使用MSS维护语义缓存一致性的方法*
2011-03-21梁茹冰刘琼
梁茹冰刘琼
(1.华南理工大学计算机科学与工程学院,广东广州510006;2.华南农业大学理学院,广东广州510642)
移动计算使计算机和其它移动信息智能终端设备可以在无线网络环境下实现数据传输及资源共享,并且这种传输与共享可以发生在任何时间、任何位置以及任何移动终端之间.移动计算是当前计算技术研究中的热点之一,对移动计算的研究是游牧计算和普适计算发展的技术支撑和重要阶段.然而,移动计算本身的特点让相关研究工作充满了挑战,如无线网络带宽和电池等资源的有限性、客户端及其设备的频繁移动性和频繁断接性等.在数据通信方面,采用“广播”和“缓存”技术是解决这些难题的有效方法.
文献[1]中提出,语义缓存的基本结构由查询语义描述和查询结果两部分组成,并研究了对单个关系表的查询处理.与传统的页缓存和元组缓存不同,语义缓存能够支持对关系型数据库的查询,而页缓存与元组缓存对此支持不够,只适用于面向对象的数据库管理系统.文献[2]中对移动计算环境中的用户位置、速度、状态,以及位置比较、位置绑定、位置相关查询、语义片段进行了形式化定义,并研究了语义查询的处理过程,提出了查询裁剪的思想.文献[3]中除了进一步利用关系代数形式化相关表达外,还提出了判断当前查询能否被语义缓存满足的3个判定定理;在语义缓存查询裁剪方面,针对5种相交情况给出了具体的实现算法.文献[4-5]中对查询如何从缓存导出、查询与缓存的匹配两方面进行了深入的研究,给出了相应的定义、判定定理及算法,并提出了一个语义缓存查询模型.文献[6]中以海量数据库应用为背景,将语义缓存技术拓展到海量数据库的聚集查询,研究了面向聚集查询的语义缓存形式模型,构造了海量数据库的语义缓存系统并研究了查询处理、缓存管理和一致性维护等关键技术.文献[7]中通过分析语义缓存段与更新语句的条件谓词及投影属性的关系,将更新粒度裁剪至被更新的属性,有效地减少了数据通信开销.
综上所述,这些研究成果为进一步研究语义缓存的一致性维护策略提供了理论基础.但它们都基于传统的服务方与客户方的两层结构,不利于缓存统一管理,一致性维护开销较大,并且没有涉及失效报告数据结构方面的研究.为此,文中提出了一种利用移动支持站点(MSS)进行缓存一致性维护的方法,并给出了中间层的失效报告结构形式.
1 语义缓存一致性维护方法
1.1 相关定义
定义2客户方缓存由多个两两互不相交的语义缓存项及其对应的缓存块数据构成.
定义3对于任意Select-From-Where查询语句,如果是单表查询,Where子句是逻辑And连接的属性与常量组成的比较表达式,且无嵌套查询,则称这样的查询为可缓存查询,表示为QC〉.其中:为查询的投影属性集为查询条件谓词,表示成合取式;QC为关系代数表示形式的查询结果
定义4 MSS中语义缓存项为〈SCID,SR,SA,SP,SVS〉.其中:SCID为缓存项索引号;SR为关系表;SA为投影属性集;SP为查询条件合取式;SVS为缓存项是否发生更新标志位,SVS=0表示无更新,SVS=1表示有更新.
定义5 MSS中索引表项为〈HID,State,SC〉.其中:HID为移动客户方索引号;State为该移动终端的当前状态,State=0表示在线,State=1表示离线(即设备关机或已经移动到另一分区);SC为指向MSS中保存该客户方缓存项的指针.
例1“UpdateR1Set AT1=20 Where AT2>30”表示成Update更新元组形式为U=〈R1,{AT1},AT1=20,{AT2},AT2>30,UC〉.
定义7服务方数据的Delete更新可表示为D=〈DR,DP,DC〉.其中:DR∈D;DP为删除更新条件谓词,表示成合取式;DC为删除元组集合.
定义8服务方数据的Insert更新可表示为I=〈IR,IC〉,其中IR∈D,IC为插入元组集合.
1.2 结构
典型的移动计算系统结构如图1所示,从服务器到移动支持站点段是有线网络连接,从MSS到移动终端(MH)是无线网络连接.传统的两层缓存结构将缓存数据存放在客户方,MSS只是广播失效数据,由于无线网络固有的局限性,各移动客户方的缓存信息只能保证弱一致性,且维护开销大.显然,数据验证、查询请求等操作都要通过MSS来完成.因此,这里的MSS有两重角色:对于客户端来说,它是一个小服务器,其中的数据实时、准确、个性化;对于服务器来说,它是一个固定的、有一定处理能力的客户端(胖客户端),稳定、高效,能够减轻服务器的负担,防止瓶颈.因此,文中利用MSS来扩展传统的两层缓存结构.
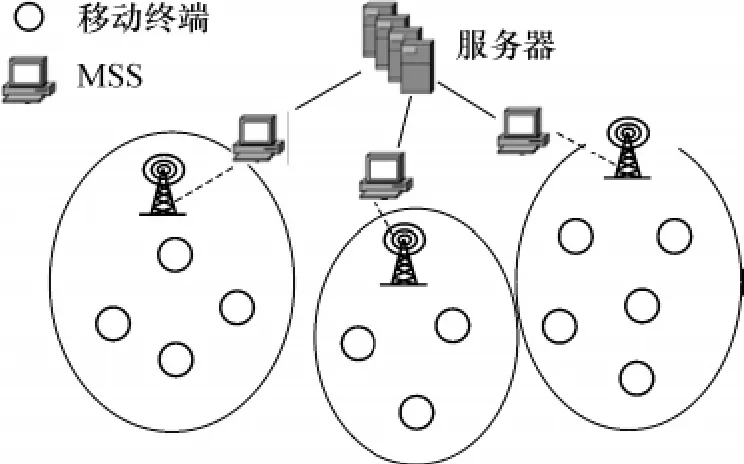
图1 典型的移动计算系统结构Fig.1 Architecture of typicalmobile computing system
客户方语义缓存存储了以往的查询描述及结果,MSS中通过存储缓存描述为客户方保存缓存备份(CB),这样MSS中就有多个移动终端的缓存内容描述,如图2所示.虽然较以前的设计而言,文中方案所需存储空间增大了,但是当前磁盘的价格不断下降,磁盘容量不断提高,多数情况下系统都有足够的空间用于热点对象的缓存.
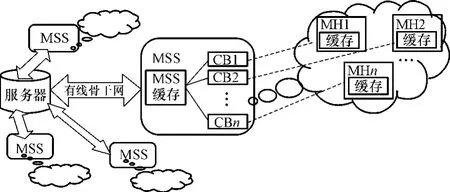
图2 扩展型语义缓存结构Fig.2 Architecture of semantic cache with extended structure
例2 MSS1所管理的分区C1中有客户方MH1和MH2,则MH1和MH2的语义缓存,以及MSS1为MH1和MH2分别保存的缓存描述如图3所示.相关数据结构说明参见定义1、4和5.通过这种数据存储方式,MSS中不仅可以保存客户方访问服务器数据的“痕迹”,以MSS中相应的语义缓存项体现,还可以进一步看出当前客户方状态是在线还是离线或者移动到另一分区.广播的失效报告中只包含当前在线的客户方缓存变化情况.
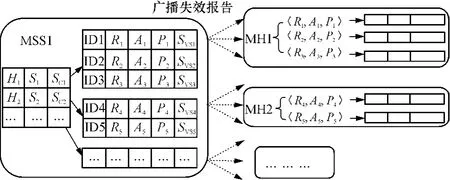
图3 MSS和客户方的缓存组织Fig.3 Cache organizations of MSS and client
1.3 MSS中的缓存一致性及失效报告格式
在一致性维护方面,由于MSS与高速骨干网络是有线连接,因此其缓存一致性维护较移动终端的缓存一致性维护容易,并且能够做到低代价、强一致性,保证数据实时、有效.另一方面,由于MSS中有多个客户方的缓存项备份,当有共同目标时,缓存还可以在一定程度上共享、合并,从而可以最大程度地满足客户方的查询请求,减少与服务器的交互次数,节省带宽资源,加快查询响应时间.
强一致性要求在任意时刻MSS中的缓存项数据与服务器上的数据保持一致.由于可用性与访问性能的问题,强一致性在移动计算环境中不能直接在移动节点上实现.然而,MSS与服务器是始终保持连接状态的,服务器的数据变更可以及时发送给MSS,通过更改相应缓存项的SVS位标记来表示有无插入、删除、更新等操作,因此,MSS中的各语义缓存项在状态上可以与服务方保持强一致性.
由于无线网络非对称性的特点,从服务方到客户方的下行通信带宽一般远大于上行通信带宽,而且从服务方接收数据的开销也远小于发送开销.数据广播技术就是利用了这一特点,将数据库中的热点数据组织起来,通过专门的广播信道,经由MSS向客户方广播.进一步地,在扩展的3层缓存结构下,MSS中存储的语义缓存项的有效状态与服务方一致.MSS可以采取同步或异步的方式向其客户方广播缓存失效报告,报告的组织可以采用位序列法,并且在报告中只包含符合State=0(见定义5)条件的客户方缓存项更新状态值,进一步缩减了失效报告长度.
例3 MSS1广播的失效报告格式“MH1:101 MH2:01……”,表示客户方MH1的第一个缓存项和第三个缓存项发生了更新操作,第二个缓存项没有更新;客户方MH2的第一个缓存项没有更新,第二个缓存项发生了更新;依此类推.MH1和MH2通过收听广播信道上的失效报告了解自己的缓存有效情况,客户方甚至可以断开网络一段时间(理论上是任意长时间),当再次连接时,只需向MSS验证自己的缓存即可,而无需像传统算法那样将自己的缓存全部设置为无效或删除.
1.4 更新粒度细化
失效报告中的0或1代表整个语义缓存项的有效状态,假设某缓存块中只有极少元组发生变化,也会将该缓存项更新状态位置为1,不能精确到元组级,从而导致用户在维护缓存时存在通信数据量大的问题.因此,文中对更新粒度如何细化进行了研究.
客户方进行一致性维护时,传统的处理方法是:如果缓存项失效,则将该缓存块数据设置为无效或直接删除,或重新提交原查询,又或采取更新事务回滚的办法,即在缓存块数据中执行引起更新的Insert、Delete和Update操作(传统方法存储的是关系表的全属性,而不是投影属性).由于这些方法都直接由客户方来完成,网络通信量大,计算开销和能量消耗也很大.文献[8]中统计数据表明,客户方维护缓存一致性所付出的代价占总能量消耗的30%左右,缓存减少了网络通信中的数据量,但如果减少的上行和下行能量消耗不足以弥补一致性维护的开销,缓存的存在就没有意义.因此,文中试图将客户方从这项艰巨的任务中解放出来,让MSS代替客户方进行缓存一致性维护,并通过广播机制发布失效报告,采用位序列方法压缩报告大小,在传统广播方法基础上进一步减少通信量.
首先,要判断Update、Insert和Delete更新操作与哪些缓存项匹配,如果某缓存项与更新匹配了,那么该缓存项就被更新,SVS=1.为了便于记录更新,文中让MSS中的各缓存项都有一个更新队列,当缓存项中数据更新时,更新操作序列就被插入到队列中;客户方通过读取更新队列中的操作序列(出队列),并按插入顺序依次在其缓存块数据中执行更新操作,就可以方便地将缓存更新至最新状态.下面详细描述如何将一个更新细化,并插入更新队列.
(1)插入更新方式Insert
如果服务器数据发生了Insert更新〈IR,IC〉,则MSS收到该更新信息后,将〈IR,IC〉与各缓存项〈SR,SA,SP,SC〉进行匹配判断:
(2)删除更新方式Delete
如果服务器数据发生了Delete更新〈DR,DP,DC〉,则MSS收到该更新信息后,将〈DR,DP,DC〉与各缓存项〈SR,SA,SP,SC〉进行匹配判断:
(3)更新方式Update(方法1)
如果服务器数据发生了Update更新〈UR,UP1A,UP1,UP2A,UP2,UC〉,则MSS收到该更新信息后,将〈UR,UP1A,UP1,UP2A,UP2,UC〉与各缓存项〈SR,SA,SP,SC〉进行匹配判断:
如果UP1A∧SPA≠∅且UP1⇒SP满足,则说明执行Update更新后,有新的数据符合条件SP待插入缓存,需要构造补充查询Q=〈SR,SA,UP1,S'C〉,查询结果S'C与原缓存合并可达到更新的目的.因此,SVS=1,补充查询操作〈SR,SA,UP1,S'C〉添加到该缓存项的更新队列中.
如果UP1A∧SPA≠∅且UP1⇒SP不满足,则说明执行Update更新后,缓存中有不符合条件SP待删除的元组,需要执行删除更新〈DR=SR,DP=UP2,DC〉来达到一致性目的.因此,SVS=1,删除操作〈SR,UP2,DC〉添加到该缓存项的更新队列中.
若UP2∧SP=∅且(UP1∧SP)⇒SP满足,说明执行Update更新后,有新的数据符合条件SP待插入缓存,需要构造补充查询Q=〈SR,SA,UP1∧SP,S'C〉,查询结果与原缓存合并可达到更新目的.因此,SVS=1,补充查询操作Q=〈SR,SA,UP1∧SP,S'C〉添加到该缓存项的更新队列中.
若UP2∧SP≠∅,则考虑下面两种情况.
若(UP1∧SP)⇒SP满足,则说明执行Update更新后,有新的数据符合条件SP待插入缓存,需要构造补充查询Q=〈SR,SA,UP1∧SP,S'C〉,查询结果与原缓存合并可达到更新的目的.因此,SVS=1,Update更新操作〈UR,UP1A∧SA,UP1∧SP,UP2A,UP2,UC〉和补充查询操作Q=〈SR,SA,UP1∧SP,S'C〉依次添加到该缓存项的更新队列中.
若UP2⇒SP满足且UP1∧SP=∅,则说明执行Update更新后,缓存中有不符合条件SP待删除的元组,需要执行删除更新〈DR=SR,DP=UP2,DC〉来达到一致性目的.因此,SVS=1,Update更新操作〈UR,UP1A∧SA,UP1,UP2A,UP2,UC〉和删除更新操作〈SR,DP=UP2,DC〉依次添加到该缓存项的更新队列中.
(4)更新方式Update(方法2)
如果Update更新所影响的元组很少(如小于3个)而不是整片更新,则可以考虑将Update更新拆分为一个Delete更新、一个补充查询和一个Insert更新.对于Update更新〈UR,UP1A,UP1,UP2A,UP2,UC〉,如果某缓存项受其影响,则先执行删除更新操作〈DR=UR,DP=UP2,DC〉,再执行补充查询〈UR,SA,UP2,QC〉,最后将查询结果插入该缓存块中.
2 仿真实验及结果分析
为了验证所提出的模型及方法的性能,文中设计了两组仿真实验.编程基于J2SE平台,运行环境是AMD 2500+1.40GHz处理器,内存为512MB,操作系统为Windows XPProfessional.仿真实验参数如表1所示.

表1 仿真实验参数Table 1 Simulation parameters
实验1服务方按UpdateInterval随机生成更新操作,更新每隔Broad Interval广播给客户方.模拟了20min内的更新及广播失效报告情况,并在不同缓存大小(2~10 kB)情况下,比较了PCID方法[9]、文中基于位序列的报告数据组织方法与传统基于数据对象和时间戳的方法的失效报告长度,运行1000次后的平均实验结果如图4所示.
在相同大小的客户端缓存(4096B)下,服务方数据以一定时间间隔被更新,更新报告以无状态同步的方式发送到客户方.随着仿真时间的延长,由MSS广播的失效报告累积字节数也在增加,如图4(a)所示.文中方法的失效报告长度比传统方法和PCID方法均短,这是因为传统方法基于数据对象和时间戳来形成失效报告,PCID方法虽然基于位序列[10],但要求包含时间戳.文中方法采用位序列方法组织失效报告,对离线或刚迁移到另一分区的客户方缓存项进行更新时不需要广播,且无需包含时间戳,因此空间复杂度更低.
在相同的传真时间(10min)下,客户方缓存从2 kB递增到10 kB,3种方法的失效报告长度如图4(b)所示.从图4(b)可知:传统方法中失效报告长度的增加与服务方数据更新频率和模拟时间成正比,而与实际缓存项数目无关;文中方法和PCID方法的报告长度随着实际缓存项数目增加而稍有增加,但仍远远小于传统方法中的报告长度;由于传统方法存储全属性,对于相同的缓存空间,文中方法可以存储更多的语义缓存项,从而提高了缓存命中率.也就是说,在缓存空间明显增加,缓存项数目也相应增加的情况下,文中方法的失效报告长度仍然远远小于传统方法,有利于节省无线部分的带宽资源.
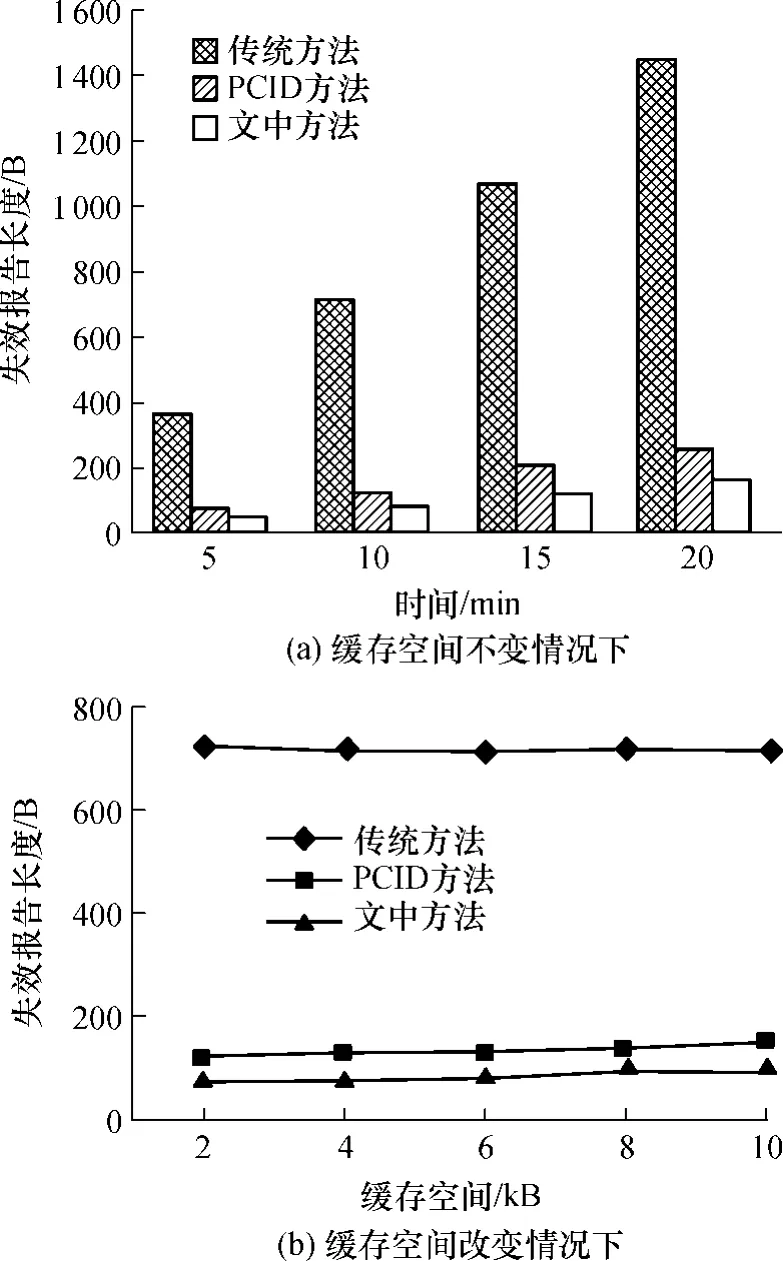
图4 在不同缓存空间情况下3种方法的失效报告长度比较Fig.4 Comparison of invalidation report size among three algorithms with different cache spaces
实验2仿真了缓存一致性维护过程,比较了文中提出的基于更新队列与粒度细化一致性维护方法、传统方法和两层结构粒度细化方法(简称两层方法)[7]在网络通信量方面的性能,运行1000次后的平均实验结果如图5、6所示.
实验数据表明,与传统方法和两层方法相比,文中方法可以存储更多的缓存项,因为传统方法需存储全属性,两层方法要预留空间存储更新语句,因此,文中方法的缓存命中率更高.也就是说,由于命中率较高,在相同的仿真时间内,文中方法较其它两种方法要做更多的缓存一致性维护工作,有更多待更新的元组数,如图5所示.
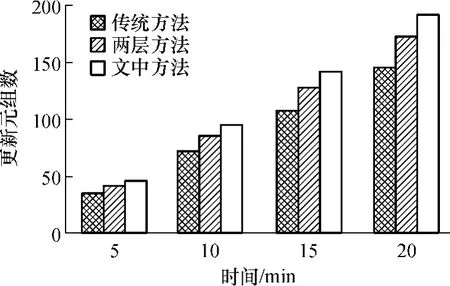
图5 3种方法的更新元组数比较Fig.5 Comparison of numbers of updated tuples among three algorithms
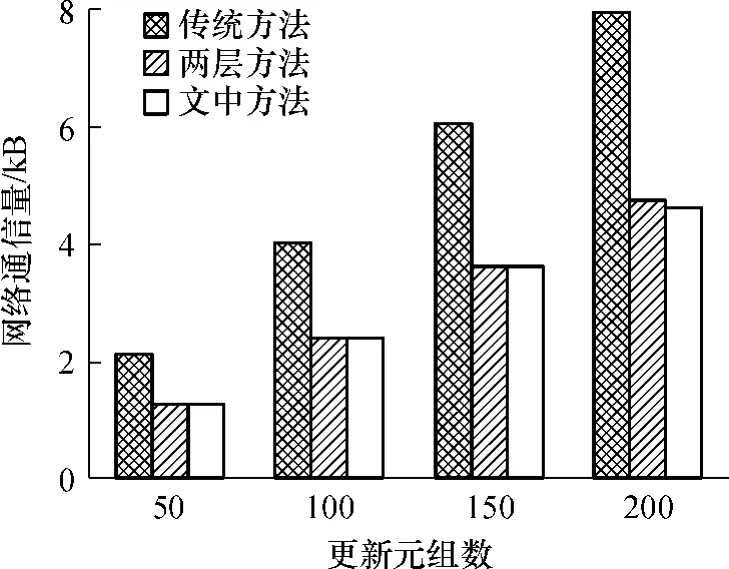
图6 3种方法的网络通信量比较Fig.6 Comparison of data communication traffic among three methods
最后,依次对缓存中50、100、150和200个待更新元组进行一致性维护,分别比较3种方法所产生的网络通信量,结果如图6所示.由图6中可知,文中方法和两层方法较传统方法有更低的网络通信量,且增长幅度也较小.这是因为传统方法执行Update更新操作时,先在缓存中执行Delete操作,再执行Select操作以获取更新后的元组,然后将它们插入到缓存中.因此在更新过程中,有时只需要修改个别属性值,却变成了对整个元组的操作,从而增加了通信量.应用文中方法时,网络通信量随着更新元组数的增加而增加,但由于采取了粒度细化策略和更新队列机制,只有当产生补充查询时才会明显增加网络通信量(实验中补充查询值设为0.2).如果无补充查询或者补充查询几率很小,则更新元组数的增加不会带来通信量的明显增加.
当客户方始终与网络保持连接时,可以持续接收失效报告进行缓存一致性维护.此时,文中方法与两层方法在网络通信量开销上很接近,如图6所示.但是,当发生断接操作时,传统方法与两层方法在断接时间小于广播时间间隔情况下,缓存恢复较易;一旦断接时间大于广播时间间隔,再次连接就无法根据当前失效报告来判断缓存的有效性,文献[7]中的两层方法没有对此进行研究.由于文中方法在MSS中设置更新队列,因此即使客户方离线(理论上可以断开任意长时间),其缓存更新序列始终有相应的MSS为其保存在更新队列中,当客户方再次连接时,只需执行出队列操作,并依次执行队列中的更新操作即可将其缓存恢复有效.
3 结语
缓存和数据广播技术是移动计算中有效利用带宽资源和节省能量的重要方法.针对传统语义缓存方法没有有效利用移动支持站点以及一致性维护通信开销大的问题,文中提出利用移动支持站点进行数据广播的方法,基于客户方访问服务器的数据“痕迹”和当前活动状态信息,采用位序列法组织失效报告,从而有效地减少了广播失效报告长度.在一致性维护方面,归纳整理了粒度细化和属性裁剪的逻辑方法,提出将原更新操作转化为等价更新序列并插入更新队列中的思想,从而简化了客户方的缓存维护过程,减少了网络通信量,并能够适应客户方频繁断接情况下的一致性维护.仿真实验结果表明,文中方法是有效的,在缩减失效报告长度和网络通信量方面都较传统方法等有明显的改善.
[1]Dar S,Franklin M,Jonsson B,etal.Semantic data caching and replacement[C]∥Proceedings of the 22nd VLDB Conference.Mumbai:Morgan Kaufmann Pub Inc,1996:330-341.
[2]Ren Qun,Dunham M H.Using semantic caching to manage location dependent data inmobile computing[C]∥Proceedings of the 6th Annual International Conference on Mobile Computing and Networking.New York:ACM,2000:210-221.
[3]Ren Qun,Dunham M H,Kumar V.Semantic caching and query processing[J].IEEE Transactions on Knowledge and Data Engineering,2003,15(1):192-210.
[4]吴婷婷,周兴铭.基于语义缓存的移动查询导出[J].计算机学报,2002,25(10):1104-1110.Wu Ting-ting,Zhou Xing-ming.Extracting query results from semantic cache[J].Chinese Journal of Computers,2002,25(10):1104-1110.
[5]吴婷婷,苏武运,周兴铭,等.移动查询缓存处理的研究[J].计算机研究与发展,2004,41(1):187-193.Wu Ting-ting,Su Wu-yun,Zhou Xing-ming,et al.Mobile query through semantic cache[J].Journal of Computer Research and Development,2004,41(1):187-193.
[6]蔡建宇,吴泉源,贾焰,等.面向聚集查询的语义缓存技术[J].软件学报,2007,18(2):361-371.Cai Jian-yu,Wu Quan-yuan,Jia Yan,et al.Semantic cache technology for aggregate queries[J].Journal of Software,2007,18(2):361-371.
[7]李东,袁应化,叶友,等.基于属性更新的语义缓存一致性维护自算法[J].华南理工大学学报:自然科学版,2009,37(5):139-144.Li Dong,Yuan Ying-hua,Ye You,et al.Algorithm of semantic caching coherency maintenance based on attribute update[J].Journal of South China University of Technology:Natural Science Edition,2009,37(5):139-144.
[8]Yeung M K H,Kwok Y-K.On energy efficient wireless data access:caching or not?[C]∥Proceedings of International Conference on Mobile Ad-hoc and Sensor Networks.Berlin/Heidelberg:Springer-Verlag,2005:528-537.
[9]Chung Y D.A cache invalidation scheme for continuous partialmatch queries in mobile computing environments[J].Distributed and Parallel Databases,2008,23(3):207-234.
[10]Jing J,Elmagarmid A,Helal A,et al.Bit-sequences:an adaptive cache invalidation method in mobile client/server environments[J].Mobile Networks and Applications,1997,2(2):115-127.
