基于隶属函数参数自学习的网络信息过滤技术的研究
2010-06-01王岚
王 岚
(云南警官学院 基础课程教研部,云南 昆明 650223)
基于隶属函数参数自学习的网络信息过滤技术的研究
王 岚
(云南警官学院 基础课程教研部,云南 昆明 650223)
随着计算机和网络技术的发展,网络上的信息越来越多,如何在短时间内查询到符合自己需求的有用的信息,则是每一个网络用户非常关心的问题。同时,随着网络信息量的增大,各种信息犯罪行为也不断涌现,其主要类型有信息窃取和盗用、信息欺诈和勒索、信息攻击和破坏、信息污染和滥用等,并表现出强烈的智能性、隐蔽性、多样性、严重性和复杂性等特征。于是,各国政府主要是从技术、管理和法律等方面采取相应的整治举措,并为了有力的侦破和打击网络犯罪纷纷建立了网络警察。网络警察的主要任务之一就是对网络上的信息进行筛选、过滤,找出其中对网络取证有用的信息。于是,网络信息过滤的研究成为了当前一个比较热门的话题。网络信息的筛选和过滤则是对信息按照预先确定的标准进行分类。本文给出了一种模糊隶属函数参数自学习的方法来对信息进行客观的分类,从而,使网络信息过滤的正确率得到大大提高。
隶属函数;参数学习;网络信息过滤;网络犯罪
一、网络信息过滤技术概述
随着计算机和网络技术的发展,网络上的信息越来越多,如何在短时间内查询到符合自己需求的有用的信息,则是每一个网络用户非常关心的问题。即,将网络上的海量信息按照一定的方法和使用一定的工具进行过滤,选出用户所需的信息,这就是网络信息过滤。在网络安全领域的防火墙和入侵检测方面涉及的主要技术也是网络信息过滤,而信息的过滤主要有以下几点:关键词、摘要、标题、网络IP、图像识别等。过滤的目的一方面是阻止不良信息或有害信息的侵入,营造一个积极健康的网络环境;另一方面则是按照网络用户的要求快速准确地找出用户需要的信息,网络警察也通过信息过滤找出相关取证信息,更好地打击和震慑网络犯罪。
网络信息过滤的首要任务是对相关信息按照一定的标准进行分类,然后,再对相关信息进行按预先确定的分类标准进行识别。从用户而言,不同社会、民族、群体、个人对不良信息有不同的认定,因此,网络信息过滤标准必须尽可能地适应用户多样化的要求;从过滤标准而言,任何一种标准都是一定的思想观点和价值观念的反映,即使是那些适合自我分级的分级体系也不例外。为此,如何尽可能准确地描述相关信息,对提高信息过滤的准确性有较大地理论意义和实用价值。通过大量的文献发现,将传统的经典集合过度到模糊集合,用来描述网络信息,进行信息过滤,更接近于对信息的抽象的理解。在对网络信息进行分类的过程中,将每一个分类定义为一个模糊集,分类的关键字作为集合的元素,其隶属函数表示与该领域的相关程度。隶属函数的参数则是刻画隶属函数,进而对模糊集的刻画具有重要的指导意义。于是,我们采用相关的技术对隶属函数的参数进行自动学习,从而,能大大提高网络信息过滤的准确性。
二、隶属函数参数的学习
要学习隶属函数的参数,必须选用能对参数进行学习的算法,符合此要求的算法有:遗传算法、神经网络等。本文采用神经网络来对隶属函数的参数进行学习,神经网络的类型很多,我们选用目前最常用、最流行的误差反向传播神经网络,即前馈型BP神经网络模型。BP网络的输入和输出关系可以看成是一种非线性映射关系,即每一组输入对应一组输出。任何神经网络的设计可分为三个部分:网络结构设计、参数优化学习算法和激活(目标)函数构造。
1. 网络结构设计
(1)隐层数
一般认为,增加隐层数可以降低网络误差(也有文献认为不一定能有效降低),提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向。本文的网络设计为两个隐层。
(2) 隐层节点数
在BP 网络中,隐层节点数的选择非常重要,它不仅对建立的神经网络模型的性能影响很大,而且是训练时出现“过拟合”的直接原因,但是目前理论上还没有一种科学的和普遍的确定方法。本文中的隐层节点数等于模糊子集数。
2. 参数优化学习算法设计
在神经网络的帮助下通过训练和学习的过程来获取知识。在许多情况下,一个未知系统的知识以数据的形式出现。因此,许多学习算法都是基于数据的。众所周知,在某些实际问题中收集数据是很困难的。这样,融合先验知识(包括启发式和专家知识)在神经网络中将变得很重要,特别是在可获得的训练数据不足时显得尤为重要。
学习是通过改变神经网络的参数(权值和节点)以优化目标函数来实现。依赖于所涉及到的学习方法,目标函数可能是很不同的。一般来说,有三种主要的学习模式:有监督学习、无监督学习和增强学习。本文采用有监督学习中的BP网络。
● 学习率
学习率影响系统学习过程的稳定性。大的学习率可能使网络权值每一次的修正量过大,甚至会导致权值在修正过程中超出某个误差的极小值呈不规则跳跃而不收敛;但过小的学习率导致学习时间过长,不过能保证收敛于某个极小值。所以,一般倾向选取较小的学习率以保证学习过程的收敛性(稳定性),通常在0.01~0.8之间。
● 网络的初始连接权值
BP算法决定了误差函数一般存在(很)多个局部极小点,不同的网络初始权值直接决定了BP算法收敛于哪个局部极小点或是全局极小点。如采用的是Sigmoid转换函数作为目标函数,则由于Sigmoid转换函数的特性,一般要求初始权值分布在-0.5~0.5之间比较有效。而本文采用的是训练模糊系统的隶属函数的参数,考虑到BP算法易陷入局部收敛而选则较小的初始参数。
3. 激活(目标)函数的构造
由于神经网络需要求梯度,从而,所给的隶属函数必须满足可导性,于是,采用最普遍使用的高斯型隶属函数。
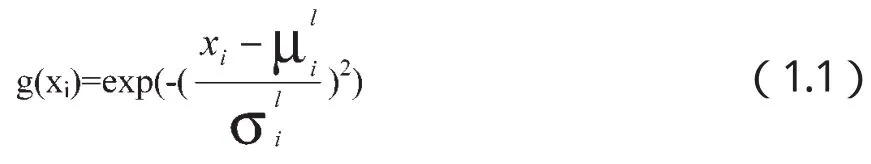
i。需要先设计目标函数(阈值函数),这里采用具有带有乘积推理机、单值模糊器、中心平均解模糊器和高斯隶属函数的模糊系统。原因是“带有乘积推理机、单值模糊器、中心平均解模糊器和高斯隶属函数的模糊系统是一个万能逼近系统,即模糊系统以任意精度逼近任意非线性函数。”[王立新 2003]。于是,激活阈值(目标)函数为:
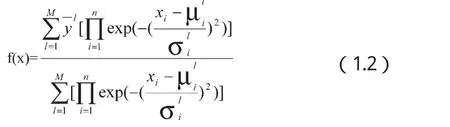


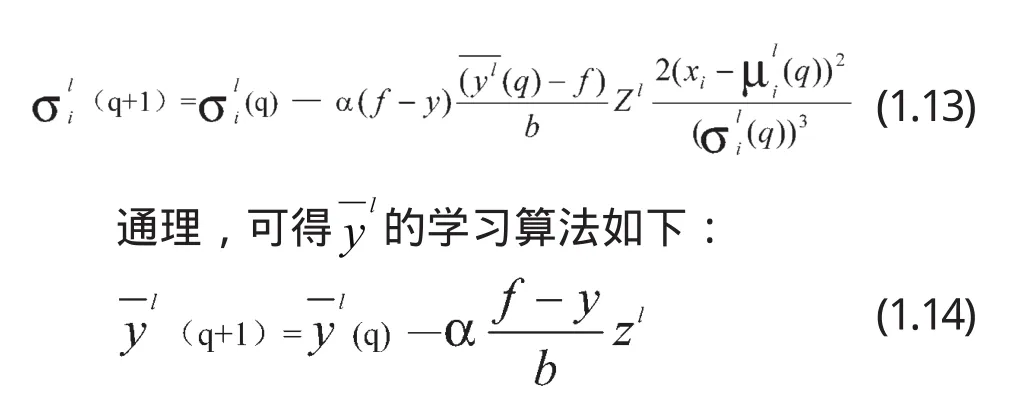
学习算法(1.10)、(1.13)和(1.14)完成的是一个BP算法。下面给出其具体的MFPLBP (membership function’s parameters learned by BP neural networks)算法:
4. 模糊隶属函数参数学习(MFPLBP)算法(隶属函数参数的学习)
输入:对处理的数据提取相关特征,得到相应的数据对作为输入
输出:学习后的隶属函数参数或隶属函数的图形表示

Step4: 令q=q+1,返回Step2重新计算,直到误差|f-yi|<ε(ε为一个很小的正数)或者直到q等于一个预先指定的正整数。
Step5: p=p+1,即用下一个输入—输出数据对来调整参数,重复step2~step4。
Step6: 对生成的模糊隶属函数,确定相关的模糊规则(另文再述),进而,根据模糊规则,即可判断信息的分类。
三、结论与展望
本文通过对模糊隶属函数的参数进行自适应学习,以生成比较客观的隶属函数,依此来对网络信息分级体系进行客观的建立,根据客观生成的模糊划分和随后模糊规则的生成,对网络上的海量信息进行较准确的分类。从而使网络信息的过滤的准确性得到大大的提高。
[1] 刘长安. 人工神经网络的研究方法及应用. 2004.12.31
[2] 徐宗本,张讲社,郑亚林. 计算智能中的仿生学:理论与算法. 科学出版社,2003(5)
[3] 王立新 著,王迎军 译. 模糊系统与模糊控制教程.清华大学出版社,2003(6),1
[4] 黄晓斌. 网络信息过滤原理与应用. 北京图书馆出版社,2005(7),1
Research on the Computer Secutity Technology of Course Teaching
Wang Lan
(Teaching and research department of Basic Course, Yunnan Police Officer Academy, Kunming Yunnan 650223)
With the development and perfect of computer technology and computer network development, the problem of computer security will be the focus of discussing by and by. In all spheres of the society , penetrated with computer technology and computer network,more and more people depended on the computer technology and network. So, the computer secutity have been payed close attention for society. This paper we gave the discussing and thought of computer security teaching which we were engaged in the teaching of computer security.
public security university;computer secutity;course teaching
