我国城镇登记失业率的数学模型与预测
2010-12-07杨帅国胡晓华朱冬和
杨帅国,胡晓华,朱冬和
(海南师范大学 数学与统计学院,海南 海口 571158)
我国城镇登记失业率的数学模型与预测
杨帅国,胡晓华,朱冬和
(海南师范大学 数学与统计学院,海南 海口 571158)
结合中国国家统计局的数据,使用基于核主成分分析与加权支持向量机的方法建立模型,找出了影响就业(失业)的22个主要指标.考虑到这些指标相互之间的相关性,使用核主成分分析与加权支持向量机的方法建模,给出了算法的步骤,构造了非线性预测函数,并对1995-2009年的城镇登记失业率进行拟合预测,得到的结果具有较高的精度.
失业率;核主成分;支持向量机
失业、经济增长和通货膨胀为宏观经济中特别重要的三个指标,按照已有的研究,就业可以定义为三个月内有稳定的收入或与用人单位有劳动聘用关系.失业的统计方法各国差异较大,我国采用城镇登记失业率,是指城镇登记失业人数同城镇从业人数与城镇登记失业人数之和的比.其中,城镇登记失业人员是指有非农业户口,在一定的劳动年龄内(16岁以上及男50岁以下、女45岁以下),有劳动能力,无业而要求就业,并在当地就业服务机构进行求职登记的人员.由于统计口径不同,存在一定的差异,有些历史数据也较难获得.
中央从2008年10月开始实施了4万亿元的投资计划,确定了十大产业振兴计划,采取扩大国内消费需求的措施,提高对外开放水平以增加出口.同时,中央财政拟投入420亿元资金实施积极的就业政策.2009年我国在就业方面的目标是城镇新增就业900万人以上,城镇登记失业率控制在4.6%以内[1].
本文利用近年来我国有关的统计数据并结合一年多来我国国民经济的运行数据就城镇登记失业率做了如下研究.
1)对有关统计数据进行分析,寻找影响就业的主要因素或指标.
2)建立城镇登记失业率与上述主要因素或指标之间联系的数学模型.
3)利用所建立的关于城镇登记失业率的数学模型,根据国家的有关决策和规划对2009年及2010年上半年的我国就业前景进行预测.
1 分析问题并建立模型
结合国家统计局的数据,从宏观层面、中观层面以及中央宏观调控政策做定性与简单定量分析,对各项经济指标进行归纳、汇总.采用冗余变量检验法,最终确定了22个作为影响就业的主要指标:即国内生产总值、居民消费支出、政府购买、城镇社会固定资产投资、第一产业国内生产总值、第二产业国内生产总值、第三产业国内生产总值、工业总产值、建筑增加值、客运量、邮件业务量、各级各类学校数、税收、国内旅游、人民币汇率、外汇储备、货币供应量、货物进出口总额、国家财政收入、国家财政支出、对外经济合作、城镇居民人均收入.
基本假设:1)不考虑农民工问题.2)假设历年的数据真实可靠,并从1995年数据开始使用.3)中央扶持政策执行度良好,资金最大限度使用.4)假设2010年上半年经济形势不会发生突变,运行平稳.5)由于前面均以年数据考虑,故先预测2010年整年的失业率,并假设上半年的失业率不会发生太大变化.
本文符号说明:xi(第i年的指标集);yi(第i年的失业率);K(xi,yi)(核函数);Kij(核函数对应的矩阵);
在经济模型中,常用的计量模型在预测失业率时对数据的假设有着很强的依赖性,这可能导致模型设定的偏差.核主成分分析与加权支持向量机方法作为一种新型的研究方法,一定程度上可以克服上述模型中的不足,在很多方面表现出了优于常用的计量模型的功能.
核主成分分析方法是一种非线性特征提取方法,是主成份分析方法的一种非线性推广.该方法通过一个非线性映射将数据从输入空间映射到高维空间,然后在高维空间进行通常的主成份分析,其中的内积运算采用一个核函数来代替.本文采用Guass径向基函数.即:Guass径向基函数[2]:
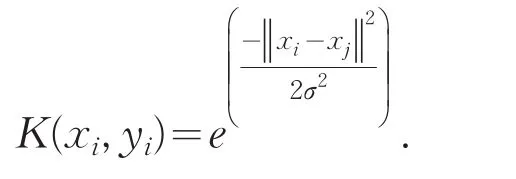
下面介绍核主成分分析加权支持向量的预测方法与步骤.
算法1:
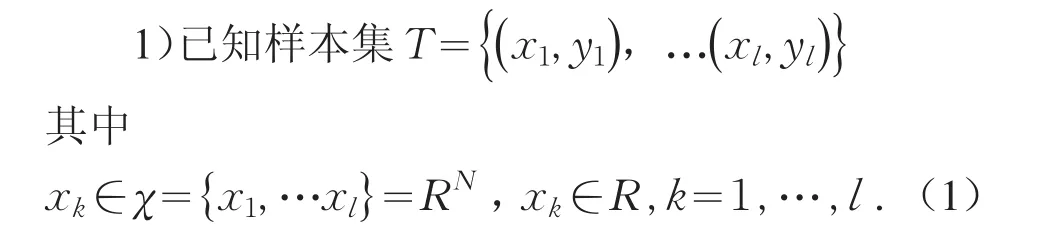
2)选择一个核函数 K=(1+xi·xj)3,利用选择的样本计算l×l的矩阵Kij.

5)根据实际需要,选取部分贡献值比较大的特征值及其对应的特征向量构成新的空间作为低维投影空间(达到降维的目的).
7)取初值:C0=100,ε0=0.01,β=0.01,γ=0.01,由公式:


因此,以本文中选取的22个主要指标,用它们的一期滞后值来拟合失业率,所用数据包括1995年到2007年,则一共可以组成13对样本.接着,这22项指标对应时间构造成22行13列的矩阵,由于各指标原始数据的差异较大,且量纲不一致,在这里对这22个指标按下式进行预处理,使其映射到区间[-1,1]中.
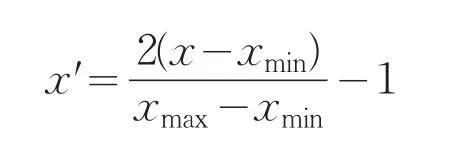
式中x′为与处理后的数据.
用Matlab编程,核主成份分析法选用的核函数为三次多项[4]k(xi,xj)=(1+xi·xj)3,经过计算的特征值、贡献率见表1.
由表1可知最后四个贡献率大,故在此取最后四个主成份进行后面的加权支持向量机,加权支持向量基中选用的核函数为高斯径向基函数核
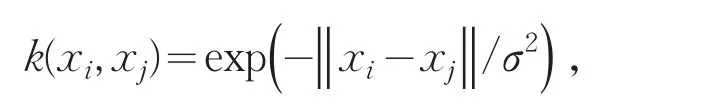
所用参数:测试结果见表2.
由上表可以看出,基于核主成份与加权支持向量机的预测方法拟合及预测都取得了很好的效果,最小的相对误差0.07%(1997年),最大相对误差4.13%(2001).

表1 核主成份计算结果Tab.1 Kernel principal component results
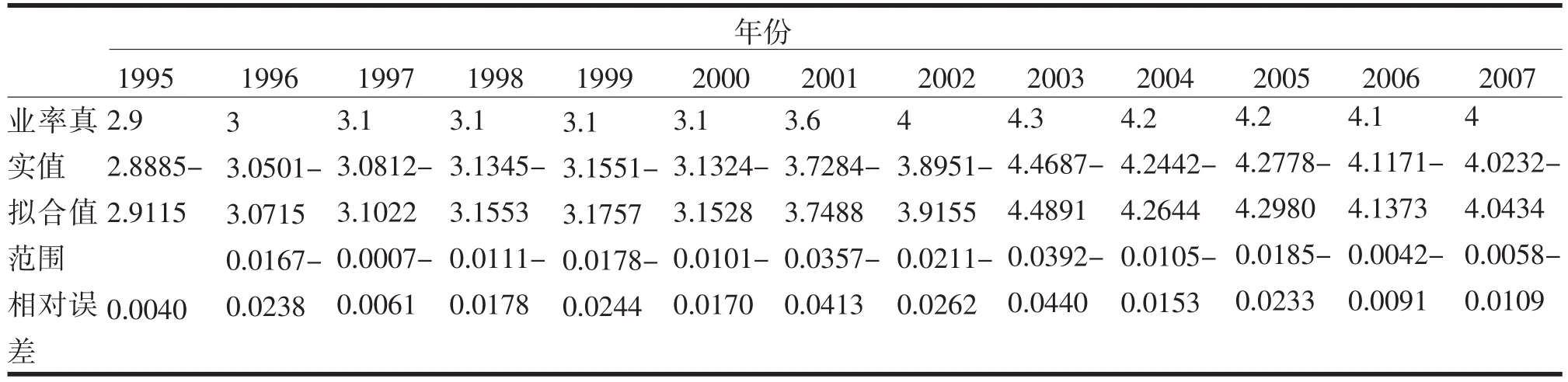
表2 训练及测试结果Tab.2 Training and test results
[1]中国统计年鉴[EB/OL].[2009-09-12].http://www.stats.gov.cn/tjsj/ndsj.
[2]邓乃杨,田英杰.数据挖掘中的新方法——支持向量机[M].北京:科学出版社,2004.
[3]向小东,宋芳.基于核主成分与加权向量机的福建省城镇登记失业率预测[J].系统工程理论与实践,2009,29(1):74-79.
[4]赵东方.数学模型及计算[M].北京:科学出版社,2007:143-145.
[5]韩中庚.数学建模方法及其应用[M].北京:高等教育出版社,2005:57-64.
The Mathematical Model and Prediction in China's Urban Registered Unemployment Rate
YANG Shuaiguo,HU Xiaohua,ZHU Donghe
(College of Mathematics and Statistics,Hainan Normal University,Haikou571158,China)
In this paper,combining with the date of China′s National Bureau of Statistics,we used the Kernel Principal Component Analysis and Kernel Weighted Support Vector Machine method to build the mathematical model.We found 22 key indicators which affect the employment(unemployment).Taking into account of the correlation among these indi⁃cators,we used the Kernel Principal Component method analysis and Weighted Support Vector Machine method to build the model and give the algorithm on how to construct a non-linear prediction function,and also we used the registered ur⁃ban unemployment rate during 1995-2009 to fit the predicted results and obtain high accuracy.
unemployment;Kernel Principal Component;Support Vector Machine
O 29
A
1674-4942(2010)04-0372-03
2010-05-21
毕和平
