基于分隔符和上下文术语的领域现象术语抽取*
2011-03-21刘里刘小明
刘里 刘小明
(北京理工大学计算机学院,北京100081)
术语是某种语言中专门指称某一专业领域一般(具体或者抽象)理论概念的词汇单位[1].领域术语集体现了领域的核心知识.自动术语抽取是信息抽取领域的重要研究课题,其在特定领域的应用需求越来越大:医疗、生物、计算机科学等领域均需要术语集来构建领域知识库.
传统的术语自动抽取技术可以归纳为基于统计和基于语言学知识两种方式.广泛采用的统计类术语抽取技术有基于语言模型统计领域相关性、领域一致性的方法[2]、基于互信息的方法[3]等.这些方法对候选结果按照统计指标进行排序,提取指标排序靠前的结果作为最终结果.基于语言学知识的术语抽取普遍采取利用术语的上下文环境,运用机器学习方法训练模型,进行自动抽取,这在特定领域取得了不错的效果[4].近期的术语抽取技术常常面临3个难点:(1)部分术语可以利用的上下文特征比较少,使得基于上下文的术语抽取算法无能为力;(2)传统算法是建立在待处理文本正确分词的基础上的;(3)对前期的领域知识(如领域词库)有较高依赖性,不便于跨领域移植.
传统的名词性术语抽取方法较多利用术语的领域特性,并对其赋予权重来识别[5].然而,这些方法常常碰到的困难是:对于非名词性术语,少量特征难以将其识别出来,过多的特征又会匹配多个特征而对术语识别产生冲突.针对这些问题,文中对领域现象术语提出了一种有效的抽取方法.
领域现象术语一般都是动词性复合词.动词性复合词是指由至少一个动词性语素构成的复合词[6].例如,在电脑故障诊断领域,“停转”、“蓝屏”、“掉线”等都是动词性复合词.文中选取复合型领域现象术语作为考察对象是基于以下考虑:(1)在特定领域,现象术语作为术语出现的概率较高,且可能和名词性术语一同出现在特定领域的词库中,然而这一类复合型术语往往不具备专门的词库,难以与名词性术语区分开来;(2)领域现象术语可以作为故障诊断领域的“条件属性+取值”的组合,抽取结果可以作为问句的条件值,推动问答系统的发展.复合词的一个突出特点是难以与短语划清界限,这是汉语研究中长期存在的一个难题.在自然语言处理(NLP)研究中,如果将这一类术语作为短语处理,由于短语结构的不确定性,难以得到理想的结果.文中从词语的角度进行处理,如果能够取得较高的正确率,会对此类复合词的处理有所启发.
1 领域现象术语抽取算法
1.1 分隔符的概念
句子是由实词和虚词连接构成的,常见的领域现象术语倾向于实词.对于句子中的一个词,与它相邻的前后两个词,分别称为它的前驱与后驱,有研究者将这两个词称作分隔符[7].
与领域术语相比,分隔符更有可能是虚词或一般性的实词,并且具有一定的领域独立性,更容易被识别出来.文中利用分隔符的特征进行术语抽取,即通过识别术语的前驱与后驱来标记术语,在两个术语分隔符之间的字符串可看作是候选术语.
先分析下面的两个例子:“云计算是一种基于因特网的超级计算模式”来源于计算机领域的一篇学术文章,其中的“云计算”、“因特网”和“超级计算模式”是计算机领域的术语,它们以术语分隔符“是”、“的”和“基于”为边界;“人民代表大会制度是中华人民共和国的基本政治制度”来源于《中华人民共和国宪法》,其中的“人民代表大会制度”、“中华人民共和国”和“基本政治制度”是法律领域术语,它们被分隔符“是”和“的”所标记.可以看出“是”和“的”在两个不同领域均是术语分隔符,由此可见分隔符具有一定的领域无关性.分隔符与术语关联,在使用时也较稳定,因此分隔符可以作为术语的边界标志.
1.2 分隔符的抽取
为了获得更好的抽取效果,文中采取停用词表与词频相结合的分隔符抽取方法.
1.2.1 基于词频的分隔符抽取方法
基于词频的分隔符抽取方法是统计领域中术语的高频前驱后继,并过滤掉领域术语,具体步骤如下:(1)对术语词典中的每个术语,如果其在训练语料中出现则进行标记;(2)对训练语料进行分词,对标记过的术语不进行切分;(3)抽取每个术语的前驱和后继,组成候选分隔符集;(4)对每个候选分隔符,如果其是术语词典中的术语,则将其从候选分隔符集中移除;(5)统计候选分隔符在训练语料中的词频,选取词频较高的候选分隔符作为分隔符.
1.2.2 领域停用词与分隔符的关系
停用词是指出现频率较高、没有太大检索意义的词,如“的”、“了”、“太”、“of”、“the”等.在知识抽取中几乎没有真正的停用词,只是把出现频率较高的虚词作为临时的停用词,切分完后仍然需要标记[8].主谓结构的上下文以常用虚词为主.可见,主谓结构的上下文相当于领域停用词,并成为主谓结构的分隔符.
经统计,领域现象术语在主谓结构中出现的概率较高.因此,将领域停用词表中的词加入领域现象术语的分隔符表,可以使分隔符表更加完善,提升领域现象术语抽取的效果.
1.2.3 分隔符混合抽取方法
将1.2.1节中基于词频方法抽取得到的分隔符表加上1.2.2节中的领域停用词表,得到分隔符抽取的最终结果.
在分隔符抽取阶段需要进行分词,且难免出现分词错误.不过分词错误不会对领域现象术语抽取的最终结果造成影响,因为分词错误出现在分隔符抽取阶段而不是领域现象术语抽取阶段,而且分隔符的权重算法也大大降低了分词错误造成的影响.
1.3 抽取算法详解
文中算法是建立在术语抽取经典算法NC-value基础上的,NC-value算法利用上下文统计和语言学信息进行术语抽取[9].抽取出来的上下文信息根据频率与术语的共现信息被赋予权重.
经典的NC-value算法在抽取术语的过程中仅仅利用了术语上下文.经统计,名词性术语与领域现象术语有着较高的共现频率.根据这一特性,在基于分隔符的基础上,文中利用名词性术语进行领域现象术语的抽取.文中在NC-value算法的基础上进行如下假设:(1)名词性术语作为上下文术语对领域现象术语的决策能力要高于普通的分隔符;(2)名词性术语和分隔符与待抽取术语的距离越近,其对术语的决策能力越强.
通过对与领域现象术语共现的词分配权重来实现上述假设.候选领域现象术语的抽取算法如式(1)所示:
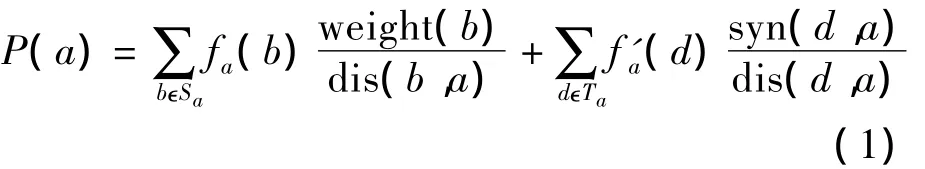
式中,a为候选术语,P(a)为a成为候选术语的概率,Sa为a的分隔符集合,b为Sa中的一个分隔符,fa(b)为在训练语料中b作为a的分隔符出现的频率,weight(b)为分隔符b的权重,dis(b,a)为b与a的句法距离,Ta为a的上下文术语集合,d为Ta集合中的一个词为在训练语料中d作为a的上下文术语出现的频率,syn(d,a)为d与a的句法权重,dis(d,a)为d与a的句法距离.式(1)中等号右边第一项表示分隔符在抽取中所起的作用,第二项表示上下文术语在抽取中所起的作用.
1.3.1分隔符的作用
不同的分隔符对确定术语所起的作用不同.文中通过分隔符在训练语料中与术语共现的频率占其所有出现频率的比值来确定分隔符的权重,即

式中:t(b)为训练语料中与b一起出现的术语数目;n为训练语料中b出现的频率总和;Nb,a为b和a之间的词语数目(根据分词的结果),相邻关系词的Nb,a定义为1.可以看出:训练语料中与一个词共现的术语频率越高,这个词作为术语分隔符的权重就越大;一个词与权重大的分隔符共现的频率越高,它就越可能是一个术语,成为术语的概率与分隔符的距离成反比,即一个词与分隔符的距离越小,其成为术语的可能性越大.
1.3.2 上下文术语的作用
文中通过与上下文术语在同一个句子中的句法关系和距离来确定领域现象术语的概率.领域现象术语的出现常有以下几种情况:(1)与“对象”类术语(常常是名词性术语)以主谓句法模式出现,但主谓关系有可能存在于其它类型的句法成分中,如台式机的显示器(对象)突然间蓝屏(现象)了;(2)与其它领域现象术语并列存在,但并列关系也可能存在于其它类型的句法成分中,如台式机的显示器(对象)不停地抖动(并列现象),接着就蓝屏(并列现象)了;(3)与“对象”类术语组合,作为状语存在,如台式机的显示器蓝屏时(状语),CPU风扇运转正常.
文中利用依存句法分析器[10]来识别句子成分.句法模式得分由句法模式(与上下文之间属于主谓、并列关系等)和距离(与作用元素相隔的词语数目)来决定.文中通过实验得到句法模式得分的经验值:主谓模式时取值为1.0,并列模式时取值为0.8,状语模式时取值为0.6.距离得分为

式(4)表明,在同一个句子中,作用因素与候选领域现象术语的距离越近,在句法上的关系越密切,其对术语的决定作用就越高.
1.3.3 非领域现象术语的过滤
采用式(1)得到的只是候选领域现象术语,其中包含着大量非领域现象术语.利用领域词表过滤掉其它类型的术语,得到的结果才是领域现象术语.
2 实验与结果分析
为了和其它抽取算法进行比较,文中采用了传统的评测标准:准确率与召回率,

实验在抽取的“百度知道”语料库上进行,范围是计算机故障诊断领域.语料库采用问答的形式,包含用户在“百度知道”上完整的问题与答案.选择这个语料库有以下几个原因:(1)计算机故障诊断领域包含的领域术语数量不多,比较容易保证人工标注的工作量和准确性;(2)一问一答的模式集中了丰富的领域信息,领域术语的密度较高;(3)“百度知道”的格式规范,利于语料库的抽取和预处理.
文中选取700组计算机故障诊断领域的问答作为训练语料,2885组(约1.83MB)问答作为实验语料.由于领域现象术语不容易得到局部上下文信息,文中利用传统的机器学习方法进行抽取,所以只将文中方法的抽取结果与传统的基于词频的方法[11]及基于分隔符的方法[7]做比较.
(1)利用文中方法进行抽取按照1.2节方法对训练语料进行分隔符抽取,在基于词频的方法中设置频率阈值为3(如果一个词与术语共现的频率超过3次,就将其选为分隔符).利用训练语料,抽取到有效前驱分隔符251个,有效后驱分隔符297个.停用词库采用Stopword List,包含了507条停用词.将两者进行结合,最终得到有效前驱分隔符337个,有效后驱分隔符385个.
对“搜狗”计算机词库进行过滤,得到“搜狗”计算机名词性词库.利用训练语料得到分隔符,并将“搜狗”计算机名词性词库作为上下文术语对实验语料按照式(1)进行抽取,得到候选领域现象术语集.然后参照“搜狗”计算机名词性词库,在候选领域现象术语集中把名词性术语过滤掉,得到最终领域现象术语.
(2)利用基于词频的方法进行抽取首先对语料进行分词,分词结果的好坏直接关系到最后的抽取结果,文中采用中国科学院的ICTCLAS[12]系统并加入“搜狗”计算机词库进行分词;然后利用基于词频的方法对分词结果进行术语抽取,采用“搜狗”计算机名词性词库在结果中过滤掉名词性术语,得到抽取结果.
(3)利用基于分隔符的方法进行抽取基于分隔符的抽取方法可以理解为只利用式(1)中的前半部分进行抽取,即
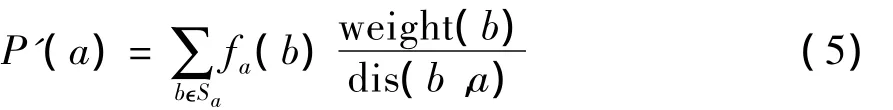
采用前面抽取到的分隔符,利用“搜狗”计算机名词性词库在候选领域现象术语集中把名词性术语过滤掉,得到最终结果.
3种方法的实验结果如表1所示.从表1可知,文中提出的领域现象术语抽取方法具有较高的召回率,但准确率相对较低.这是因为文中方法对领域现象术语的过滤主要集中在名词性术语上,还有一定数量的动词性术语没有过滤掉.如“打开机箱,开始清扫灰尘”中的“清扫”被认为是领域现象术语,实际上它只符合普通动词性术语的特征.如果文中算法能将领域现象术语中的动词性术语过滤掉,那么抽取的结果会更加准确.
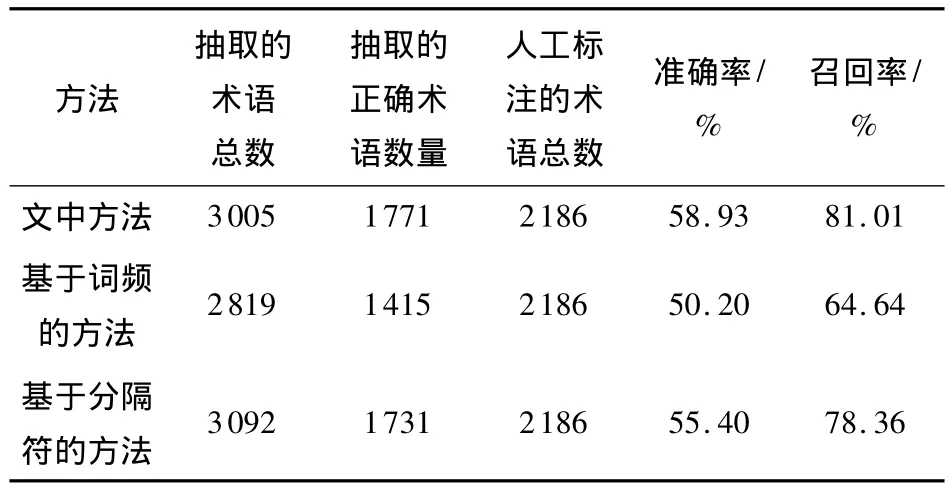
表1 3种方法的抽取结果比较Table 1 Comparison of extraction results obtained by three methods
3 结语
文中将基于局部上下文的抽取方法应用到分隔符抽取中,利用分隔符和上下文术语进行术语抽取,同时过滤掉词性不符的术语,在一定程度上解决了领域现象术语难以利用特征进行抽取的问题.这种方法在小规模语料库上取得了较为显著的效果,如果语料库选取得当,可以被应用于多种限定领域,对多种复合词进行抽取.实验结果表明,文中方法没有达到很高的准确率.这是由于利用式(1)方法抽取到了大量的非领域现象术语,而能够过滤掉的术语类型又比较有限.下一步将针对如何更加合理地过滤掉更多类型的非领域现象术语进行研究.
[1]冯志伟.现代术语学引论[M].北京:语文出版社,1997:31.
[2]傅继彬,樊孝忠,毛金涛,等.基于语言特性的中文领域术语抽取算法[J].北京理工大学学报,2010,30(3):307-310.Fu Ji-bin,Fan Xiao-zhong,Mao Jin-tao,et al.An algorithm of Chinese domain term extraction based on language feature[J].Transactions of Beijing Institute of Technology,2010,30(3):307-310.
[3]张锋,许云,侯艳,等.基于互信息的中文术语抽取系统[J].计算机应用研究,2005,22(5):72-73.Zhang Feng,Xu Yun,Hou Yan,et al.Chinese term extraction system based onmutual information[J].Application Research of Computers,2005,22(5):72-73.
[4]Argamon S,Dagan I,Krymolowski Y.A memory-based approach to learning shallow natural language patterns[C]∥Proceedings of the 17th International Conference on Computational Linguistics.Montreal:Association for Computational Linguistics,1998:67-73.
[5]Itagaki M,Aikawa T,He X.Automatic validation of terminology translation consistency with statisticalmethod[C]∥Proceedings of MT Summit XI.Copenhagen:[s.n.],2007:269-274.
[6]董秀芳.动词性并列式复合词的历时发展特点与词化程度的等级[J].河北师范大学学报:哲学社会科学版,2000,23(1):57-63.Dong Xiu-fang.The features of the diachronic development of verbal coordinate compound words in the Chinese language and their etymological changes[J].Journal of Hebei Normal University:Social Science Edition,2000,23(1):57-63.
[7]Qin L.Chinese term extraction using minimal resources[C]∥Proceedings of the 22nd International Conference on Computational Linguistics.Manchester:Association for Computational Linguistics,2008:1033-1040.
[8]化柏林.知识抽取中的停用词处理技术[J].现代图书情报技术,2007(8):48-51.Hua Bo-lin.Stop-word processing technique in knowledge extraction[J].New Technology of Library and Information Service,2007(8):48-51.
[9]Frantzi K,Ananiadou S,Mima H.Automatic recognition of multi-word terms:the C-value/NC-valuemethod[J].International Journal on Digital Libraries,2000,3(2):115-130.
[10]李彬,刘挺,秦兵,等.基于语义依存的汉语句子相似度计算[J].计算机应用研究,2002(12):15-17.Li Bin,Liu Ting,Qin Bing,et al.Chinese sentence similarity computing based on semantic dependency relationship analysis[J].Application Research of Computers,2002(12):15-17.
[11]Joachims T.A probabilistic analysis of the Rocchio algorithm with TFIDF for text categorization[C]∥Proceedings of the 14th International Conference on Machine Learning.San Francisco:Morgan Kaufmann Publishers Inc,1997:143-151.[12]Zhang H P,Yu H K,Xiong D Y,et al.HHMM-based Chinese lexical analyzer ICTCLAS[C]∥Proceedings of the 2nd SIGHAN Workshop on Chinese Language Processing.Sapporo:Association for Computational Linguistics,2003:184-187.
