决策树ID3算法的改进及其应用
2011-01-29盛俊
盛俊
(扬州职业大学,江苏扬州225009)
在分类规则挖掘中,决策树是一种常用的有效的方法。在决策树的各种算法中,最为有影响的是Quinlan于1979年提出的以信息熵的下降速度作为选取测试属性标准的ID3算法。ID3发展了CLS算法,CLS算法是1966年由Hunt等提出的一种决策树学习算法。该方法使用最大信息增益选择测试属性,使分类的效率和质量都得到提高。Quinlan基于窗口技术进行增量式学习,窗口随机性地从数据集中选择一个子集,从而逐步形成完整的决策树[1]。
1 ID3的改进算法
ID3算法把信息熵作为选择测试属性的标准,而每次信息增益的计算很大程度上将受多值偏向性问题影响,即有优先选取取值较多的属性的倾向。多值偏向所带来的问题是:把属性在分类中的重要性与属性取值数多少关联起来,认为取值较多的属性在分类中具有更重要的作用。而事实上取值较多的属性却不总是最优的属性,增益的计算依赖于特征取值的数目较多的特征,这样不太合理。这就难以判断得到的测试属性究竟是因为本身比较重要还是由于多值偏向取值较多的缘故而得到的。
ID3算法还存在着另一个不足之处,就是它忽视了属性之间的交互作用。对于每个结点,ID3算法总是希望选择测试属性时实现熵的最大化减少,即含有最大信息增益的属性作为结点的分裂属性。然而由于ID3算法只考虑到使属性带来的信息增益最大,忽略了属性之间的交互信息,进而忽略了属性所带来的信息增益是否完全的实现了信息熵的减少。
上述缺陷影响了分类预测的高效性。因此,对ID3算法进行改进,主要在如下两个方面:
1.1 基于属性优先值的属性选择
首先,针对增益依赖于选取特征值较多的特征,本文引入了属性优先值的概念。用户可以根据事实情况,依照本领域的实际需要,来选择一个有关于属性的优先值,而这个属性优先值能加大对决策树生成和修改的影响,从而起到避免出现所选属性与现实无关或大数据量掩盖小数据量的错误。
然后,针对规则生成方法即属性选择标准算法进行了改进,通过增加属性优先值参数,最终使决策树减少了对取值较多的属性的依赖性,从而尽可能地减少大数据掩盖小数据的现象发生。对每个属性Ai,用户定义一个优先值为αi,使其满足:
(1)设所有属性的集合为{Ai,i=1,2,…,r},
(2)对于较重要的属性,赋予较大的属性优先值。则
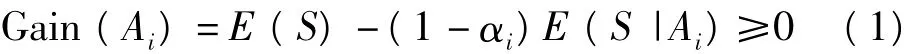
这样,可以使具有较高权值的属性得到较大的增益,加强了重要属性的影响,使生成决策树时数量少的数据元组不会被淹没。
1.2 基于属性交互作用的属性选择
如图1所示,每个圆代表属性或类。根结点的初始信息熵E(C),设在根结点选择测试属性AS,剩余的信息熵为SE(C)-S3-S4,并将根结点按属性AS的值进行划分得到树的第一层分支,然后在根结点的一个子结点按照ID3算法选择测试属性Ai,使得Gain(S2+S3)最大化,剩余的信息熵为SE(C)-S3-S4-S2,可以看出真正减少的信息熵是S2而不是S2+S3,因为S3所代表的那部分信息熵已经通过父结点使用属性AS消减了。S2+S3大,并不一定S2大,所以使用ID3算法并不能真正实现信息熵的减少。
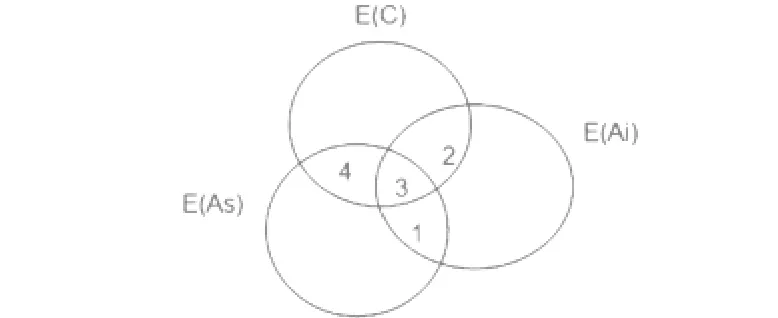
图1 属性与信息熵
因此,每当选择一个新的属性时,算法不仅考虑到属性带来的信息增益,还考虑到选择该属性后为继续选择的属性所带来的信息增益,即同时考虑属性之间的交互信息。为此,我们提出采用考察树的两层结点的方法。具体做法如下:
设A为侯选的属性,A具有r个不同的值,对应的概率分别是p1,p2,…,pr,按照最小信息熵原则对属性A扩展,设{B1,B2,…,Br}为r个子结点选择的属性,{S1,S2,…,Sr}为划分到这些节点的样本集合。分别计算条件信息熵{E(S1|B1),E(S2|B2),…E(Sr|Br)},定义A的交互信息熵为:
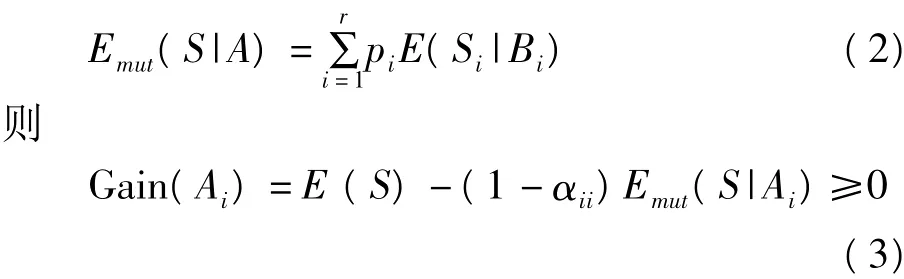
改进的ID3算法使用上述的公式(3)计算增益中,由于考虑了下一层各个分支上的信息熵,在选择测试属性时不仅要求所选的属性带来的信息增益尽可能大,而且要求其与同一分支上已经使用过的各属性之间的交互信息尽可能小,从而避免了对冗余属性的选择,实现信息熵的真正减少。
2 实验测试
表1为一个可能带有噪音的扬州百年老店共和春酒店餐饮客户数据集合,使用ID3的改进算法进行测试。它有四个属性:“类型”、“用餐时间”、“用餐地点”、“用餐人数”。分为两类:“点菜”与“和菜”。“类型”是指客户的类型,属性值有“机关和事业”、“企业”和“个人”三类;由于酒店不供应早餐,“用餐时间”有“中午”、“晚上”两类;“用餐地点”分“大包厢”、“小包厢”和“堂厅”三类;“用餐人数”分为少、中、多三类,用餐人数少于5人为“少”,在6到10人之间为“中”,11人以上为“多”。所要做的就是构造决策树将客户数据进行分类。根据实际经验,对“类型”、“用餐时间”、“用餐地点”、“用餐人数”四个属性分别赋予属性优先值0.4、0.3、0.1、0.2。

表1 餐饮客户数据
根据公式(3)计算出“类型”、“用餐时间”、“用餐人数”、“用餐地点”四个属性的增益值分别为0.247、0.234、0.147和0.144。由于“类型”属性具有最小的交互信息熵,他被作为测试属性,创建根节点“类型”,并对每一个属性值引出一个分支,再据此来划分样本数据。然后依次对各个分支递归调用同样的方法,直到每个分支的样本都属于同一类为止。最后得到见图2的决策树。
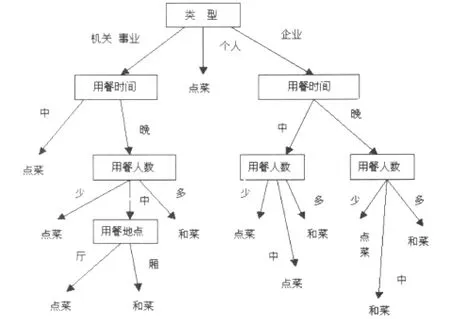
图2 餐饮客户决策树
3 决策树算法在营销决策支持系统中的应用
将决策树算法应用于营销决策支持系统中,可通过对历史数据的研究,准确地预测产品与目标市场的关系,从而为决策者提供营销决策依据。在本文的营销决策支持系统中,有这样的一个问题,即企业的所有销售市场中,有高、中、低档等产品大类,在目标市场上,可通过营销决策支持系统预测产品的市场需求,具体步骤如下。
3.1 数据预处理
在确定数据仓库的信息需求后,首先进行数据建模,然后确定从源数据库到数据仓库的数据提取、清理和转换等。
数据提取:从综合数据库中提取出当前主题需要的那部分数据。由于该部分主要是有关产品、市场、促销的数据,所以元数据主要是日期时间、产品名称、销售价格、销量、区域市场、广告促销名称和广告促销费用等。
数据清洗:数据清洗是整个数据仓库的数据入口,通过数据清洗将获取有效的数据。
数据转换:由于数据仓库中各个主题中的数据是按照前端应用的需求存放的,因此在数据清洗后必然存在一个数据整理和转换的过程,这一过程需要对数据进行变形,使之适应前端应用的需要。
3.2 数据仓库模型设计
从上述主题出发,设计出的雪花模型,见图3。
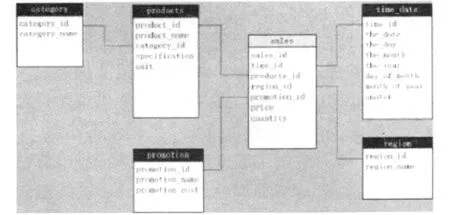
图3 产品销售雪花结构的模型
在主题中,根据研究问题的需要,共有四个维度和两个度量值。四个维度分别是产品维、时间维、区域市场维和促销维,度量值分别是产品的销售价格、数量(销量)和促销费用。由图3可知,本主题的事实表为sales表;维度表为product表、time—date表、region表、promotion表。
3.3 前端程序设计
采用.NET2003中的C#作为前台开发工具,利用上述改进的算法实现挖掘结果的输出。
3.4 结果输出
结果输出有多种形式,如微软的OLAP中利用决策树进行数据挖掘显示的结果是树形图表,而且是动态的。
[1]JIAWEI HAN,MICHELINE KAMBER.Data Mining:Concepts and Techniques[M].Boston:MIT press,2000.
[2]邵峰晶,于忠清.数据挖掘——原理与算法[M].北京:中国水利水电出版社,2003.
[3]韩慧,毛锋,王文渊.数据挖掘中决策树算法的最新进展[J].计算机应用研究,2004(12):5-8.
[4]FAYYAD U,PIATETSKY-SHAPIRO,SMYTH,et al.Advances in Knowledge Discovery and DataMining[M].Boston:MIT Press,1996.
[5]林剑广,邬义杰.基于数据仓库的商业营销决策支持系统开发[J].计算机应用与软件,2004(2):39-40.
