结合重写与数据并行的XQuery查询优化
2011-02-20陈荣鑫
陈荣鑫
(1.北京工业大学计算机学院, 北京 100124;2.集美大学计算机工程学院, 福建 厦门 361021)
0 引 言
XQuery作为W3C推荐的XML数据查询语言[1],在桌面系统、企业级Web服务和云计算平台等各种开发和应用场景中得到逐步推广.大量XML数据的操作要求高效的XQuery查询支持.由于XQuery语言的编译和执行依靠XML查询引擎完成,引擎的性能问题成为研究重点.目前发展出各种旨在提升引擎性能的XQuery查询优化方法,包括逻辑优化和物理优化等方面,通过查询代数优化设计、查询重写等手段实现[2].
查询优化需要综合考虑查询语言本身特点和实际应用条件等软硬方面因素.一方面,查询重写根据特定规则,为原查询生成较为高效的查询计划,在查询优化过程中广为应用.Brantner M等人提出通过XQuery语言层的重写,获得尽可能接近单一查询块的形式,以便进一步生成优化的查询计划[3].廖伟等人给出XQuery集成系统的查询分解优化方法,通过XQuery查询重写实现,并且引入了新的语法元素以表达针对数据源的操作,该法用于提高多数据源分布式查询的性能[4].另一方面,并行化措施是提升系统性能的重要途径[5],尤其是多核计算环境日益普及的今天.Li X给出一个XQuery并行化框架[6],由编译器完成并行化重写,由于缺乏对通用查询的支持,适用性有限.Re C等人把XQuery语言扩展成面向分布计算的XQueryD语言[7];Fernàndez M等人则设计了用于分布式XML查询的DXQ语言[8];Yui等人在XBird查询引擎上扩展了并行功能,通过远程代理传递数据实现按需查询[9],这些工作主要面向分布式查询应用,面向单机多核并行计算的研究目前仍然很有限.
考虑既要获取高效的查询计划,又要充分利用多核计算环境,本文分别在XQuery语言层和中间语言层开展工作,给出使用查询重写技术和数据并行技术进行查询优化的方法,综合这两种技术以提高查询引擎整体性能.
1 查询重写优化
1.1 XQuery查询分析
XQuery作为XML查询的专用语言,主要作用是从XML数据中查找和提取元素及属性,并重新组织XML数据输出.XQuery中最重要的语法结构是FLWOR语句,其表达式语法[1]定义形如FLWORExpr ::= (ForClause | LetClause)+WhereClause? OrderByClause? "return" ExprSingle.对应的语法组成包括ForClause | LetClause变量绑定子句(FL),where谓词过滤子句(W),OrderByClause排序子句(O),再加上return返回结果子句(R).FLWOR语句可以嵌套使用,以构成功能强大的查询程序,比如ExprSingle可能也是个FLWOR语句.以下XQuery程序来自W3C案例[10],该程序是基于XML的在线拍卖系统中的1.4.4.3查询实例,用于查找等级低于‘C’级的用户,该用户提供的拍卖品低价超过1 000,要求返回相关信息记录.程序如下:
for $u in doc("c:/MR/users.xml")//user_tuple
for $i in doc("c:/MR/items.xml")//item_tuple
where $u/rating > "C" and $i/reserve_price > 1000 and $i/offered_by = $u/userid
return
该程序主体是FLWOR框架,带有两个for子句分别对两个数据源的XPath轴操作结果序列进行变量迭代绑定,这部分可视为数据获取操作;where子句内包含多个过滤条件,以及连接操作;return子句通过轴操作对变量进行投影,并完成XML节点构造并返回.where子句和return子句完成查询的关键工作,往往是耗时最多的地方,其效率受前级数据获取量的影响,因此有必要通过查询重写进行优化.
1.2 查询重写
关系代数中查询优化[11]的一般原则是尽早执行选择操作,以有效减少元组数量,涉及单个表的选择条件尽可能转移到数据源处完成;尽早执行投影操作,以降低后续操作的数据量,对于后续没有需求的属性可以考虑提前去除.该优化思路适用于XQuery查询重写,通过重写来减少前级数据获取量,降低了后续操作次数,有效提高查询性能.
查询重写的方法是遍历表达式语法树,分析依赖数据源的操作;判别数据获取的投影操作来源,包括直接轴操作,where子句和返回子句中的轴操作;把来自不同数据源的投影操作分离出,组成对应数据获取表达式的for/let变量绑定子句;判别数据获取的选择操作来源,包括where子句和XPath表达式中的谓词;把来自不同数据源的选择操作分离出,组成对应数据获取表达式的where子句;用let绑定数据获取表达式到返回变量$seq,该变量作为数据获取序列提供后续操作使用;在提取后的主体表达式中,用$seq变量替换原有的数据获取操作,框架剩余保持不变.一个重写前的典型查询程序如下:
for $x in doc(1), $y in doc(2)
where fun($x,$y)
return
该程序包含了常见的涉及多个数据源操作的FLWOR表达式.doc表示数据源连接与获取,包含了各种直接的轴操作,其中where条件表达式fun($x,$y)内含有连接表达式join($x,$y)、选择表达式filter($x,cond1)和filter($y,cond2)、投影表达式proj1($x)和proj1($y).连接表达式与两个以上数据源相关,而选择和投影表达式仅与单个数据源有关.return返回结果构造表达式,内含有投影表达式proj2($x)与proj2($y).
用提取的选择表达式构成对应数据获取表达式的where条件部分;用原来where条件表达式中和返回结果中的投影表达式构造对应数据获取表达式的返回结果表达式.用提取的连接表达式join($x,$y)构成新的主体表达式中的where条件表达式,该主体表达式变成对数据源获取结果序列的迭代处理.重写后的结果如下:
1: let $xseq:= for $x in doc(1)
2: where filter($x,cond)
3: return {proj1($x), proj2($x)}
4: let $yseq:=doc(2)
5: where filter($y,cond)
6: return {proj1($x), proj2($x)}
7: for $x in $xseq, $y in $yseq
8: where join($x,$y)
9: return
其中语句1~6为数据获取表达式;语句7~9为包含连接操作的主体表达式.查询重写结果仍然使用XQuery语法,并未增加新的语法元素,有利于本层次重写结果的可移植性.
对1.1节中的案例经查询重写后如下,
let $useq:=for $u in doc("c:/MR/users.xml")//user_tuple
where $u/rating > "C"
return
let $iseq:=for $i in doc("c:/MR/items.xml")//item_tuple where $i/reserve_price > 1000
return
for $u in $useq,
$i in $iseq
where $i/offered_by = $u/userid
return
重写前后的查询计划,用查询代数算子表示分别为示意图1(a)和1(b).为了简化表示,图中的XML节点名称仅用第一个字符;涉及的主要查询代数算子包括连接,投影π,选择σ和节点构造χ.
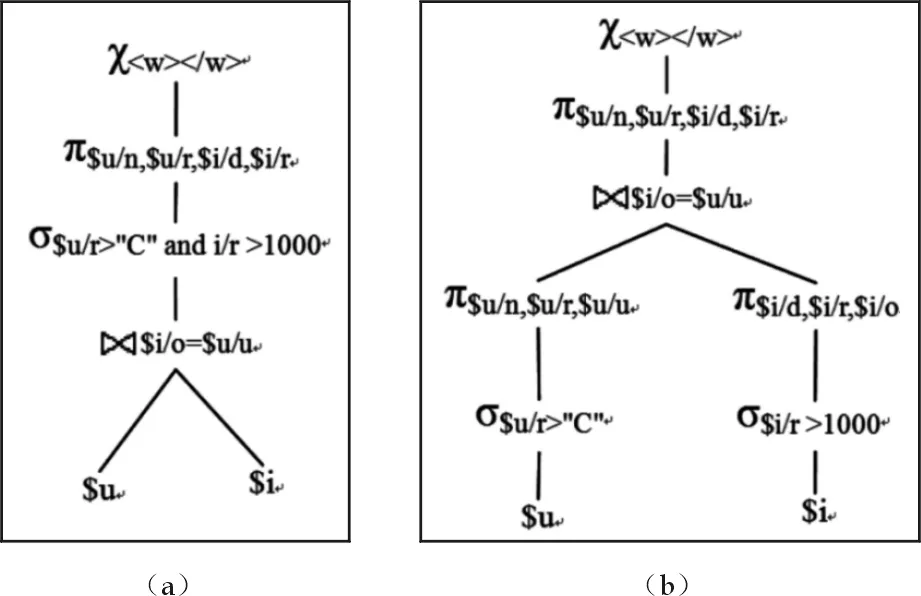
图1 查询计划组织示意
2 数据并行处理
2.1 pFL中间语言
由于XQuery语言面向开发人员,语法形式丰富但较为复杂,在查询引擎设计中,有必要引入更为简洁的中间语言表达查询计划,以利于优化处理.本文引入的pFL中间语言,主要采用函数调用形式进行表达式求值,易于通过函数原语并行化设计来实现并行.
pFL语法主要包括3类基本表达式:
(1) 常量 e::=c
(2) 带局部变量 e::=e where (id=e)* (id(id*)=e)*
(3) 函数调用 e::=id(e*)
其中e∈Exp表达式;id∈ID变量或函数名;c∈Const常量.用id=e表示变量绑定,即变量id的定义;用id(id*)=e表示函数绑定,即函数id()的定义,该函数带有数个变量.函数调用表达式中,当id为并行原语时,支持并行化处理.
2.2 原语数据并行
FLWOR表达式在中间语言层翻译成各种操作原语组合,其中常用的FOREACH、FOREACHAT、FILTER和FILTERAT等原语用于对序列的迭代操作,适合进行数据并行化设计.使用pmap描述用于数据并行操作,其功能简记为pmap(D,F,T)=join(map(D, fork(F), type(F)),其中变量D为数据对象,F为操作任务,T表示操作类型;用type获取操作任务的类型;用fork指定线程执行任务;map为描述数据迭代处理的基本原语;join进行必要的结果排序和除重.
使用pmap组织数据并行的求值语义描述如下:
pmap::[Thread]→Exp→Exp→Int→Val
pmap((t:ts), (x:xs)┣[e1]ρ, e2, op)= switch(op):
case FOREACH: [e2]ρl{ ρl=ρ+x+t┣getThread(1)}: pmap(ts,xs,e2,op)
case FOREACHAT: ([e2]ρl{ ρl=ρ+x+t┣getThread(1)},index(x)): pmap(ts,xs,e2,op)
case FILTER: (if[e2]ρl{ ρl=ρ+x+t┣getThread(1)} =true) then x else ε): pmap(ts,xs,e2,op)
case FILTERAT: (if [e2]ρl{ ρl=ρ+x+t┣getThread(1)} =true) then (x,index(x)) else ε): pmap(ts,xs,e2,op)
其中ρ,ρl∈Env = (id┣Val)*+(t┣Thread)*,分别表示当前求值环境、线程相关局部环境,这里用v┣E表示把变量绑定到表达式E的求值结果;id∈ID变量/函数名称;t∈Thread逻辑工作线程;局部环境ρl由线程、函数闭包以及保存本地变量值及中间计算结果的局部堆空间等对象组成.内部函数getThread(n)表示从线程池中获取n个线程;index(x)表示获取x在序列中的索引.
查询重写优化后,由于分离出了数据获取表达式,中间语言层的函数调用关系更为清晰,有利于可并行性分析.对1.2节查询重写后程序语句7的$x迭代操作部分并行化,语句7~9的对应的pFL描述形式如:PMAP($x,FOREACH(FILTER($y, JoinFun($x,$y)), ReturnFun), FOREACH),其中JoinFun表示用pFL表达的连接操作函数,ReturnFun表示用pFL表达的返回操作函数.原来的for子句迭代操作转换为FOREACH原语函数调用,而where条件子句转换为FILTER原语函数调用.
2.3 代价优化设计
由于FLWOR语句往往嵌套使用,翻译后的查询程序可能存在多个嵌套的迭代原语,如果都进行并行化处理,可能造成任务粒度过细,线程管理和通信开销将抵消并行处理带来的性能提升,因此可结合代价分析等手段,识别需要调用并行化原语的地方.
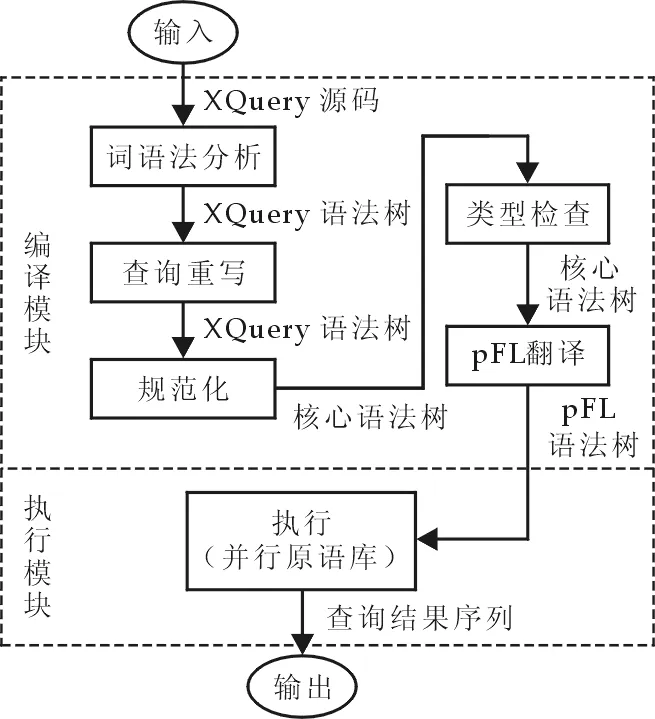
图2 XQuery查询引擎工作流程
影响代价的因素包括数据类型、数据量、操作频度和操作类型.代价计算公式记为:C= kind(F, type(D))×size(D),其中C为无量纲的代价值,F表示计算原语,D表示作为内部对象类型的序列数据,kind用于判定并获取不同操作类别在不同数据类型下的代价,type用于获取数据类型,size用于获得数据对象个数,对应F的处理频度.基本优化策略是:在中间语言层估算有效计算的执行时间代价,选择代价高的迭代操作进行数据并行;此外,为了控制并行任务的粒度,根据代价对数据迭代操作进行分组,为每组计算任务分配一个工作线程.
3 原型系统构建
开发的XQuery查询引擎原型系统包括了编译模块和执行模块.其中编译模块包括了词语法分析、查询重写、规范化、类型检查、pFL翻译等阶段;执行模块整合了基本执行原语,包括并行化的查询原语,图2显示了引擎的工作流程.在词语法分析阶段完成XQuery源码的词法和语法分析,生成XQuery语法树;查询重写阶段实现第1节介绍的重写优化;在规范化阶段实现向XQuery核心语言[12]转换,降低中间语言描述的复杂性,完成语法树的预处理;在类型检查阶段需要根据XQuery的语义规范进行静态类型检查,完成早期程序错误检测;在pFL翻译阶段实现pFL查询计划重写,选择适当位置使用并行原语.执行模块中引擎以函数调用形式完成表达式求值,其中调用并行原语函数以实现并行处理.
4 实例测试
为了验证优化方法的实际效果,选取W3C测试案例[10]1.4.4节中9个实例作测试.Q1至Q9查询分别对应第2、3、4、6、11、15、16、17和18查询实例,这些查询的特点是涉及多个数据源的数据获取和连接操作.查询涉及3个XML文档数据,鉴于原有的数据量较小,本文根据案例提供的DTD重新生成较大的XML数据,以模拟实际应用情况.测试硬件平台为AMD Athlon II X4 620 (2.60 Ghz) 多核PC,软件环境是Windows XP系统运行JDK1.6.0_18.图3显示了各实例在查询重写优化前后的执行时间对比.比如Q2的主体是带两个for的FLWOR结构,where子句包含过滤操作和连接操作,通过数据源过滤操作的提取获得较小相关数据集,大大降低了连接操作强度,执行时间大幅缩短为重写前的17%.Q8仅带有一个for子句,where子句未带过滤条件,仅进行数据源投影操作提取获得较少属性的数据,执行时间缩短为原来的58.1%.总体来看,各个实例重写后性能均有较大提升,案例平均执行时间缩短为优化前的27.3%.

图3 查询重写优化前后执行时间对比 图4 并行化前后执行时间对比
并行测试的配置采用Java Concurrent的线程池模式,未设置固定线程数目,由JDK管理线程分配.在已完成查询重写优化的前提下,对并行化前后执行时间对比如图4所示,在未进行优化的情况下,平均效率提升31.6%.并行粒度和负载均衡程度直接影响到并行化效果,通过优化代价模型和任务调度设计,有望进一步提高并行效率.
5 结束语
高效实用的XQuery查询引擎的设计通常需要整合各种查询优化措施.针对XQuery多数据源查询进行重写优化,由于未增加或修改任何语法元素,在XQuery语言层的重写结果同样适用于其他查询引擎,具备良好可移植性.为了充分利用多核计算环境以进一步提升查询性能,在中间语言层通过使用并行原语实现了数据并行处理.引入代价模型为合理识别可并行性与控制并行粒度提供了优化手段.原型系统的测试实验结果验证了优化方法的有效性.
参考文献
[1] Boag S, Chamberlin D, Fernández M F,etal. XQuery 1.0: An XML query language[EB/OL]. http://www.w3.org/TR/xquery/.2011-03-29.
[2] 孟小峰,王 宇,王小锋. XML查询优化研究[J]. 软件学报, 2006,17(10): 2 069-2 086.
[3] Brantner M, Kanne C C, Moerkotte G. Let a single FLWOR bloom[J]. Database and XMLTechnologies, 2007(2): 46-61.
[4] 廖 伟,廖湖声,任 宇. 基于 XQuery 的数据集成系统中的查询分解算法[J]. 通讯和计算机, 2005,2(6): 24-30.
[5] Sutter H. The free lunch is over: A fundamental turn toward concurrency in software[EB/OL].http://www.gotw.ca/publications/concurrency-ddj.htm.2011-04-10.
[6] Li X. Efficient and parallel evaluation of XQuery[D]. Columbus: The Ohio State University, 2006.
[7] Re C, Brinkley J, Hinshaw K,etal. Distributed xquery[C]//Workshop on Information Integration on the Web. Citeseer, 2004:116-121.
[8] Fernández M, Jim T, Morton K,etal. DXQ: A distributed XQuery scripting language[C].Proceedings of the 4th International Workshop on XQuery Implementation, Experience and Perspectives. ACM, 2007:1-6.
[9] Yui M, Miyazaki J, Uemura S,etal. XBird/D: distributed and parallel XQuery processing using remote proxy[C].Proceedings of the 2008 ACM Symposium on Applied Computing. ACM, 2008:1 003-1 007.
[10] Chamberlin D, Fankhauser P, Florescu D,etal. XML Query Use Cases[EB/OL]. http://www.w3.org/TR/xquery-use-cases/.2011-03-29.
[11] Garcia-Molina H, Ullman J. D, Widom J. Database system implementation[M]. Prentice Hall Upper Saddle River, 2000.
[12] Draper D, Fankhauser P, Fernández M F,etal. XQuery 1.0 and XPath 2.0 Formal Semantics[EB/OL]. http://www.w3.org/TR/xquery-semantics/.2011-04-10.
