Web信息抽取与语义检索框架
2010-09-07师雪霖程文涛
师雪霖, 程文涛
(北京化工大学信息科学与技术学院 北京100029)
Web信息抽取与语义检索框架
师雪霖, 程文涛
(北京化工大学信息科学与技术学院 北京100029)
提出了一种Web信息抽取与语义检索框架,采用定制本体模型,针对Web网页特点设计了抽取与语义标引策略,并在检索过程中引入语义推理机制,从而改善了信息检索的效果.最后介绍了基于Jena实现的该框架的原型系统.
信息抽取;本体;语义检索;Jena
0 引言
Web是在H TML的基础上构建起来的,数据以一种半结构化的形式被组织起来.随着Internet的迅速发展,Web已经发展成庞大的异构资源空间,对其检索和处理工作变得越来越繁重.网络搜索引擎技术虽然日趋成熟,但其搜索方式仍旧是基于关键词,大量的信息分类和处理工作还需要人工进行.造成上述问题的根本原因是Web文档缺乏机器可处理的标识,不能进行语义检索.
文[1]提出了语义网的概念,旨在赋予Web一个全新的体系结构和运作方式.语义网以及相关理论的提出为信息检索技术的发展提供了强有力的工具[2].但是,如何实现对这些海量、半结构化、缺乏语义标识的Web数据的抽取和语义检索仍然缺少有效的解决方法,本文提出了一种Web信息抽取与语义检索框架(Framework of Web Extraction&Semantic Search,FWESS),采用定制本体模型,针对Web网页特点设计了抽取与语义标引策略,并在检索过程中引入语义推理机制,从而改善了信息检索的效果.
1 本体模型与描述
为了实现语义检索功能,首先需要进行Web数据抽取和语义标识,在其中增加计算机可理解的语义信息,这就需要定义一些计算机可理解和推理的概念与规则,即设计相应的语义数据模型——本体.为此设计了一种简化通用本体模型,并以学术资源为对象,具体化该通用模型形成领域本体.
1.1 简化通用本体模型
本体常被用来作为语义模型,被认为是进行语义推理的基础,典型的本体具有一个完善的分类体系和一系列推理规则,借助本体的推理规则,可以使语义网应用系统具备更强的语义推理能力.一般认为本体是一个五元组:O∶=(C,R,F,A,I),其中C,R,F,A和I分别是本体中概念、关系、函数、公理和实例的集合,也可以称为5个基本的建模原语[3].
本体模型较为复杂,建立某一领域本体时,往往需要领域专家对概念、关系等进行描述和抽象.Internet上的各类Web资源内容庞杂,涉及众多领域,考虑到FW ESS系统的扩展性,借鉴以往工作基础[4],设计了一种较为简单的通用本体模型,只包含基本的语义关系,在具体实现时,根据领域知识特征,具体化概念与相应属性即可.该简化通用本体模型为O∶=(C,R,A,V,σA),其中,①集合C,R,A,V分别表示概念、关系、属性和数值;②集合R包含4个元素:part-of(表达概念之间部分与整体的关系),kind-of(表达概念之间的继承关系),instance-of(表达概念的实例与概念之间的关系),attribute-of(表达某个概念是另一个概念的属性);③函数σA:A→C称为属性签名;④函数σR:R→C2称为关系签名.
当FWESS针对某个领域数据工作时,只需要具体化集合C和A,定义好概念与属性之间的映射关系σA,以及概念之间的映射关系即可.
1.2 定制领域本体
以学术文献为对象,定制了本体模型,形成学术文献领域本体.首先定义概念:书籍、论文和作者,即集合C中包含3个元素,C={book,paper,author}.其次定义属性和属性签名函数,即确定集合A中的元素,然后限定每个属性和概念之间的映射关系σA.最后定义关系签名,即各个概念之间的关系函数σR.在简化通用本体模型中,只考虑4种最基本的关系.针对学术文献领域本体,概念之间涉及到2种关系:part-of和attribute-of,例如autho r和book,autho r和paper之间存在attribute-of关系,paper和book之间存在part-of关系.
定制了学术领域本体后,在模型描述上借鉴了RDF(Resource Descrip tion Framework)的结构.RDF的基本结构是对象-属性-值三元组,对象O具有属性A,属性值为V,通常记为A(O,V).很适合用图表示这种三元组:对象O和值V(即RDF资源)用节点表示,属性A为连接两节点的边,即[O]-A-[V].因为通常一个对象也可以作为其他对象的值,所以采用图来表示更为实用明了.图1给出了对图书、科技文献、作者3个相关资源的本体描述实例图.
2 Web信息抽取与语义检索框架
基于上述本体模型,设计了Web信息抽取与语义检索框架FW ESS,以实现对Web数据的语义加工和检索.它针对书籍、文献、作者以及其他相关资源进行抽取、过滤和语义化转换,建立全局性的语义知识库,满足用户对资源的查询要求.FWESS系统框架见图2.

图1 资源本体描述实例图Fig.1 Descrip tion instance of resource ontology
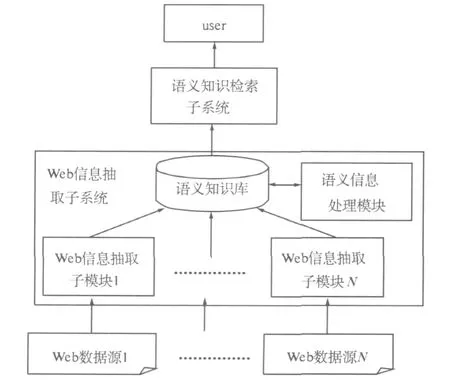
图2 FWESS系统框架图Fig.2 A rchitecture of FW ESS
2.1 Web信息抽取
信息抽取的目的就是要让有用的信息以统一的形式集成在一起.Web信息抽取子系统对网页中的各种结构数据进行抽取、筛选,并做语义化的处理,将生成的语义数据存入知识库.图3给出了Web信息抽取子系统的工作模式.
Web信息抽取子系统由Web信息抽取模块和语义信息处理模块组成.Web信息抽取模块负责从异构Web数据源获取资源,相当于数据源包装器(w rapper).可预先根据数据源的特点以及要处理成的领域本体模型建立抽取规则,Web信息抽取模块依据规则抓取数据、抽取语义信息,将对象数据(即资源本身,如文本文档、pdf文档、图片等)和抽取的语义信息存入语义知识库.
Web信息抽取模块包括3个部分:规则库、规则执行模块和数据转换模块.规则库采用XML格式记录了Web数据源的URL、抽取识别标签,在目前研究中使用人工方式为Web数据源建立抽取规则.抽取过程中,首先通过URL连接某一数据源抓取信息.规则执行模块根据对应的抽取规则处理抓取的Web页面,抽取出相应标签所包含的信息,并把该信息输入到数据转换模块.数据转换模块将被抽取出来的信息转换成RDF三元组格式,将其存储在语义知识库中.语义信息处理模块负责更新语义知识库,并对其进行定期整理,建立新语义信息与旧信息的语义关联.
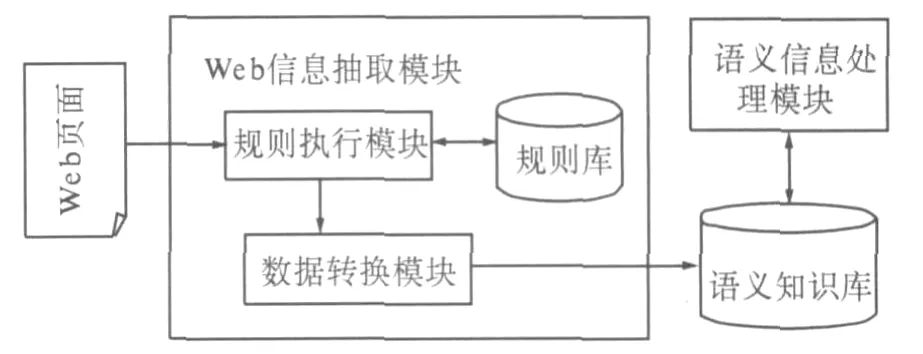
图3 Web信息抽取子系统Fig.3 Web extraction subsystem
2.2 语义知识检索
语义知识检索子系统负责处理用户的查询请求,并从语义知识库中检索相关的信息,将包含语义联系的结果返回给用户.图4为语义知识检索子系统的框架图.
语义知识检索子系统主要包括用户接口、检索模块和学习模块.用户接口接受和提交用户的查询请求,并返回语义化数据.检索模块根据用户模块的需求,在语义知识库中检索相应的记录,返回给用户接口模块.为了提高系统性能及协助细化用户的检索请求,增加了个性化服务功能.学习模块记录用户每次的检索情况以及用户对检索结果的评价,总结用户查询习惯,建立用户个性化信息文件.当用户下一次检索时,可以根据用户个性化信息,引导用户将普通的关键词检索请求细化成针对某项语义属性或语义联系的检索,从而提高检索的准确率.
3 基于Jena的框架实现
使用Java构建了一个FWESS原型系统,其中RDF数据持久化、语义检索及推理功能均使用Jena实现.Jena是HP实验室开发的一种用来构建semantic Web的Java API框架,它提供了操作RDF,RDFS和OWL的开发环境[5-6].图5给出了基于Jena实现的FW ESS原型系统.
原型系统实现了Web抽取、语义加工和检索功能,目前只定制了学术资源本体模型,因此数据源选择了某图书馆开放检索系统(S1)以及某IT专业咨询网站(S2).S1抽取的信息相当于资源的元数据,FWESS原型系统对应设计的抽取规则为元数据到本体属性的映射关系.S2获取的原始Web文档作为资源的对象数据,再从中抽取相关语义属性.目前很多网站为了实现其推广目标,便于被搜索引擎索引,都增加了很多语义标签,即标签,这为语义属性的抽取带来了便利.FWESS原型系统即根据S2的语义标签特点设计了相应的语义属性抽取规则.
抽取的对象数据和语义信息存入语义知识库中,以便为用户提供语义层面的检索服务.语义知识库的物理存储使用了关系数据库,利用Jena提供的数据库引擎,可以将表示本体的三元组存储在数据表中,也可以根据需要从数据表中检索出来创建成三元组结构.

图4 语义知识检索子系统Fig.4 Semantic know ledge search subsystem

图5 基于Jena实现的FW ESS原型系统Fig.5 FWESS p rototype implemented based on Jena
语义检索的关键是概念之间的推理,Jena提供了基于规则的推理机,利用Jena的推理功能,为用户提供了语义层面的检索.与传统的网页检索工具相比,提高了检索的准确率,而且不仅提供单纯文本信息,还为用户提供了资源的语义结构和层次信息.
4 结论
本文针对目前Internet上Web数据资源的特点,提出了一种Web信息抽取与语义检索框架FWESS.为了实现对Web数据的语义处理,首先设计了一种简化通用本体模型,据此模型定制了学术资源领域本体. FWESS从Web数据源抽取信息并进行语义标识,生成学术资源本体数据,存放在语义知识库中;再运用语义推理实现对语义知识库的检索,从而为用户提供语义检索结果.最后,介绍了基于Jena实现的FW ESS原型系统.
FWESS具有如下特点:设计了简化通用本体模型,可以依据对不同领域知识的处理需要,定制成领域本体,保证了系统的可扩展性;可以根据Web页面的不同结构制定抽取规则,实现对Web数据的语义加工,实现了自动语义抽取;在检索过程中引入语义推理机制,提高了系统检索的准确率,为用户提供了更多的语义关联信息.在下一步研究工作中,将对本体模型进行细化,建立完备而合理的概念层次关系,从而给用户提供按语义层次化检索功能.
[1] Shadbolt N,Berners-Lee T,Hall W.The semantic Web revisited[J].IEEE Intelligent System s,2006,21(3):96-101.
[2] Benjamins V R,Contreras J,Co rcho O,et al.Six challenges fo r the semantic Web[EB/OL].[2009-11-01].http:// www.cs.man.ac.uk/~ocorcho/documents/KRR2002.
[3] Fensel D.The semantic Web and its languages[J].Intelligent Systems and Their App lications,2000,15(6):67-73.
[4] 师雪霖,赵英.移动主体异构资源互操作框架[J].计算机工程与应用,2009,45(15):150-153.
[5] Reynolds D.Jena inference support[EB/OL].[2009-11-01].http://jena.sourceforge.net/inference.
[6] 丁晟春,顾德访.Jena在实现基于ontology的语义检索中的应用研究[J].现代图书情报技术,2005(10):5-9.
A Framework of Web Data Extraction and Semantic Search
SH IXue-lin, CHENGWen-tao
(School of Inform ation Science and Technology, Beijing University of Chem ical Technology,Beijing 100029,China)
A framework of Web extraction and semantic search is brought out to imp rove efficiency of information retrieval.Based on a customized ontology model,semantic extraction policies for heterogeneous data sources and app lied semantic inferencemechanism are designed.A p rototype system constructed w ith Jena is also described.
info rmation extraction;ontology;semantic search;Jena
TP 393
A
1671-6841(2010)01-0029-04
2009-12-16
北京化工大学青年教师基金资助项目,编号QN0732.
师雪霖(1977-),女,讲师,博士,主要从事Web挖掘及网格计算研究,E-mail:shixl@mail.buct.edu.cn;通讯联系人:程文涛(1981-),男,硕士研究生,主要从事Web语义研究,E-mail:2008000728@grad.buct.edu.cn.
