基于唇部灰度能量图的唇读方法*
2011-03-21梁亚玲杜明辉
梁亚玲 杜明辉
(华南理工大学电子与信息学院,广东广州510640)
唇读是指通过观察说话者的口型变化,读出全部或者部分所说的内容[1],它是人工智能研究的一个新方向,被广泛应用于噪声环境下以提高语音识别率.基于单视觉通道的语义识别系统在近几年迅速发展起来[2-5],文中基于单视觉通道小样本大词汇唇读系统进行研究.唇读系统中待处理的数据是表示唇部变化的图像序列.由于语速的不同或者采集系统的帧率不同,对于同一个字或词在不同时间或用不同器材采集到的样本长度(帧数)是不同的,即每个样本的数据维数是不同的.目前解决此类时变信号样本数据维数不同的方法主要有两类:
(1)对每帧图像分别提取特征,利用隐马尔科夫(HMM)进行模型的训练或用动态时间规整(DTW)方法进行动态匹配识别.HMM是一种基于统计的方法,它通过对大量的样本进行模型参数的训练来获取每类的模型参数.当训练样本数较大时,模型的识别率较好;当训练样本数较小时,模型的识别率较低.DTW是一种把时间规整与距离测度计算结合起来的非线性规整技术.该方法通过计算给定的模板序列和测试序列在时间轴上的距离,将与测试序列在时间约束条件下距离最短的模板所对应的类判定为该测试样本的识别结果.DTW是一种简单易行的方法,对于训练样本的个数要求最低,每类有一个样本作为模板即可,它实质上是一种模板匹配方法,其识别率与原始模板关系较大,且总体识别率相对大训练样本的HMM来说不高.这两种方法是目前进行唇读的典型方法.
(2)在提取特征时或提取特征前对输入数据进行规整.如文献[6]中采用动态时间规整核(DTAK)方法获取等长特征,再利用支持向量机(SVM)进行分类.SVM是一种能有效解决小样本识别问题的方法,一般用于较少类别的分类问题,因为其分类器的个数与类别数n的关系为n(n-1)/2.若类别数较多,则识别时间较长.在提取特征前对非等长数据进行规整的另外一种方法是目前广泛应用于步态序列图像识别的能量图法,该方法通过将二值序列图像投影到步态能量图(GEI)[7]或将步态序列的轮廓线投影到时空能量图[8]上完成数据维数的统一,间接完成数据降维.能量图法具有思路简单、特征维数小、识别速度快、识别率高等特点,受此启发,文中提出了基于唇部灰度能量图(LGEI)的唇读方法.
1 唇部灰度能量图
1.1 唇部灰度能量图的定义
步态能量图像G(x,y)定义为[7]
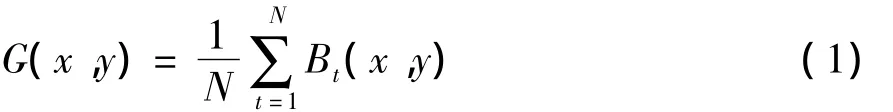
式中,Bt(x,y)为步态侧面二值图像在像素点(x,y)处的值,N为一个完整的步态周期的总帧数.与步态能量图类似的还有用来判别动作类型的运动能量图(MEI)、运动历史图像(MHI)等,它们都是将二值化的序列图像投影到二维的能量图上,完成数据维数的统一,然后对能量图进行特征提取,最后将测试样本的特征与模板的特征进行匹配,从而得到识别结果.能量图法已广泛应用于步态识别和动作识别中.
步态能量图处理的是二值化的步态序列图像.唇部图像的二值化受人种、光照、个体等的影响较大,一般来说很难提取到较为理想的轮廓图像,且早期关于唇读的研究结果表明,基于轮廓的唇部特征提取方法的识别率低于基于像素的唇部特征提取方法[9].基于像素的唇部特征提取方法就是对唇部灰度图像直接提取特征,而不是对分割后的二值图像提取特征.该方法的识别率高于基于轮廓的唇部特征提取方法,主要有两方面的原因:(1)基于轮廓的方法很难提取到精确的唇部轮廓信息;(2)唇部图像中牙齿、舌头等包含了一定的信息量,二值化后的唇部轮廓图像会丢失该部分相关信息.基于以上原因,文中提出了唇部灰度能量图的定义.(x,y)处的唇部灰度能量图定义为
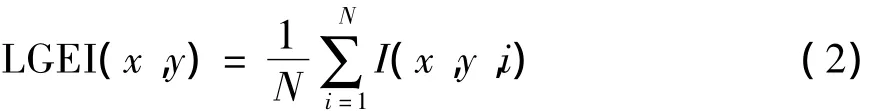
式中,I(x,y,i)为第i帧图像中像素点(x,y)的灰度值,N为一个完整的样本中图像的帧数.图1给出了唇部序列图像及其灰度能量图的示意图.唇部能量图将非等长的唇部序列图像投影到相同大小的唇部灰度能量图上,同时间接地完成了数据的降维.
1.2 多训练样本唇部灰度能量图
基于唇部灰度能量图法实质上仍然是模板匹配法,模板匹配方法的识别率受模板的影响具有一定的随机性且识别率一般不高.当有多个训练样本时,单样本模板匹配的方法不能充分利用其它训练样本的优点.基于此,文中将单训练样本推广到多训练样本.定义多训练样本唇部灰度能量图为

图1 唇部序列图像及其灰度能量图Fig.1 Lip image sequence and its LGEI
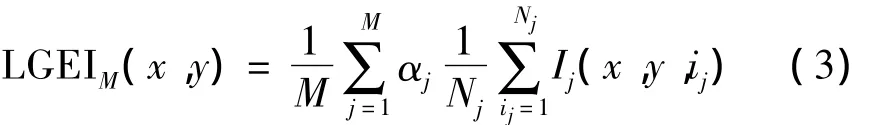
式中:M为训练样本数;Nj为第j个训练样本序列中的帧数;Ij(x,y,ij)表示第j个样本中第ij帧唇部图像中像素点(x,y)的灰度值;αj为第j个训练样本的系数,满足α1+α2+…+αM=1且0≤αj≤1,αj用来反映各训练样本对模板的贡献值,与训练样本的质量有关.对于图像清晰、帧率较高的样本,可给予较大的系数;对于质量较差的样本则可给予较小的系数.唇部灰度能量图实质上是唇部序列图像的平均,由于视频序列的采样频率一般较低,采用多训练样本生成模板图就相当于提高了视频序列的采样频率,这样生成的模板更接近其真实值,从而能提高系统的识别率.
唇部灰度能量图扩展到多训练样本,实际上是指在生成唇部灰度能量图时用多个样本的能量图进行加权平均得到唇部灰度能量图模板.
1.3 LGEI的抗噪性
假设原样本第i帧图像中像素点(x,y)的噪声为n(x,y,i),噪声与信号间相互独立且分别独立同分布,则受噪声影响的图像信号为
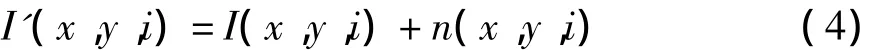
LGEI的均值和方差分别为
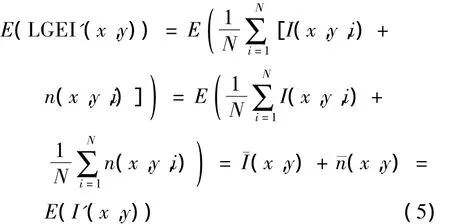
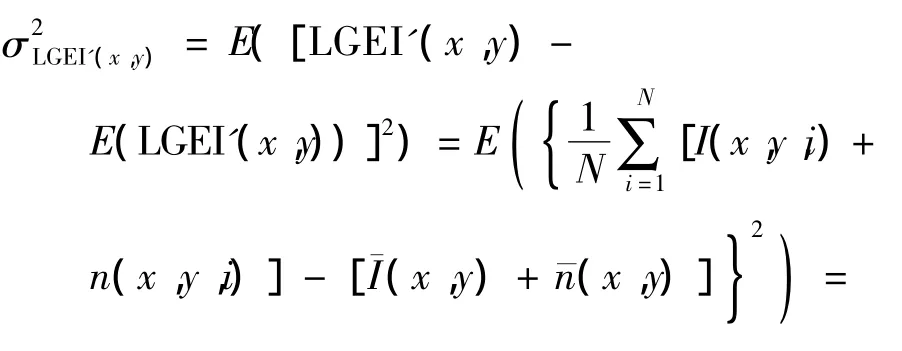
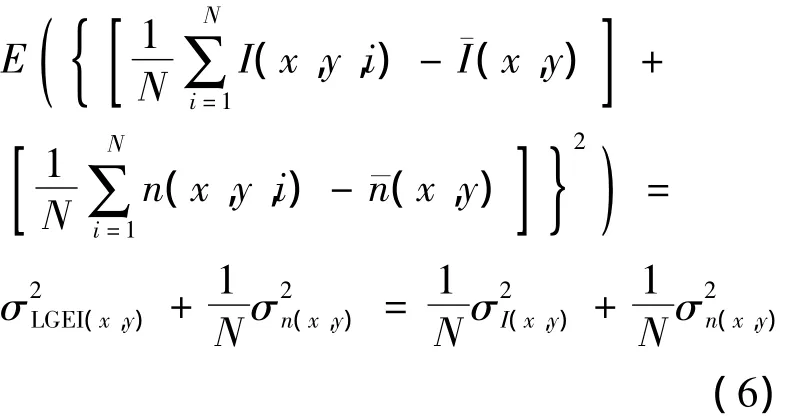
式中,I(x,y)和n(x,y)分别为像素点(x,y)的灰度值和噪声,¯I(x,y)和¯n(x,y)分别为点(x,y)的平均灰度值和平均噪声.
从式(5)、(6)可以看出,受噪声影响后唇部灰度能量图的均值与单幅图像相同,方差为单幅图像的1/N.与传统的对单帧图像分别提取特征的方法相比,采用DTW进行识别或采用HMM进行训练时,在识别过程中会造成噪声的叠加,导致噪声的干扰远大于单幅图像噪声的影响.可见,采用唇部灰度能量图的方法能够平滑噪声,避免了对单帧图像分别提取特征导致的噪声叠加效应,提高了系统的抗噪性.
2 基于LGEI的唇读方法的步骤
用唇部灰度能量图进行唇读识别的步骤如下:
1)将视频序列分割为表示具体字或词的图像序列;
2)采用文献[10]中的方法对图像序列中的每幅图像进行唇部检测和定位,得到大小为48×64的唇部感兴趣区域图像;
3)运用式(2)生成每个序列的唇部灰度能量图;
4)对唇部灰度能量图进行二维DCT变换,用zigzag方法对DCT系数进行扫描,选取前面部分重要系数用主成分分析(PCA)进行降维得到特征向量;
5)将每类中第一个样本的特征作为模板,计算测试样本与模板样本特征的欧式距离,与样本距离最短的模板所属的类即判定为样本所属的类.
3 实验及结果分析
3.1 数据库
文中实验采用HIT BiCAV数据库,数据采集速率为25 f/s,分辨率为256×256,由200个句子组成,约合1000个字,每个句子录制3遍.在汉语中,相同的音标会有不同的音调,通过唇部口形不能区分不同音调,因此文中将相同音标、不同音调的视为同一个类.从该库中选取96个具有不同音标的字共288个样本进行实验.
3.2 数据预处理
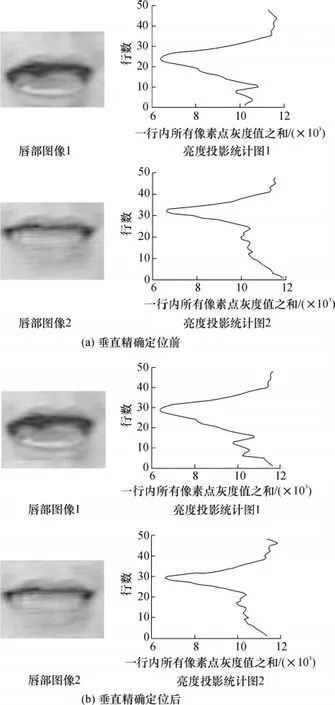
图2 唇部垂直精确定位前后的图像及其投影Fig.2 Images of lips before and after an vertical accurate location and their projections
文中采用的数据库已完成字与字的序列分割,因此可直接进行唇部的检测与定位.由于唇部灰度能量图是将唇部对应位置的灰度值进行直接相加的处理,要求唇部图像精确定位.文献[10]中通过检测双眼的位置,然后根据眼睛与嘴巴的相对位置分割出唇部图像.该方法很好地运用了基于人的不变特征来确定唇部的左右位置,且通过双眼之间连线将唇部调整至水平,但对唇部上下位置的定位效果较差.文中通过对由文献[10]中方法生成的感兴趣区域图像进行研究,发现嘴角连线处的灰度统计值最小,如图2(b)中亮度投影统计图所示.根据唇部的这个特性,文中在文献[10]的基础上,通过唇部灰度图像在水平方向的投影来确定嘴角的位置,将嘴角调整至统一高度.整个数据的预处理过程为:(1)通过OpenCV检测人脸及瞳孔位置;(2)根据瞳孔之间连线的角度将唇部调整至水平,并将瞳孔之间距离缩放至统一大小,根据瞳孔位置确定出唇部的左右边界,并根据人脸与唇部的几何关系粗步确定唇部上下边界;(3)对粗定位唇部图像进行水平方向投影确定嘴角位置,并将嘴角调整至统一高度,得到精确定位的唇部感兴趣区域图像.数据预处理的实现过程如图3所示.唇部垂直定位前后的图像及其投影如图2所示.

图3 数据预处理过程Fig.3 Data preprocessing
考虑到唇部在张开时下唇高度大于上唇高度,因此将嘴角连线的位置定位在整个唇部感兴趣区域约2/5的位置.文中提取的唇部图像大小为48×64,将唇部嘴角的连线位置定在20,可保证唇部张开时,下唇不会被分割在唇部区域之外.
3.3 实验结果与分析
实验1-5选取前100个DCT系数进行实验,实验6对DCT系数的个数选取进行讨论.
实验1采用文中提出的唇读识别方法进行实验.对比方法是传统的对单帧图像分别提取特征的方法(对样本序列中单幅图像采用DCT和PCA提取特征,然后用DTW进行识别).文中没有采用HMM作为识别方法是因为HMM是一种基于统计的建模方法,当每类训练样本数量足够大时能得到较好的模型,否则会影响识别率.实验结果如图4所示.
图4(a)中特征维数表示单帧图像提取的特征维数.文中方法先将序列图像投影,然后对唇部灰度能量图进行特征提取,因此能量图的特征维数是单帧图像时的1/7.8(文中采用的数据库中每个样本的平均长度为7.8帧).从图4(a)中可以看出,若对单帧图像提取相同维数的特征,文中方法的识别率远高于传统方法.如对单帧图像提取特征维数为1时,传统方法的识别率为35.42%,而文中方法的识别率为63.54%.在单帧图像提取特征维数大于10的情况下,文中方法的识别率比传统方法提高了4%.这是因为文中方法最大限度地保留了图像序列的特征,且反应了其动态特征.而传统方法对单帧图像分别提取特征,不同帧特征之间的相似性很大,存在较大冗余.因此在特征维数相同情况下,文中方法的识别率更高.
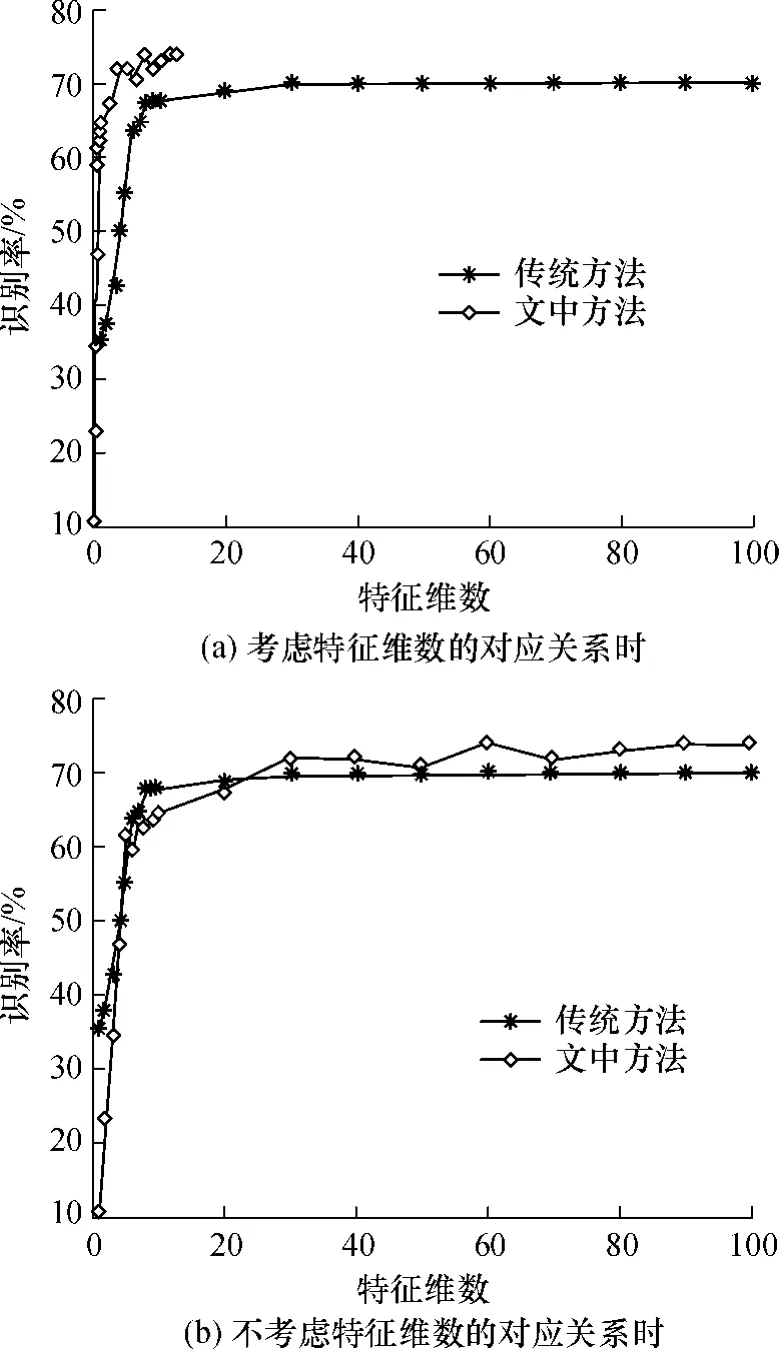
图4 文中方法和传统方法的识别率对比Fig.4 Comparison of recognition rates between proposed and traditionalmethods
如果不考虑特征维数的对应关系,即对传统的单帧图像提取的特征维数与对唇部灰度能量图提取的特征维数相同,则两种方法的实验结果如图4(b)所示.从图4(b)中可以看出,当特征维数大于30时,文中方法的识别率高于传统方法.这说明在总特征维数为传统方法的1/7.8的情况下,整个序列总特征维数大于30后,文中方法能够获得优于传统方法的识别率.这是因为对单帧图像分别提取特征,然后用DTW进行匹配的方法会造成序列图像总误差的叠加效应,因此传统方法的识别率低于文中方法.
实验2采用单训练样本法与双训练样本法进行实验.双训练样本法指用每类的前两个样本作为训练样本生成唇部灰度能量图,采用DCT和PCA对唇部灰度能量图提取特征,并将该特征作为模板,用第3个样本唇部灰度能量图的特征做测试.单训练样本法指用第1个样本唇部灰度能量图的特征作为模板,另外两个样本唇部灰度能量图的特征作为测试,单训练样本法的识别率是指两次测试识别率的平均值.由于文中采用的实验样本是在相同的环境下采集得到的,因此样本的质量大致相同,双训练样本的权重系数可均匀分配,每个训练样本的αj设为0.5.两种方法的实验结果如图5所示,图中的特征维数是对能量图提取的特征维数.
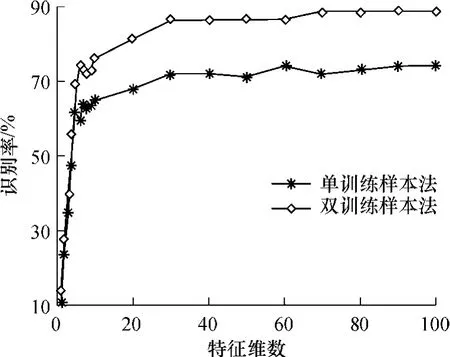
图5 单训练样本法和双训练样本法的识别率对比Fig.5 Comparison of recognition rates between single-training sample and double-training samplemethods
从图5中可以看出,双训练样本法的识别率远远高于单训练样本法,平均识别率提高了11.29%.这是因为采用双训练样本生成模板能量图时,可弥补视频序列数据采样率低的问题.如采用双训练样本进行训练获取模板特征相当于将模板的采样率提高了2倍,这样生成的能量模板就更能体现信号本身的特性.因此随着训练样本的增加,识别率会有所增加.
实验3采用双训练样本生成唇部灰度能量图模板的方法,在唇部进行精确定位前后的数据库上进行实验,考察唇部精确定位前后的识别率,结果如图6所示.
从图6中可以看出,唇部精确定位后,识别率相比定位前有了很大的提高.尤其是当特征维数较小时,其识别率提高幅度较大,达10%以上.当特征维数较大时识别率仍然有比较明显的提高,达2%以上,系统的最高识别率达90.63%.
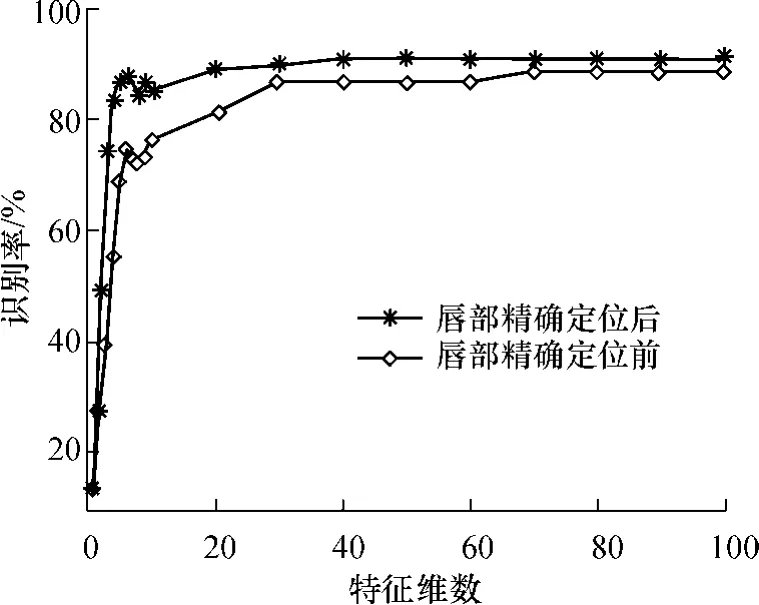
图6 唇部精确定位前后识别率对比Fig.6 Comparison of recognition rates before and after an accurate lip location
实验4由于不同文献采用的特征提取方法及识别方法不同,对数据库的要求也不同,因此无法得到直接的仿真结果来进行对比.故直接将文中方法的实验结果与文献[6,11]中的实验结果进行对比,如表1所示.
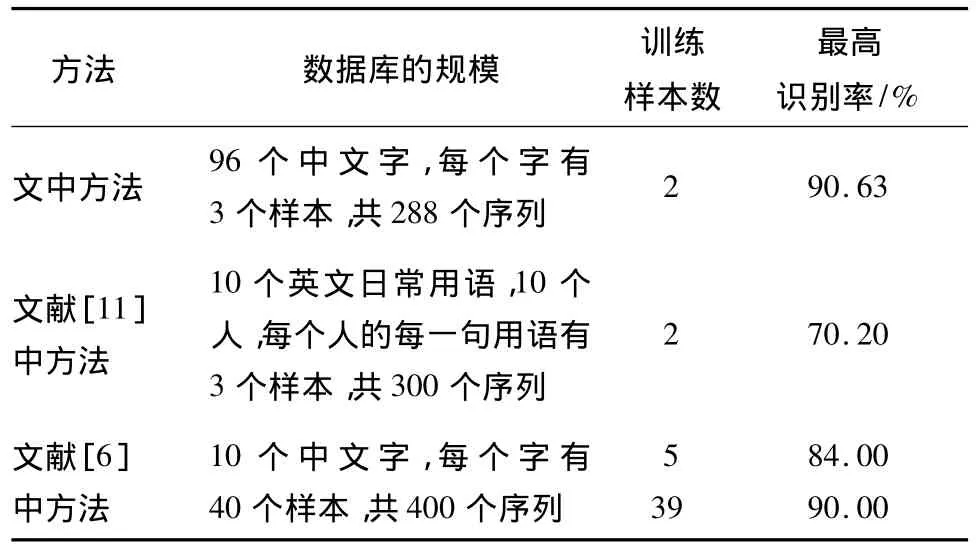
表1 不同方法的识别率对比Table 1 Comparison of recognition rates obtained by different methods
从表1中可以看出:相比文献[11]中方法对英文句子的识别率,文中方法的识别率有明显优势;相比文献[6]中方法对10个中文字的识别,虽然文中方法的识别率与该方法的最高识别率相差不多,但文中方法的类别数大很多,且训练样本数远远小于文献[6]中方法.因此,对于特定人、大词汇、小样本的单视觉唇读系统来说,文中方法是一种简单实用且识别率高的方法.
实验5文中唇部识别方法将序列图像转化为能量图,相对于DTW方法来说,在识别阶段不需要进行相应的最佳匹配路径的搜索,直接对其能量图提取的特征进行距离的求取即可,因此在识别时间上有了较大的缩减.在不同特征维数下文中唇部识别方法与DTW方法在识别96个字所需的时间对比如图7所示.
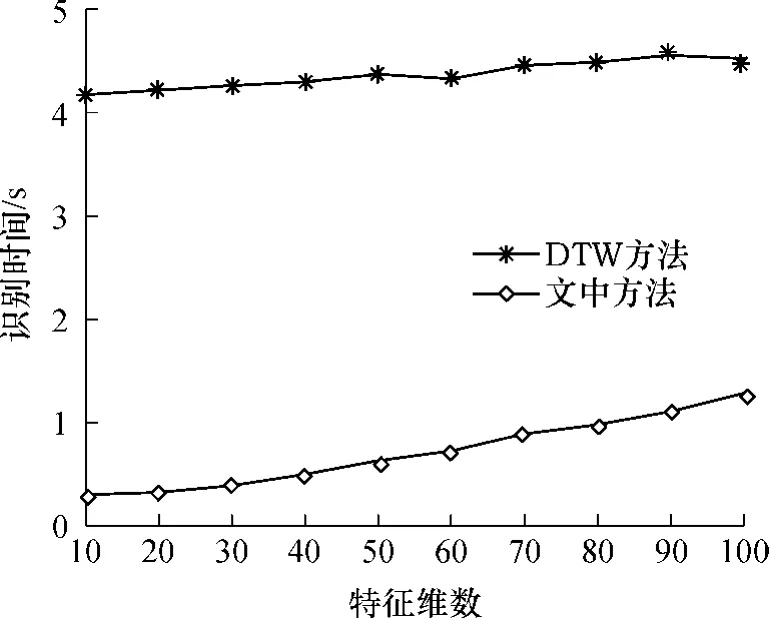
图7 文中方法与DTW方法的识别时间对比Fig.7 Comparison of recognition time used in proposed method and DTW method
从图7中可以看出,文中方法的识别时间比DTW方法短得多.这是因为识别时间主要包括计算距离测度所需时间及统计识别率所需时间,而计算距离测度所需时间占主要部分.文中方法求取样本间距离时只需要进行一次向量间距离的运算,而DTW方法需要对样本中的每幅图像进行距离测度才能得到两个样本累计距离的最小值,该过程需要多个距离的计算和比较才能完成.若单独考虑求取距离的时间,则文中方法计算距离测度部分所需时间将小于DTW方法所需时间的1/7.8.由于识别时间不只是计算距离测度所需时间,因此实验统计出的实际识别时间之比与该比例有一定偏差.从图7中可以看出:文中方法所需识别时间大约为DTW方法的1/4;随着特征维数的增加,识别时间有所增加,但增幅并不明显.
实验6文献[2-3]中采用了DCT和PCA的特征提取方法,降维后在特征维数为60~80时取得了较好的识别率,因此选取的DCT系数个数应该大于80.据此,文中采用精确定位后的数据和DCT系数个数分别为100、200时进行实验,考察DCT系数个数对识别率的影响.实验结果如表2所示.
从表2中可以看出,DCT系数个数为200时的识别率较DCT系数个数为100时无明显提高,而且在单训练样本下还有所降低.这主要是因为识别率与特征维数不是呈线性的关系,在一定范围内识别率随特征维数的增加而增加,当特征维数增加到一定程度后,识别率会有所下降.若选取的DCT系数越多,则PCA降维时将需要更多的运算时间,同时也增加了选取主成分的干扰.基于以上考虑,文中选取DCT系数个数为100.
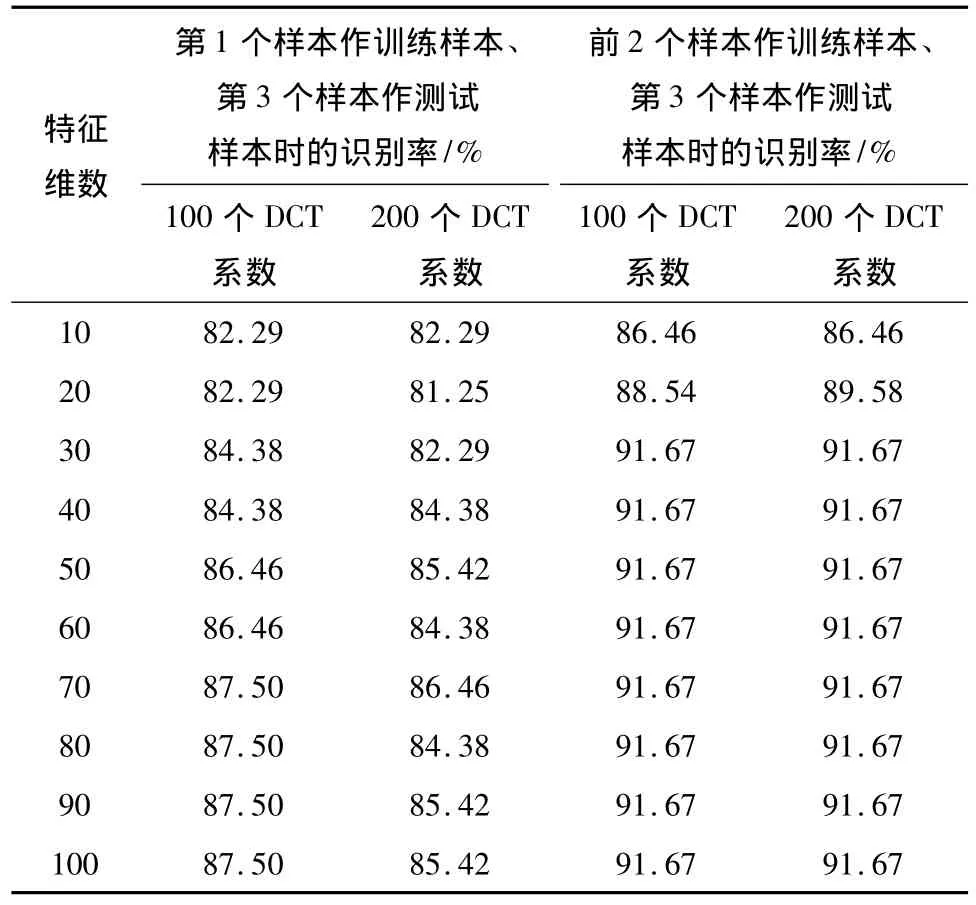
表2 DCT系数个数对识别率的影响Table 2 Effects of number of DCT coefficients on recognition rate
4 结语
文中提出了唇部灰度能量图以及多训练样本唇部灰度能量图的概念,并将其用于唇读中,然后根据数据预处理的需要提出唇部中心点精确定位方法.实验结果表明:与传统的对单帧图像提取特征的方法相比,文中基于唇部灰度能量图的方法大大地减少了特征维数,提高了识别速度和识别率;相比DTW方法,基于唇部灰度能量图的方法可方便地扩展到多训练样本,能够充分利用多训练样本的信息,进一步提高识别率.唇部灰度能量图的提出,使得人脸识别的方法可直接用于唇读识别,但该方法要求唇部精确定位,且文中只对基于人的系统进行了研究,因此后续的研究可着力于提高唇部定位的准确性,以及将唇部灰度能量图的思想与其它分类器结合起来以实现不基于人的唇读识别系统.
[1]姚鸿勋,高文,王瑞,等.视觉语言——唇读综述[J].电子学报,2001,29(2):239-246.Yao Hong-xun,Gao Wen,Wang Rui,et al.A survey of lipreading:one of visual languages[J].Acta Electronic Sinica,2001,29(2):239-246.
[2]Hong Xiaopeng,Yao Hongxun,Wan Yuqi,et al.A PCA based visual DCT feature extractionmethod for lip-reading[C]∥Proceedings of International Conference on Intelligent Information Hiding and Multimedia Signal Processing.Pasadena:IEEE,2006:321-326.
[3]万玉奇,姚鸿勋,洪晓鹏.唇读中基于像素的特征提取方法的研究[J].计算机工程与应用,2007,43(20):197-199.Wan Yu-qi,Yao Hong-xun,Hong Xiao-peng.Research of pixel based feature extraction in lip-reading[J].Computer Engineering and Applications,2007,43(20):197-199.
[4]何俊,张华,刘继忠.在DCT域进行LDA的唇读特征提取方法[J].计算机工程与应用,2009,45(32):150-152.He Jun,Zhang Hua,Liu Ji-zhong.LDA based feature extraction method in DCT domain in lipreading[J].Computer Engineering and Applications,2009,45(32):150-152.
[5]He Jun,Zhang Hua.Research on visual speech feature extraction[C]∥Proceedings of International Conference on Computer Engineering and Technology.Singapore:IEEE,2009:499-502.
[6]He Jun,Zhang Hua.Lipreading recognition based on SVM and DTAK[C]∥Proceedings of the 4th International Conference on Bioinformatics and Biomedical Engineering.Chengdu:IEEE,2010:1-4.
[7]Han Ju,Bhanu Bir.Individual recognition using gaitenergy image[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(2):316-322.
[8]韦素媛,马天骏,宁超,等.用时空能量图和小波变换方法表征和识别步态[J].电子科技大学学报,2009,38(3):431-434.Wei Su-yuan,Ma Tian-jun,Ning Chao,etal.Gait representation and recognition using spatio-temporal energy image and wavelet transformation[J].Journal of University of Electronic Science and Technology of China,2009,38(3):431-434.
[9]Potamianos Gerasimos,Neti Chalapathy,Gravier Guillaume,et al.Recent advances in the automatic recognition of audiovisual speech[J].Proceeding of the IEEE,2003,91(9):1306-1326.
[10]YaoWenjuan,Liang Yaling,Du Minghui.A real-time lip localization and tacking for lip reading[C]∥Proceedings of the 3rd International Conference on Advanced Computer Theory and Engineering.Chengdu:IEEE,2010:363-366.
[11]Zhao Guoying,Barnard Mark,Pietikäinen Matti.Lipreading with local spatiotemporal descriptors[J].IEEE Transactions on Multimedia,2009,11(7):1254-1265.
