不完全朴素贝叶斯分类模型在垃圾邮件过滤中的研究
2011-01-12董萍
董 萍
(三门峡职业技术学院信息工程系,河南三门峡 472000)
伴随着网络的发展和电子邮件的广泛应用,令用户烦恼的垃圾邮件大量产生,它严重占用网络带宽,影响网络服务的正常进行;侵犯收件人的隐私权,耗费网络存储空间;附件中带有的病毒或木马,给个人计算机安全带来极大危害[1]。鉴于这些危害,过滤垃圾邮件也就随之成为人们的重要工作之一。垃圾邮件分类是对在网络上传递的邮件进行判别分类,阻塞非法邮件的传递。本文引入 N平均 1-依赖邮件过滤模型的新的邮件过滤分类模型,在一定程度上考虑了属性之间的语义关联,对垃圾邮件的过滤更有效。
1 N平均 1-依赖邮件过滤模型
朴素贝叶斯分类模型[2]是对贝叶斯分类模型的简化,它因简单、高效在邮件过滤应用的研究中扮演着重要的角色。x-依赖的贝叶斯分类模型既有NB分类模型的高效性,又能保留部分的属性之间的关联以便能获得更好的分类效果。
该分类的条件独立假设割裂了属性之间的关系,影响了分类的准确性,放松朴素贝叶斯分类模型关于属性之间条件独立假设。该分类模型放松了NB分类模型对属性之间条件独立假设的约束,允许每一个属性和最多 x个属性条件依赖,即该属性有x个父属性。
基于上述思想,本文提出了一种新的邮件分类模型,N平均 1-依赖邮件过滤模型[3]。该模型依据属性之间的互信息大小挑选出 N个属性作为父属性,依次按照 1-依赖分类模型计算各个类别标签的后验概率,最后取 N个 1-依赖后验概率的平均值作为分类概率。
N平均 1-依赖邮件过滤模型如式 (1)。

式 (1)给出了朴素贝叶斯分类模型,其中的 Pr(cy)为各个类标签的先验概率该模型的关键就是选取哪些属性来作为父属性,模型使用平均互信息来选取 N个属性。
x-依赖的贝叶斯分类模型放松了 NB分类模型对属性之间条件独立的假设,允许属性和最多 x个属性条件依赖。NB分类模型就是一个 0-依赖的贝叶斯分类模型。考虑到计算的复杂性问题,构建一个 1-依赖贝叶斯分类模型是一个较好的选择。由于这种分类模型放松了 NB的条件独立假设,所以称做不完全朴素贝叶斯分类模型。
基于不完全的朴素贝叶斯分类模型,提出一种新的邮件分类模型,N平均 1-依赖邮件过滤模型[4]。该模型使用属性所携带的平均互信息的大小衡量属性的权值的高低,并对其进行排序。具有较高权值的属性对分类效果的影响较大,所以权值高的属性应该优先被选择为父属性。最后,模型选取排在最前面的N个属性作为候选的父属性。
2 算法描述
对于每一封测试邮件,具有 m个属性和 2个类别标签 (垃圾邮件类别标签 Cspam与合法邮件类别标签Clegit)。
Step 1:确定 N值;
Step 2:计算属性 attri与其他属性 <attrl,attr2,…,attri-1,attri+1,…,attrm>之间的互信息量;
Step 3:挑选出互信息量最高的 N个属性构成super-parent集合;
Step 4:依次从候选的父属性集合中取出属性按照 One-Dependance-Estimate进行类别概率计算;
Step 5:计算 N个 ODE概率的平均值作为最终的分类概率;
Step 6:输出邮件的类别估计,结束算法。
3 实验与分析
3.1 实验设计
实验环境:实验的硬件平台为一台 IBM Pc计算机,配置为双核 3.0GHz Pentium CPU、2G内存,操作系统为 Windows XP sp2。实验环境依然是在 eclipse3.2上运行Weka机器学习实验环境。
实验数据:垃圾邮件数据集 Spambase有 57个属性,1个类别标签属性含有两个类别标签 (合法邮件和垃圾邮件)。Spambase数据集总共包含有 4601封邮件,其中有 2788封邮件为合法邮件 (Legit),有1813封邮件为垃圾邮件 (Spam)。垃圾邮件的数量占邮件数目总体的 39.4%。
在实验的过程中,数据集被近似平均地划分为10个子集进行 10次交叉验证,取其平均值为最终的测试结果。每一次交叉验证,都使用一个不同的子集来作为测试数据集,其他的子集作为训练数据集。这样,每一个子集都会被作为测试数据进行分类计算。
3.2 实验结果与分析
图1显示了基于 N平均 1-依赖邮件过滤模型的 0-1损失分类错误率曲线。图中的 X轴表示测试邮件的数量,实验测试了从 2000封邮件到 4500封邮件的分类准确率,其中的间隔为 500。Y轴表示不完全朴素贝叶斯分类模型对邮件分类的 0-1损失错误率。不同的曲线表示了分类模型在取不同的 N值的分类结果。错误率越小,模型的分类准确率越高,分类性能越好。
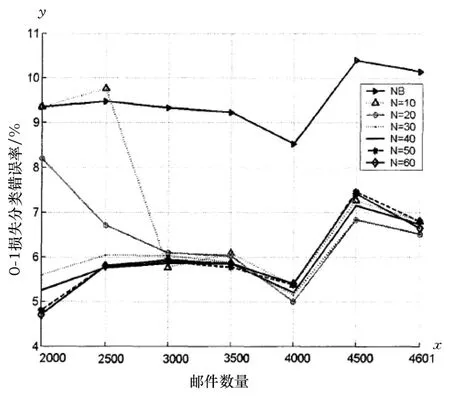
图1 spambase数据集在 N平均 1-依赖邮件过滤模型中的结果
从图1中可以看到,NB分类模型 (即当 N=0的时候)达到较高的邮件分类准确率 (89%—91.5%),但是 N平均 l-依赖分类模型达到了更佳的分类结果。图1显示了 N=10,20,30,40,50和 60的时候的分类错误率曲线,除了 N=10的曲线在邮件数目为 2500封邮件时的分类错误率略高于 NB分类模型外,其他的曲线都显示了 N平均 1-依赖邮件过滤模型的分类错误率低于 NB分类模型。同时,虽然添加依赖属性能降低分类的错误率,但是添加更多的父属性数目需要有更多的计算时间,另一方面从实验结果中可以看到并不是 N值越高越好。N=20的曲线,虽然在 2000到 3500的实验结果不如N=30,40,50和 60的实验结果,但是在邮件数量增多后,在 4000封及以上的时候,N=20达到了最好的分类效果 (最低的错误率)。当邮件数目很多的时候,实验显示N值取 20是一个较好的选择。
当邮件总数从 4000增加到 4500的时候,分类错误率有一个较大幅度的上升。出现这个现象的原因可能是因为新增加的 500封邮件中有部分邮件特征向量导致了分类错误率的突变。虽然如此该实验的目的是比较不同的 N值条件下分类模型在不同邮件数目下的分类效果,该突变对实验的最终结果没有太多的影响。该实验的结果显示了实验达到了预先的目的。
4 结束语
在不完全朴素贝叶斯分类模型的基础上提出了一种基于不完全朴素贝叶斯的垃圾邮件分类模型:N-平均 1-依赖邮件过滤模型。该模型放松朴素分类模型条件独立假设,利用 N个 1-依赖贝叶斯分类的平均概率估计值来对邮件的类别进行判别。经过实验证明,该模型到达了更好的分类效果,得到了更低的分类错误率。同时,实验验证了 N的取值并不是越大越好,当邮件数在 4000封以上的时候,N取20是不错的选择。
[1] 刘震.垃圾邮件过滤理论和关键技术研究[D].成都:电子科技大学,2007.
[2] 衣治安,毛岩.垃圾邮件过滤技术概述[J].长江大学学报 (自然科学版),2010,3(7):256-258.
[3] 谢建伟,魏晓宁.基于内容的垃圾邮件过滤技术综述[J].黑龙江科技信息,2008,36(94):95-96.
[4] 时红梅,高茂庭.垃圾邮件过滤技术及发展[J].计算机与数字工程 [J],2008,36(6):128-132.
