基于Web的英语自助学习系统设计
2010-07-05张红斌李广丽
张红斌,李广丽
(华东交通大学 1.软件学院;2.信息工程学院,江西 南昌 330013)
计算机辅助学习已经成为时下流行的学习模式,英语的学习也不例外。例如,人们在学习英语或阅读英语文章时常会遇到生词,很多人会立即求助于词库软件进行单词查询。目前流行的词库软件多为单机版本,如谷歌金山词霸、灵格斯翻译等,它们的使用具有一定的局限性,即无法面向Web进行单词查询、语音表达、口语纠正以及学习资源共享等。故本文叙述了在Web环境下如何构造1个英语自助学习软件系统。
英语学习强调“听”“说”“写”3个方面的技能训练[1],中国学生的英语阅读能力普遍较好,但由于缺乏语言环境,他们的听力和口语能力却有待提高。因此,如何利用Web网站技术、多媒体技术、语音识别技术完成1个可以面向Web用户的开放式英语学习系统,并侧重于听力及口语训练,对于提高中国学生的英语综合素质是1件十分有意义的事情。
1 基于Web的英语自助学习系统的工作原理
英语自助学习系统的核心功能是听力训练和口语训练,实现的关键技术是文本语音转换技术(Text To Speech,TTS)和语音识别技术(Speech Recognition,SR)。文语转移TTS的主要功能是将计算机中任意出现的文字转换成自然流畅的语音输出[2]。运用TTS技术可实现英文单词、词组、句子及文章的在线朗读,指引学生完成基于Web的英语听力训练。运用SR技术则可实现学生所朗读单词、句子的实时语音识别,指引学生完成基于Web的英语口语训练。目前,国内著名网站nciku已经实现了基于Web的英文文本语音转换,但却无法完成英语口语的实时识别及诊断。
微软开发了1套基于Windows环境的语音编程专用组件Microsoft Speech SDK5.1,该组件包含了语音识别(Speech Recognition)和语音合成(Speech Synthesis,SS)两大技术[1]。它可以为我们提供清晰和标准的美式英语发音和标准普通话的简体中文男生发音[3]。该组件包是实现基于Web的英语自助学习系统的重要基础。
1.1 文本语音转换的工作原理
在Speech SDK中TTS功能的工作原理如图1所示。语音应用程序编程接口SAPI是介于语音应用程序和语音引擎之间的中间层[4]。其中SpVoice对象需要实现ISpVoice和ISpTTSEngineSite两个接口[2]。IS-pVoice是应用程序能正常操作TTS功能的接口,它是控制文本语音转换的关键。ISpTTSEngineSite用来写音频数据和消息队列事件。TTS Engine实现ISpTTSEngine和ISpObjectWithToken两个接口。ISpTTSEngine是SAPI调用TTS Engine的接口[5],而ISpObjectWithToken使得SAPI可以创建和初始化TTS Engine。如果用户软件存在界面(User Interface)则必须实现ISpTokenUI接口[1]。SAPI在应用程序和语音引擎之间提供了1个高级别的接口。SAPI实现了所有必需的对各种语音引擎的实时控制和管理等低级别细节。SAPI还支持对SpVoiceObject以ActiveX控件的形式进行调用,故在基于Web的英语自助学习系统中,当网页加载时,同时加载SpVoiceObject,就可完成基于Web的文本语音转换功能。
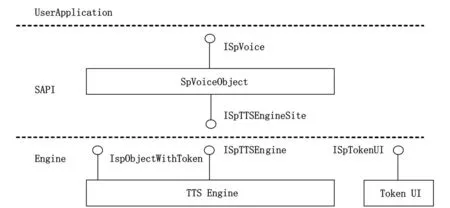
图1 在Speech SDK中的TTS原理
1.2 语音识别的工作原理
ISpRecoContext是语音识别的主接口,它是语音程序接收被请求的语音识别事件通知的媒介[5]。创建1个共享的ISpRecoContext接口后,即可完成语音识别的环境设置,而要创建该接口则必须先创建1个SAPI默认的音频输入流,然后设置语音识别事件通知,其中最重要的事件通知是SPEI-RECOGNITION。最后,创建应用程序,加载并激活1个ISpRecoGrammar,即指定被识别的语音规则。
要实现基于Web的语音识别,其转换引擎必须以ActiveX的方式嵌入到网页中[6]。加拿大的Geoff Bailey基于Speech SDK 5.1和ATL技术封装了1个可完成语音识别的ActiveX控件WebVoiceCtl,该控件可以嵌入到网页中,接受用户的语音输入,然后根据Grammar完成对指定单词、句子的识别,即识别满足正确发音标准的英语语音[7]。
WebVoicceCtl的语音识别工作流程如图2所示。待识别的内容存储在1个XML文件WebVoice.xml中,程序人员可以对其进行编程把需要识别的单词、句子等装载进去,为语音识别做好准备。识别的语音规则被存储在Grammar.xml中,当WebVoiceCtl控件被成功编译后,该规则即被装载到控件中,不能再修改,故必须在编译生成控件前就设定好语音规则。在语音识别过程中,语音识别引擎会把输入的用户语音与正在运行的语音规则进行比较,如果识别规则匹配,则提示正确识别,否则提示用户重新输入语音信息。
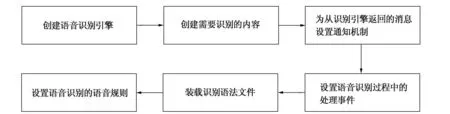
图2 WebVoiceCtl控件语音识别功能的流程图
2 基于Web的英语自助学习系统的设计
基于Web的英语自助学习系统综合运用了TTS,SR,XML和数据库等技术,其中关键技术的集成如图3所示。软件在使用前客户端必须首先正常安装Microsoft Speech SDK 5.1。当TTSPage.AspX网页加载到客户端浏览器后,即通过JavaScript脚本实现1个Spvoice对象,该对象内嵌在网页中,当用户检索英语词库获取单词、词组、句子等英文文本信息时,Spvoice对象就会调用客户端电脑的TTS引擎,执行Speak方法将文本信息转换为语音信息,并通过客户端电脑的扬声器发出。
在SRPage.AspX网页中内嵌了WebVoiceCtl控件,它必须首先在客户端的注册表中完成注册。当客户端与服务器连接后,服务器立即为该客户端复制1份WebVoice.xml文件,用户可以输入英文单词、词组、句子等,并将其注入到WebVoice.xml文件中,在语音识别引擎初始化后,WebVoiceCtl接受客户端语音输入,然后读取WebVoice.xml文件,遵循图2的流程完成语音识别功能。
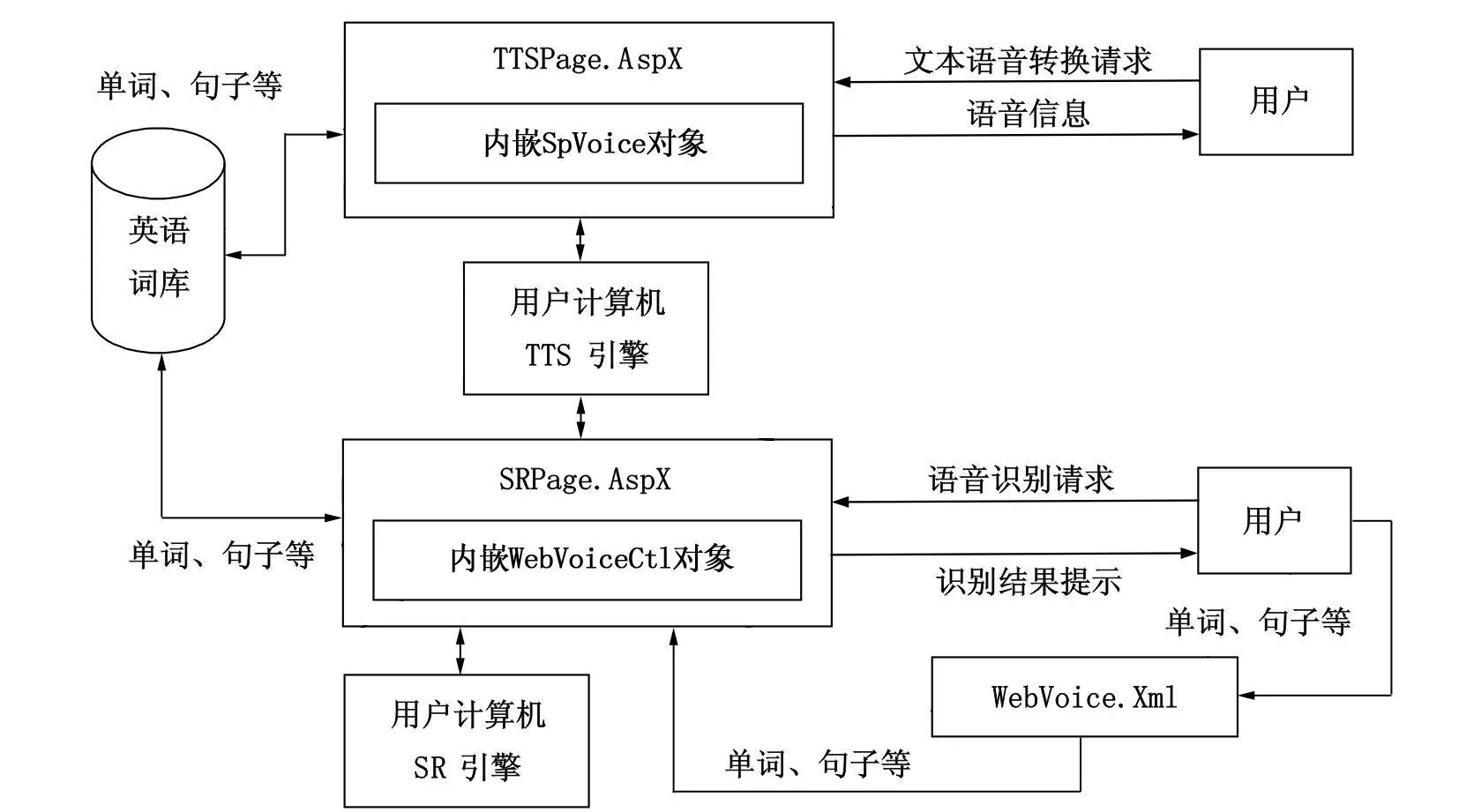
图3 基于Web的英语自助学习系统的关键技术集成示意图
3 基于Web的英语自助学习系统的实现
软件开发环境:Microsoft Visual Studio 2005+SQL Server 2000+Microsoft Speech SDK 5.1+WebVoiceCtl+IIS+XML,在Win2000 SP4/Win XP SP2下均可正常运行。
3.1 文本语音转换功能的实现
文本语音转换功能的软件实现思想如下(仅以单词的TTS为例,词组、句子等的TTS处理方法类似)。
第1步 通过脚本创建SpVoice对象,并将其加载到用户浏览器中,脚本代码:var VoiceObj=new ActiveXObject(”SAPI.SpVoice”)。
第2步 创建触发TTS功能的图片按钮:<img src=”picture/tts-play.gif”style=”cursor:hand”alt=”单击朗读”onclick=”SpeakText()”/>。
第3步 实现SpeakText方法,将文本内容转换为语音:VoiceObj.Speak($('TxtWord').value,1)。
在英文文本朗读的同时,用户还可设置朗读者的朗读口型。微软设计了1组较合理的口型图片顺序[1],该口型图片序列能较准确地模拟人的英语发音口型,脚本代码如下。其中VisemeId为口型编号,它从1变化到21,循环反复。
function VoiceObj::Viseme(StreamNum,StreamPos,Duration,VisemeType,Feature,VisemeId){

此外,用户可基于Web进行转换语音的语速、音量、朗读者等属性设置,以优化其人机交互界面,脚本代码不再叙述,可见Microsoft Speech SDK的帮助文档。
3.2 语音识别功能的实现
以单个英语单词的语音识别为例,词组、句子及文章的识别依赖于逐个英文单词的正确识别,故英文单词的语音识别是整个语音识别功能的关键。
第1步 创建SRPage.AspX并将WebVoiceCtl控件嵌入到网页中。当客户端发出语音识别请求后,它可以响应并正确处理,其代码如下
<object id=”voice” classid=”CLSID:143D27F4-F40B-4F28-918B-FC156A72C07D” codebase=”http://www3.telus.net/CanGeordie/bin/WebVoiceCtl.dll”type=”application/x-oleobject”></object>
第2步 初始化语音识别转换引擎。其代码被封装在WebVoiceCtl控件中,是C++实现,Geoff Bailey已经将其封装好,以下均为引用。语音识别引擎通过按钮点击触发初始化函数,代码如下


第3步 注入识别单词。用户选择将待识别的单词注入到WebVoice.xml中,为语音识别做好准备,这是提供给二次开发者的编程接口,实现代码如下

第4步 完成语音识别。WebVoiceCtl虽然内嵌在网页中,但它却是1个ActiveX控件,可以响应Windows消息,故在其封装代码中,首先为语音识别指定消息响应列表MESSAGE-HANDLER(WM-RECOEVENT,OnRecoEvent),即当该控件接受到WM-RECOEVENT消息后,立即执行OnRecoEvent函数,而在On-RecoEvent函数中通过ProcessRecoEvent函数处理语音识别,ProcessRecoEvent函数代码如下,以下均为引用。


4 结论
基于Web的英语自助学习系统使学习者足不出户就可轻松完成英语学习,其学习内容涵盖了英语学习的听、说、写等训练,并强调了听力训练和口语训练的重要性,该系统具有较好的通用性和推广价值。日后,笔者仍会在语音识别的效率以及多语种自助学习的Web应用等方面做进一步的研究,期望有更多的智能化的语言学习系统能够得到应用,以满足更加丰富、多样的语言学习需求。
[1]李广丽,张红斌.基于TTS和SR技术的英语自学系统的设计[J].华东交通大学学报,2009,26(2):86-90.
[2]廖日坤,纪越峰,黄小迅.基于TTS文语转换的Web语音浏览器[J].兰州工业高等专科学校学报,2006,13(2):10-13.
[3]赵强,左娅佳,房维强,等.诊断学仿真实验系统中应用TTS技术创建虚拟问诊功能的研发设计[J].电化教育研究,2009,(10):62-63.
[4]林茜,欧建林,蔡骏.基于Microsoft Speeeh SDK的语音关键词检出系统的设计与实现[J].心智与计算,2007,1(4):433-441.
[5]袁军,张思民.嵌入式中文TTS系统的研究与实现[J].电脑知识与技术,2008,(6):1 345-1 347.
[3]尹惠玲,杨帆,于虹,等.基于COM的智能TTS系统的设计与实现[J].微计算机信息,2009,25(5-3):172-173.
[4]GEOFF B.Voice-activated Web Browsing[EB/OL].2004[2009-08-16].http://www.codeproject.com/KB/audio-video/Web-VoicePkg.aspx.
