搜索引擎自动性能评估函数的研究
2010-09-07王明文吴世勇罗文兵
王明文, 吴世勇, 罗文兵, 熊 超
(江西师范大学计算机信息工程学院 江西南昌330022)
搜索引擎自动性能评估函数的研究
王明文, 吴世勇, 罗文兵, 熊 超
(江西师范大学计算机信息工程学院 江西南昌330022)
基于聚类分析的搜索引擎自动性能评价方法能自动计算信息类查询的覆盖范围,并根据其覆盖范围对检索结果进行聚类,通过评估函数实现检索性能的自动评价.对如何利用类间距和类内距2个指标来定义合适的评估函数进行了分析,提高了自动性能评价的准确性.
信息检索;性能评价;评估函数
0 引言
当前搜索引擎涉及到的索引页面数量巨大,利用手工标注答案的方式进行网络信息检索系统的评价是不现实的,因此提高搜索引擎性能评价的自动化水平是当前检索系统评价研究中的热点[1].近年来提出了一些自动进行搜索引擎性能评估的方案,Kwok和Vinay等人提出了对检索结果同质性进行分析的方法, Cronen-Tow nsend等提出了对检索结果突显性分析的Clarity Sco re方法,对利用检索结果质量的好坏程度来实现检索系统的自动性能评价提供了思路[2-6].
基于聚类分析的搜索引擎自动性能评价方法,是先通过计算查询的覆盖度,再应用聚类方法分析搜索引擎检索返回文档的质量,用类间距和类内距等聚类指标来定义检索性能评估函数,从而实现检索系统的自动性能评价.本文在研究搜索引擎自动性能评价方法的基础上,对评估函数的设计及参数调整进行了深入分析,进一步提高了自动性能评价的准确性.
1 自动性能评价方法
本文的搜索引擎自动性能评价方法是针对信息类的查询,搜索引擎自动性能评价框架见图1.考虑到信息类查询的主题一般可以划分为几个子主题,可以根据查询子主题的个数确定返回文档聚类的数目,即查询子主题的个数越多,相应的聚类数目也就越多.确定聚类数目后对检索返回文档进行聚类,如果一个类中的文档间比较相似、紧密程度较高,我们就认为这个类中的文档与查询中相应的一个查询子主题比较相关;如果几个类中心的距离比较大,侧面反映查询子主题的内聚性比较好,不相关文档(噪声因子)较少.即固定聚类数量后,通过比较类内距和类间距等聚类指标对检索性能进行评价,如果类内距越小、类间距越大则检索返回文档的质量越好.

图1 搜索引擎自动性能评价框架Fig.1 Automatic search engine performance evaluation framework
首先,我们对搜狗实验室提供的用户查询日志(SogouQ)进行查询类别分析,使用文[7]中的方法提取出查询日志中的信息类查询,随后计算查询覆盖度[8],同时使用不同的搜索引擎对提取出来的查询进行检索,将检索返回的结果网页抓取回来并进行预处理,最后结合查询的覆盖度对检索结果进行聚类分析[9],通过比较类内距和类间距等聚类指标对检索性能进行评价.
2 评价函数
2.1 评价指标
类间距是所有聚类簇中心之间距离的平均值,可以表示为Inter_dist=,其中,n是聚类数目,ci,cj分别表示聚类Ci和Cj的类中心,/ci,cj/表示2个类中心之间的距离.类间距表示类之间的区分程度,类间距越大,检索结果中的不相关文档(噪声因子)越少,说明搜索引擎的检索性能越好.
类内距是所有聚类簇中的元素之间距离的平均值,表示为Intra_dist=,其中,n是聚类数目,mi表示聚类Ci中元素的个数,ci表示聚类Ci的类中心,χij表示聚类Ci中的第j个元素, /χij,ci/为聚类Ci中元素与类中心的距离.类内距表示类内的凝聚程度,类内距越小,检索结果中的相关文档就越多,反映了搜索引擎的检索性能越好.
2.2 评价函数
可以用类间距和类内距2个指标来估计搜索引擎的检索性能,可以用Quality表示检索结果的质量,则Quality=f(Inter_dist,Intra_dist).函数f可以有不同的定义方式,本文给出了3种基本的函数来估计Quality,分别是:

其中,α是可调参数,用来平衡类间距和类内距2个评价指标在评价函数中的权重,实验中我们将通过对α取不同的权值来考查2个评价指标的重要度.
3 实验结果及分析
3.1 实验说明
本文选取了3个搜索引擎作为性能评价的对象,分别是Google,Baidu和Bing.实验数据全部采集自2009年7月的互联网.首先我们从搜狗实验室提供的用户查询日志(SogouQ)中提取出100个查询频率较高的信息类查询并计算其查询覆盖度,分别用3个搜索引擎进行检索,利用一些网页抓取工具分别将搜索引擎返回的前600个检索结果抓取下来.经数据预处理后,对3组检索结果分别采用K-M ean算法进行聚类分析.
为说明自动性能评价方法是可行的,我们也进行了基于人工标注的评价.选择每个搜索引擎对每个查询的前20个结果,以及21~100中5%的结果来进行人工标注答案,采用Pooling的方法构造结果池,评估指标使用P@10.计算100个查询检索准确度的平均值,Google平均值为0.677,Baidu为0.520,Bing为0.548.人工评价结果是Google检索结果准确度总体上要比Baidu和Bing的检索结果准确度高,Bing检索结果准确度和Baidu检索结果准确度比较接近.
3.2 评估函数比较分析
通过3个评估函数进行自动评价的结果基本相同,Google检索结果质量总体上都比Baidu和Bing的检索结果质量好,Baidu和Bing的检索结果质量相差不大,与人工评价结果基本一致.为进一步比较3个评估函数的评价结果和人工评价方法的一致性,我们通过一致性检验来分析.设xg(i),xbd(i),xb(i)分别为Google,Baidu,Bing第i个查询的自动评分,yg(i),ybd(i),yb(i)分别为Google,Baidu,Bing第i个查询的人工评分,然后分别对3组变量对{xg(i)-xbd(i),yg(i)-ybd(i)},{xg(i)-xb(i),yg(i)-yb(i)},{xbd(i)-xb(i),ybd(i)-yb(i)}进行相关分析,表1中列出了3个不同评价函数的评价结果与人工评价结果的Pearson相关系数.
从表1中可以看到,3个评估函数的评价结果与人工评价结果的Pearson相关系数都大于0.700,表明2种评价方法的评价结果是基本一致的且有统计学意义.同时,我们发现函数f2的评价结果比函数f1和f3的评价结果与人工评价结果的一致性相关系数更高,说明函数f2能更好地评价搜索引擎的检索性能.
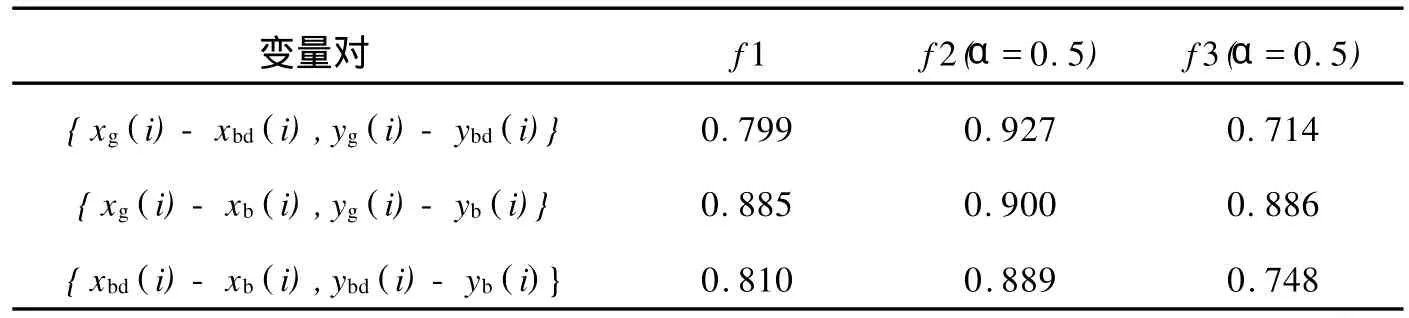
表1 3种不同函数的评价结果与人工评价结果的相关系数Tab.1 Co rrelation coefficient of 3 evaluation functions
为分析类间距和类内距2个评价指标在评价函数中所占的重要程度,对函数f2和f3中的α分别取不同值得到自动评价结果,再分别与人工评价结果进行一致性检验,同样对前文中的3组变量对进行相关分析,得到3组变量对的Pearson相关系数见表2、表3.

表2 函数f2的评价结果与人工评价结果的相关系数Tab.2 Co rrelation coefficient of evaluation functions f2

表3 函数f3的评价结果与人工评价结果的相关系数Tab.3 Co rrelation coefficient of evaluation functions f3
从表2和表3中可以看出,α取0.7时,评估函数f2得到的评价结果与人工评价结果的一致性相关系数达到最大值,α取0.9时,评估函数f3得到的评价结果与人工评价结果的一致性相关系数达到最大值,说明2个评价指标中类间距在评估函数中所占的权重应该比类内距大一些.实验结果表明,信息类查询的评价过程中应该更注重考查检索结果的全面性,因为用户在进行信息类查询时是想尽可能获得更多与该查询相关的检索结果,而类间距反映的正是查询相关主题之间的联系,类内距反映的是一个主题中相关文档的联系.
4 结论
为改进搜索引擎自动性能评价的准确性,本文对自动性能评价中的评估函数进行了研究.实验结果表明,自动性能评价结果与人工标注的评价结果是基本一致的,2个评价指标中类间距在评估函数中所占的权重应该比类内距大一些,参数α为0.8左右的评估函数是较合适的.
参考文献:
[1] Saracevic T.Evaluation of evaluation in info rmation retrieval[C]//Fox E A,Ingwersen P,Fidel R.Proceedings of the 18th Annual international ACM SIGIR Conf on Research and Development in Info rmation Retrieval(SIGIR′95).New York:ACM Press,1995:138-146.
[2] 陶跃华,鲁晓南,张玉琢.一种瘦服务器—胖客户分布式搜索引擎的设计[J].广西师范大学学报:自然科学版,2007,25 (2):74-77.
[3] 李智超,熊风,富羽鹏,等.分布式大规模文本检索系统[J].广西师范大学学报:自然科学版,2007,25(2):178-181.
[4] Joachims T.Evaluating retrieval performance using clickthrough data[C]//Proceedingsof the ACM SIGIRWo rkshop on Mathematical/Fo rmal Methods in InformationRetrieval.Finland:Tampere,2003:79-96.
[5] Vinay V,Cox IJ,M ilic FN,et al.On ranking the effectivenessof searches[C]//Proceedingsof the 29th Annual International ACM SIGIR Conf on Research and Development in Information Retrieval.New York:ACM Press,2006: 398-404.
[6] Zhou Y,Croft W B.Ranking robustness:a novel framework to p redict query performance[C]//Proc of the 15th ACM International Conf on Information and Know ledge Management.A rlington:ACM Press,2006:567-574.
[7] Liu Y Q,Zhang M,Ru L Y,et al.Automatic query type identification based on click through info rmation[C]//Proc of the 3rd A sia Info rmation Retrieval Symp,A IRS 2006.Berlin:Sp ringer-Verlag,2006:593-600.
[8] Lang H,Wang B,Jones G,et al.Query perfo rmance p rediction for info rmation retrieval based on covering topic score [J].Journal of Computer Science and Technology,2008,23(4):590-601.
[9] 沙芸,张国英.基于词间语义相关度的搜索结果聚类算法[J].郑州大学学报:理学版,2009,41(1):73-76.
Research on Search Engine Automatic Performance Evaluation Function
WANG M ing-wen, WU Shi-yong, LUO Wen-bin, XIONG Chao
(School of Com puter Information and Engineering,Jiangxi Normal University,Nanchang 330022,China)
Search engine automatic performance evaluation method based on clustering analysis can compute the coverage sco re of info rmational type query,and cluster search results by the coverage sco re,evaluate the retrieval perfo rmance by evaluation function.The definition of evaluation function is analyzed using cluster cohesion and cluster separation.Evaluation results of search performance are imp roved.
info rmation retrieval;perfo rmance evaluation;evaluation function
TP 391
A
1671-6841(2010)01-0074-04
2009-10-25
国家自然科学基金资助项目,编号60963014,60663307;江西省自然科学基金资助项目,编号2007GZS0186;江西省科技攻关项目,编号2006-184;江西省教育厅科技课题项目,编号2007-129.
王明文(1964-),男,教授,博士生导师,主要从事信息检索、数据挖掘、并行计算等研究,E-mail:mwwang@jxnu.edu.cn.
