基于余弦过完备原子库的语音信号MP稀疏分解
2011-01-23李雨昕
李雨昕
(四川师范大学 成都学院,成都 611745)
语音通信在人类生活中扮演着极其重要的角色。为了保证语音信息的有效获取,在实际应用中需要对语音信号进行去噪、增强、压缩、编码等一系列处理[1]。而这些处理的效果都依赖于信号的表示方式。通常的做法是将语音信号分解在一组完备的正交基上,该方法会导致用基的组合表示语音信号时表达的不简洁性,即语音信号表示不是稀疏的。这将不利于语音信号的处理。Mallat S和Zhang Z首先提出信号在过完备库上分解的思想[1]。信号在过完备库上的分解,其分解结果将可以得到信号一个非常简洁的表达(即:稀疏表示)。得到信号稀疏表示的过程称为信号的稀疏分解。由于信号稀疏表示的优良特性,该表示方法已经被应用到信号处理的多个方面,如信号去噪[2]、信号识别[3]、信号时频分布[4]等。目前,大多数的稀疏分解研究都是基于Gabor原子库进行的,该原子库上的信号稀疏分解计算量十分巨大,计算时间在现有计算条件下令人无法忍受。
针对此问题,本文在分析语音信号具有类似余弦信号周期性特性的基础上,根据信号稀疏分解具有按照信号本身特点自适应地选择原子,使所选原子与信号的非线性逼近误差最小化的特点,选用余弦过完备原子库,并在该原子库上完成语音信号的稀疏分解。相比在Gabor过完备原子库上的语音信号稀疏分解,在余弦过完备原子库上的分解速度得到了一定程度的提高,同时对原子库中原子个数的要求也有所降低。
1 算法描述
图1是从实际录制的语音信号中截取N=256的一段语音信号(为语音信号的长度)。从图1中可以明显地看出语音信号具有类似余弦信号的周期特征。
1.1 余弦过完备原子库
根据语音信号具有类似余弦信号周期性特征,本文采用如下的过完备原子库:

其中,n=0,1,…,N-1,N 为信号长度。也就是说原子 gγ的长度和语音信号的长度相同。原子应作归一化处理,即│gγ│ =1,其中│·│表示原子的范数,其定义是在H=RN信号空间中信号到该空间坐标原点的距离。fm为频率参量,按照需要的搜索精度均匀取值,m=0,1,…,M-1,M 为整个原子库中原子的个数。M应远远大于语音信号的长度N,以保证原子库的过完备性。原子参数γ由m单独确定。当搜索的间隔越小,M的值越大,即原子库中原子的个数越多。图2是N=256,M=10 240时随机抽取的过完备原子库中的3个原子样本。
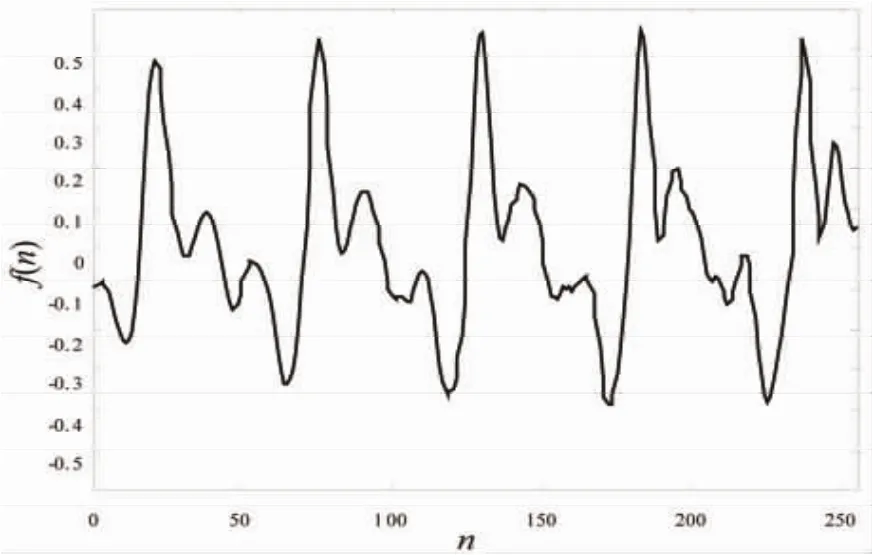
图1 N=256长的实际语音信号
1.2 基于余弦过完备原子库的MP语音信号稀疏分解
通过以上分析可知,余弦过完备原子库中的原子更加贴近语音信号的周期特征,因此本文设计基于余弦过完备原子库的语音信号MP稀疏分解算法为:
1)设置分解参数。构造如式(1)所示的过完备原子库。根据语音信号的长度N适当地选择原子库的大小M,保证M≫N。

图2 余弦过完备原子库中的3个原子样本
2)形成过完备原子库。根据分解参数形成一系列的原子,最后形成整个过完备原子库。
3)在过完备原子库中寻找最为匹配的原子。算法采用常规的MP算法,求解如式代表的最优化问题。求得在过完备原子库中与语音信号或语音信号残差最为匹配的原子。

图3 余弦过完备原子库和Gabor过完备原子库对比实验1
4)完成一步分解。利用3)中寻找到的最佳原子,从语音信号或语音信号的残差中去除其在该原子上的分量,完成一步分解。记录此步最佳原子的参数,作为该步分解的结果。
5)分解完成。利用分解步数(相对应于原子的数目)判定分解是否完成。如果分解达到了事先规定的步数,就停止分解。
2 仿真实验结果
仿真实验使用的信号是从录制的语音信号中分别截取长度N=256的2段语音信号。实验中使用按式(1)构造的过完备原子库。根据语音信号的长度N=256选取M=10 240(M≫N),即形成的过完备原子库中原子的个数为10 240。图3和图4给出了在Matlab环境下原始语音信号及其分别在余弦过完备原子库和Gabor过完备原子库MP稀疏分解为30个原子后重建的语音信号和语音信号残差。表1和表2分别为图3和图4相应的语音信号基于2种原子库MP稀疏分解为30个原子所用时间t及重建信号的MSE值比较,其中,为重建信号误差的均方根值。

表1 基于2种原子库的语音信号MP稀疏分解重建信号所用时间t和MSE值比较
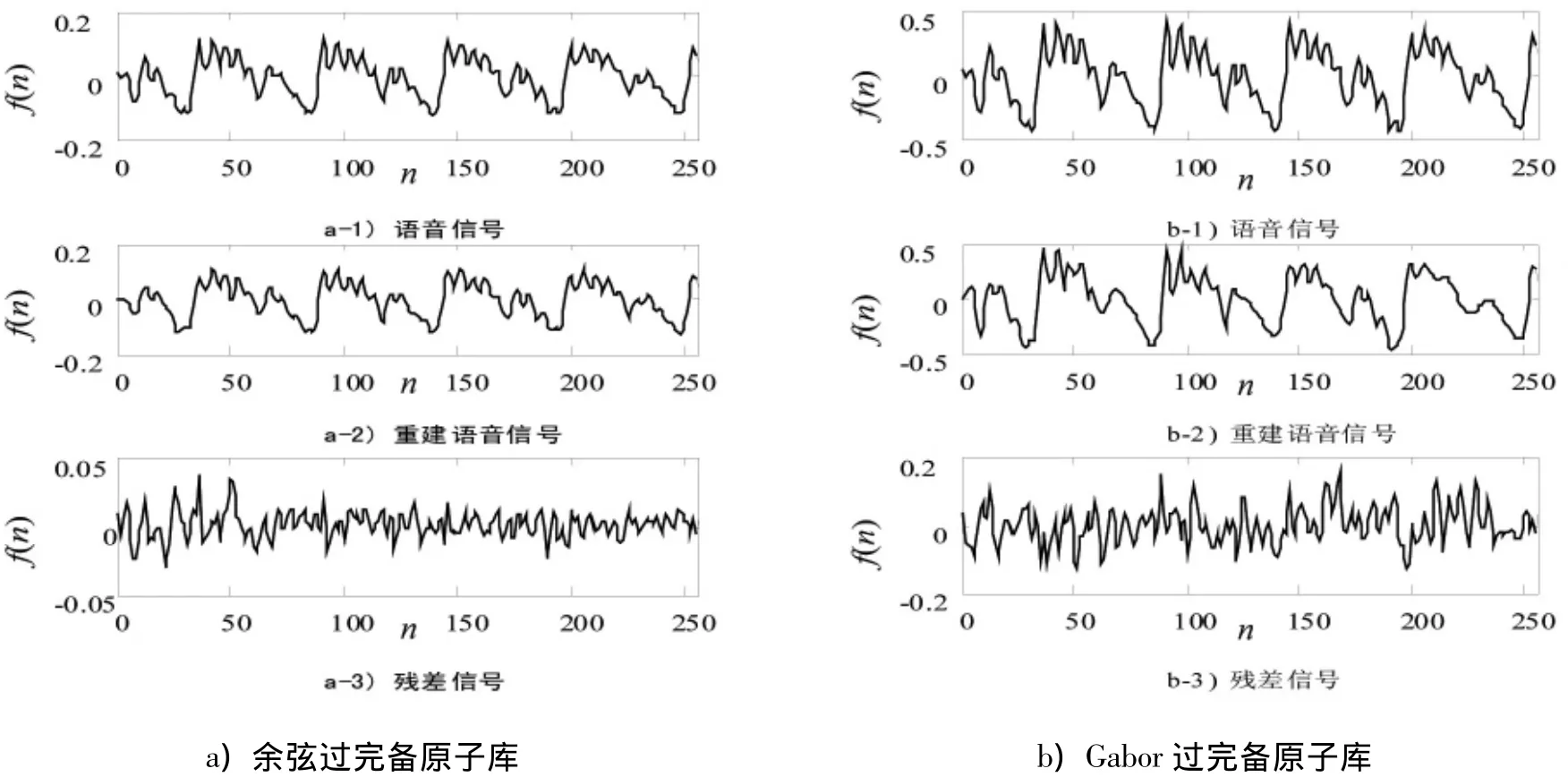
图4 余弦过完备原子库和Gabor过完备原子率对比实验2

表2 基于2种原子库的语音信号MP稀疏分解重建信号所用时间t和MSE值比较
3 实验结果分析
仿真实验中仅用30个原子即可表示长度为256的语音信号,相对于正交分解需要使用256个基来说,充分说明该表示方法的稀疏性。
从图3、图4及表1、表2中可以看到重构信号很好的近似了原始的语音信号,说明了基于余弦过完备原子库的语音信号MP稀疏分解算法的有效性。同时,还可以看到基于余弦过完备原子库的语音信号MP稀疏分解后重建的语音信号比基于Gabor过完备原子库的语音信号MP稀疏分解后重建的语音信号从信号的质量来讲要稍微好些。实验中所用的余弦过完备原子库中原子的个数M=10 240。又因为N=256,根据文献[3]中提供的计算方法可计算出Gabor过完备原子库中原子的个数约为12万个,其原子数量是余弦原子库中原子数量的11.7倍。信号稀疏分解的计算量主要由形成原子库的计算量和信号在过完备原子库上分解的计算量这两部分组成[5],该计算量巨大。而计算量过大、计算速度过慢和存储空间要求过高也是制约信号稀疏分解应用的主要瓶颈。如果过完备原子库中原子的数量减少,则信号在过完备原子库中分解的计算量将大大减少,计算的速度也将大大提高,同时算法所需要的存储空间也将降低。
4 结论
本文根据语音信号的特征选用余弦过完备原子库,不仅能够提高语音信号MP稀疏分解的速度,同时还降低算法所需的存储空间,并提高了重构信号的质量。实验证明余弦过完备原子库更适合具有类周期特性的语音信号。
[1]MALLAT S,ZHANG Z.Matching pursuit with time-frequency dictionaries[J].IEEE Trans.on Signal Processing.1993,41(12):3397-3415.
[2]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2005.
[3]ARTHUR P L,PHILIPOS C L.Voiced/unvoiced speech discrimination in noise using Gabor atomic decomposition[C]//Proceedings of IEEE ICASSP.Hong Kong:[s.n.],2003:820-828.
[4]邹红星,周小波,李衍达.时频分析:回溯与前瞻[J].电子学报,2000,28(9):78-84.
[5]王建英,尹忠科,张春梅.信号与图像的稀疏分解及初步应用[M].成都:西南交通大学出版社,2006.
