从树库的实践看句本位和中心词分析法的生命力
2010-09-06黄昌宁李玉梅微软亚洲研究院北京0090清华大学北京00084
黄昌宁,李玉梅(.微软亚洲研究院,北京 0090;.清华大学,北京 00084)
从树库的实践看句本位和中心词分析法的生命力
黄昌宁1,李玉梅2
(1.微软亚洲研究院,北京 100190;2.清华大学,北京 100084)
树库是一种带句法标注的语料库,它记录着真实文本中每个句子的句法分析结果——句法树。上世纪90年代,自然语言的自动句法分析再次成为国际计算语言学界关注的焦点,一个重要原因是美国宾州树库PTB的建成。根据树库自动归纳出来的概率型上下文无关语法,使英语的句法分析器在性能上显著超越了先前基于规则和合一运算的句法分析器。世界上为各种自然语言构建的树库,不论是短语结构树库还是依存结构树库,都以句子为基本的描述单位。依存语法是一种词例化语法,它不采用短语结构的语法概念,而直接描写句子中词与词之间的依存关系,即认为句子中任何两个具有依存关系的词中必有一个是中心词(支配词),而另一个是被支配词。因此,依存语法直接体现了一种语言的句法层面和语义层面之间的天然联系。这充分说明,黎锦熙先生在《新著国语文法》中倡导的句本位语法体系和中心词分析法具有鲜活的生命力。它们不仅在我国解放前后的中学语文教学中数十年长盛不衰,而且至今仍在指导着树库的建设和应用。
句本位;中心词分析法;树库;自动句法分析
一、树库和语言学理论
黎锦熙先生在《新著国语文法》①黎锦熙:《新著国语文法》,北京:商务印书馆,1998年版。中倡导的句本位语法体系和中心词分析法具有鲜活的生命力。它们不仅在我国解放前后的中学语文教学中数十年长盛不衰,而且至今仍在指导着树库的建设和应用。
那么什么是树库呢?树库是一种带句法标注的语料库,它记录着真实文本中每个句子的句法分析结果——句法树(见图1)。不论是以短语结构为表示形式的短语结构树库,还是以依存关系为表示形式的依存树库,都把句子作为树库存储的基本单位,也是句法描述的基本单位②在文本文件(text)中,每个句子占据一行,行与行之间用回车符分割,行内不得插入回车符。。树库中的每一棵句法树好比是指定语言的一个语法样本,把这样的大量样本收集到一起,就可以勾画出这种语言整体的语法现象和规律。在“句本位”、“词组本位”、“小句本位”等诸多的本位说中,“本位”的意思是试图把某个语言单位作为语法分析的基础,其语言学假设是:“把这个单位内部的成分和结构分析清楚了,整个语法系统也就清楚了”③胡明扬:《现代汉语的开创性著作——〈新著国语文法〉的再认识和再评价》,《语言科学》2002年1(1)期,第92-101页。。如果这样来理解“本位”的意思,那么正是黎锦熙先生的句本位思想,而不是别的什么“本位”,真正体现了树库构建的真谛。
上个世纪90年代,自动句法分析再次成为国际计算语言学界关注的焦点,一个重要原因是:美国宾州大学在华尔街日报(WSJ)的真实文本上加工成规模达百万词次的宾州树库④M.P.Marcus et al.Building a large annotated co rpusof English:The Penn Treebank.Computational Linguistics, 19(2),1993.313-330.http://www.cis.upenn.edu/~treebank/(Penn Tree-bank,简称PTB)。英文PTB-3的训练集共有39,727句,938,167词次,平均句长24.4词次;宾州中文树库(又称PCTB 6.0)的训练集含22,277句,609,060词次,平均句长27.3词次。简而言之,树库的意义有三:
(1)人工编制的语法规则一般都以词性标记(终结符)和短语标记(非终结符)作为规则的书写符号,很难细化到词例化(lexicalization①在语言学中,lexicalization被译作“词汇化”。为避免术语上的混淆,这里译作“词例化”,特指句子中的每个词语(word)将同它的词性一起作为终结符进入句法规则。)的程度。然而在树库中,句子里的词语和它们的词性一样都是可观察的,因此根据树库自动归纳出来的概率型上下文无关语法(Probabilistic Context Free Grammar,简称PCFG),其规则既可以是词例化的,也可以是非词例化的。树库不仅可以用来估计短语规则的概率,而且规则的词例化使句法知识的颗粒度极大地细化了。
(2)由于规则的约束条件容易出现相互冲突,几百条人工编制的短语规则便已经很难管理了。这样的规则集对真实文本的覆盖面窄,往往满足不了实际应有的需求。而从PTB英文树库中归纳出来的非词例化短语规则就超过17,000条,极大地提高PCFG对真实文本的覆盖面。
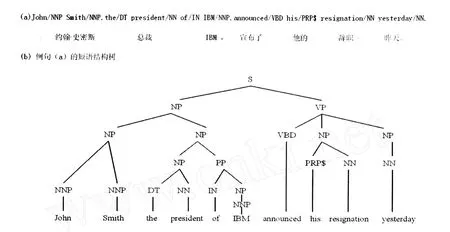
图1 宾州树库的一棵短语结构树
(3)学术界一般都会在树库中按一定比例划分出专门的训练集、开发集和测试集,以便为自动句法分析研究提供一个可比的测试平台。这种可共享的资源使得统计机器学习(statistic machine learning)方法在自动句法分析技术中如虎添翼,迅速成为这一领域的主流方法。在新旧世纪之交,由宾州树库训练出来的PCFG句法分析器在性能上明显超越了原先基于规则和合一(unification)运算的句法分析器,后者包括语言学界熟知的广义短语结构语法(GPSG)、词汇功能语法(LFG)、中心语驱动短语结构语法(HPSG)和功能合一语法(FUG)等等。
宾州树库的标注依据的是短语结构语法,但在短语节点上增加了SBJ(主语)、OBJ(宾语)、TM P (时间)和LOC(处所)等功能标记,在句法树上则添置了转换生成语法特有的W h-转移和空语类(Null)等节点。在析句时采用直接成分分析法,但又不严格遵守二分法,图1(b)的“VP→VBD NP NP”便是一个三分的例子,目的是使句法树显得平坦一些,便于人们阅读和审查。宾州树库在S (句)、NP(名词短语)、VP(动词短语)、PP(介词短语)等短语标记中既不指明短语内部的结构类型(如主谓、述宾、述补、定中、状中等),又不标明每个短语的中心语位置。这给后来的自动句法分析带来了一些困难。Collins②M.Collins.Head-driven statisticalmodels for natural language parsing.PhD thesis,University of Pennsylvania, 1999.在实现概率型自动句法分析系统时,不得不用一个人工编制的“中心语规则表”来为分析系统自动推断每个短语的中心语,这也在一定程度上降低了基于宾州树库的训练精度。
与此相应,周强主持制作的清华大学中文树库①周强:《汉语句法树库标注体系》,《中文信息学报》2004年18(4)期,第1-8页。(TCT)改进了短语结构的标记系统,不仅定义了16个短语成分标记,还用大写的字母后缀定义了27个短语内部的结构关系类型:-ZZ(主谓), -PO(述宾),-DZ(定中),-ZZ(状中)等,用数字后缀指明了每个短语的中心语位置:-0(第1位置),-1(第2位置),-2(第3位置)等。图2中的根节点dj-ZW-1表示这是一个单句(dj),内部是主谓结构,其中心语是vp(在第2位置)。谓语vp-PO-0是一个述宾结构,其中心语为动词“是/v”(在第1位置)。这是一种多层次的句法标注体系,不仅综合了中心词分析法和直接成分分析法的优点,而且照顾了自动句法分析的需要。
如前所述,树库的制作,尤其是树库标注规范的编制,离不开语言学理论的指导。反过来,由于树库所体现的语法知识不仅规模大而且颗粒细,必将给语言学研究本身和自动句法分析技术两方面都带来重大影响。比如,树库的标注应采用哪种句法结构知识表示,现有的词类和短语标记能否适应树库标注的需求,树库的标注应至少包含哪些必要的层次和信息,不同层次之间的标注怎样交互索引等等,都是值得研讨的问题。鉴此,2002年学术界发起了一个名为“树库和语言学理论”的国际研讨会(International Wo rkshop on Treebanks and Linguistic Theo ries,简称TL T),目的是更好地推动计算语言学与理论语言学这两个领域研究人员的互动。TL T研讨会每年一届,2009年12月4-5日在意大利米兰举行的是它的第八届年会②http://tlt8.unicatt.it/p rogramme-tlt8.htm.。
二、依存语法和依存结构树
依存语法是指导树库构建的另一种常用的语法理论,由于它不采用短语结构和短语范畴那样的语法概念,显然不符合词组本位的语言观,而只能遵循句本位的语法体系。此外,依存语法认为,在句子中任何两个词的依存关系中必有一个是中心词(head),另一个是从属词(dependent)。所以中心词析句方法在依存句法分析中具有不可替代的位置。
依存语法③http://en.w ikipedia.org/w iki/Dependency_grammar.是法国语言学家L.Tesniere于1959年提出的。依存语法直接通过句子中词与词之间的依存关系来描述句子的句法结构,而不采用短语结构和短语类那样的语法概念。因此它和链语法(Link Grammar)、范畴语法(Category Grammar)一样,同属于词例化语法。在词例化语法中,语言的全部知识几乎都登录在词库中一个个特定的词项上,除此以外没有众多的语法规则。捷克语的布拉格依存树库④J.Hajic et al.Prague Dependency Treebank 2.0,2006.http://ufal.mff.cuni.cz/pdt2.0.(Prague Dependency Treebank,简称PD T)包含三个层次的语法信息标注:第一层为词法信息,第二层为依存句法信息,第三层是像施事(agent)、受事(patient)那样的深层语义角色标注。PD T的训练集共有38727句, 652544词次,平均句长16.8词次。

图2 清华中文树库的一棵短语结构树
依存语法认为,如果一个句子由n个词组成,那么它的依存结构树就只包含n+1个节点和n条表示某种依存关系的弧。其中只有一个ROOT (根)节点是独立的,它惟一地支配着句子的谓词(即句子的中心词),句子中其余的每个词节点分别只能接受另外一个词节点的支配,支配者是一个依存关系的中心词,被支配者是这一依存关系中的连带成分或附加成分。正是这种词间的支配与被支配关系体现了句子的句法结构。值得注意的是,除了ROOT节点以外,句子中起支配作用的词节点可以支配两个或两个以上的词节点。图3是图2同一例句的依存关系表示(a)和依存结构树表示(b)。图中谓语动词“是/v”不仅支配着主语“中国/nS”,依存关系记作SBJ(主语),而且支配着宾语的中心词“国家/n”,依存关系记作OBJ(宾语)。对比图2和图3人们不难看到,依存句法树的标注比短语结构树简单得多。更重要的是,在任何一个句子中这种词与词之间的依存关系与特定语言无关,具有普遍语法(Universal Grammar)的意义。这一点和格语法和配价理论的动机是一致的。

图3 图2例句的依存树
树库既有用短语结构(PS)来表示的,也有用依存结构(DS)来表示的。当人们想把短语结构树转换成依存结构树时,研究者在宾州树库中遭遇了短语中心语不完全确定的困难,转换精度一般只有90%左右。相比之下,清华中文树库TCT由于对每个短语标记都用数字后缀方式显式地指明了中心语的确切位置(见图2),可使上述转换的精度达到97%左右①党政法、周强:《短语树到依存树的自动转换研究》,《中文信息学报》2005年19(3)期,第21-27页。。
请注意,依存语法强调每一个依存关系中都有一个中心词,这一点和句子的语义解释可谓不谋而合。例如,计算语言学所关注的谓词-论元结构(p redicate-argument structure)和语义角色标注(semantic role labeling,即SRL)也都认为概念的语义核心一般落在短语的中心语(词)上,所以句法的和语义的依存关系之间有一种天然的联系。第十三届自然语言学习国际研讨会(CoNLL-2009)②http://ufal.mff.cuni.cz/conll2009-st/#task.举办了一次自动依存句法分析和语义角色标注的公开评测。会议提供了包括英、汉、德、西、捷、日、加泰隆(catalan)等七种语言的训练和测试语料③J.Hajic et al.The CoNLL-2009 shared task:Syntactic and semantic dependencies inmultip le languages.In Proceedingsof the Thirteenth Conference of Computational Natural Language Learning(CoNLL):Shared Task, Boulder Colo rado.Jane 2009.1-8.。评测成绩以七种语言句法和语义依存分析结果的召回率和精确率的调和平均值F④召回率R是系统输出的正确标注数占答案中标注总数的百分率,精确率P是系统输出正确标注数占系统输出的标注总数的百分率,调和平均值定义为F=2PR/(P+R)。来排名。在这项评测中绝大多数参评团队只懂得其中的一两种语言,对那些完全不懂的语言,机器学习方法利用开发集的样本来自动选择语言特征以适应不同语言的特点。在CoNLL-2009的综合评测结果中,前三名七种语言平均的F值都达到了82%以上,这是相当令人鼓舞的。
小结:依存语法是一种词例化语法,强调句子中词与词之间的直接依存关系,既有相邻词又有远距词之间的依存关系,每个依存关系中必有一个中心词,句子的结构层次表现在间接的依存关系上。在当今世界各国构建的树库中,除了短语树库以外依存树库是数量最多的另一类树库。尽管基于短语结构语法的树库也以句子而不是短语作为树库的基本描述单位,词组本位也许仍可以被视为构建这类短语树库的理论基础;然而依存语法完全摒弃了短语或短语范畴一类的概念,说依存树库的建设也要用词组本位的语法体系来指导,就说不通了。这一事实彰显了句本位思想和中心词分析法在语言学意义上的广义性和生命力。
三、词语依存概率和中心语(词)的应用
树库的一个重要价值在于树库语法(treebank grammars)对自动句法分析所作出的巨大贡献。在这一领域,中心语(词)在改进PCFG句法分析器的精度中发挥了重要作用,也从一个侧面表现出中心词分析法在现代语言科技中仍然充满了活力。
Co llins⑤M.Collins.A new statistic parser based on bigram lexical dependency,ACL-1996.在他的统计型词例化句法分析器中充分利用了基本名词短语(baseNP)的中心词以及词语之间的依存概率,使其句法分析的召回率和精确率的调和平均值F在宾州树库的测试集上首次达到了86.1%。Collins把非嵌套的名词短语定义为基本名词短语。在图4(a)中我们用方括号示出图1(a)例句S的基本名词短语B,并用黑体表示该基本名词短语的中心词。下一步,Collins用这些中心词来替代原来的基本名词短语,得到如图4 (b)所示的经过简约的句子S’。图4(c)是这个句子简约后的依存结构D。
值得注意的是,Collins不仅用基本名词短语的中心词来替换该基本名词短语,而且用简约后的句子来估计和考察词语对的依存概率。Collins是一位在统计型词例化句法分析模型上作出过重要贡献的学者,他采用的上述句子简约方法,并非来自转换生成语法的经典理论,而是创造性地运用了传统语法的中心词思想。

图4 (a)基本名词短语B;(b)简约句S’;(c)词语依存关系D(Collins,1996)
小结:在1981-1982年国内析句方法的讨论中①华萍:《评“暂拟汉语教学语法系统”》,《中国语文》1981年第6期,收入《中国语文》杂志社编:《汉语析句方法讨论集》,上海:上海教育出版社,1984年版,第1-19页。史存直:《句子结构和结构主义的句子分析》,《中国语文》1981年第2期,收入《中国语文》杂志社编:《汉语析句方法讨论集》,上海:上海教育出版社,1984年版,第28-41页。,黎先生的中心词分析方法曾备受指责,其中一个给人印象深刻的例子就是“于福的老婆是小芹的娘”,经过主、宾语中心词紧缩后,成了“老婆是娘”,似乎很可笑。其实,既然是句法分析方法,就应当首先肯定紧缩后的句型——“N是N”是一个极其常用的汉语句型,而不必强求紧缩前后的句子在语义上是否维持不变,因为这不是句法关注的焦点。张志公先生对这种讨论问题的方式也提出了批评,他说:“‘中心’本来就是在‘整体’中存在的,没有‘整体’也就无所谓‘中心’。……把中心词连带着的词统统拿掉,剩下来的就只是一个‘词’,不是‘中心词’了”②张志公:《分歧点和交叉点——分析句子问题琐谈》,《中国语文》1981年第6期,收入《中国语文》杂志社编:《汉语析句方法讨论集》,上海:上海教育出版社,1984年版,第192-204页。。Collins用句子中基本名词短语的中心词来替换该基本名词短语,而且用简约后的句子来估计词语对的依存概率。应当说,这是中心词析句法和紧缩法在自动句法分析系统中的创新应用,不是什么荒诞可笑的想法。
四、句本位和中心词分析法的再认识
如上所述,黎锦熙先生创导的句本位、三个层次(主-谓、宾-补、定-状)、六大句法成分和中心词析句方法是一些非常基本的语法思想,迄今依然可以在世界各国的树库建设和各种自然语言处理的研究中看到它们的广泛应用。它们作为中学语法教学的知识点也不会过时。正是黎锦熙的《新著国语文法》奠定了汉语教学语法的基础。这些朴素的传统语法思想在印欧语言的中学母语语法教学中至少流行了二百年以上,是不可能轻易被撼动的。
其实,我国解放后中学语法教学的内容和课时一直存有争议。一方面,语法和文学争课时;另一方面,语法教学的内容和体系也不断受到外界求新求变的压力。在1981-1982年那场全国汉语析句方法的讨论中,一部分学者企图用所谓“科学性”的名义把中心词分析法(又称句成分分析法)批倒,而用直接成分分析法(又称层次分析法)取而代之。虽然这一诉求得逞于一时,但经不起我国中学语文课教学的考验③胡明扬:《现代汉语的开创性著作——〈新著国语文法〉的再认识和再评价》,《语言科学》2002年1(1)期,第92-101页。。这也许说明,“暂拟汉语教学语法系统”在被迫仓促做出修订之后,中学语法教学的难度和课时都有所膨胀;而物极必反,引发了新一轮的语法和文学的课时之争,这一次看来是文学占了上风。
如果我们要从1981-1982年那场析句方法的讨论中吸取一点教训的话,那么以下三点可以供大家参考:
(1)中学语法教学的内容和方法必须经过长期教学实践的考验,要有一个稳定的教学大纲,几十年不变;
(2)一般而言,语言学理论研究的成果不能简单地取代中学语法教学中行之有效的观念与方法,因为培养杰出的语言学家从来不是中学语法教学的目标;
(3)在语言学的讨论中,应该多一些宽容,慎用“科学性”一类的标准,因为至今我国语言学中的大部分思想和方法尚未经过真正意义上的科学验证。提倡宽容,也不是只说好话,而是倡导实事求是、与人为善。相信这一态度有助于繁荣我们的学术。
(责任编辑 宋媛 责任校对 宋媛 刘伟)
L ife Force of Sentence-Based Syntax and Head-Driven Sentence Analyzing Method:A View from Treebanking
HUANG Chang-ning1;L IYu-mei2
(1.Microsoft Research Asia,Beijing 100180;2.Tsinghua University,Beijing 100084,China)
Treebank is a text co rpus w ith syntactic annotation.It records the syntactic tree,i.e.the syntactic parse,of every sentence in running texts.Since 1990s,automatic parsing of natural languages has again become the focusof the international community of computational linguistics,and one of the crucial reasons is the realization of the Penn Treebank (PTB).The perfo rmances of statistical parsers,w hich are based on automatically induced Probabilistic Context-Free Grammar(PCFG),outperform significantly those rule-and unification-based parsers.A Treebank of any language in the wo rld,rep resented w ith either phrase structures o r dependency structures,takes sentence as its basic description unit.Dependency Grammar is a lexicalized grammar;it denies the notion of phrase structures and describes only the variouswo rdwo rd relations in a sentence,in w hich the head-word is the dominant of a given relation,and the other word of the wo rdpair at stake is the dependentof the head.Dependency Grammar creates a transparent interface between the dependency syntax and semanticsof a language.Thispaper highly estimates the life fo rceof the sentence-based syntax and the head-driven sentence analyzing method advocated by Jinxi Li,because they have no t only dominated grammar teaching in middle schoolsmore than half century before and after the foundation of the Peop le’s Republic of China,but also guides the treebanking p ractice today.
sentence-based syntax;head-driven sentence analyzing method;Treebank;automatic parsing
H146
A
1002-0209(2010)05-0053-06
2010-06-24
黄昌宁,清华大学计算机系,教授;微软亚洲研究院,高级顾问。
