时每一个数据纪录都组成一个单独的组,在接下来的迭代中,它把那些相互邻近的组合并成一个组,直到所有的记录组成一个分组或者某个条件满足为止。代表算法有:BIRCH算法、CURE算法、CHAMELEON算法等。
1.2 基于划分的聚类算法
给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K<N。而且这K个分组满足下列条件:1)每一个分组至少包含一个数据纪录;2)每一个数据纪录属于且仅属于一个分组;对于给定的K,算法首先给出一个初始的分组方法,以后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次好,而所谓好的标准就是:同一分组中的记录越近越好,而不同分组中的纪录越远越好。使用这个基本思想的算法有:KMEANS算法、K-MEDOIDS算法、CLARANS算法。
划分法收敛速度快,在对中小规模的数据库中发现球状簇很适用。缺点是它倾向于识别凸形分布大小相近、密度相近的聚类,不能发现分布形状比较复杂的聚类,还要求用户预先指定聚类个数。
1.3 基于密度的聚类算法
基于密度的聚类算法,其指导思想是:只要一个区域中的点的密度(对象或数据点的数目)大过某个阈值,就把它加到与之相近的聚类中去。该法从数据对象的分布密度出发,把密度足够大的区域连接起来,从而可发现任意形状的簇,并可用来过滤“噪声”数据。常见算法有DBSCAN,DENCLUE算法等。
1.4 基于网格的聚类算法
首先将数据空间划分为有限个单元的网格结构,然后对划分后的单个的单元为对象进行聚类。该算法优点是处理速度快,处理时间与数据对象的数目无关,一般由网格单元的数目决定。缺点是只能发现边界是水平或垂直的聚类,不能检测到斜边界,该类算法也不适用于高维情况。典型的算法有STING,CLIQUE等。
1.5 基于模型的聚类算法
基于模型的方法给每一个聚类假定了一个模型,然后去寻找能够很好满足这个模型的数据集。这个模型可能是数据点在空间中的密度分布函数,它由一系列的概率分布决定,也可能通过基于标准的统计数字自动决定聚类的数目。它的一个潜在假定是:目标数据集是由一系列的概率分布所决定的。通常有2种尝试方向:统计的方案和神经网络的方案。
2 聚类融合
处理很多现实问题时,需要将数据聚类。例如银行根据客户的个人属性、交易行为等对客户进行风险评估,其数据集不但海量,而且数据属性包括数值属性和类属性[2]。以上列出的5种常用聚类算法不能有效处理这类数据集,无法对类属性和混合型属性的数据集进行聚类。
聚类融合方法是近年聚类分析的研究趋势,其基本思想是用若干独立的聚类器分别对原始数据进行聚类,然后对这些结果进行组合,最终获得对原始数据进行的聚类结果。详细说明如下所示:设有N个样本的样本集X,对数据集X进行H次不同聚类算法得到H次聚类结果[3]。通过共识函数G,把H次聚类得到的聚类成员融合得到C*,融合过程如图1所示。
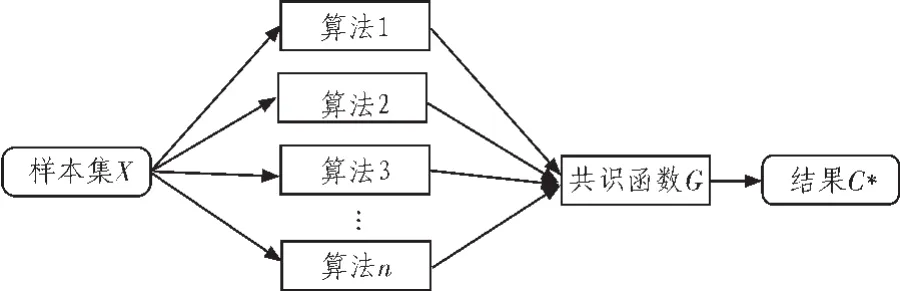
图1 聚类融合过程图Fig.1 Procedure chart of clustering fusion
聚类融合算法比单一聚类算法具有鲁棒性、稳定性和适用型等优势。因此,目前聚类融合研究的重点一般是:如何产生高效的聚类成员;共识函数如何构建才能产生高效的聚类融合算法。
2.1 聚类成员产生
可以通过选择不同的算法,对同一个算法选择不同的初始值、选择不同的对象子集及选择不同的特征子集投影到数据子空间等来产生聚类成员。
Topchy[4]等主要研究了由“弱”聚类组成的聚类成员对聚类融合的影响。“弱”聚类指比随机划分好一点的聚类。他们用实验结果表明,由“弱”聚类组成聚类成员实现的聚类融合算法,其结果普遍好于单一的经典聚类算法。
Fern和Brodley[5]通过实验说明,在不同的随机投影下得到的不同的聚类结果是互补的,由此可以推测基于随机投影的方法是一个获得聚类成员的很好方法。
2.2 改进的随机投影聚类方法
下面对一种改进的随机投影方法[6]进行说明,算法具体步骤如下:
1)在原始数据集X中随机选择k个初始聚类中心;
2)计算原始记录中每个属性Aj所有类别取值ti,j对应的频率,将频率满足条件f(ti,j)>β的记录保存在二维数组中;
3)根据得到的二维数组选择保存与聚类中心关系密切的维向量qj,1≤j≥m;扫描目标数据集,寻找与每条记录最相似的聚类中心实现聚类,对小于界限值的记录进行归类;
4)从初始的随机聚类中心中选择并保存好的聚类中心,删除无效的聚类中心,算法的选择标准为若该聚类中的所有记录所属类别相同,则将相关记录从待测数据集X中移除。若记录数大于界限值,返回步骤1);
5)对于未被聚类的数据对象作为异常点处理。
运用该方法生成聚类成员,实验表明[6]它能够得到更多类别的基本聚类成员,融合性能好。
2.3 共识函数的构建
共识函数的设计方法主要有共联矩阵法、投票法、信息论方法、超图法和混合模型法。
Topchy等用一个多项式分布的混合模型构建共识函数,然后使用EM算法求解最终的聚类。这种方法完全避免了标志匹配的问题,而且能够处理丢失的数据。
3 结论
本文研究了常用聚类算法及聚类融合算法。并对如何产生高效的聚类成员和共识函数如何构建才能产生高效的聚类融合算法进行了说明,运用改进的随机投影算法来生成聚类成员,实验表明随机投影是一个生成聚类成员的很有效的方法。最后得出运用聚类融合算法能得到更好的聚类效果的结论。如何把聚类融合方法运用到具体问题上,是下一步研究的方向。
[1]HAN Jia-wei.Data mining:concepts and techniques[M].San Francisco:Morgan Kaufmann Publishers,2001.
[2]赵宇,李兵,李秀,等.混合属性数据聚类融合算法[J].清华大学学报:自然科学版,2006,46(10):1673-1676.
ZHAO Yu,LI Bing,LI Xiu,et al.Cluster ensemble method for databases with mixed numeric and categorical values[J].Journal of Tsinghua University:Science and Technology,2006,46(10):1673-1676.
[3]秦锋,陈奇明,程泽凯.聚类融合算法研究[J].计算机技术与发展,2010,20(7):106-108,113.
QIN Feng,CHEN Qi-ming,CHENG Ze-kai.An overview of clustering ensemble approaches[J].Computer Technology and Development,2010,20(7):106-108,113.
[4]Topchy A,Jain A K,Punch W F.Combining multiple weak clusterings[C]//The Proceedings of the 3rd IEEE International Conference on Data Mining,2003:331-338.
[5]Fem X Z,Brodley C E.Random project ion for high dimensional data clustering[C]//A cluster ensemble approach.In:Proceedings of the Twentieth International Conference on Machine Learning,2003:186-193.
[6]汪海英,卢辉斌,李振平.基于聚类融合算法的高维数据聚类的研究[J].电子测量技术,2008,31(4):41-45.
WANG Hai-ying,LU Hui-bin,LI Zhen-ping.Study of high dimensional data clustering based on cluster ensembles algorithm[J].Electronic Measurement Technology,2008,31(4):41-45.
