基于同义词关系的局部查询扩展
2010-09-07徐建民刘清江
徐建民, 刘清江
(1.天津大学 系统工程研究所 天津300072;2.河北大学数学与计算机学院 河北保定071002)
基于同义词关系的局部查询扩展
徐建民1,2, 刘清江2
(1.天津大学 系统工程研究所 天津300072;2.河北大学数学与计算机学院 河北保定071002)
利用局部分析法,提出一种基于词语之间同义关系的查询扩展方法.该方法利用原始查询术语实现初次查询,然后利用局部分析法得到查询术语在初次查询结果集中的同义词,并实现查询扩展.实验结果表明,该方法能有效提高检索性能.
局部分析法;查询扩展;同义词
0 引言
在信息检索中,用户输入的词语一般是很少的,Wen等[1]通过分析发现,49%的用户查询仅有一个单词,33%的用户查询由2个单词组成,用户平均使用1.4个单词描述他们的查询.如何从这有限的词语中尽可能地挖掘用户所要表达的信息,是信息检索的首要问题.查询扩展是信息检索中很重要的一项技术,它利用计算机语言学、信息学等多种技术,把与原查询相关的词或者与原查询语义相关联的概念添加到初始查询中,得到比原查询更长、更全面的新查询,然后再次检索文档,以改善信息检索的查全率和查准率,从而解决信息检索领域长期困扰用户的“词不匹配”问题,弥补用户查询信息不足的缺陷.
目前常用的查询扩展方法可大致分成2类:全局分析法和局部分析法.其中,局部分析法是应用更为广泛的查询扩展方法,其计算效率和检索性能都要优于全局分析法,但是当初始查询结果集中排在前面的文章与原查询相关度不大时,局部分析法会把大量无关词加入原查询,严重降低查询精度[2].
同义词关系是信息检索领域最重要的术语关系之一.Furnas等[3]研究发现,人们在文章中常常用不同的词语表达相同的事物,2个人使用同一个词描述同一事物的概率不到20%.很多研究表明,合理利用术语关系能够提高信息检索系统的性能[4-5],因此,合理挖掘术语关系并实现查询扩展一直是IR领域研究者所关注的重要问题之一.
本文将查询术语的同义词关系应用于局部分析法,以实现查询扩展.实验证明,这种方法在一定程度上可以避免初次查询排在前面的文档与原查询相关度不大时,把大量无关的词加入查询问题,有效提高信息检索的准确度.
1 相关知识
1.1 局部分析法
局部分析法就是将初次检索得到的与原查询最相关的N篇文章作为扩展词的来源,从中抽取出扩展词,并用来实现查询进行扩展.常见的局部分析法主要是局部反馈法,这种方法在得到初次检索结果后,将初次查询的N前篇文章认为是相关文章,并以此为依据对查询进行扩展.局部分析法在一些实际的信息检索系统中得以使用.Xu等[6]研究表明,多数情形下,局部分析法在计算效率和检索性能上均优于传统的全局分析法.但是,当初次查询后排在前面的文档与原查询相关度不大时,局部分析会把大量无关的词加入查询,从而严重降低查询精度,甚至低于不做扩展优化的情形.
局部上下文分析(Local Context Analysis,LCA)方法是一种改进的局部分析方法[7],它假设初次查询得到的前N篇文档与初始查询最为相关,并以此作为查询扩展词语的来源.然后利用共现频率法从中抽出与初始查询术语最相关的词语作为查询扩展词,实现查询扩展.因为任何术语的相关词必然是和原始术语有关的,因此LCA方法避免了单纯局部分析方法易向原查询加入不相关词的缺点.应用LCA方法的INQUERY系统在TREC标准测试集上取得了良好的实验效果,但是,LCA方法的效果仍然依赖于初次检索的结果.如果初次检索返回的多数文档与原查询无关,该方法仍会将大量无关的词加入到新查询,从而大大降低最终的检索精度.
1.2 信息检索领域的同义词关系
在信息表示和信息检索领域中,同义词的概念并不等同于语言学和日常生活中的同义词,它不考虑感情色彩和语气,主要指在信息检索中能够相互替换、表达相同或相近概念的词汇.用于信息检索的同义词主要分为以下几类:①等价的词和等义的词、词组,即意义完全相等的词.主要是指一些语义等价的词以及学名与俗名、全称与简称、新称与旧称、产品的代号与型号等,如电脑—计算机、自行车—脚踏车、玉米—苞谷等.②准同义词和准同义词词组,即意义基本相同的词和词组.也就是说2个词或词组含有的义项基本相同,就可以把它们看作同义词,如边疆—边境、住房—住宅等.③某些过于专指的下位词,如球类运动和门球、毽球、网球等.④极少数的反义词.这类词描述相同的主题,但所包含的概念互不相容,如平滑度—粗糙度等.
同义词一般可以利用同义词词典得到,同义词之间的相近程度可以用词语相似度表示.词语相似度是用来衡量2个词语在查询中或文档中意义相符程度的度量,是词语间语义关系的数量化.一般地,词语相似度是一个数值,取值范围为[0,1][8].
2 基于同义词关系的局部查询扩展
2.1 基本过程
设待检索的语料库为C,初始查询Q={t1,t2,…,tm},基于术语关系的局部查询扩展过程如下:
1)利用原始查询术语实现初步查询,获得初始查询结果集D;
2)选取初始结果集D中的前n篇文档作为扩展词来源文档集合S={d1,d2,…,dn};
3)在集合S中查找每一个初始查询术语ti的同义词,得到集合Ti={ti1,…,tik},并从中选取合适的子集,作为Q的同义扩展词;
4)实现扩展查询.
2.2 同义扩展词的选取
初始查询术语的同义词可以通过同义词词典得到,但从同义词词典中查找的同义词并不是每个词都是可用的,需要一个标准来判断哪些词适合做原查询的同义词.考虑到词语相似度反映了词语之间相似的程度,某同义词在集合S中出现的次数能影响其权重,故本文选用这2个指标作为判断标准.
词语相似度是一个主观性相当强的概念,脱离具体的应用去谈词语相似度很难得到一个统一的定义,只有在具体的应用中词语相似度的含义才比较明确.例如,文献[9]对用于机器翻译的词语相似度定义为:2个词语在不同的上下文中可以互相替换使用而不改变文本的句法语义结构的程度.在信息检索中,词语相似度主要反映的是词语的语义相似性,也就是词语间语义关系的数量化.
目前词语相似度有2类常见的计算方法:一种是根据某种世界知识来计算;一种是利用大规模的语料库进行统计.基于世界知识的方法简单有效,无需用语料库进行训练,比较直观,易于理解,但这种方法得到的结果受人的主观意识影响较大,有时并不能准确反映客观事实;基于语料库的方法比较客观,综合反映了词语在句法、语义、语用等方面的相似性和差异,但这种方法比较依赖于训练所用的语料库,受资料稀疏和资料噪声的干扰较大,而且计算量大,计算方法复杂.
基于《How net》的相似度计算方法充分利用了《How net》中对每个词语描述时的语义信息,得到的结果与人的直觉比较符合,词语相似度值刻画得也比较细致,但是这种方法主要是基于机器翻译的.基于同义词词典的方法比较简单,符合信息检索要求,但这种方法得到的数值比较粗糙.本文采用综合的方法,即首先用《同义词词林(扩展版)》来获取每个初始查询术语的同义词集合,以保证同义词的不失真,然后利用《How net》计算这些同义词间的相似度,得到较为精确的数值.初始查询术语同义扩展词的获得过程如下:已知利用《同义词词林(扩展版)》得到初始查询术语ti的同义词集合为Ti={ti1,…,tik},则利用《How net》计算初始查询术语ti和集合Ti中每一个tij的词语相似度Sim(ti,tij).相似度大于阈值α的视为原查询的同义词,小于阈值α的直接删除,从而得到集合T′i={t′i1,…,t′ic},T′i为选取的术语ti的同义扩展词的集合.
2.3 扩展词加权
不同的扩展词因为其与原查询词语义距离的远近不同而具有不同的重要性,查询扩展的另一个问题就是如何对扩展后的新查询Qnew中的词语进行权重的分配.
1)初始查询术语的加权
直接采用Rocchio公式[10]来计算Qnew中初始查询术语ti的权重Weight(ti|Qnew)为
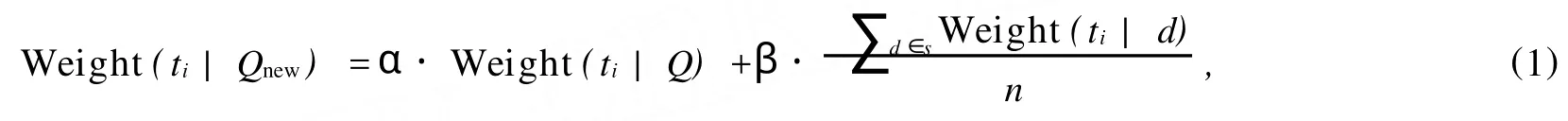
其中,Weight(ti/Q)为查询词ti在初始查询Q中的权重,通常直接使用ti在Q中的频度来表示;Weight(ti/d)为查询词ti在文档d中的权重,计算方法与所采用的检索模型具有一定的关系;n为局部文档集中的文档个数;α和β为2个大于0的可调参数.
2)同义扩展词的加权
同义扩展词的权重取决于2个因素:其一,是该同义词和初始查询术语之间的词语相似度,词语相似度越大,该同义词在新查询中的权重越大;其二,是该同义词在集合中出现的次数,该同义词在集合S中出现的次数越多,该同义词在新查询中的权重越大.基于此,计算同义扩展词在新查询中的权重为

其中,调节系数γ要保证同义扩展词的权重不能大于相应初始查询术语的权重.
3 实验与比较
实验所用数据来源于一个小型中文信息检索测试集[11],该测试集包括1 705篇文档,共构造6个查询.针对这6个查询分别进行了3组实验:未扩展的查询; LCA法;本文方法.
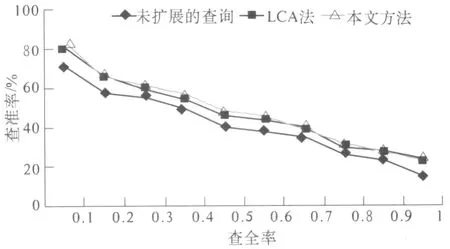
图1 3组实验性能比较Fig.1 Experimental perfo rmance comparison of the three groups
图1给出了3组实验在查全率为0.1~1时相应的查准率.可以看出,本文方法与未进行查询扩展相比检索性能有明显提高,跟LCA法相比效果却并不明显.一个主要原因是本文所用测试集主要是关于计算机方面的,而在《同义词词林(扩展版)》中对这方面词语的同义词收录较少.但是本文方法是基于语义词典的扩展查询,即使出现初次查询排在前面的文档与原查询相关度不大这种情况时,也不会将与原查询无关的词语加入到原查询中,所以本文方法要比LCA法具有更好的稳定性.
[1] Wen Jirong,Nie Jianyun,Zhang Hongjiang.Clustering user queriesof a search engine[C]//Proceedingsof the 10th International Wo rld Wide Web Conference.New York:ACM Press,2001.
[2] 桑艳艳,刘培刚,李勇.基于语义计算的查询扩展优化研究[J].情报学报,2007,26(5):704-710.
[3] Furnas GW,Landauer T K,Gomez L M,et al.The vocabulary p roblem in human-system communication[J].Commun ACM,1987,30(11):964-971.
[4] de Campos L M,Fernández-Luna JM,Huete J F.The BNR model:foundations and perfo rmance of a Bayesian networkbased retrievalmodel[J].International Journal of App roximate Reasoning,2003,34(3):265-285.
[5] Xu Jianmin,Tang Wansheng,Ning Yufu.A belief network based retrievalmodelw ith two term layers[C]//Proceedingsof International Conference on Machine Learning and Cybernetics.Dalian,2006.
[6] Xu J X,Croft W B.Query expansion using local and global document analysis[C]//Proceedingsof the 19th Annual International SIGIR Conference on Research and Development in Information Retrieva1.New York:ACM Press,1996.
[7] Xu J X,CroftW B.Imp roving the effectivenessof information retrievalw ith local context analysis[J].ACM Transanctions on Information Systems,2000,18(1):79-112.
[8] 徐建民,陈振亚,白艳霞.利用查询术语同义词关系扩展信念网络检索模型[J].情报学报,2008,27(3):363-368.
[9] 刘群,李素建.基于《知网》的词汇语义相似度计算[J].计算语言学及中文信息处理,2002,7(2):59-76.
[10] Rocchio J J.Relevance feedback in info rmation retrieval[M]//The Smart Retrieval System-experiments in Automatic Document Processing.London:Prentice Hall,1971.
[11] 徐建民,王平.小型中文信息检索测试集的构建与分析[J].情报杂志,2009(1):28-30.
Local Query Expansion Based on Synonyms
XU Jian-min1,2, L IU Qing-jiang2
(1.Institute of Systems Engineering,Tianjin University,Tianjin 300072,China; 2.College of M athem atics and Com puter,Hebei University,Baoding 071002,China)
Based on synonymous relationship,a local query expansion method is p resented w hich uses o riginal query term s to imp lement first query and gets a result document set.Synonym s of original query term s are got f rom this set,and then to expand user query.Experimental results show that the performance of the expanded model is better than basic models.
local analysismethod;query expansion;synonym
TP 391
A
1671-6841(2010)01-0045-04
2009-11-12
国家博士后科学基金资助项目,编号20070420700.
徐建民(1966-),男,教授,博士生导师,主要从事信息检索及不确定信息处理研究;通讯联系人:刘清江(1982-),男,硕士研究生,主要从事信息检索研究,E-mail:yy.csi@hbu.edu.cn.
