视觉加权的率失真优化死区调整算法
2010-08-10曹峥
曹 峥
(上海贝尔股份有限公司,上海 201702)
1 引言
H.264/AVC有许多创新,比如帧内的混合预测编码、低复杂度的变换编码等。最大的亮点是不需要除法和浮点运算的量化算法,量化以4×4的变换块为单位进行。前向量化准则为 Z=ROUND((Y+f)/Qstep),反向准则为 Y=Z×Qstep,其中 Y={yi,i=0,…,N=15}为 4×4 的变换残差块,对应的量化阶块 Z={zi|zi∈I,i=0,1, …,15},Qstep是范围从0.625到224的量化步长。为了使量化器很好地匹配输入信号,H.264中引入参数f调整死区大小,对于帧内模式f=Qstep/3;对于帧间模式f=Qstep/6。然而f并不能适用于所有码流。同时,由于图像和视频的最终接受者是人,人眼视觉系统和客观质量评估并不总是一致的,因此客观质量评估并不能完全正确地表示图像质量。
目前国内外一些学者对H.264的量化器进行了改进。Thomas Wedi和Steffen Wittmann提出了在H.264的量化器中引入死区调整参数θ分开控制死区和重构值位置的算法[1]。该算法可以在减小死区使细节被恢复的同时保持原有的重构值位置不变,从而不会增加量化误差。在此基础上联合优化参数f和θ可以进一步提高量化器的性能[2],带来0.5 dB左右的增益。但是这种方法需要传输参数θ,因此带来了额外的开销,同时也和标准解码器不兼容。除此之外,上述方法都旨在提高量化器的客观质量,而没有考虑如何提高主观质量。
针对这些不足,提出了基于视觉模型的率失真优化的死区调整算法。该算法根据视觉加权的率失真代价值调整死区大小。由于死区是零点附近被量化为0的区域,因此本算法根据上述的率失真代价值将死区附近的信号自适应地量化为0或1。本算法可有效提高图像视觉质量,同时没有额外的开销,和标准解码器兼容,而且可适用于任何基于块编码的图像和视频压缩标准。
2 率失真优化的死区调整算法
根据香农率失真理论,最优的量化器是在给定码率Rc约束条件下使失真最小的量化器[3]。对于一个有限阶数的量化器,假定S是一组实数的集合,I={0,1,2,…}是量化阶(quantization level)的有限集合,那么最优的量化器满足
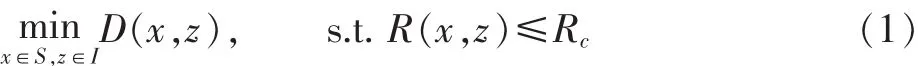
其中 x是输入信号,z是对应的量化阶,D(x,z)是 x被量化成z后产生的失真,R(x,z)是对应的速率。如果对输入信号的每一个值都按照式(1)选择最优的量化阶,无疑可以得到最好的率失真性能。但是这种作法意味着巨大的计算量,几乎是不可能实现的,因此需要减少处理的信号,使计算量下降。在图像和视频压缩编码中变换编码后的信号可以近似为拉普拉斯分布[4]。拉普拉斯分布的特点是在离零点近的区域呈现比较陡峭的分布,而在远端呈现近似均匀的平坦分布。由于H.264的量化器是死区大小为[0,Qstep-f]的均匀量化器,它量化大幅度信号的性能几乎是最优的[5],而对小信号性能较差。因此将研究重点放在死区及其附近的小信号区间。令第1个和第2个量化区间的区域为上述的小信号区间,并将该区间定义为自适应窗wadpt⊂S。自适应窗wadpt内的信号允许的量化阶的集合为 I′={0, 1}。 根据式(1),落在自适应窗内的信号x的最优量化阶z*为

当码率等于给定的码率约束Rc时,式(2)的受限问题可以转换为不受限的求解方程[6],z*为

举例说明该算法:如图1所示,系数y1和y2落在自适应窗wadpt内的4×4的残差矩阵Y,其中y1落在死区内而y2落在第2个量化区间,因此按照原有的量化规则,y1会被量化为0,而y2被量化为1。根据式(3)对y1和y2重新量化后,原来被量化为0的y1被量化为1,而原来被量化为1的y2被量化为0。自适应窗外的系数保持原有的量化阶不变。

图1 调整量化阶的示意图
在H.264中,假定残差块中有m个系数位于自适应窗wadpt内,每个系数可能有2个量化阶0或1,那么m个系数可以产生2m种可能的量化结果。保持残差块内其他系数的量化阶不变,这m个系数产生的2m种可能的量化结果就构成了 2m个候选的量化阶块 Zi,i∈L,L={0,1,2,…,2m-1}。这样为m个系数选择最优量化阶的问题就转化为在2m个候选量化阶块中选择最优量化块的问题。在给定码率约束Rc的条件下,最优解为
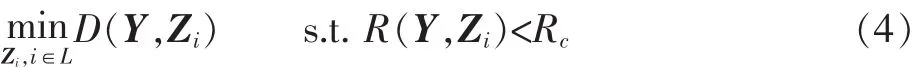
转变成不受限的问题后,最优的量化块Z*可以由最小化代价函数 J(Y,Zi),i∈L 得到

其中,λ≥0,Jλ(Y,Zi)=D(Y,Zi)+λ×R(Y,Zi), R(Y,Zi)是Y量化成 Zi时编码花费的比特数,D(Y,Zi)是 Y量化成Zi重构矩阵Y^i和Y之间的失真。
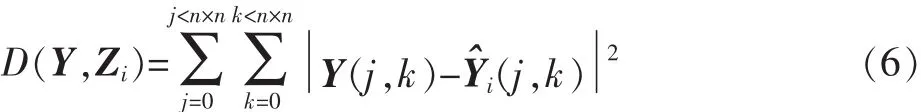
3 视觉加权死区调整算法
人是图像和视频信息的最终接收者,因此在压缩编码中应该考虑人眼的视觉特性。人眼误差敏感度是空间频率的函数。一般地,人眼误差敏感函数可以看作是带通滤波器,它在某个频点处达到最大的频率响应后,随着频率的增加而快速下降。也就是说人眼对低频误差较敏感,而对高频误差不敏感。利用人眼的这一特性,视觉加权的率失真优化的死区调整算法可以获得更高的主观质量,同时通过给高频分配较少的码字降低编码速率。
图像/视频编码块中灰度能量的大小表示它内在的噪声屏蔽能力。噪声屏蔽能力和人眼察觉不到的量化噪声有关[7]。人眼视觉系统中函数H^(f)用来衡量人眼对不同频率误差的敏感度。H^(f)定义如下

式中:δ=11.636/角度,频率f的单位是周/角度。f可以进一步变换成 f(周/角度)=fd(周/像素)×fs(像素/角度),其中
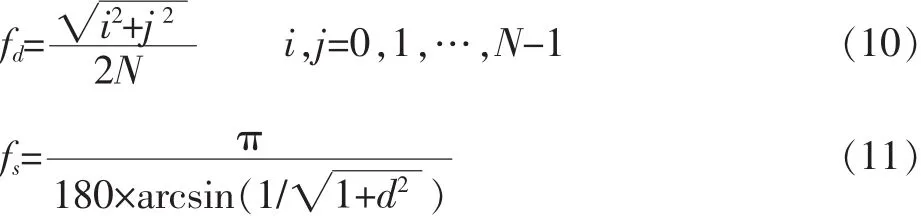
式中:N是DCT块的大小,在H.264中N=4,d为观看距离。可见fs和观看距离有关,对于高度是288像素的CIF图像,当观看距离是图像高度4倍时,fs=20像素/角度。
根据上面介绍的人眼视觉模型,1个位于第i行和第j列的像素能量可以加权为从而视觉加权失真DW(Y,Z)可以定义为
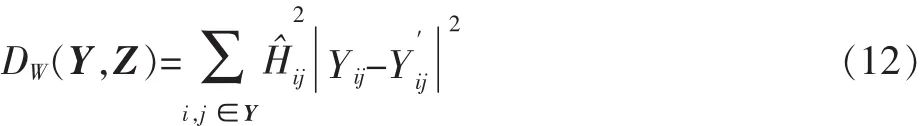
而视觉加权的率失真优化的最优量化块为

由 式(11)和式(12)可以看出随着频率的增加,每个像素的失真占总失真的比重不断减小。因此较高频率的像素易被量化为0,而较低频率的像素易被量化为1。通过给高频像素分配较少的比特,可以在保证主观图像质量不变的条件下使用较少的比特。
综上所述,视觉加权的率失真优化的死区调整算法主要步骤如下:
1)设置自适应窗wadpt;
2)确定4×4编码块中落在wadpt中系数的个数m;
3)编码候选量化块 Zi,计算对应失真 DW(Yi,Zi)和码率 R(Yi,Zi),i=0,…,2m-1;
4)计算每个候选块的率失真代价函数JW(Yi,Zi)=DW(Yi,Zi)+ λR(Yi,Zi),i=0, …,2m-1;
5)求出{JW(Yi,Zi),i=0,…,2m-1}中的最小值 Jmin;最优量化块Z*就是对应Jmin的量化块。
4 实验结果
基于JM11.0版本的标准参考代码,分别对率失真优化的死区调整算法DRDO和视觉加权的率失真优化的死区调整算法PDRDO进行了测试。编码参数设置为帧率30 f/s,图像格式 4∶2∶0,序列的帧格式为 IPBB,P 帧和 B 帧使用相同的量化阶,在进行率失真代价函数的计算时,拉格朗日因子λ和H.264中进行编码模式选择时使用的λmode取值相同。
DRDO算法的测试结果如图2和图3所示。测试序列分别是QCIF格式的News序列和CIF格式的Foreman序列,编码长度为100帧。图中圆圈标记的曲线是由H.264的参考代码得到的率失真性能,正方形标记的曲线是在原有量化器中加入DRDO算法得到的性能曲线。由上述的实验结果可以看出,改进后的量化器无论在高码率还是低码率情况下性能都优于原有量化器,并且增益在高码率情况下表现更为明显,一般可以超过1 dB。
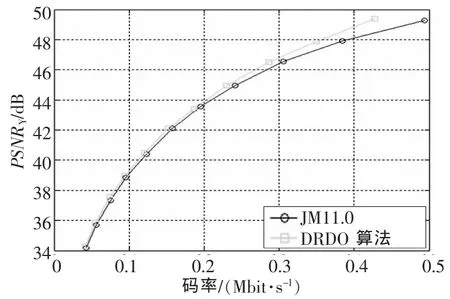
图2 添加DRDO前后对News序列(176×144)的率失真性能比较

图3 添加DRDO前后对Foreman序列(352×288)的率失真性能比较
图4给出了H.264、DRDO算法和PDRDO算法分别对CIF格式的Mobile序列编码300帧后得到的率失真曲线。从图中可以看出DRDO算法提高了量化器的率失真性能,PDRDO算法的率失真曲线位于DRDO算法甚至H.264的曲线之下。然而PDRDO算法编码的图像拥有和原量化器相同的主观质量(图略),同时使用更少的比特。表1给出了Mobile序列352×288P在相同量化阶下PDRDO算法和H.264相比节约的比特和得到的编码增益。
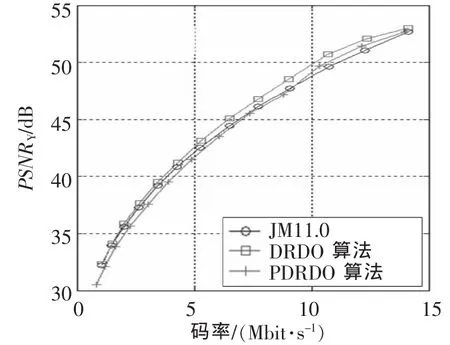
图4 H.264,DRDO和PDRDO的率失真性能比较
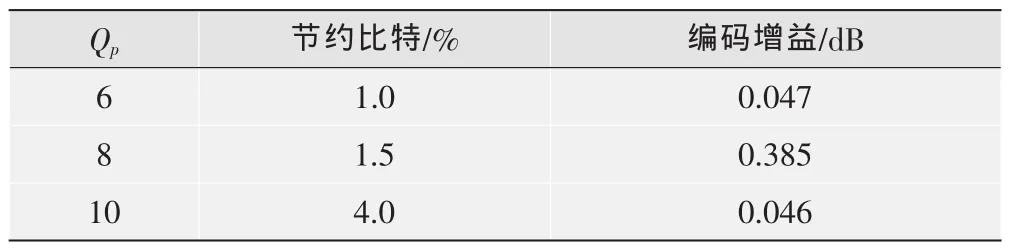
表1 PDRDO算法的节约比特和得到的编码增益
主观质量评估遵循规范ITU-R BT.500-11[8]。在相同量化阶下参考代码和PDRDO算法得到的解码序列在屏幕上并排放置。在观众不知道序列由哪个算法产生的条件下,进行打分。一轮结束后调换序列的位置再进行一次打分。PDRDO算法的平均主观质量分数几乎和H.264的相同。因而虽然PDRDO算法得到的信噪比低,但和H.264有相同的主观质量,同时还节约了10%的码率。
5 小结
率失真优化死区的方法可以有效地提高编码的率失真性能。通过将人眼视觉模型引入率失真代价值的计算,该算法可以在不影响主观视觉质量的前提下,扔掉较多的高频信号,从而花费较少的编码比特。主观质量评估显示当主观质量相同时,基于视觉加权的率失真优化的死区调整算法可以平均节约10%的编码比特。该算法没有额外的开销,适用于任何基于块编码的图像和视频压缩标准,而且和标准解码器兼容。
[1]WEDI T,WITTMANN S.Quantization with an adaptive dead zone size for H.264/AVC FRExt[C]//Proc.JVT DOCUMENT, JVT-K026.Munich,Germany:[s.n.], 2004:51-58.
[2]WEDI T,WITTMANN S.Rate-distortion constrained estimation of quantization offsets[C]//Proc.JVT DOCUMENT, JVT-0066.Busan,KR:JVT, 2005:89-96.
[3]SHANNON C E.A mathematical theory of communication[J].Bell Syst.Tech.,1948,27:379-423.
[4]SMOOT S R,ROWE L A.Study of DCT coefficients distributions[J].Proc.SPIE,1996,1:403-411.
[5]GYÖRGY A,LINDER T.Optimal entropy-constrained scalar quantization of a uniform source[J].IEEE Trans.Inform.Theory, 2000, 46:2704-2711.
[6]EVERETT H.Generalized lagrange multiplier method for solving problems of optimum allocation of resources[J].Operations Reasearch,1963,11(3):399-417.
[7]TAN S H,PANG K K.Classified perceptual coding with adaptive quantization[J].IEEE Trans.Circuits Syst.Video Technol., 1996, 6(4):375-388.
[8]ITU-R.Methodology for the subjective assessment of the quality of television pictures[S].2002.
